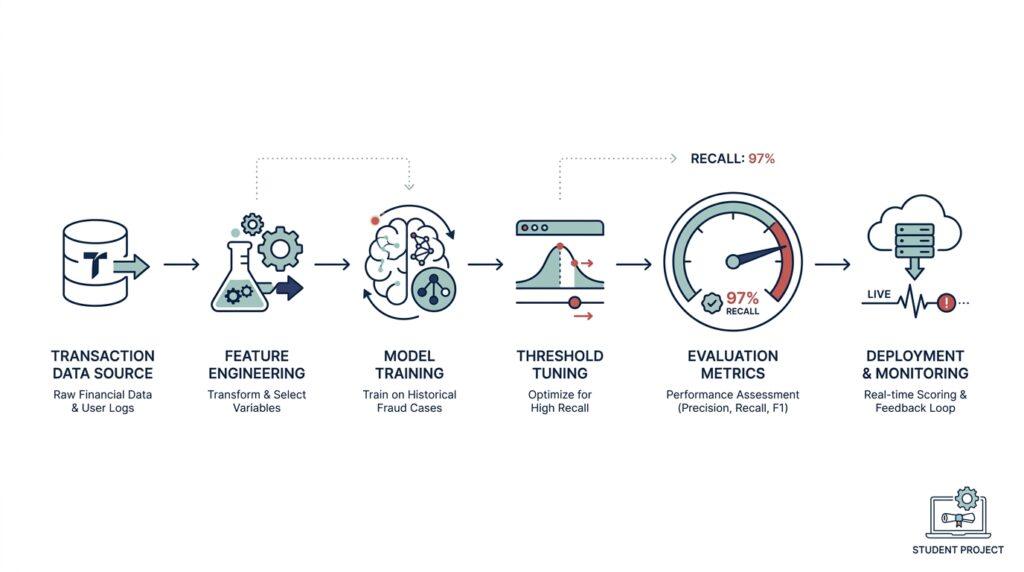
Project Setup and Data Stack
When I started building the fraud detection system, the hardest part was not the model itself — it was getting the project setup and data stack to feel calm enough to trust. I had raw transaction files, a few messy notebooks, and a growing sense that the real battle was organization, not math. What does a fraud detection system data stack actually look like when you are starting from scratch? In my case, it meant building a path from raw data to clean, repeatable experiments, one layer at a time.
I began with a very plain structure: Python for the code, Jupyter Notebook for exploration, and a small folder system that kept raw data separate from cleaned data. Python is the programming language that powered everything, and Jupyter Notebook is an interactive workspace where you can write code, run it in pieces, and inspect results as you go. That combination mattered because fraud detection work is full of small surprises, and I needed a place where I could ask the data questions without losing track of my answers. The project setup also made it easier to revisit old experiments instead of guessing which version had produced the best fraud detection system results.
The next piece was the data stack itself, which is really just the chain of tools that move data from storage into analysis. I used CSV files for the earliest samples because they are easy to open and share, then moved cleaned tables into pandas, which is a Python library for working with tabular data like spreadsheets on steroids. For faster querying and more structure, I also leaned on SQL, which stands for Structured Query Language and lets you ask precise questions of a database. That mix gave me a simple rhythm: collect, inspect, clean, and then feed the data back into the fraud detection system pipeline.
The moment things started to click was when I treated the data like a story instead of a pile of rows. Fraud labels were rare, so class imbalance became a major issue; that means one class, like fraud, appears far less often than the normal transactions. If we are not careful, a model can look impressive while barely catching anything useful. So I built checks into the data stack for missing values, duplicate records, inconsistent timestamps, and suspicious spikes in feature values. Those checks did not feel glamorous, but they protected the 97% recall goal by making sure the model learned from real patterns instead of noise.
I also set up the workflow so every experiment had a clear starting point and a clear ending point. The training set, validation set, and test set each played a different role: the training set taught the model, the validation set helped tune decisions, and the test set gave the final reality check. Keeping those splits separate was like learning a skill with practice, feedback, and then a final exam. Once I had that discipline in place, the fraud detection system became much easier to improve because I could tell whether a gain was real or just accidental.
If you are wondering how to build a fraud detection system without getting buried in tools, the answer is to keep the stack small, visible, and repeatable. I used the project setup to reduce confusion, and I used the data stack to turn messy transactions into something the model could understand. That combination gave me confidence every time I retrained, adjusted features, or tested a new idea. In the next step, the real challenge was making those cleaned features pull their weight.
Collect and Label Transactions
Once the folder system was in place, the next challenge was more human than technical: I had to collect transactions that actually told a believable story. If you are wondering, how do you collect and label transactions for fraud detection? the answer starts with choosing sources that are consistent enough to trust and messy enough to teach from. In my fraud detection system, I treated every transaction as a tiny event with a time, an amount, a merchant, and a result. That gave me a clean starting point before I ever touched the model.
