Understanding the Challenges of Bilingual Voice Recognition
Creating a bilingual voice assistant is an exciting yet highly complex endeavor, particularly when it comes to perfecting voice recognition for multiple languages. The first major challenge is phonetic diversity. Languages can vary widely in their sound systems. For example, Spanish employs rolled “r” sounds and open vowels, while English tends to have more diphthongs and abrupt consonant stops. Training a system to recognize and accurately differentiate these sounds, especially when pronounced by bilingual or non-native speakers, requires sophisticated acoustic modeling. Research from MIT demonstrates that even regional accents create considerable variability in voice recognition accuracy.
Another significant challenge is code-switching—where a speaker alternates between languages within a single sentence or conversation. In many bilingual environments, code-switching is a natural form of communication, yet it can quickly confuse voice recognition algorithms that expect input in only one language at a time. As highlighted by studies from the University of Cambridge, current voice assistants frequently stumble when confronted with such hybridized language use.
Vocabulary overlap and context sensitivity represent yet another layer of difficulty. Some words sound identical in both languages but have different meanings, such as “pie” meaning a dessert in English and “foot” in Spanish. Properly recognizing these words and understanding user intent demands sophisticated semantic modeling and the integration of contextual cues. Google AI researchers suggest that advanced contextual training and user profiling can help resolve these ambiguities, but significant development is still ongoing.
Lastly, there are technical and resource-oriented hurdles such as limited training data for certain bilingual or less commonly paired language combinations. While English-Spanish may have abundant datasets, training a voice assistant for Vietnamese-French or Tagalog-German will likely face a scarcity of quality voice samples. Open datasets like those provided by Linguistic Society of America and multilingual corpora are invaluable, yet they still have gaps that developers must bridge using data augmentation or synthetic data techniques.
Addressing these challenges involves a combination of approaches, such as employing neural network architectures optimized for multilingual learning, utilizing transfer learning from high-resource languages to low-resource ones, and continuously gathering more diverse voice samples from real users. Innovators and researchers are making strides, but achieving truly seamless bilingual voice recognition remains a frontier with both technical and linguistic complexity.
Key Technologies Behind Bilingual Voice Assistants
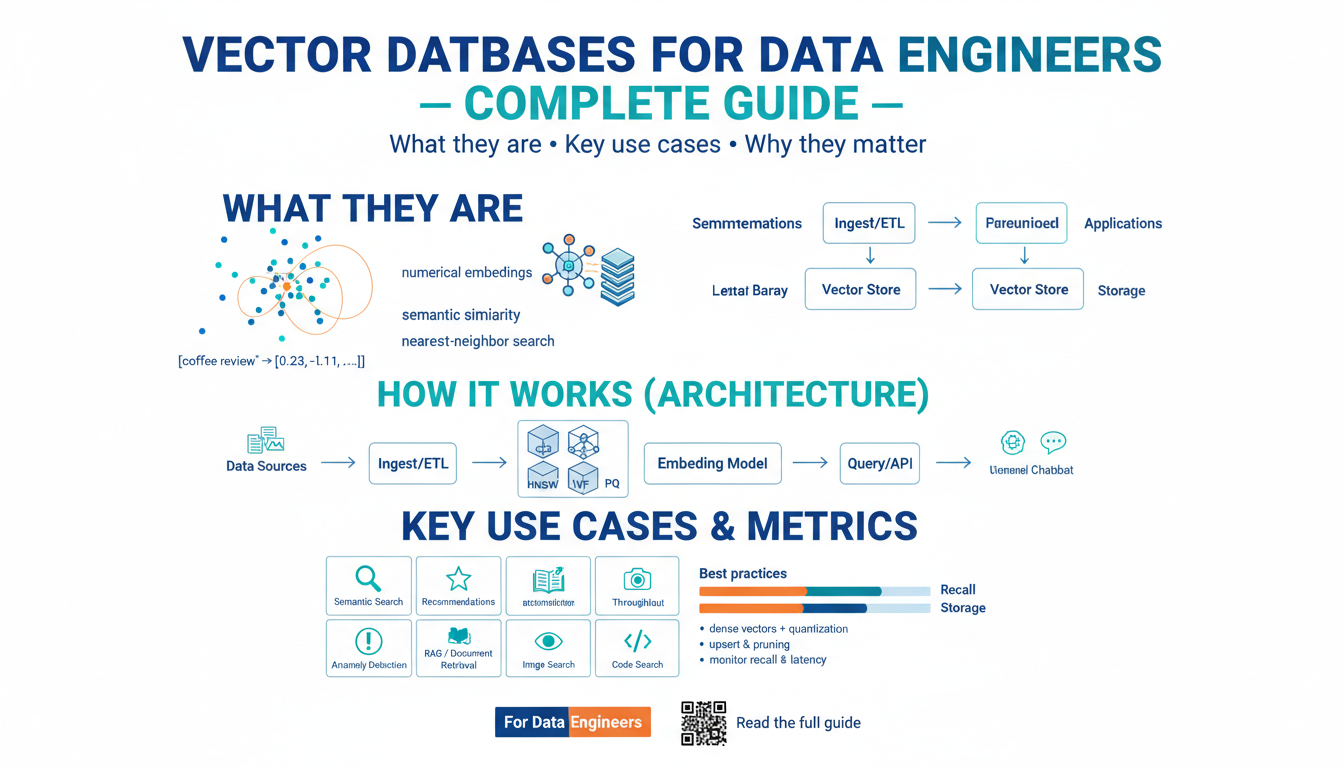
Bilingual voice assistants rely on a sophisticated mix of hardware and software technologies to understand, process, and interact in multiple languages. Below are the key components and innovations that empower these systems to function smoothly and accurately across linguistic boundaries.
Automatic Speech Recognition (ASR) for Multiple Languages
