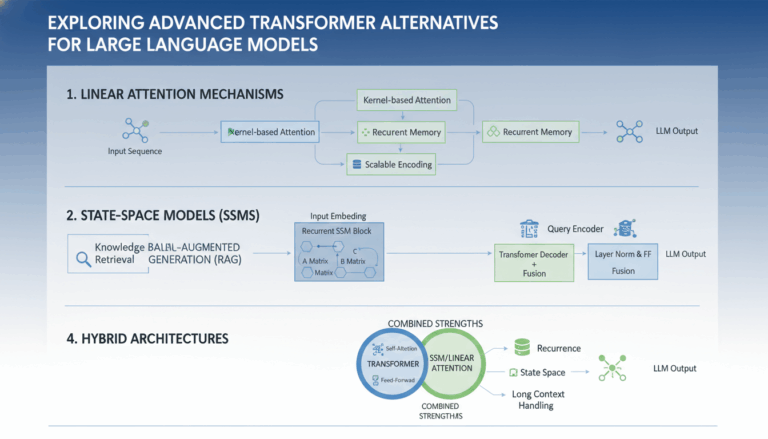
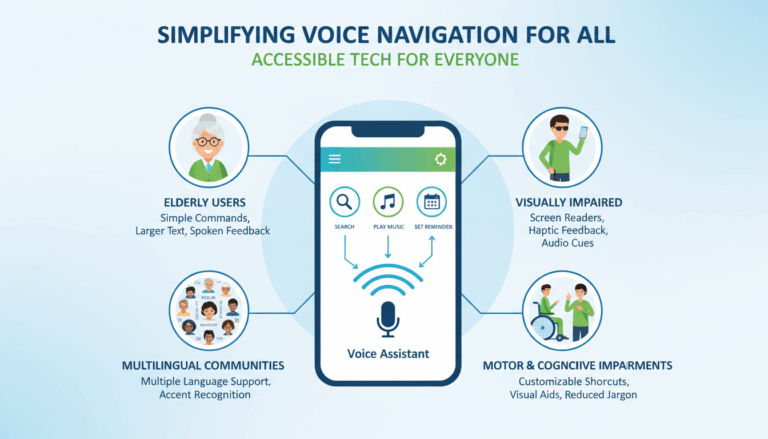
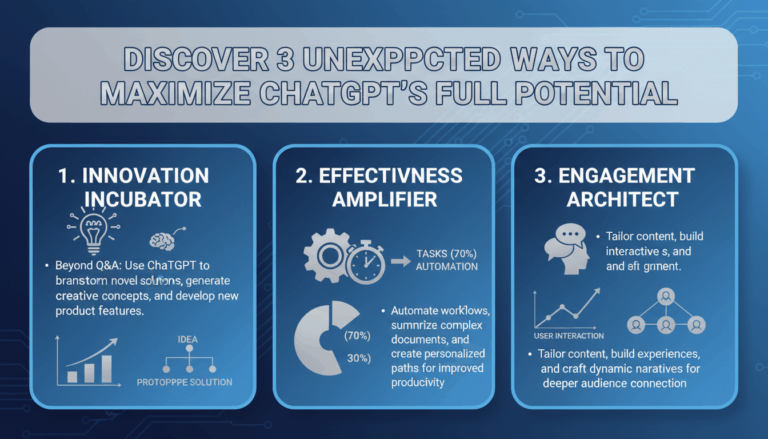
What Are Hallucinations in Large Language Models?
Hallucinations in the context of large language models (LLMs) refer to instances where these AI systems generate information that sounds plausible or authoritative but is factually incorrect, irrelevant, or even completely fabricated. These erroneous outputs can range from minor inaccuracies to entirely made-up facts, people, or events. Understanding why hallucinations occur is crucial for both developers and users aiming to utilize LLMs effectively and responsibly.
At their core, LLMs like GPT-4 and similar systems work by predicting the next most likely word in a sentence based on patterns identified in their vast training data. However, they do not possess true understanding or knowledge—they simply generate text that aligns statistically with their training. This statistical process, while powerful, can lead to errors, especially when the AI encounters ambiguous prompts or lacks sufficient context or training data on a topic.