I began by collect transactions from the places where transaction history was already living: exported CSV files, database tables, and public datasets that mimicked real payment activity. A CSV file, or comma-separated values file, is a plain text table that opens like a spreadsheet, which made it easy to inspect early on. When I pulled data from SQL, which is a language for asking questions of a database, I could filter by date, amount, and transaction type before bringing anything into Python. That mattered because a fraud detection system gets noisy fast, and raw noise can drown out the signal we actually care about.
The labeling part was where the work became careful. Transaction labeling means assigning each record a truth tag, such as fraudulent or legitimate, so the model knows what to learn from. In a perfect world, every label would come from a verified case, like a confirmed chargeback or a manual review by an analyst, but real data rarely arrives that neatly packaged. So I built the dataset around the strongest labels first and kept uncertain records separate instead of forcing them into a guess.
That separation helped more than I expected, because unknown labels can quietly damage a fraud detection system. A false label is like handing a student the wrong answer key and then grading them on it. To avoid that, I used simple rules to flag suspicious records for review, such as repeated failed payments, unusual transaction timing, or sudden jumps in spending behavior. Those rules did not define fraud by themselves, but they helped me decide which rows deserved extra attention during transaction labeling.
I also learned that label quality matters more than label quantity. It is tempting to think a bigger dataset always means a better model, but in fraud detection, messy labels can teach the model the wrong lesson very quickly. So I checked for duplicate transactions, mismatched timestamps, and records that looked identical except for the label. When two records told conflicting stories, I paused and traced them back to the source rather than letting the inconsistency slip into training data.
Another thing I had to watch was class imbalance, which means one label appears far less often than the other. Fraud is usually rare, so the normal class can overwhelm the fraud class if we are not careful. To keep the fraud detection system honest, I preserved enough fraud cases to learn from while still keeping the full context of ordinary behavior around them. That balance made the dataset feel less like a random pile of rows and more like a realistic map of what normal and suspicious activity looked like.
By the time I finished this step, I had more than a table of transactions. I had a labeled dataset that could support real experimentation, because each row had a place in the story and a reason for being there. That is what made the next stage possible: turning those transactions into features the model could read without losing the meaning hidden inside them.
Build High-Signal Risk Features
Once the labels were in place, the real work began: turning plain transaction rows into signals that could help a fraud detection system notice danger before a human ever would. This is where feature engineering, the process of turning raw data into useful model inputs, starts to feel a little like detective work. We are no longer asking, “What happened?” We are asking, “What pattern does this behavior fit, and how unusual is it?”
The first features I built were the ones closest to the transaction itself, because those usually carry the clearest warning signs. Amount, time of day, merchant category, and transaction channel all became separate clues instead of one oversized record. A feature is just a measurable piece of information the model can use, and in fraud detection features matter because fraud rarely looks suspicious in only one way. A $7 purchase at 2 a.m. on a new device tells a different story than a normal grocery run at noon, and the model needs that contrast spelled out.
Then I moved from single events to behavior over time, which is where the feature set started to feel much stronger. How do you build a fraud detection system that notices patterns, not just isolated weirdness? You look at velocity features, which measure how quickly actions happen, like multiple transactions in a short window, and rolling-window features, which summarize recent activity over a moving span of time. Those features helped the model answer a simple but powerful question: has this account suddenly started moving differently from its own baseline?
That baseline idea was especially important, because normal for one user can look risky for another. Instead of treating every transaction the same, I built deviation features that compared the current amount to a customer’s recent average, their median spend, and their usual transaction frequency. Median means the middle value in a list, and it helped because extreme outliers did not distort it as much as an average could. In practice, this let the fraud detection system spot behavior that was not just large or small, but out of character.
I also added relationship features, which capture how one part of the transaction connects to another. Examples included whether the billing country matched the shipping country, whether the device was new, and whether the merchant had shown up often in the past. These kinds of signals are high-signal risk features because fraud often hides in mismatches: a familiar account with unfamiliar behavior, a stable history with a sudden shift, or a device that appears for the first time and then starts spending aggressively. Once we frame it that way, the model is not guessing blindly; it is comparing pieces of a story against each other.
Some of the most useful features were also the easiest to overlook. I encoded time as cyclical patterns, which means I represented hours and days in a way that preserves their natural loop, so 11 p.m. sits close to midnight instead of far away from it. That matters because fraud rarely respects a straight line on the clock. I also grouped merchants into broader categories, because the model could learn more from “travel” or “electronics” patterns than from dozens of nearly identical merchant names.
