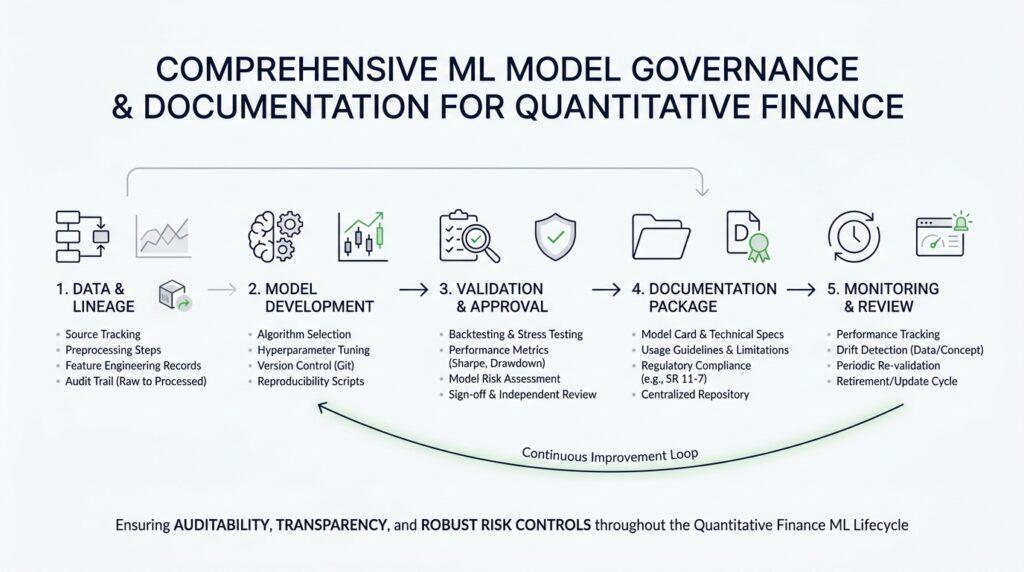
Define Model Scope and Purpose
Before we talk about technical documentation, we need to answer the quiet question that sits at the center of every strong model governance program: what is this model actually for? In quantitative finance, models often help us underwrite credit, value positions, measure risk, estimate capital, or assess reserves, so the purpose is never a small detail—it is the reason the model exists at all. When you define model scope and purpose clearly, you give everyone a shared map of the problem the model is meant to solve and, just as importantly, the decisions it should never be asked to make.
Think of scope as the boundary line around the model’s world. It should tell you which business line, products, portfolios, geographies, users, and decision points the model covers, along with the time horizon and the type of output it produces. That boundary matters because a model used to support regulatory requirements or manage financial risk exposures is generally treated as higher risk than one used for a narrower internal task, and that risk level affects how deeply we validate and monitor it. In other words, the purpose statement is not a label on the box; it is the frame that tells us how much trust the box deserves.
This is where model documentation starts to feel practical instead of ceremonial. A sound model inventory should record the model’s purpose, the products it was designed for, its actual or expected usage, any restrictions on use, the intended outputs, the owner, the users, and the model’s status. If we write the purpose well, it reads like a plain-language promise: this model is designed to do one job, for these users, under these conditions. That kind of statement helps a reviewer, a validator, or a business user understand the model without having to reverse-engineer its intent from code or slides.
Here is the part that often trips people up: a vague purpose creates vague behavior. If the scope says only that a model “supports risk management,” the team may start using it for pricing, capital planning, or portfolio steering even when it was never built for those decisions. Clear scope and purpose help prevent that drift by making exclusions visible, such as whether the model is not intended for intraday trading, customer-facing offers, or firmwide reporting. That clarity also gives validation a fair target, because concept review and outcomes analysis can only judge whether a model is sound if they know what success is supposed to look like.
A good way to write the statement is to imagine you are handing the model to someone who has never seen the project before. What question would they ask first? Usually it sounds like, “What decision will this model support, and in what setting?” If we answer that directly, with the decision, the population, the product, the output, and the boundaries all in view, then the rest of the governance file becomes easier to read, easier to test, and easier to defend. Once that frame is clear, we can move on to the inputs, assumptions, and controls that make the model trustworthy in practice.