Several factors contribute to hallucinations in LLMs:
- Gaps in Training Data: LLMs are only as reliable as the data they were trained on. When faced with subjects not well-covered in their training material, they might “fill in the blanks” with invented or estimated information. For more on this, see Stanford HAI’s explanation of LLM hallucination.
- Ambiguous Prompts: When a question is open-ended or vague, an LLM may make assumptions that don’t reflect reality, leading to speculation and inaccuracies.
- Overgeneralization: LLMs may inadvertently generalize from examples in their training data, producing statements that appear universally true but have significant exceptions.
- Artificial Confidence: The outputs are often presented in a confident tone, even when the information is fictional. This can mislead users into trusting incorrect details.
For example, consider asking an LLM for a quote from a novel using a paraphrased prompt. The model might generate a passage that sounds authentic but is not actually present in the book. Similarly, requesting a summary of research published after the model’s knowledge cutoff may yield a credible-sounding, but imaginary, article reference.
These complications make hallucinations a significant concern in applications like healthcare, legal research, and journalism, where factual accuracy is paramount. The AI community continues to study and seek solutions to this challenge. For in-depth research, this overview from arXiv provides a scholarly perspective on hallucination in generative models.
Understanding what hallucinations are and why they happen is the first step toward developing methods—such as the use of specialized tools—to mitigate their effects and responsibly harness the potential of LLMs.
Why Do LLM Hallucinations Happen?
Hallucinations in large language models (LLMs) are often the result of the model’s inherent limitations in understanding and generating information. At their core, LLMs are sophisticated statistical systems trained on vast datasets that include books, articles, and web pages. Despite their impressive abilities, they do not “know” facts in the way humans do. Instead, they generate responses by predicting the most likely sequence of words given the prompt and their training data. This predictive process can generate plausible-sounding but entirely fabricated or inaccurate information—a phenomenon commonly referred to as “hallucination.”
The root cause of these hallucinations is the model’s reliance on patterns in data rather than verified truth. For example, if an LLM is asked about a topic on which it has seen little or no reliable information, it may “fill in the gaps” by constructing a response based on similar but unrelated contexts. This is particularly noticeable when the model is prompted for specific numbers, dates, or unpublished details. Unlike humans, LLMs lack grounding or real-time access to the external world, which makes it impossible for them to cross-verify or fact-check their outputs autonomously.
Several factors contribute to LLM hallucinations:
- Training Data Limitations: LLMs are only as reliable as their training data. If the data contains inaccuracies, biases, or incomplete information, these issues can be reflected in the model’s output. For an in-depth look at AI dataset challenges, see this summary from Scientific American.
- Lack of Contextual Understanding: While LLMs excel at mimicking human language, they don’t truly understand the context or nuance behind the information. This can cause them to generate statements that seem reasonable but are ultimately incorrect. Learn more about AI and contextual reasoning from Google AI Blog.
- Ambiguous Prompts: When users provide vague or open-ended prompts, the model may “guess” what is being asked, resulting in fabricated answers. Careful prompt engineering can reduce, but not eliminate, hallucinations.
Consider a practical example: If prompted with “Who won the Nobel Prize in Physics in 2023?”, an LLM trained only up to 2021 data might confidently generate a plausible-sounding—but factually incorrect—response. This happens even though the model lacks access to post-2021 facts. Learn how LLMs are trained and why their knowledge is limited at Stanford AI Lab.
Hallucinations are thus a direct outcome of the model’s design and the constraints of its training. Understanding why they happen is the first step toward developing techniques—like tool augmentation and external verifiers—to reduce their frequency and improve trustworthiness.
The Role of Tools in Enhancing LLM Accuracy
Large Language Models (LLMs) have achieved impressive feats in language understanding and generation, but one notorious challenge remains: hallucinations, or the confident output of factually incorrect information. As LLMs become integrated into high-stakes applications, reducing these hallucinations is critical. A promising approach revolves around augmenting LLMs with tools—external systems and sources of truth—that can provide real-time, factual grounding.