As I kept testing, I learned that a strong fraud detection system does not need a mountain of features; it needs the right ones, repeated in different ways. Some features were raw, some were summarized, and some were comparisons, but all of them were chosen to make suspicious behavior easier to see. The trick was not to make the dataset bigger for its own sake. The trick was to make the model’s job clearer, so it could separate ordinary life from risk without losing the nuance in between.
By the end of this step, the transactions no longer looked like flat records sitting in a table. They had context, memory, and contrast, which is exactly what a model needs when it is trying to catch fraud in the middle of everyday activity. That stronger feature layer became the bridge to the next stage, where we could finally start training the system to recognize which patterns mattered most.
Train on Imbalanced Data
At this point, the fraud detection system had clean labels and stronger features, but training it introduced a new kind of problem: the model could still learn the wrong lesson from an imbalanced dataset. That means the fraud cases were so rare that a model could look successful while quietly missing the very transactions I cared about most. If you have ever wondered, how do you train on imbalanced data without letting the majority class take over? the answer starts with admitting that accuracy is not the goal here. In fraud detection, missing fraud hurts more than flagging a few extra normal transactions, so recall had to stay in the driver’s seat.
The first thing I had to do was stop trusting accuracy as my main scoreboard. Accuracy is the percentage of predictions a model gets right, but with class imbalance it can be misleading in the same way that a student can pass a quiz by guessing the same answer over and over. A fraud detection system can reach a high score by predicting “legitimate” almost every time, yet still fail at the one job that matters. So I shifted my attention to recall, which measures how many real fraud cases the model actually catches, and I kept precision nearby so the system would not become reckless.
From there, I trained the model in a way that gave fraud more voice during learning. One approach was class weighting, which means telling the model that mistakes on fraud cases should count more than mistakes on normal cases. Another approach was oversampling, which means repeating or synthesizing rare fraud examples so the model sees them often enough to learn their shape. I did not treat these as magic tricks; I treated them like volume knobs, because they changed how loudly each class spoke during training. In practice, that helped the fraud detection system pay attention to patterns it might otherwise have ignored.
I also had to be careful not to let the training data become a distorted version of reality. Oversampling can help the model notice fraud, but if you overdo it, the model may memorize the rare examples instead of learning general behavior. Under-sampling, which means shrinking the normal class, can make training faster and more balanced, but it also throws away useful context. So I tested both directions and watched how the model behaved on the validation set, because the validation set is the checkpoint that tells us whether learning is actually improving or just getting louder.
The next layer was threshold tuning, and this is where the model started to feel more like a decision system than a raw predictor. A threshold is the cutoff that turns a probability into a final yes-or-no label, and moving it changes how cautious the model behaves. If I set the threshold too high, the fraud detection system became timid and missed fraud; if I set it too low, it started shouting about everything. Finding the right cutoff was less like picking a number and more like tuning a radio until the signal came through clearly enough to trust.
To make those choices honestly, I kept the test set untouched until the very end. That separation mattered because imbalanced data can tempt you into adjusting the model until it looks perfect on paper. I wanted a model that could survive the real world, not one that had merely learned to impress my notebook. So I used cross-validation, which means testing the model across several train-and-validation splits, to make sure the recall gains were stable and not just a lucky result from one split.
The biggest lesson was that training on imbalanced data is really about respect: respect for the rare class, respect for the limits of the data, and respect for the tradeoffs hidden inside every metric. Once I treated fraud detection as a recall-first problem, the training process became much more intentional. Instead of asking whether the model looked smart, I asked whether it would notice the dangerous cases buried inside normal activity. That question changed everything, because it pushed the fraud detection system toward the one behavior that mattered most: catching the signal before it disappeared into the noise.
Tune Threshold for Recall
Once the model could separate fraud from normal transactions, the next question became a practical one: where do we draw the line? A fraud detection system usually does not answer with a hard yes or no right away; it first produces a probability, which is the model’s estimate of how likely a transaction is to be fraud. Threshold tuning is the step where we choose the cutoff that turns that probability into a final decision, and it mattered because recall was still the metric I cared about most. If you are asking, how do you tune a fraud detection model for recall without making it panic over everything? this is where the answer starts to come into focus.
I treated the threshold like the volume knob on a speaker. Turn it up too high, and only the strongest fraud signals get through, which means the fraud detection system stays quiet when it should speak up. Turn it down too far, and the model starts flagging too many normal transactions, which can bury the signal in unnecessary noise. The trick was not to find a perfect number in theory, but to find a cutoff that matched the real cost of missing fraud.
That is why I worked on the validation set, not the test set. The validation set is the portion of data used to make decisions during development, while the test set stays untouched until the end so it can act as a final reality check. I ran the model at several thresholds and watched how recall, precision, and the confusion matrix changed. A confusion matrix is a table that shows correct and incorrect predictions, and it helped me see whether a threshold was catching more fraud or just making more mistakes.