At the heart of any voice assistant lies Automatic Speech Recognition (ASR), the technology responsible for transcribing spoken language into text. For bilingual systems, ASR models must be trained on vast datasets encompassing diverse accents, dialects, and linguistic structures. Many companies use deep learning techniques—such as recurrent neural networks (RNNs) and transformers—to build robust ASR engines that can switch between languages seamlessly. Advances in ASR from leaders like Google and Microsoft underpin most modern voice assistants.
- Step 1: Capturing diverse voice data in both languages.
- Step 2: Training machine learning models to accurately map sounds to words for each language.
- Step 3: Integrating language identification systems that detect the spoken language and select the corresponding ASR model.
Natural Language Understanding (NLU) and Code-Switching
After speech is transcribed, Natural Language Understanding (NLU) models interpret the user’s intent. Bilingual voice assistants must excel at code-switching, which means understanding when users alternate between languages within a single conversation or even a sentence. Companies like Meta are researching robust models to handle code-switching efficiently.
- NLU models must be context-aware and flexible, handling subtle linguistic nuances and mixed-language phrases.
- Advanced algorithms use context clues and user profiles to decipher intent, maintaining conversation coherence across languages.
- Training data for NLU includes mixed-language dialogues to teach the model transitions and responses.
Text-to-Speech (TTS) and Natural Output in Multiple Languages
A bilingual voice assistant’s ability to speak naturally in both languages is crucial for user satisfaction. Text-to-Speech (TTS) engines use neural network models to generate lifelike speech, adjusting pronunciation, emotion, and intonation. Companies such as IBM Research have made major strides in creating multi-language synthesis that doesn’t sound robotic or forced.
- Voice talents provide linguistic data samples in each language for the system to mimic.
- Neural vocoders synthesize high-quality audio for natural, expressive speech in either language.
- Some assistants allow users to select preferred voices for each language, enhancing personalization.
Language Detection and Seamless Switching
One of the core challenges in bilingual voice assistants is instant, accurate language identification. Specialized algorithms analyze speech patterns, phonemes, and keywords to determine language before routing the request to the correct processing pipeline. For example, Mozilla’s DeepSpeech engages in language identification at the edge, minimizing delay and confusion.
- Real-time analytics ensure minimal lag when switching languages, critical for natural conversations.
- Some assistants offer manual override options for users to select a target language, reducing error rates.
- Sequential and contextual clues are used by algorithms to predict and adapt to upcoming language switches.
Continuous Improvements with AI and User Feedback
Finally, cutting-edge voice assistants continuously learn from user interactions. Developers collect anonymized feedback on misunderstood queries or awkward pronunciations, feeding this information back into both ASR and NLU models. Many platform providers, including Amazon Alexa, provide detailed frameworks for analytics, model retraining, and quality assurance.
- Active learning cycles help refine speech models for regional accents and slang.