When an LLM is empowered to use tools like search engines, databases, calculators, or code interpreters, its responses become anchored in up-to-date and verifiable information. For instance, OpenAI’s GPT-4 can access external APIs to fetch live data or perform calculations, dramatically improving its reliability compared to models limited to their training data alone. According to research from Semantic Scholar, tool augmentation demonstrated measurable reductions in hallucination rates because the model could fetch and cite updated facts.
1. Real-World Examples of Tool Usage
- Web Search Integration: An LLM can execute a web search when asked for population statistics or the latest weather, ensuring that it references the most current data. For instance, Microsoft’s Bing AI combines language generation with live web content, leading to more accurate answers (read more).
- Code Execution: When given a mathematical expression or data analysis task, models equipped with a Python interpreter tool can run code and return the computed result, reducing errors in complex reasoning tasks. This is illustrated in tools like Google Gemini, which display heightened analytical capabilities by invoking code execution tools for precision.
- Retrieval-Augmented Generation (RAG): This technique enables LLMs to pull relevant documents from curated databases or knowledge graphs in real time. As highlighted by IBM, pairing LLMs with retrieval tools not only reduces hallucinations but also cites sources, ushering transparency and trustworthiness.
2. Workflow: How LLM-Tool Synergy Functions
The process starts with the LLM analyzing the user’s query to decide if a tool invocation is necessary. For example:
- Query Analysis: On questions like “Who won the FIFA World Cup in 2022?” or “What’s the stock price of Tesla right now?”, the LLM identifies the need for current external information.
- Tool Invocation: The model interacts with an external tool—such as a database lookup, web scraper, or real-time API.
- Response Synthesis: Once the tool returns precise information, the LLM integrates this data into its response, often providing citations or context to increase transparency and trust.
- Fact Assurance: The final output undergoes additional verification steps if supported, such as consistency checks with multiple sources or referencing original data points, which further reduces the risk of hallucination.
3. The Future of LLM-Tool Collaboration
While LLMs alone can generate fluent text, integrating tools ensures that their outputs are not just plausible but also accurate and timely. As highlighted by experts at Stanford HAI, the trend of LLMs acting as orchestrators of external tools is paving the way for higher standards of factuality and reliability in conversational AI.
By systematically relying on trustworthy sources and automating fact retrieval, the partnership of LLMs and tools represents a pivotal advancement toward reducing hallucinations and building systems users can depend on. This synergy is not only boosting confidence in the results but also opening new doors for intelligent, responsible AI-powered solutions.
Types of Tools That Can Reduce LLM Hallucinations
Reducing hallucinations—where a language model generates information that is plausible but untrue—has become a critical challenge as large language models (LLMs) gain mainstream adoption. An effective strategy to address this is to equip LLMs with external tools that supplement their capabilities with verifiable data, specialized computations, or real-time knowledge. Let’s delve into some of the most impactful types of tools and how they help minimize hallucinations:
1. Search Engines and Up-to-Date Databases
One of the primary sources of hallucination is the LLM’s limited knowledge cutoff. By integrating real-time search tools, LLMs can fetch current and accurate information in response to user queries. For instance, an LLM connected to a search API like Bing Web Search or Google Custom Search can provide data grounded in recent events, verified statistics, or the latest scientific research.
How it works:
- User asks a question (e.g., “What were the most recent Nobel Prize winners in Physics?”)
- The LLM generates a search query and sends it to the connected search engine.
- Top results are analyzed and synthesized into an answer, with links to sources for fact-checking.
Research from arXiv demonstrates that retrieval-augmented generation (RAG) pipelines like these consistently reduce hallucinations compared to relying solely on the model’s internal knowledge.
2. Mathematical and Code Interpreter Tools
LLMs occasionally struggle with precise calculations, logic, or code generation, leading to erroneous or fabricated outputs. Integrating mathematical engines (such as Wolfram Alpha) or code execution environments lets the LLM delegate computations it’s uncertain about.