At first, I was tempted to chase the highest recall possible. That sounds good on paper, but in practice it can turn the fraud detection system into an alarm that never stops ringing. More recall usually means fewer missed fraud cases, but it can also mean more false positives, which are legitimate transactions flagged as suspicious. So I had to balance the relief of catching more fraud against the frustration of flooding the pipeline with unnecessary reviews.
The validation curves made that tradeoff much easier to read. As I lowered the threshold, recall climbed because the model became more willing to call something fraud. Precision, which measures how many predicted fraud cases were actually fraud, usually fell at the same time. That push and pull is the whole story of threshold tuning: we are not changing what the model knows, only how strict it is when acting on what it already knows.
I also learned to think about the threshold in terms of business cost, not just model metrics. In fraud detection, a false negative means a real fraud case slips through, while a false positive means a legitimate transaction gets flagged. Those two mistakes do not hurt equally, and that difference guided my choice. Because my goal was 97% recall, I was willing to accept a few more false alarms if it meant the fraud detection system caught more of the dangerous cases hiding in the stream.
The most useful part of this process was testing small threshold changes instead of making one dramatic jump. A tiny shift from 0.50 to 0.42, for example, could change the model’s behavior in a way that was easy to miss at first glance but important over thousands of transactions. That is why threshold tuning felt a bit like adjusting a camera lens: the image does not become clearer all at once, but each careful turn reveals more of the shape you were trying to see.
By the time I finished tuning, I had a fraud detection system that felt more honest about risk. It was no longer pretending that one cutoff should work for every situation; it was making a deliberate choice about how cautious it should be. That choice connected the model’s raw probabilities to the real-world job of catching fraud, and it set up the final stage, where those tuned predictions had to prove themselves on truly unseen data.
Deploy Alerts and Monitor Drift
After I had a tuned model that could catch fraud on unseen data, the next step felt less like machine learning and more like keeping watch over a living system. A fraud detection system is not finished when it leaves the notebook; it has to stay alert once real transactions start flowing through it. That is where deployment alerts and drift monitoring come in, because a model that worked last month can quietly get worse this month if the world around it changes. If you have ever asked, “How do you keep a fraud detection model reliable after deployment?”, this is the part where we answer it.
I started by treating the model like a teammate who needed feedback, not praise. In production, the system would produce a score for each transaction, and I set up alerts for the moments that mattered most: a sudden spike in flagged transactions, a drop in recall on recent confirmed fraud cases, or a rise in false positives that would overwhelm review work. An alert is just an automatic warning when something crosses a limit, and that limit should be chosen carefully instead of guessed. For my fraud detection system, alerts were the bridge between model performance and real-world action.
The most important alert was the one that watched for drift, which means the data no longer looks like the data the model learned from. Drift can show up in transaction amounts, device patterns, merchant categories, or even the timing of activity, and it often arrives quietly. One week the model sees a normal pattern; the next week, a new payment method or a seasonal shopping burst changes the shape of the data. When that happens, the fraud detection system may still look busy and confident while its actual judgment starts slipping.
To catch that early, I monitored both feature drift and prediction drift. Feature drift means the input values themselves have shifted, while prediction drift means the model’s outputs have changed in a noticeable way, even if the raw inputs look similar. I compared recent transaction windows against the training baseline, because the baseline is the original pattern the model learned from during development. That comparison gave me a practical way to watch for concept drift, which is when the relationship between input and fraud label changes over time.
I also made sure the monitoring was useful to a human, not just impressive on a dashboard. A dashboard is a visual panel that shows key numbers in one place, and mine highlighted recall, precision, alert volume, and the most suspicious feature shifts. Instead of drowning in metrics, I wanted a simple story: what changed, how fast it changed, and whether the model’s decisions still made sense. When a fraud detection system sends alerts, the point is not to create noise; the point is to give us enough context to decide whether we need to retrain, investigate, or adjust the threshold.
That workflow became even more important because production data rarely stays polite. Fraudsters adapt, customer behavior shifts, and business rules change, so the system has to keep learning from the environment it lives in. I set a review loop where confirmed cases fed back into the training data, and I watched whether recent recall stayed close to the benchmark I had earned during testing. That way, drift monitoring was not a separate chore; it became part of how the fraud detection system stayed honest.
In practice, this was the difference between a model that looked strong in a demo and a model that could survive in the real world. Alerts told me when something urgent was happening, and drift checks told me whether the ground beneath the model had moved. Together, they turned deployment from a one-time launch into an ongoing habit of care, which is exactly what a fraud detection system needs once it starts making decisions outside the notebook.