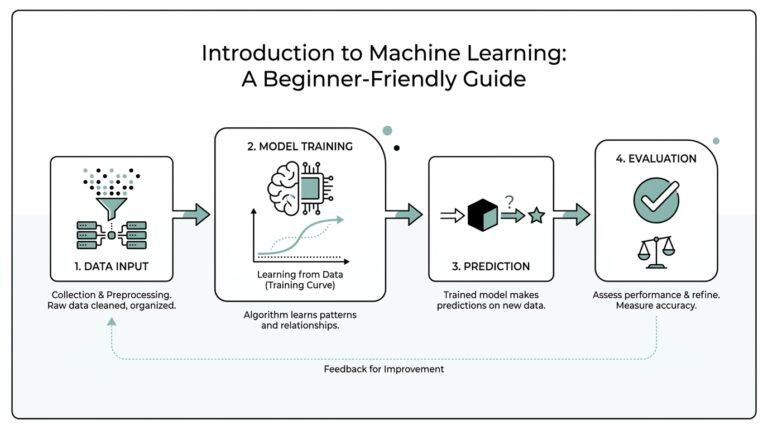
Introduction to Gradient Descent: Why Optimization Matters
Optimization is at the heart of nearly every modern achievement in machine learning and artificial intelligence. From training neural networks to fine-tuning recommender systems, the quest for better, faster, and more accurate models inevitably leads us to the mathematics of optimization. One of the most fundamental and widely-used methods in this domain is gradient descent. But why is optimization so crucial, and how does gradient descent serve as its backbone?
In any machine learning problem, we start with a model — a set of parameters that we want to adjust so our predictions match reality as closely as possible. Imagine you’re trying to fit a line to a scatter plot of data points. The process of tinkering with the slope and intercept until the line hugs the data as tightly as possible is an optimization problem. This process isn’t just confined to lines: more complex models have hundreds, thousands, or even millions of parameters needing adjustment.
The central idea behind optimization in machine learning is to minimize a cost function (or loss function), which quantifies how far off our model’s predictions are from the actual outcomes. The lower the cost, the better our model fits the data. This concept isn’t just theoretical; it affects everything from how accurately your favorite search engine finds answers, to how reliably a self-driving car navigates streets. For a deeper dive into cost functions and their significance, explore this guide by Geoffrey Hinton, one of the pioneers in machine learning.
Optimization matters not only for accuracy, but also for efficiency. Consider a scenario where a model’s parameters are not set optimally; the results might be misleading and computational resources wasted. In large-scale applications — such as Facebook’s AI infrastructure — efficient optimization directly translates to billions of calculations done faster or more reliably, affecting real-time user experiences worldwide.
So why is gradient descent such a favored tool for optimization? The answer lies in its elegance and scalability. Gradient descent is an algorithmic method that uses the gradient (or slope) of the loss function — with respect to the model’s parameters — to guide the search for the minimum. Imagine standing on a foggy hillside: you can’t see the whole landscape, but you can feel which direction slopes downward beneath your feet, so you step that way. With each step you take, you adjust your direction according to the steepest descent, moving from uncertainty (chaos) to a more orderly and optimal solution (convergence).
Understanding why optimization matters sets the stage for exploring how gradient descent fundamentally operates, and why it’s essential not just in theory, but in every practical corner of machine learning. To learn more about how optimization fuels breakthroughs in AI, you might enjoy this accessible overview from DeepAI.
The Mathematical Foundations of Gradient Descent
At its core, gradient descent is a powerful optimization algorithm grounded in calculus, specifically in the concept of gradients and directional movement along a function’s landscape. To truly appreciate why gradient descent is so effective at finding minima in complex systems, it’s vital to first unravel its underlying mathematics.
Imagine you are standing on a hilly terrain shrouded in fog, with visibility so limited that you can only sense the slope directly beneath your feet. The goal is to reach the lowest point in this landscape. The key insight here is that, at any given point, the fastest way downhill is in the direction of the steepest descent — mathematically, this direction is given by the negative of the gradient.