For example:
- User requests: “Calculate the eigenvalues of this matrix.”
- LLM parses the request and sends the calculation to the external tool.
- Accurate results are retrieved and neatly formatted in the response.
This step-wise invocation of tools for specialized tasks, as explored in academic studies, has greatly decreased the rate of numerical hallucinations in deployed LLM systems.
3. Fact-Checking and Verification APIs
Several fact-checking APIs enable LLMs to cross-verify claims before presenting them as factual statements. These tools use curated, reputable datasets and, in some cases, crowd-sourced truth judgments to mark or correct hallucinated facts. Examples include Full Fact’s automated checking and fact-checking datasets from the International Fact-Checking Network (IFCN).
Steps in action:
- Model generates an answer and flags uncertain statements.
- An API call checks these claims against authoritative sources.
- If any conflicts arise, the model revises the response or provides qualifiers and links to evidence.
This multi-step approach is essential for sensitive domains such as healthcare and law, as incorrect statements can have significant real-world consequences.
4. Structured Knowledge Graphs
Knowledge graphs such as Wikidata or Google Knowledge Graph compile structured, interconnected data on millions of topics. By querying these graphs, LLMs can retrieve contextually accurate and up-to-date facts instead of making potentially erroneous inferences.
Use cases:
- Providing concise, accurate biographical or geographical data.
- Clarifying relationships between concepts or entities (e.g., “Is Canada part of the Commonwealth?”)
Structured knowledge graphs act as a safeguard, offering a layer of reliability when presenting facts commonly prone to hallucination.
5. Domain-Specific Knowledge Systems
For specialized information needs—in medicine, finance, or engineering—the most effective hallucination-reducing tools are often expert-curated knowledge systems. These can include medical ontologies like UMLS, legal research databases, or scientific publication repositories such as PubMed and arXiv.
Typical flow:
- User queries a specialized topic (e.g., rare disease symptoms).
- LLM routes the query through the appropriate knowledge source.
- Accurate, source-backed responses are returned, significantly reducing risk.
By leveraging these domain-centric resources, LLMs can ensure that critical output is both consistent and verifiable, lowering the stakes of incorrect or misleading results.
By employing these tool integrations, LLMs become less susceptible to knowledge limitations and more capable of supporting their outputs with external, real-world verification. For a deeper dive into these emerging approaches, consider reading recent publications from experts at Google AI and Microsoft Research.
Retrieval-Augmented Generation: How External Data Sources Help
Large Language Models (LLMs), while impressively capable, often struggle with a phenomenon known as “hallucination”—where the AI generates responses that sound plausible but are factually incorrect or entirely made up. Retrieval-Augmented Generation (RAG) is a powerful approach to curbing this issue by allowing LLMs to tap into external, up-to-date, and reliable sources of information instead of relying solely on the information encoded in their parameters.
This process starts with the recognition that no single model can “know” everything, especially in rapidly evolving knowledge domains. RAG addresses this limitation by integrating a retrieval component with the generative model. Here’s how it works:
- Step 1: Query Understanding — The user’s prompt is first analyzed. The system breaks down the request to determine what additional information may be needed.
- Step 2: Retrieval of Relevant Documents — Instead of responding purely from memory, the model sends a search query to an external knowledge base—this could be a curated set of documents, a public search engine, or an up-to-date database (source: Meta AI research).
- Step 3: Information Synthesis — The retrieved documents are then fed to the language model, which synthesizes an answer using both the query and the new context from fresh documents. This ensures the response is not just plausible but also grounded in verifiable facts.
For example, in medical or legal domains—where stakes and the risk of hallucination are high—this approach can significantly enhance response accuracy. Imagine an LLM asked about the latest COVID-19 guidelines: with RAG, it fetches the most recent CDC updates and generates a summary. Without retrieval, it might generate outdated or incorrect advice based on training data from months or years earlier.
The benefits of this approach are underscored by research from institutions such as Stanford HAI, which highlights how combining search capabilities with generative models dramatically reduces the rate of hallucinated facts. Additionally, it enables “live” access to new knowledge, meaning users can get answers rooted in information that did not exist during the model’s initial training phase.
