Define Clear Evaluation Rubrics
When you first sit down to define evaluation rubrics, it can feel a little like trying to describe the taste of soup with a spreadsheet. You know when a model feels helpful, off-track, or unreliable, but those impressions are slippery unless you pin them to clear language. That is why strong evaluation rubrics matter so much in AI evaluation and machine learning testing: they turn a vague hunch into something we can inspect, compare, and improve.
The easiest way to begin is to ask a question that sounds simple but carries the whole weight of the work: how do you write evaluation criteria that two people, or two models, could apply in the same way? A good rubric answers that by naming the behavior you care about, the conditions under which you are judging it, and the difference between a weak result and a strong one. Instead of saying a response is “good,” you spell out what good means, such as being factually correct, complete enough for the task, and written in a tone that matches the user’s needs.
Clear evaluation rubrics work best when they describe one idea at a time. If a single score tries to cover accuracy, style, safety, and helpfulness all at once, it becomes hard to know what the model actually did well or poorly. So we separate the parts of the judgment, almost like checking the windows, engine, and brakes of a car instead of asking whether the whole vehicle feels fine. In practice, that means each criterion should focus on one observable thing, because observable details are much easier to review than broad impressions.
This is where many teams get stuck, because they write criteria that sound polished but remain too open to interpretation. Words like “clear,” “useful,” or “appropriate” are not wrong, but they need support. If we want a rubric to guide machine learning testing, we have to define what those words look like in the real world: does “clear” mean short sentences, no jargon, or a logical sequence of steps? Does “useful” mean it answers the question directly, includes the right level of detail, or avoids extra filler? The more concrete we are, the less room there is for guesswork.
A helpful rubric also gives reviewers a shared scale. That scale might be as simple as pass, partial, or fail, or it might use several levels that describe increasing quality. The important part is that each level has a meaning a person can apply without reading the model’s mind. This is one of the quiet strengths of evaluation rubrics: they make disagreement productive. When two reviewers score the same output differently, the rubric helps them uncover whether the problem is the model’s behavior or the wording of the criteria itself.
We also want the rubric to reflect the real risk of the task. A conversational assistant that offers a friendly summary does not need the same scrutiny as a system that helps with medical or financial decisions. In the first case, a small amount of ambiguity may be acceptable; in the second, even a tiny mistake can matter a great deal. That is why clear evaluation rubrics should match the stakes of the use case, the expectations of the user, and the kind of failure we most want to catch.
Once the criteria are written in plain language, we can test them against actual examples and see where they wobble. A rubric that feels obvious on paper may become confusing the moment it meets a messy, real-world response. That check is valuable, because it tells us whether our AI evaluation rules are sturdy enough to survive contact with the model output we actually see. As we refine them, we are not just grading answers; we are building a shared language that will make every later version easier to compare and improve.
Store Criteria in Git
Once your evaluation rubric starts working in the real world, the next question is where it should live so the whole team can trust it. For AI evaluation and machine learning testing, storing criteria in Git gives us a calm, traceable home for the rules we use to judge model behavior. Git is a version control system, which means it keeps a history of changes so we can see what changed, when it changed, and why. That matters because evaluation criteria are not static decorations; they are part of the testing process itself.
Think about what happens when criteria live in a shared document with no history. One person updates wording, another edits a score scale, and soon no one remembers which version was used for last week’s test run. With Git, that fog clears. You can ask, “What criteria did we use for this model release?” and answer it by checking the exact version of the file in the repository, which is the central project folder Git tracks over time. In machine learning testing, that kind of traceability is not a luxury; it is how we keep experiments reproducible.
The big advantage is that Git turns evaluation criteria into something we can review like code. A pull request, which is a request to merge changes into the main branch, lets teammates inspect new wording before it affects testing. That review step is especially useful when a small edit changes meaning in a big way, such as tightening what counts as a factual error or expanding what “helpful” should include. Instead of discovering the mismatch after a failed test cycle, we catch it while the rubric is still easy to adjust.
Storing criteria in Git also makes versioning feel natural. Each commit, which is a saved snapshot of changes, becomes a checkpoint in the story of your AI evaluation process. If a new rubric creates confusion or scores differently than expected, you can compare versions and see whether the problem came from the model or from the criteria itself. Have you ever wondered why the same output suddenly looks worse or better than it did last month? Git gives you a practical way to answer that question without guessing.