The gradient, as defined in multivariable calculus, is a vector of partial derivatives pointing in the direction of the greatest rate of increase of a function. When we seek to minimize a cost function (or loss function), the negative gradient shows us the quickest route to lower values. This is why at each step, gradient descent adjusts the position (the parameters we are optimizing) by moving in the direction opposite to the gradient.
In mathematical terms, let’s consider a function J(θ), which we wish to minimize. The update rule for gradient descent is expressed as:
- θ = θ – α * ∇J(θ)
Where:
- θ represents the parameters (e.g., weights in a neural network).
- α is the learning rate — a small scalar controlling how large a step is taken in each iteration.
- ∇J(θ) is the gradient of the cost function with respect to the parameters.
This fundamental rule is iteratively applied, inching the parameters closer to the function’s minimum. The learning rate α is critical: if it’s too large, the algorithm might miss the minimum or even diverge; if it’s too small, convergence is slow. For a deeper dive, consult the scholarly article on cost functions and gradient descent from Coursera’s acclaimed machine learning course.
Let’s ground this with an example. Suppose we have a simple quadratic cost function: J(θ) = θ². The gradient at any point θ is 2θ. According to the update rule, we subtract a fraction of the gradient from our current θ:
θ = θ – α * 2θ
With each iteration, θ moves closer to zero — the minimum of the function. This elegantly demonstrates how gradient descent methodically carves a path from arbitrary starting points down to optimal solutions.
On a higher level, these mathematical principles don’t just apply to toy functions, but are the foundation for training modern AI systems, optimizing financial models, and more. For an extensive treatment of gradient descent’s role in modern machine learning, see the comprehensive guide at Google Developers.
In summary, the mathematical foundations of gradient descent merge the elegance of calculus with pragmatic step-wise strategy, allowing us to traverse even the most convoluted data landscapes — and emerge, inevitably, at the point of convergence.
From Chaos: The Role of Initial Conditions and Learning Rate
At the heart of gradient descent lies a delicate dance between chaos and order, often dictated by two critical factors: the initial conditions and the learning rate. These two components can determine whether your optimization journey will be smooth and fruitful or endlessly turbulent and unproductive.
Initial Conditions: The Starting Point Determines the Journey
The story of gradient descent begins with the selection of initial values, often referred to as initial weights or initial parameters. Picture a vast mountainous landscape—where you drop your ball (your starting point) will heavily influence the path it takes as it rolls down toward a valley (the minimum). Poor initial choices might trap your algorithm in a local minimum, far from the global minimum you actually want. Initializing too close to a saddle point or a plateau might result in painfully slow progress or convergence to suboptimal solutions.
Random initialization is widely used, but not all randomness is created equal. Techniques such as Xavier initialization and He initialization have been developed to address the pitfalls of poorly chosen starting points, especially in deep learning applications. These approaches help set the initial weights to values that make learning feasible by preventing the gradients from vanishing or exploding as they propagate through the network.
- Step 1: Randomly assign small values to parameters (weights and biases).
- Step 2: Optionally use data-driven approaches or established schemes (like Xavier or He) for better starts.
- Example: In training a neural network, careful initialization can mean faster convergence and better accuracy, as demonstrated in practical studies and research papers (Stanford CS231n).
Learning Rate: The Speed of Descent
The learning rate acts as the gas pedal in gradient descent—it determines how big each update step will be in the search for a minimum. Set the learning rate too high, and your parameters might overshoot the valley, bouncing chaotically between peaks and valleys without settling down. Set it too low, and the journey can become agonizingly slow, with minuscule steps barely making progress.
Finding the right learning rate is a challenge that requires experimentation and intuition. In practice, strategies like learning rate scheduling or adaptive optimizers (e.g., Adam, RMSProp) dynamically adjust the learning rate based on feedback from the optimization process, leading to faster and more stable convergence.
- Step 1: Choose an initial learning rate, often starting with a small positive value (e.g., 0.01).
- Step 2: Monitor loss progression—if the loss fails to decrease, decrease the learning rate; if it stagnates, consider increasing it.
- Example: In a Google ML Crash Course experiment, a poorly tuned learning rate led to erratic loss curves, while fine-tuning resulted in rapid and stable descent toward the minimum.