- User-corrected responses boost accuracy for future interactions.
- Industry feedback loops standardize improvements across various assistant ecosystems.
Together, these technologies and processes empower bilingual voice assistants to bridge language barriers and create truly inclusive user experiences. For further exploration, consider visiting resources like the SpeechTEK Conference for the latest in voice technology innovation.
Designing for Code-Switching and Multilingual Contexts
Designing a voice assistant for bilingual users involves much more than simply toggling between two languages. One of the greatest challenges developers face is accommodating code-switching: the seamless alternation between languages within a conversation, a sentence, or even a single phrase. This phenomenon is particularly common in multilingual communities, where speakers might fluidly switch from English to Spanish, Hindi to English, or Mandarin to English based on context, intention, or even emotion.
Understanding Code-Switching and Multilingual Contexts
Before diving into the implementation, it’s important to grasp the nature and complexity of code-switching. Research in sociolinguistics highlights that code-switching is not random but governed by linguistic, social, and psychological factors. If a voice assistant is to be truly helpful, it must recognize not only what is being said but also how and why speakers switch codes. Reviewing academic literature such as this study on code-switching patterns (SAGE Journals) provides important context for developers.
Step 1: Data Collection and Annotation
The first challenge is gathering real-world audio data that actually reflects authentic code-switching. Bilingual speakers in natural settings should be recorded with appropriate privacy considerations. These recordings need careful annotation at the word or even morpheme level to indicate where switches between languages occur. Several initiatives, such as Microsoft’s code-switched speech corpora, set examples for building robust datasets.
Step 2: Training Language Models
Traditional speech recognition systems rely on monolingual training data, which often fails spectacularly with code-switched input. To handle bilingual interactions, you’ll need to train models explicitly on code-switched datasets. Large Language Models (LLMs) and end-to-end neural architectures have shown promising results when exposed to mixed-language input. For a thorough technical overview, researchers can refer to ACL Anthology’s work on multilingual and code-switching models.
Step 3: Contextual Understanding
Another key factor is maintaining context throughout a conversation. This means not only understanding the languages but tracking who is speaking, which domain is being discussed, and what the speaker’s intentions may be. For example, a user might ask, “Hey assistant, pon la alarma para las ocho de la mañana” (“set the alarm for eight in the morning”). The model must set the correct alarm and respond in the language most natural to the user. Integrating contextual AI, as discussed in Google AI’s work on multilingual context, can significantly enhance performance.
Step 4: User Experience Design
Beyond the technical aspects, user interface and experience design play crucial roles. The system should be flexible, letting users switch languages on the fly without forcing manual toggles. Additionally, prompts, confirmations, and feedback should adapt to the user’s likely language preference at each moment. This reduces friction and creates a more natural interaction. For inspiration on designing these systems, developers can examine the multilingual support guidelines from Google Assistant.
Examples In Action
Consider a voice assistant deployed in India, where Hindi and English weaving is common. A user might start a command in Hindi, “Mujhe SMS bhejna hai to Ravi,” and finish in English: “wish him happy birthday.” The ideal assistant not only parses both instructions but picks up the context, segments the task, and possibly offers the response, “Sending Ravi a message: Happy Birthday. Anything else?” in Hindi or English, based on the user’s choice.
In summary, designing for code-switching and multilingual contexts requires a multifaceted approach: deep linguistic understanding, rich and diverse training data, advanced language models, contextual awareness, and human-centered user experience design. Embracing these challenges is key to making voice assistants genuinely accessible and helpful for the world’s diverse language communities.
Best Practices for Data Collection and Training
Building a bilingual voice assistant involves unique challenges and opportunities, especially during the data collection and training phases. A well-planned approach ensures that the assistant understands and responds accurately in both languages, offering seamless interactions for users. Here are best practices to guide your journey, with linked resources for deeper learning.
1. Prioritize Diverse and Representative Data Collection
Start by assembling a dataset that reflects the variety within each language: different dialects, accents, slang, and typical real-world noise. The quality and diversity of your initial dataset significantly impact the eventual performance and inclusivity of your assistant. For example, Spanish spoken in Mexico can differ considerably from Spanish in Spain, both in pronunciation and vocabulary. To achieve this diversity:
- Source recordings from multiple regions and demographic groups.
- Include participants of varying ages, genders, and socioeconomic backgrounds.