Establish Governance and Ownership Roles
Now that the model’s purpose is clear, we can turn to the human side of governance: who owns the work, who approves it, and who watches it after launch. In model governance, that ownership cannot live in a vague committee note or a slide deck; it needs named people with real accountability. If you have ever asked, “Who owns the model once it goes live?”, you are already asking the right question, because model risk management only works when the business can point to a clear owner, not a crowd. Clear roles and responsibilities are a core part of effective model governance, and the current interagency guidance treats that as a practical control, not a formality.
At the top, the board and senior management set the tone. The Federal Reserve guidance says model risk governance sits with the board and senior management when they establish an organization-wide approach, and the updated interagency guidance says model risk management benefits from clear roles, well-defined accountability, and policies that fit the institution’s size and complexity. In plain language, leadership decides how much model risk the firm will accept, how the model governance framework will work, and what happens when the model behaves outside that comfort zone. That is why model ownership starts with decision rights, not with code.
From there, the ownership map should separate development, validation, and monitoring. The people who build the model should not be the same people who independently test it, because the guidance explicitly warns about conflicts of interest between development and validation groups. Internal audit then plays a different role again: it should evaluate whether the model risk management framework is effective, not duplicate development or validation work. This separation is one of the clearest signs that model governance is working, because it creates a built-in challenge function instead of asking the same team to grade its own homework.
This separation is not bureaucracy for its own sake; it is how we keep a quantitative finance model honest after the excitement of launch fades. A practical governance map often assigns a business owner to oversee use, a development lead to manage rebuilds and enhancements, a validator to challenge assumptions, and a monitoring function to watch for drift over time. When those duties are written down clearly, no one has to guess who signs off on a change, who investigates a surprise, or who can pause the model if it no longer fits its purpose. That kind of clarity turns model ownership into something people can actually use when the pressure is on.
External help does not remove responsibility. If the bank uses a vendor, consultant, or other outside resource, the guidance says the organization should maintain proper oversight, define the scope of work clearly, and integrate that work into the wider model risk management process. That is an easy place for teams to drift, because outsourcing can feel like handing off the problem, but governance only works when the firm still knows who is accountable for the outcome. The same logic applies to any shared service arrangement: if the work moves, the accountability does not.
A strong ownership structure should also show up in the model inventory, which should hold enough information to understand the risks of models under development or in use across the portfolio. That inventory becomes the map we reach for when a reviewer asks what changed, who approved it, and where the evidence lives. Once the roles are visible and the escalation path is clear, the rest of the documentation can do its job: recording assumptions, controls, and monitoring in a way that lets the next chapter of governance pick up right where this one leaves off.
Track Data Lineage and Inputs
Once the owner and validator are named, the next quiet question is where the model’s numbers actually come from. Model data lineage is the trail that shows how each input moves from its original source, through any cleaning or reshaping, and into the model itself. That trail matters because banking guidance treats input quality, data constraints, and the systems that move data into and out of a model as part of model risk, not as background plumbing. In other words, if the inputs wobble, the model can wobble with them.
When we document lineage well, we are not writing down every detail for its own sake; we are building a map that another person can follow later. A strong record names the source system, the field or file used, the transformations applied, any aggregation or filtering, the exclusions made, the refresh timing, and the person or team responsible for each step. That matches supervisory expectations to document key assumptions, data inputs, data exclusions, model design choices, and any adjustments that shape the final output.
How do we track model data lineage without turning the documentation into a paperwork maze? A practical approach is to start at the model’s input table and walk backward, one step at a time, until we reach the original record or vendor feed. Along the way, we note where a value was joined, averaged, capped, imputed, or manually overridden, because those are the moments when meaning can quietly change. This is especially useful for quantitative finance models, where even small differences in reference data, timing, or aggregation can affect risk estimates and business decisions.
It also helps to treat missingness and overrides as first-class citizens in the story. If a feed arrives late, if a record is incomplete, or if someone replaces a field by hand, that change should appear in the lineage notes rather than hiding in an email thread or a memory. The reason is simple: sound model risk management depends on data and reporting integrity, plus controls and testing that show the model was implemented and is being used as intended. When we can see the breakpoints, validation has something concrete to challenge instead of guessing at what happened upstream.