In summary, both your starting point and the pace of your learning have a dramatic impact on the effectiveness of gradient descent. By understanding and harnessing their roles, practitioners can transform what might seem like a chaotic search into a directed journey toward convergence.
Understanding Cost Functions and Gradients
Before diving deep into gradient descent, it’s crucial to build a solid understanding of cost functions and gradients. These two concepts form the mathematical backbone of the optimization process that powers so many machine learning algorithms.
Cost Functions: The Objective of Learning
At its core, a cost function (also known as a loss function or objective function) quantifies the error or discrepancy between the model’s predictions and the actual values. In supervised learning, this function lets us measure how well (or poorly) our model is performing. For example, in linear regression, the cost function is typically the Mean Squared Error (MSE):
J(θ) = (1/2m) Σ(ŷ - y)2
Here, ŷ represents the model’s predictions, y stands for the true values, and m denotes the number of samples. The goal is straightforward: minimize this cost function by adjusting the model parameters, θ, such that our predictions get as close as possible to reality. If you want to dig deeper into the various cost functions used across machine learning, Coursera’s Machine Learning course by Andrew Ng offers a foundational overview.
Gradients: The Direction of Improvement
If the cost function tells us how well our model is doing, the gradient tells us how to improve. In mathematical terms, a gradient computes the partial derivatives of the cost function with respect to each parameter. This gradient, which points in the direction of steepest ascent, helps reveal how the model’s parameters should change to reduce the cost the fastest. To visualize, imagine standing on the side of a mountain (the cost landscape) and wanting to get to the lowest valley (minimum cost). The gradient points you toward the direction of steepest climb, so to descend, you move in the opposite direction!
Here’s a simplified step-by-step example:
- Start with an initial guess for your model parameters.
- Calculate the model’s prediction and use the cost function to find the current error.
- Compute the gradient (the vector of derivatives of the cost with respect to each parameter).
- Update the parameters by moving them a little against the direction of the gradient.
- Repeat steps 2–4 until the cost function reaches its minimum (or stops improving significantly).
For an intuitive explanation of gradients and their importance, check out this visualization by 3Blue1Brown.
Common Pitfalls and Examples
It’s important to note that not all cost functions have just one minimum — some have several (i.e., local minima). Picture a bumpy landscape rather than a single valley. If you’re not careful with the learning rate or starting position, you might end up stuck in one of these smaller dips rather than finding the lowest possible point. For a real-life illustration, imagine fitting a line to a small set of points. If the cost function is calculated, and its gradient is too steep, adjusting by too large a step can overshoot the optimal solution, making convergence difficult.
For further exploration on cost functions and gradients, the Google Machine Learning Crash Course provides a hands-on introduction with interactive visualizations and practical exercises.
Step-by-Step: How Gradient Descent Iteratively Updates Parameters
Gradient descent is like a guided journey through a dynamic landscape, where each step is meticulously calculated to take our model closer to peak performance. Rather than simply leaping towards a goal, gradient descent iteratively adjusts model parameters—such as weights in a neural network—based on the current landscape defined by our loss or cost function. Here’s a detailed breakdown of how this powerful optimization algorithm operates step by step:
1. Initialize the Parameters
The process begins by setting initial values for all parameters. These can be random or based on some heuristic. It’s important to note that initialization can affect the speed and success of convergence; poor choices here can lead to longer training times or even prevent finding the best solution. For more on parameter initialization, visit Machine Learning Mastery.
2. Compute the Loss Function
With initial parameters in place, we feed data through our model to calculate the loss. The loss function quantifies how far the model’s predictions are from the actual targets. This function provides a numerical score representing the “cost” of the current state. For example, in linear regression, this could be the Mean Squared Error (MSE), as described in Google’s ML Crash Course.
3. Calculate the Gradient
The gradient is a vector of partial derivatives that points in the direction of steepest ascent of the loss function with respect to each parameter. In gradient descent, we’re interested in descending the loss landscape, so we move in the opposite direction. This calculation is the mathematical engine powering each update, using calculus to determine how a small change to each parameter alters the loss. MIT’s notes on gradient descent offer a thorough explanation.