- Collect samples in varied environments—public spaces, homes, vehicles—for more robust models.
For more insights on linguistic diversity and its influence on AI, check out this Brookings analysis.
2. Ensure High-Quality Transcriptions and Annotations
Accurate transcription is crucial for effective voice assistant training. Invest in native speakers and trained linguists to annotate data, ensuring grammatical and contextual correctness. Automated tools can assist, but human oversight remains essential, especially for languages with complex morphology or less standardized orthography.
- Develop clear annotation guidelines to maintain consistency among annotators.
- Perform regular audits and reviews to catch errors or inconsistencies.
- Use a feedback loop where annotators clarify ambiguous cases, refining your guidelines as needed.
Resources such as LREC conference papers provide advanced methodologies for multilingual annotation projects.
3. Address Code-Switching and Mixed Language Inputs
Many bilingual users naturally mix languages, switching mid-sentence or even within a single phrase. Your assistant must identify and process these instances. Collect and label data containing code-switching, and consider the sociolinguistic norms around when and why speakers blend languages.
- Create special collections of code-switching audio samples.
- Design test cases to evaluate the assistant’s performance on mixed language input.
The research article from ACL Anthology offers practical frameworks for handling code-switching in speech recognition systems.
4. Focus on Ethical Data Collection and Privacy
Respecting privacy is non-negotiable. Always inform participants about how their data will be used and obtain their informed consent. Follow ethical guidelines, anonymize recordings where possible, and comply with data protection regulations like the GDPR.
- Maintain transparent communication with data contributors.
- Remove or mask personally identifiable information during annotation and storage.
5. Iterative Model Training and Continuous Evaluation
Training is not a one-time process. Evaluate your model across multiple metrics—accuracy, latency, and bias—using fresh bilingual test sets as you expand and refine your datasets. Regularly update your model with new data to adapt to changing language trends and user needs, ensuring sustained relevance.
- Conduct error analysis to identify frequent misunderstandings or dialectal gaps.
- Encourage community feedback to uncover real-life usage issues.
Google’s AI research on multilingual systems provides valuable benchmarks and strategies—read more here.
By rigorously following these best practices, you’ll lay a strong foundation for a world-class bilingual voice assistant, equipping it to deliver equitable and effective conversational experiences across languages.
Ensuring Natural Language Understanding Across Languages
Creating a bilingual voice assistant that truly understands and responds naturally in multiple languages is both a technical and linguistic challenge. Achieving high-quality natural language understanding (NLU) requires more than simply translating keywords; it involves ensuring the assistant grasps context, intent, idiomatic expressions, and the nuances of how people speak differently in each language. Here’s how developers can approach this multifaceted task:
1. Leveraging Multilingual Data Sets
Effective bilingual NLU starts with diverse, high-quality linguistic data in both target languages. Training datasets must include various dialects, accents, and sentence constructions to help the assistant recognize ordinary and colloquial speech. Open-source resources such as OPUS and the European Language Resources Association (ELRA) offer multilingual text and speech corpora that are invaluable for NLU training. Incorporating user-generated, real-world speech patterns also improves contextual awareness.
2. Contextual Understanding and Intent Recognition
Context is crucial in any human interaction, especially when intent can shift subtly with language. Developers can utilize advanced natural language processing frameworks such as BERT (Bidirectional Encoder Representations from Transformers) or Hugging Face’s multilingual models, which are designed to discern meaning across languages. These models employ deep learning techniques to recognize intent—even when phrasing varies fundamentally between languages. For instance, the casual ways someone might ask for the weather in Spanish can be significantly different in tone and phrasing from English. NLU systems must map such requests to the same backend intent without losing the natural manner of the user’s query.
3. Handling Ambiguities and Non-Literal Language
Both literal translations and word-by-word matching fall short when dealing with idioms, slang, or cultural references. A phrase like “break a leg” in English means nothing like its literal translation in another language. The assistant must be trained to identify and paraphrase such expressions to maintain conversational authenticity. Developers should implement context-driven mapping and, where possible, collaborate with native speakers during testing phases to ensure that figurative language is interpreted correctly. The ACL Anthology features a wealth of research on handling linguistic ambiguity, which can be particularly instructive at this stage.