This approach becomes even more valuable when teams work across product, research, and engineering. A shared repository creates one source of truth for evaluation criteria, so everyone reads the same definitions instead of relying on memory or scattered notes. It also makes collaboration safer, because branches, which are parallel lines of work in Git, let people experiment with new rubric ideas without disrupting the stable version used in testing. We get room to improve the criteria while protecting the current workflow.
Good versioning also supports accountability. When criteria change, the commit history shows not only what changed but often who changed it and in what context. That record helps during audits, incident reviews, and model comparisons, especially when a system’s behavior affects users in meaningful ways. In other words, storing criteria in Git does more than organize files; it creates a paper trail for the judgment calls that shape your machine learning testing.
As the repository grows, you can also keep criteria close to the tests that use them. That might mean storing rubric files alongside evaluation scripts, sample prompts, and expected outputs, so the whole testing setup travels together. When the rubric, the tests, and the model version all move as a unit, it becomes much easier to reproduce a result later and much harder for accidental drift to sneak in. That is the quiet power of Git in AI evaluation: it turns evaluation criteria from a loose idea into a reliable part of the system we can inspect, share, and improve over time.
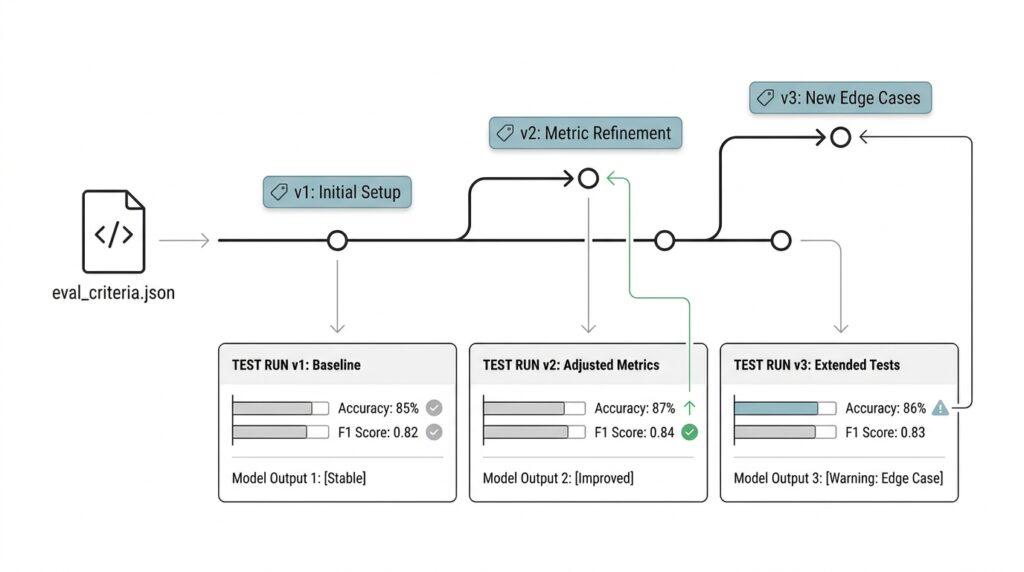
Tag Criterion Versions
Once your evaluation criteria live in Git, the next challenge is giving each meaningful snapshot a name you can actually remember. Commit hashes are exact, but they are also the kind of detail that disappears the moment a meeting starts or a test run fails. Tagging a criterion version solves that problem by turning a specific commit into a readable label, so when someone asks which rubric powered a model release, you can point to the tagged snapshot instead of hunting through history. In practice, versioned evaluation criteria make machine learning testing feel less like guesswork and more like checking a clearly marked map.
Git gives us two tag styles, and the difference matters here. A lightweight tag is only a name for an object, while an annotated tag stores the tagger’s name, the date, a message, and optionally a signature. Git’s own documentation treats annotated tags as the better fit for releases, while lightweight tags are more like temporary labels, which is why annotated tags usually fit evaluation criteria better. If we name the tag something plain and durable, like criteria-v3 or rubric-2026-06-09, we create a marker that feels as stable as the rules it represents.
The real skill is knowing when a new tag is worth creating. If you only fixed wording, spelling, or formatting, the behavior of the rubric may not have changed at all, so a new version would add noise without adding clarity. If you changed the meaning of a score, tightened a safety rule, or expanded what counts as a correct answer, that is a real shift in evaluation criteria and deserves a fresh version. That simple habit keeps the tag trail readable, because each tag starts to stand for a change in judgment rather than a change in punctuation.
This is also where branches and pull requests become part of the story. A pull request is a proposal to merge changes from one branch into another, which gives teammates a chance to review rubric edits before they affect shared testing. That review step matters because a small wording change can quietly reshape how people score the same model output. Once the team agrees, merge the branch and tag the resulting commit, so the repository shows both the review point and the released version of the criteria.