4. Update Parameters
With the gradient in hand, parameters are updated by subtracting a fraction of the gradient (scaled by the learning rate) from each parameter value:
θ = θ - α * ∇L(θ)where θ represents the parameters, α is the learning rate, and ∇L(θ) is the gradient. This step can be visualized as taking a cautious stride downhill, ensuring we’re continuously moving toward lower loss but not so quickly that we overshoot the minimum. Stanford’s CS231n course is an excellent resource for further details and visualizations.
5. Repeat Until Convergence
The parameter update step is repeated—often millions of times—until convergence is achieved, meaning further updates produce little or no reduction in loss. The process is akin to gradually honing in on the lowest point in a hilly landscape, where the precise path taken depends on factors like the learning rate and the complexity of the loss surface.
Example: Linear Regression
Consider a simple linear regression problem. We initialize the weights (let’s say w and b for slope and intercept). For each data point, we calculate the prediction, evaluate the loss (e.g., squared error), compute gradients with respect to w and b, and update these parameters. Over time, the line becomes a better fit for the data, demonstrating the power of iteration in gradient descent.
Common Pitfalls and How to Avoid Them
- Learning Rate Too High: Updates might overshoot the minimum, causing divergence. For guidelines, check out DeepLearning.AI’s guide.
- Learning Rate Too Low: The process becomes painfully slow and may get stuck in a suboptimal point.
- Local Minima and Saddle Points: Complex loss surfaces can have many local minima, but techniques like momentum or adaptive learning rates (see Sebastian Ruder’s optimization overview) help circumvent these issues.
By iteratively adjusting parameters in response to the loss landscape, gradient descent brings mathematical rigor and predictability to an inherently chaotic search for optimal solutions, transforming randomness into learner-guided progress with every step.
Visualizing the Descent: Navigating the Loss Landscape
Imagine you’re dropped onto a vast, fog-covered landscape filled with hills and valleys. Without a map, your goal is to reach the lowest point, but your visibility is limited—you can only sense the slope beneath your feet. This is the essence of navigating the loss landscape while optimizing a machine learning model using gradient descent.
The loss landscape is a metaphor for the graph of the loss function, which measures the error between your model’s predictions and actual outcomes. Each point in this landscape corresponds to a specific set of parameters (weights and biases) of your model, and the height of the terrain at that point indicates the magnitude of the error. The ultimate aim is to find the lowest valley—the global minimum—where error is minimized across the training data.
To visualize this, consider a simple model with just two parameters. Plotting the loss against these parameters would yield a 3D surface. In higher dimensions, while visualizing becomes impossible, the conceptual analogy holds: the surface is rugged, full of peaks (local maxima), valleys (local minima), and sometimes flat plains (saddle points). You can explore interactive demonstrations of this concept, such as the one provided by ML4A’s Backpropagation Guide.
Gradient descent works by repeatedly calculating the gradient (the vector of partial derivatives) at the current position. The gradient points in the direction of steepest ascent, so to minimize the loss we instead move in the opposite direction—it’s as if you’re standing on a slope and taking a cautious step downhill. The Google Machine Learning Crash Course provides a step-by-step walk-through of this process with helpful visuals.
- Step 1: Initialization – Start at a random point in parameter space. This could be anywhere on the loss landscape.
- Step 2: Compute Gradient – Calculate the slope of the loss function with respect to each parameter. This tells you how the loss will change if you nudge each parameter.
- Step 3: Update Parameters – Adjust parameters in the opposite direction of the gradient, scaled by a learning rate, which determines the size of each step. Towards Data Science explains different step sizes and their tradeoffs.
- Step 4: Repeat – Continue this process iteratively, following the series of descending slopes toward a minimum.
Throughout this journey, visualizations can help demystify what’s happening under the hood. Animations of the descent, like those found on 3Blue1Brown’s Gradient Descent series, demonstrate how choosing a correct learning rate ensures the path is smooth and convergent, while overly large steps cause overshooting and erratic wandering across the landscape.
In practical machine learning problems, landscapes are high-dimensional and incredibly complex. Yet, the intuition remains: gradient descent navigates this chaos by continuously seeking lower ground in the quest for optimal model performance. Next time you train a model, picture this unseen descent—slow, methodical, and guided only by the gradient underfoot—toward the landscape’s lowest point.