The integration of external sources aligns AI-generated content closer to journalistic standards of accuracy and citation. For users, this means more dependable answers and, crucially, references that can be independently verified—an important feature for research, journalism, and education. For developers and organizations, it means easier compliance in regulated industries, as responses can be traced back to specific documents.
As RAG technology continues to evolve, we can expect even tighter coupling between LLMs and domain-specific knowledge repositories, further reducing hallucinations and expanding the practical utility of AI in complex environments. For more technical foundations and ongoing developments in this area, consider reviewing the comprehensive resources provided by arXiv and DeepLearning.AI.
Real-Time Web Search Integration for Fact-Checking
One of the most effective ways to minimize hallucinations in Large Language Models (LLMs) is by integrating real-time web search capabilities directly into their workflow. Hallucinations—confident statements by LLMs that are factually incorrect or unsubstantiated—often stem from outdated, incomplete, or biased training data. By allowing an LLM to access real-time information, developers can equip models with up-to-date facts and corroborate the claims they generate.
This approach is quickly gaining traction in industries where factual accuracy is paramount. Here’s how real-time web search integration advances fact-checking in LLM-generated content, illustrated with steps, best practices, and working examples:
How Does Real-Time Web Search Fact-Checking Work?
At its core, real-time web search integration involves allowing an LLM to issue internet search queries during a conversation or knowledge retrieval task. This results in:
- Dynamic Fact-Checking: The LLM identifies points of uncertainty or potential factual claims in its response and submits relevant queries to a trusted search engine or curated database.
- Result Synthesis: Retrieved web snippets, articles, or datasets are then incorporated to refine, amend, or even overwrite the LLM’s original answer, reducing reliance on potentially outdated training data.
This technique not only enhances accuracy but also provides transparency—enabling LLMs to cite reputable external sources. For instance, models like Microsoft’s Bing-powered Copilot and OpenAI’s GPT-4 with browsing capabilities use similar architectures to supplement their responses with real-world facts (OpenAI Blog).
Step-by-Step: Integrating Real-Time Fact-Checking
- Trigger Identification: The LLM detects when a response requires a factual check—typically by recognizing user queries containing statistics, time-sensitive information, or proper nouns.
- Automated Query Formation: The model constructs effective search queries, optimizing for precise, unbiased results. Techniques from retrieval-augmented generation research guide this process.
- Result Parsing and Filtering: The model processes returned results, prioritizing those from authoritative sources (e.g., government, academic, and established media sites).
- Content Synthesis and Attribution: Extracted knowledge is blended into the response, ideally with inline citations or links back to source material for user transparency.
Examples of Enhanced Output
Consider a user querying, “What are the current COVID-19 travel restrictions for France?” A conventional LLM trained before 2023 may provide outdated information. However, an LLM with real-time search integration can retrieve official information from the French Ministry of Foreign Affairs or the CDC, offering users current regulations along with direct links for verification.
Key Considerations for Effective Implementation
- Quality of Sources: Always filter and rank factual responses from reputable institutions. Integrating a whitelist of domains, such as NIH, BBC, and Google Scholar, can bolster reliability.
- Transparency and Trust: Displaying source URLs not only builds trust but invites users to perform independent verification—an essential practice in responsible AI deployment.
- User Feedback Loop: Incorporate feedback mechanisms to flag unhelpful or incorrect outputs, improving system performance over time.
With advances in retrieval-augmented generation, real-time web search is becoming a best-practice for reducing hallucinations and ensuring the trustworthiness of LLM-generated content. To learn more about the technical details and emerging trends, see the original RAG paper on arXiv and Forbes Tech Council’s overview on retrieval-augmented LLMs.
Using APIs and Knowledge Bases to Ground LLM Responses
One of the most promising approaches to reducing hallucinations in Large Language Models (LLMs) is to connect them with external APIs and curated knowledge bases. By grounding their responses in verified data sources, LLMs are able to provide accurate, up-to-date, and contextually relevant answers—even for complex or specialized queries. Let’s explore how this process works in detail, step by step.