Why does this matter so much when results start to look strange? Because tagged criteria make comparison possible without detective work. Git records changes over time and lets you recall specific versions later, so if a model looked stronger in May and weaker in June, you can compare the tagged rubric commits and see whether the model changed, the criteria changed, or both changed together. That kind of traceability is what turns versioned evaluation criteria into a practical tool for reproducible machine learning testing instead of a tidy folder full of files.
A small naming convention goes a long way here. Keep the tag name short, consistent, and obvious to the whole team, then store the tagged rubric alongside the tests and sample prompts that depend on it. When the criteria version, the test suite, and the model snapshot travel together, you can recreate the same evaluation later without relying on memory or side notes. That is the quiet payoff of tagging criterion versions in Git: you give your judgment calls a stable address, and the next round of testing has a clear place to start.
Run Evals in CI
Now that your evaluation criteria have a home in Git and a clear version tag, the next move is to let them work for you automatically. This is where evaluation criteria in CI become powerful: CI, or continuous integration, is the practice of running checks every time code changes so problems show up early instead of after a release. If you have ever asked, “How do I run AI evals in CI without slowing everything down?” the answer starts with treating evaluations like any other test that guards the quality of your machine learning system.
The easiest way to picture this is to imagine a careful checkpoint at the edge of your pipeline. Every time someone opens a pull request or pushes a commit, the system grabs the tagged rubric version, runs the relevant evals, and compares the results against the expected threshold. That might sound formal, but the idea is familiar: we are asking, before this change moves forward, does the model still behave the way our criteria say it should? By placing AI evaluation inside CI, we turn the rubric from a document people remember into a live test that keeps watch for us.
This matters because model behavior can shift in small, sneaky ways. A prompt change, a dependency update, or a new retrieval step can make outputs feel slightly better in one area while quietly breaking another. When CI runs machine learning testing automatically, it gives you a fast signal about whether the change improved the system or only changed its shape. Instead of waiting for a manual review later in the week, you see the result while the code is still fresh in your mind and easy to fix.
A good CI setup usually starts with a smaller set of evals that run quickly and reliably. These are your smoke tests, which are short checks designed to catch obvious problems before you spend more time on deeper analysis. Once those pass, you can run a fuller evaluation suite on a schedule or in a heavier pipeline stage. That balance keeps the feedback loop tight, which is the whole point of CI: we want useful answers fast, not perfect answers too late.
The versioned rubric from the earlier step becomes especially important here. When the pipeline runs, it should point to a specific criterion tag so the test result is tied to an exact judgment rule, not whatever happens to be in the main branch that day. That makes evaluation criteria in CI reproducible, because you can rerun the same checks later and know the meaning of the score has not drifted. If a test fails, you can ask a much better question: did the model change, or did the evaluation rule change?
Good CI also helps teams decide what should block a merge and what should only warn. Some failures are red lights, like a safety regression or a clear factual error rate increase. Other signals may deserve attention without stopping progress, especially when the metric is noisy or the sample size is small. The important part is that the team agrees on the policy ahead of time, so the pipeline feels fair rather than surprising. That way, machine learning testing becomes a shared contract instead of a last-minute argument.
As the system grows, you can keep the CI job readable by separating the steps the same way you separated the rubric itself. One part fetches the model or build artifact, one part loads the tagged criteria, and one part runs the evals and reports the score. That structure makes it easier to debug when something breaks, because each step has a clear job and a clear result. And once that rhythm is in place, running evals in CI stops feeling like extra work and starts feeling like the natural way to protect every change before it reaches users.
Compare Results Across Releases
Once your rubric is versioned and your CI checks are running, the next question becomes the one everyone eventually asks: how do we compare results across releases without getting lost in the noise? This is where AI evaluation starts to feel less like a one-off scorecard and more like a moving story. Each release gives us a new chapter, and the job is to see whether the plot really improved or whether we just changed the lighting. If the rubric version, the test set, and the model release all have clear labels, we can compare results across releases with far more confidence.
The first thing we need is a stable baseline, which is just the earlier release we treat as our point of reference. Think of it like measuring new shoes against the pair you already trust, not against an empty shelf. When you compare AI evaluation results across releases, you are looking for change relative to that baseline, not just reading a raw score in isolation. A model that moves from 82 to 84 may look better, but that number only means something if the criteria, prompts, and sample set stayed consistent enough to make the comparison fair.