4. Real-Time Language Identification
For a bilingual system, language identification should occur at the utterance level. The assistant needs to determine not only which language is being spoken but also seamlessly switch between them if the user does. Fast and accurate language identification tools, such as Google’s Language Detection API (Google Cloud), are essential for this transitional capability. This flexibility allows the assistant to respond appropriately without lag or confusion, further enhancing the user experience.
5. Continuous Learning with User Feedback
Bilingual NLU development is never truly finished. Voice assistants must be equipped to learn from user corrections, failed interactions, and evolving slang or cultural shifts. Integrating feedback loops and retraining models periodically keeps the assistant up-to-date and responsive. The importance of live, user-specific training data is backed by industry research, such as that conducted at MIT and published in leading AI research journals.
Overall, ensuring natural language understanding across languages demands a thoughtful blend of technology, linguistic expertise, and ongoing adaptation. By utilizing robust datasets, advanced NLP models, expert consultation, and structured feedback, developers can create bilingual voice assistants that not only understand the words—but also the intentions, emotions, and cultural subtleties behind them.
Testing and Evaluating Bilingual Voice Assistants
Assessing the effectiveness of a bilingual voice assistant is a critical step in development, requiring a comprehensive and structured approach. This process ensures your assistant not only recognizes and processes two languages accurately, but can also deliver meaningful and contextually correct responses. Below, we’ll break down the key considerations, methodologies, and industry best practices for testing and evaluation.
Automated Speech Recognition (ASR) Performance
The cornerstone of any voice assistant is its ability to understand spoken input. For bilingual systems, this means testing the accuracy of Automatic Speech Recognition (ASR) in both languages. This involves:
- Text Transcription Accuracy: Use standardized benchmarks such as open speech-to-text datasets and compare the transcribed output to the ground truth. Measure metrics like Word Error Rate (WER) and Sentence Error Rate (SER) for both languages.
- Code-Switching Scenarios: Evaluate performance when users naturally switch languages mid-sentence—a common occurrence in bilingual contexts. Prepare mixed-language audio samples and examine how well the assistant distinguishes and transcribes each language.
- Accent and Dialect Coverage: Test with a variety of accents and dialects to ensure broad accessibility. Reference frameworks like NIST Speech Recognition Evaluation protocols to help design your test set.
Natural Language Understanding (NLU) Evaluation
The next stage is to ensure the assistant can interpret meaning, intent, and nuances across languages. This includes:
- Intent Classification: Create a diverse set of user queries in both languages and measure the assistant’s ability to assign the correct intent. Use evaluation datasets or create your own scenarios reflecting real-world usage.
- Entity Extraction: Test the system on its ability to identify key information (such as dates, names, or locations) from utterances in either language. Resources from ACL Anthology provide insights on best practices for multi-language NLU evaluation.
- Context Switching and Continuity: Check that the assistant can maintain conversational context when the user switches languages. For instance, if a user asks a question in Spanish and follows up in English, the assistant should retain context over the language boundary.
User Experience Testing
Usability is key to adoption and satisfaction. Human-centered testing includes:
- Beta Testing with Diverse Users: Recruit testers representing the target demographics and linguistic backgrounds. Observe them using the assistant in homes, offices, or public spaces to surface usability issues.
- Surveys and Feedback Loops: Gather structured feedback using surveys, interviews, and focus groups. Questions should address ease of use, error rates, and user confidence in the assistant’s abilities. Guides from Nielsen Norman Group can help you design effective UX testing protocols.
- Real-World Task Completion: Measure how well the assistant helps users accomplish common tasks, such as setting reminders or searching for information, in both languages.
Continuous Improvement
Testing is not a one-time event. Continuous evaluation, especially through real-world data collection and periodic updates, keeps the assistant responsive and accurate as usage evolves. Consider:
- Analytics and Error Logging: Track where breakdowns occur in understanding or responding. This data should inform model retraining and feature updates.
- Community Engagement: Encourage users to report issues and suggestions. Regularly update your assistant with improved features based on this feedback stream.
- Compliance and Privacy Checks: As you collect and process bilingual audio data, adhere to regulatory standards such as GDPR and Common Criteria to ensure data privacy and ethical use.
Rigorous, multi-layered testing strategies are crucial to delivering a voice assistant that meets the demands of bilingual users. By leveraging established benchmarks, user-centered design, and continuous feedback mechanisms, developers can create assistants that truly bridge linguistic gaps.