1. How LLMs Leverage APIs for Factual Responses
APIs serve as bridges to real-time information, offering LLMs access to specialized databases, live news feeds, scientific literature, and much more. For example, instead of generating stock prices or weather forecasts from trained data (which may be outdated or incorrect), LLMs can call reliable APIs such as the Yahoo Finance API or Open-Meteo to retrieve the latest data on demand.
- Step 1: The LLM receives a user query requiring current or factual information.
- Step 2: The model determines which connected API is relevant for the query type (e.g., weather, finance, sports).
- Step 3: It formats an API call, sends the request, and receives structured data in response.
- Step 4: The LLM integrates this accurate data into its natural language output, minimizing hallucinations.
This process not only boosts accuracy, but also provides transparency—users can often be shown the data source, fostering trust.
2. Harnessing Knowledge Bases for Deep and Reliable Answers
Knowledge bases (KBs) like Wikidata, Britannica, and proprietary enterprise databases contain vast amounts of fact-checked and structured information. Modern LLMs can tap into these sources to answer questions that require expert knowledge, ensuring both depth and precision.
- Case Example: An LLM connected to PubMed for medical literature can produce medically sound answers by referencing current research studies, rather than speculating based on its training data alone.
- Step-by-Step:
- The LLM identifies keywords in the user’s question.
- It queries a knowledge base to retrieve relevant facts, dates, statistics, or studies.
- The extracted facts are delivered in natural language, with references or links to the sources for further validation.
For instance, Google’s research on using language models as knowledge bases highlights how this approach can reduce misinformation and improve confidence in AI-generated replies.
3. Real-World Implementations and Value
Prominent LLM-enabled tools like ChatGPT plugins and BloombergGPT incorporate real-time data feeds and knowledge base lookups, demonstrating the immense practical value of this technique. These integrations empower business users, researchers, and the public to ask nuanced questions and receive trustworthy answers, grounded in verifiable sources.
As the industry advances, API and KB integration is becoming a gold standard for deploying LLMs in sensitive domains—such as healthcare, law, and finance—where accuracy is paramount. For best practices and challenges in implementation, the ACL Paper on Document-Grounded Generative QA provides further reading.
By grounding AI responses in trusted data through external tools and references, we can dramatically reduce the risk of hallucinations and unlock the full potential of LLMs for reliable and robust real-world applications.
Best Practices for Tool-Enhanced Prompt Design
When incorporating external tools with Large Language Models (LLMs), the design of your prompts plays a pivotal role in reducing hallucinations and ensuring better answer reliability. Here are some best practices to consider, each enriched with practical steps and illustrative examples.
1. Precisely Define Tool Usage Scenarios
Ensure your prompts clearly communicate when and why a tool should be used. Ambiguous instructions often lead the LLM to improvise or make assumptions, increasing the risk of hallucination. For example, specify: “Use the calculator tool for all mathematical operations beyond simple arithmetic.” This precision restricts the model’s generative freedom to only scenarios where it is most accurate.
For further reading on prompt specificity, see OpenAI’s guide on Prompt Engineering.
2. Chain-of-Thought with Tool Invocation
Encourage step-by-step reasoning, guiding the LLM to explicitly call a tool at the appropriate step. For instance, structure the prompt as: “First, analyze the problem. If the data retrieval tool is necessary, deploy it. Then, summarize the findings.” This approach is rooted in the chain-of-thought prompting technique, which boosts transparency and reduces reliance on the LLM’s internal (and sometimes inaccurate) knowledge.
3. Validate and Incorporate Tool Outputs
Always instruct the LLM to cross-verify its own responses with the external tool’s output. For example:
- Step 1: Ask the LLM to retrieve the latest statistics using an up-to-date API or database tool.
- Step 2: Have it paraphrase or explain the result, ensuring the original tool output is referenced in the LLM’s final answer.
This workflow mirrors practices recommended by leading AI research labs, such as DeepMind’s work on LLMs as tools.