This is where the model inventory becomes more than a list of names. If lineage records stay attached to the inventory entry, reviewers can see which inputs changed between versions, which upstream systems feed the model, and which source data deserve extra attention during review or revalidation. That kind of traceability is valuable when a vendor file changes format, a business rule is updated, or a new portfolio is added, because the team can tell whether the model itself changed or only the data around it did. Building that habit now makes the next step easier: showing not only what the model sees, but what it assumes about the world it sees.
Validate Assumptions and Outputs
Now that we have traced the inputs back to their source, the next question is the one that quietly decides whether the model can be trusted: what has it assumed about the world, and do those assumptions still hold? In model governance, assumptions are the hidden promises inside the model’s design, and model validation is the process that checks whether those promises are reasonable, documented, and still aligned with the model’s purpose and business use. The Federal Reserve’s model risk guidance says validation should examine a model’s assumptions, methods, data, and relevant theory, and it should also clarify the model’s limitations and appropriate use.
A good way to think about this step is to treat the model like a map drawn for a specific road trip. If the map was made for city driving, we cannot assume it will guide us safely through mountain weather or an overnight detour. So we test model assumptions against the problem the model was built to solve, look for places where judgment filled in gaps, and compare alternative assumptions or methodologies when the stakes are meaningful. That is why model validation often includes out-of-sample and out-of-time testing, as well as critical review of data quality and modeling choices.
What does a “good” output look like in practice? It is not the output that merely looks tidy on a slide; it is the output that behaves credibly when we compare it with real-world results. The guidance describes outcomes analysis as a comparison between model outputs and actual outcomes, used to assess performance against the model’s objectives and business use. If the output keeps drifting outside the institution’s performance thresholds, the team may need to recalibrate, adjust, or even rebuild the model rather than defending a number that no longer fits reality.
This is where model outputs and model assumptions meet each other in public. A model can still be risky even when it is mathematically sound if users misunderstand its limits or use it beyond its intended purpose, so validation has to challenge not only the calculation but also the decision context around it. Effective challenge means objective experts press on the logic, ask uncomfortable questions, and have enough independence to influence change. When outputs are judgment-heavy, quantitative review helps us see whether the human judgment inside the model was well supported or merely convenient.
That is also why documentation matters so much at this stage. We want a reviewer to see, in one place, which assumptions were tested, what evidence supported them, what thresholds were used, where the model fell short, and what action followed. Current interagency guidance says effective policies and procedures should support model governance, and adequate documentation should help track recommendations, responses, exceptions, and remediation work. In other words, documentation turns model validation from a one-time debate into a record we can actually use later.
If the model comes from a vendor or another third party, the same discipline still applies. Banking organizations are expected to understand the vendor model’s conceptual soundness, design, development data, and performance, and to document and justify any custom overlays or adjustments made for their own use. That matters because model governance does not stop at the firm’s front door; if we borrow the engine, we still have to prove the car is safe to drive. Once assumptions and outputs are validated this way, we are ready for the next layer of control: showing that the model continues to behave well after launch, not only on the day it was approved.
Monitor Drift and Performance
Once the model is live, the room gets quieter, but the real work begins. Model drift is the slow mismatch between what the model learned and what the business world is doing now, and performance monitoring is how we catch that mismatch before it turns into a bad decision. How do you know a model is drifting before trouble shows up on a loss report? You watch it in production, because supervisory guidance says monitoring starts when the model is first implemented for actual business use and continues over time, especially when products, exposures, activities, clients, or market conditions change.
The easiest way to picture this is to think of the model as a dashboard in a car. We do not stare at it once and assume the road will stay flat; we keep checking the gauges while we drive. In model performance monitoring, those gauges include adherence to risk appetite, internal limits on use, and targets for accuracy or reliability, along with risk measurements and performance thresholds that tell us when the model is getting too far from acceptable behavior. A threshold is the line that tells us, “keep going” or “slow down and look closer.”
How do we spot drift in practice? We compare what the model predicted with what actually happened. That comparison is called outcomes analysis, and when it uses actual results against forecasts over a period that was not used in development, it becomes back-testing, which is especially useful when the forecast horizon or performance window is clear. The guidance also recommends early-warning metrics and trend analysis, because a model rarely fails in one dramatic moment; more often, it starts slipping a little at a time.