That is why versioned criteria matter so much here. If the rubric changes between release A and release B, then the score shift may reflect a new judgment rule instead of a real model improvement. In machine learning testing, we want to separate those two causes as cleanly as we can. So when a release looks stronger or weaker, we ask a careful question: did the model change, did the criteria change, or did both change together? That habit keeps AI evaluation honest and helps us avoid celebrating phantom progress.
A useful way to compare results across releases is to look at the same output in more than one light. One release may improve factual accuracy while slipping on tone, or it may answer faster but become less complete. When we score each criterion separately, the pattern becomes easier to read, almost like watching different instruments in the same song. The overall score matters, but the sub-scores tell us where the release is truly getting better and where it still needs attention. That is especially important when you are deciding whether a change is ready for users.
This is also where side-by-side review becomes valuable. Instead of staring at a spreadsheet of numbers, you place the outputs from two releases next to each other and ask what a human would notice first. Did the newer version answer the question more directly? Did it invent fewer details? Did it stay within the expected tone more reliably? Those concrete comparisons make it much easier to compare results across releases in a way that feels grounded, not abstract. Numbers tell us that something changed; examples help us understand what changed.
How do you compare AI evaluation results across releases when the scores bounce around from run to run? The answer is to look for patterns, not single points. A small dip on one test may be noise, but the same dip appearing across several runs or several prompts is a signal worth taking seriously. That is why release comparison works best when we collect a few consistent runs, keep the evaluation conditions steady, and watch for repeated shifts. Over time, we stop reacting to every wobble and start seeing the shape of the release itself.
Once the comparison is in place, the real value comes from making the results easy to explain. A release note should not just say that a model improved; it should say where it improved, where it regressed, and which rubric version produced that judgment. That kind of reporting gives product, research, and engineering teams a shared language for release decisions. It also makes future comparisons simpler, because the next release can be measured against a clear, documented history rather than a memory of what “good” used to mean.
When we compare results across releases this way, we are doing more than scoring models. We are building a timeline of evidence that shows how the system behaves as it evolves. That timeline becomes the bridge between testing and trust, because every new release has to answer to the same recorded standards. And once that rhythm is in place, release comparisons stop feeling like a debate and start feeling like a reliable part of the workflow.
Review Changes Before Merge
Once the rubric version is tagged, the next safeguard is a human pause before the change becomes the new standard. Pull requests exist for exactly that moment: they let collaborators propose changes, discuss them, and either approve them or ask for further edits before merge. For evaluation criteria, that means we do not let a new definition of “helpful,” “safe,” or “correct” slip into testing unnoticed. We review changes before merge so the rule we trust is the rule we actually meant to write.
How do you review changes before merge when the file only changed a few words? We open the pull request and read the diff, because GitHub shows the differences between the base branch and the compare branch right in the Files changed view. Git itself also treats diff as the tool for comparing commits, the working tree, and related snapshots. That matters for evaluation criteria because a tiny wording change can quietly shift the score, even when the file still looks tidy and familiar.
This is where the review becomes more than proofreading. When we look at evaluation criteria, we ask whether the edit changes the meaning of the rule, the edge cases it covers, or the kind of output it rewards. GitHub reviews support that kind of discussion by letting reviewers comment, approve, or request changes before the pull request is merged. In practice, we want to notice whether a new sentence clarifies the rubric or whether it opens a new loophole that machine learning testing will happily exploit later.
The best reviews often happen on real examples, not in the abstract. GitHub documents that you can check out a pull request locally to test and verify the changes before merging, which is especially useful when a rubric edit feels small but might affect a larger evaluation flow. That gives us a chance to run a sample output against the revised criteria and see whether the scoring still feels consistent. If the answer changes in a surprising way, we know the wording needs another pass before we merge.
We also want the review process to match the stakes of the change. GitHub supports required reviews, so repositories can demand a certain number of approving reviews before a pull request is allowed to merge. For AI evaluation and machine learning testing, that is a useful habit when a rubric change affects safety, compliance, or release gating, because it keeps one person’s wording choice from becoming the team’s new truth overnight. In other words, the more important the evaluation criteria, the more valuable it is to make review before merge non-optional.
That shared review also gives us a cleaner story later. If a release behaves differently, we can trace the exact pull request, read the review comments, compare the diff, and see which version of the rubric was approved. Git’s change history and GitHub’s review records work together here: one shows the snapshot, the other shows the conversation that led to it. So when we review changes before merge, we are not slowing the work down; we are making sure every future comparison starts from a version we can explain with confidence.