4. Provide Tool-Specific Prompts and Examples
Every tool has its quirks. The more context provided on how to interact with each tool, the less the model guesses. Craft tool-oriented templates and share concrete examples. For instance:
"When needing current exchange rates, use the 'Currency API' with the format: get_rate(USD, EUR). Afterwards, explain the result in plain language."
This level of detail helps eliminate ambiguity and supports consistent, fact-based responses.
5. Encourage Transparency and Self-Correction
Prompt the LLM to document which tool was used and why, in its own words. This not only increases answer traceability but also allows users to consciously assess the provided information. Example phrasing: “I used the medical database tool for drug interactions because the knowledge cut-off of my model may be outdated.” Guidance on model transparency can be found in academic discussions like the Stanford paper on Toolformer.
By thoughtfully integrating these best practices, you can significantly reduce LLM hallucinations, resulting in answers that are both more accurate and easier for users to trust. Leveraging tools isn’t just a technical solution—it’s a strategic enhancement of prompt design that elevates language models from creative wordsmiths to reliable digital assistants.
Challenges and Limitations of Tool-Assisted LLMs
While leveraging external tools such as search engines, calculators, and databases can significantly reduce hallucinations in large language models (LLMs), several challenges and limitations persist. Understanding these hurdles enhances our ability to deploy safer AI applications and set realistic expectations about their performance.
1. Tool Integration Complexity
Integrating LLMs with external tools is technically complex. Each tool—whether a search engine, API, or proprietary database—may require a unique interface and handling mechanism. This demands ongoing engineering effort to maintain compatibility as these tools evolve. For example, search APIs from providers like Google Search or Microsoft Bing frequently update their endpoints, pricing, or quota limits. As a result, a tool integrated today may break or behave unpredictably tomorrow, potentially undermining the LLM’s reliability.
2. Trust and Accuracy of External Tools
Outsourcing knowledge retrieval to external tools does not guarantee accuracy. These sources can contain outdated, incorrect, or biased information—problems well documented in Stanford University research on web data quality. When an LLM relies on a tool like a web search, it inherits any inaccuracies found in those sources, potentially propagating misinformation. Moreover, the model might select the top result regardless of its reliability unless carefully tuned to evaluate source credibility. For example, if a web page is SEO-optimized but factually incorrect, it may be cited by the LLM if extra safeguards aren’t in place.
3. Latency and User Experience
Incorporating external tools often increases response times. Each interaction with a tool involves outbound API requests, data retrieval, and sometimes additional processing. This latency can compromise the smooth, conversational experience users expect from LLM-based applications, particularly under heavy loads or with tools that have limited throughput. If a user asks, “What’s the current weather in London?”, waiting several seconds for the LLM to check a weather API—such as OpenWeatherMap—can feel disruptive, especially compared to a direct, instant response.
4. Context and Tool Usage Failures
LLMs can sometimes misuse or misunderstand when to call external tools, leading to incorrect outputs. For instance, if an LLM can access both a search engine and a calculator, it may call the wrong tool for a math problem phrased as a question (“What is 13 multiplied by 7?”) or fetch an answer from a low-quality webpage instead of performing the calculation. AI researchers have highlighted this issue in several studies, including papers published on arXiv. Designing robust prompt architectures or explicit tool-use instructions is non-trivial and an ongoing research challenge.
5. Data Privacy and Security Concerns
Sending user queries or sensitive data to external APIs raises privacy and security concerns. For instance, querying third-party services with identifiable information can run afoul of data protection regulations such as the General Data Protection Regulation (GDPR). Developers must implement strict safeguards, anonymization protocols, and user consent mechanisms to reduce risks.
6. Maintenance, Cost, and Accessibility
Over time, the ongoing need for technical maintenance—updating integrations, paying for API usage, and handling rate limits—can significantly increase costs and operational overhead. Tool-based approaches, while powerful, may lock users or applications into specific vendors, reducing overall accessibility or openness, especially if these tools require licensing or have financial barriers.