But drift does not always show up as a neat gap between forecast and outcome. Sometimes it appears when users keep overriding the model because the output does not fit the business reality in front of them. That is why ongoing monitoring should include override analysis, with the reasons for overrides documented and the override performance tracked; if overrides are frequent or consistently improve results, the model often needs revision or redevelopment. Benchmarking works the same way: we compare the model with another internal or external model or dataset, then investigate any meaningful differences instead of ignoring them.
Data drift often shows up first upstream, before the output looks obviously wrong. If a source feed changes, a vendor file shifts, or the way a portfolio is used changes, the model may still run while quietly losing fit. That is why the guidance asks firms to verify that inputs remain accurate, complete, and consistent with the model’s purpose, to monitor the integrity and applicability of internal and external information sources, and to keep code and system changes under control. It even notes that if a model only works well in certain ranges of input values or market conditions, we should watch for the moment those limits are being approached or exceeded.
This is also where performance monitoring becomes a governance habit instead of a one-time test. Reports derived from model outputs should be timely, accurate, and informative, and they should reach the right people, including the board when needed. When monitoring shows poor performance, significant threshold breaches, or repeated signs that the model no longer fits its intended use, the response should be clear: adjust, recalibrate, redevelop, or replace the model, then record what happened and what changed. That record matters because the next reviewer should be able to see not only that model drift was detected, but also how the organization responded.
In practice, the healthiest model drift process is a steady loop: watch, compare, question, and act. That rhythm keeps model performance visible after launch and turns monitoring into an early warning system rather than a postmortem.
Maintain Change Logs and Approvals
Now that we’ve seen how monitoring can reveal drift, the next thing we need is a paper trail that tells the story behind every fix. A strong model change log turns model governance from memory into evidence: it records what changed, who asked for it, who reviewed it, and why the team accepted it. Supervisory guidance expects documentation to support continuity, track recommendations, responses, exceptions, and remediation, and the OCC’s model risk handbook specifically looks for a detailed change history that captures model version, rationale, supporting evidence, related tests, and approvals.
That log works best when it reads like a clear conversation, not a pile of technical noise. We want to see whether the change was a small recalibration, a new data feed, a code fix, a parameter override, or a broader redesign, because the required review often depends on the model’s purpose, methodology, and the frequency and scope of its changes. If you are wondering, “How do we keep model change logs useful instead of bureaucratic?”, the answer is to write them for the next reviewer, not for the filing cabinet. The record should make it easy to follow the path from the original issue to the final decision.
Approvals matter because model governance should not ask the same people to build the change and bless it alone. The guidance stresses clear roles and responsibilities, well-defined accountability, and effective challenge from objective experts with enough independence and influence to effect change; it also warns against conflicts of interest between development and validation groups. Internal audit, when used, should evaluate whether the framework is effective rather than duplicate development or validation work. In practice, that means the approval chain should show who challenged the change, who signed off, and whether the approvers had the right independence for the risk involved.
Some changes are routine, but others are large enough to reset the whole review process. The interagency guidance says validation timing and frequency vary with model purpose, methodology, and the frequency and scope of model changes, and it notes that validation generally happens before first use unless urgent business needs force a different sequence. In some regimes, material changes can also trigger supervisor notice or prior written approval; for example, OCC guidance on advanced approaches model changes describes notification expectations, and the Federal Reserve’s internal models approach requires prior written approval for qualifying use. That is why the approval record should never be treated as a formality.
A good approval file tells the whole story in one place. It should show the business reason for the change, the test results that supported it, any residual limits or exceptions, and what monitoring will watch the change after release. If the model uses a vendor component, the record should also explain any custom adjustments, overlays, or justifications, because the guidance expects those changes to be documented, justified, and evaluated as part of validation. When the log captures both the evidence and the decision, it becomes much easier to defend the model later, especially when a reviewer wants to know whether the team changed the model itself or only the world around it.
Done well, change logs and approvals give us something far more valuable than a history lesson. They create a clean chain of custody for model risk management, so the next test, review, or remediation effort can start with confidence instead of guesswork. That kind of traceability is what lets a model governance program stay steady when the pressure rises.