Despite these challenges, tool-assisted LLMs remain a promising avenue for improving factuality and utility. However, to maximize their effectiveness and safety, developers must proactively address each limitation with thoughtful design and continuous monitoring. For further insights into best practices and research developments, readers can consult resources at ACL Anthology and in specialist journals like ACM Transactions on Information Systems.
Future Directions in Combating LLM Hallucinations with Tools
As language models become more integrated into our daily workflows, combating hallucinations—unfounded or fabricated outputs—remains a central challenge. Looking ahead, a variety of emerging strategies and technologies are poised to make tool use even more effective in minimizing hallucinations. Below, we explore the most promising future directions and how they might reshape the landscape of reliable AI-driven communication.
Enhanced Integration with Real-Time Knowledge Bases
One of the most compelling advancements is the deeper integration of LLMs with continuously updated, authoritative knowledge bases. Instead of relying solely on their training data, LLMs will increasingly leverage APIs connected to trusted sources like Google Scholar for academic publications or PubMed for medical research. This enables real-time verification of facts and data, drastically reducing the likelihood of outdated or incorrect information making its way into responses.
- Example: A medical chatbot could query PubMed for peer-reviewed studies published in the last six months to support or refute claims, ensuring the latest evidence is considered.
- Step-by-step: When a user asks a question, the LLM checks its response against the latest information found via an API, harmonizing the answer and providing citations.
Multi-Tool Reasoning and Cross-Validation
Future LLMs will multiply checks against hallucinations by utilizing multiple tools simultaneously. This approach—sometimes called ensemble verification—has the model consult different types of external resources for cross-validation, such as calculators, code interpreters, web search modules, and domain-specific databases.
- Example: For a complex financial analysis, the LLM could use a calculator tool to check mathematical consistency, a stock database for current prices, and a news API for relevant economic events—correlating these sources to bolster accuracy.
- Step-by-step: The model generates its initial answer, then sequentially queries each tool to check for discrepancies or gaps. Only when all tools corroborate the response does the answer get delivered.
Transparent and Explainable Outputs
Transparency will become a hallmark of future LLM tool usage. Researchers are advancing techniques for models to “show their work,” providing inline citations or rationale for each factual claim. This not only fosters user trust but makes it easier to spot and correct errors.
- Example: When generating a summary of a legal case, the LLM might cite statutes from the Legal Information Institute for every step in its reasoning process.
- Step-by-step: After tool access, the model annotates each claim or data point with a direct link or reference, making sources clear for end users.
Adaptive Feedback Loops and Human-in-the-Loop Systems
Another significant trend is the integration of adaptive feedback systems, where human evaluators or users can flag hallucinations. The model then retrains or adjusts its tool-using behaviors accordingly. For instance, platforms may utilize crowd-sourced verification, as seen in projects like Wikipedia‘s editorial process, to further refine the reliability of automated outputs.
- Example: An educational chatbot might prompt teachers to flag dubious content, triggering an automated review and subsequent improvement in the model’s retrieval and verification mechanisms.
- Step-by-step: After presenting an answer, the platform collects user ratings or correction suggestions, which are then used to update both the toolset and model weights.
Continuous Tool Ecosystem Expansion
As new domains and data sources become relevant, the ecosystem of external tools available to LLMs will expand rapidly. This ongoing evolution includes specialized scientific calculators, live weather and geospatial databases, and more, as explored by the DeepMind and other advanced AI labs. Interoperable standards and modular architectures will allow LLMs to plug into new tools with minimal friction, fostering adaptability as information needs shift.
- Example: Environmental monitoring applications could have LLMs tap into live satellite feeds, providing up-to-the-minute insights on air quality or disaster response scenarios.
- Step-by-step: The model detects a user’s intent (“Is there a wildfire nearby?”) and invokes the relevant external data streams to construct the response.
The future of reducing LLM hallucinations is dynamic and complex, relying on ever more sophisticated tool use, transparency, and human feedback mechanisms. These evolving strategies promise not only to boost accuracy but also to elevate the reliability and trustworthiness of AI-powered systems for countless applications. For deeper insights into these developments, review the latest research from organizations such as OpenAI and Google AI Blog.