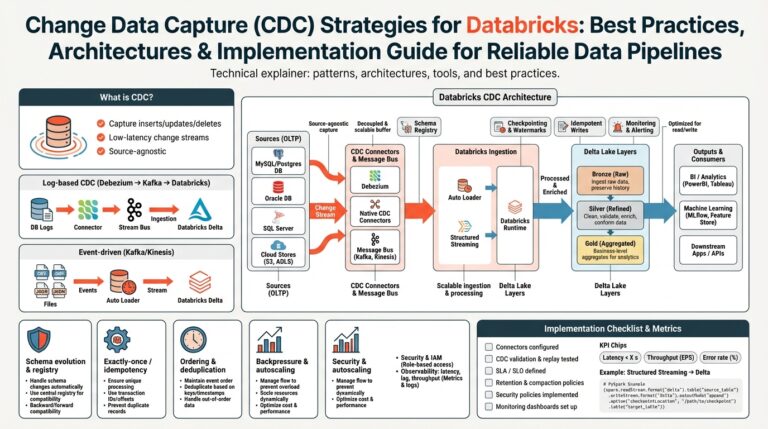
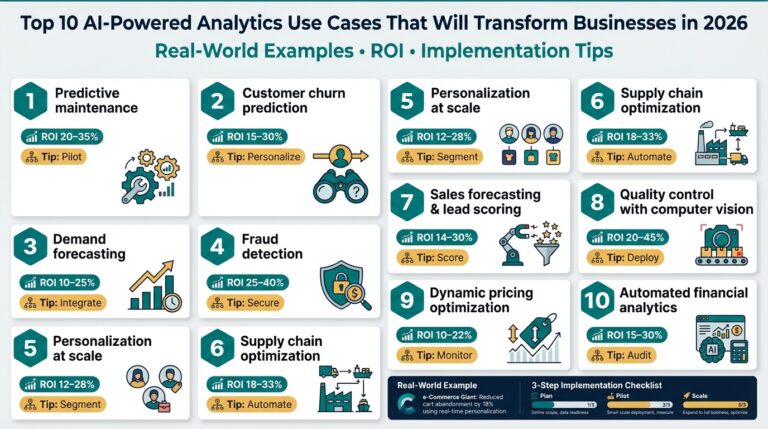
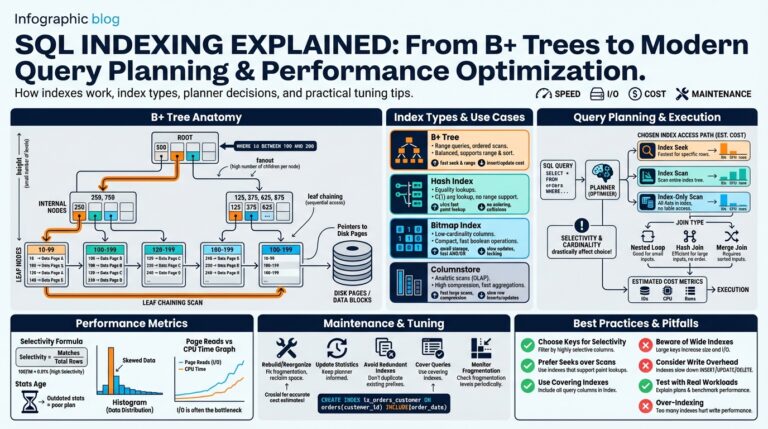
Introduction to Ollama and Large Language Models
Large language models (LLMs) have revolutionized the field of artificial intelligence by enabling machines to understand and generate human-like text. These models, such as GPT (Generative Pre-trained Transformer), are capable of performing a wide range of tasks, from language translation to creative writing, and even coding assistance. However, the immense computational power required to run these models often presents a barrier for individuals or small organizations. This is where tools like Ollama come into play, allowing users to run these powerful models on local machines.
What are Large Language Models?
Large language models are neural networks that have been trained on vast datasets containing diverse language inputs. They are designed to predict the next word in a sentence, which allows them to generate coherent and context-aware text. The training of these models involves:
- Data Collection: Gathering large amounts of text data from books, websites, and other sources. This data forms the basis for training the model.
- Pre-Training: Using the collected data to train the model to understand language patterns and structures. This involves creating probabilistic mappings from input text to output text.
- Fine-Tuning: Adjusting the model’s parameters to specialize in specific tasks, such as translation or summarization.
Examples of large language models include OpenAI’s GPT-3, Google’s BERT, and Microsoft’s Turing-NLG. Each model has its strengths and applications, but they all share the common requirement of significant computational resources.
Understanding Ollama
Ollama is a tool designed to simplify the process of deploying and running large language models locally. It provides several key features and advantages:
- Local Deployment: By running models on local hardware, Ollama removes the need for costly cloud services and gives users more control over their data and resources.
- User-Friendly Interface: Intuitive interfaces and command-line tools make it accessible even to those with limited experience in machine learning or programming.
- Customizable Solutions: Ollama allows users to fine-tune models based on specific domain requirements, making it adaptable to various industries and applications.
Key Benefits of Using Ollama with LLMs
- Cost Efficiency: Avoid ongoing cloud service fees by utilizing existing hardware for computations.
- Privacy and Security: Keep sensitive data in-house, reducing potential exposure and compliance concerns.
- Customization: Tailor models specifically to your organization’s needs without third-party constraints.
Getting Started with Ollama
To leverage Ollama for local running of large language models, follow these steps:
-
Installation:
– Ensure your system meets the hardware requirements for running large models.
– Install Ollama through their official website or package manager. -
Configuration:
– Configure Ollama to recognize your local hardware specifications and optimize for available resources.
– Set up necessary dependencies and libraries required for specific models you intend to use. -
Model Deployment:
– Choose the model best suited for your task (e.g., GPT-3 for creative content, BERT for question answering).
– Use Ollama’s interface to deploy the chosen model, adjusting settings as needed.
Ollama bridges the gap between state-of-the-art A.I capabilities and accessible technology solutions, empowering users to harness the full potential of large language models without the need for extensive infrastructure investments. By understanding and utilizing these models locally, businesses and individuals can transform their workflows with efficient and adaptable tools.
Installing Ollama on Your Local Machine
System Requirements
Before proceeding with the installation, ensure your machine meets the necessary hardware and software prerequisites. This is crucial for optimal performance and avoids potential issues during the setup.
- Operating System: Most versions of Linux (Ubuntu 18.04 or later), macOS (10.14 Mojave or later), and Windows (10 and above) are supported.
- Processor: A multi-core CPU is recommended for handling intensive computations.
- RAM: At least 16GB of RAM, but 32GB is preferable for large model implementations.
- Disk Space: Ensure at least 20GB of free storage, as models and dependencies can take significant space.
- GPU: If using Ollama’s GPU acceleration, a compatible NVIDIA GPU with CUDA support is recommended.
Installing Prerequisites
Before installing Ollama, some dependencies must be set up on your local machine:
-
Python: Ollama requires Python (version 3.8 or later). You can check your version with the following command:
bash python --versionIf not installed, download from Python’s official website.
-
Package Manager: Install
pip(Python Package Installer) if it’s not already available:bash sudo apt install python3-pip # On Ubuntu brew install pip # On macOS -
CUDA Toolkit: For GPU support, ensure the CUDA toolkit is installed and properly configured. Installation guides are available on NVIDIA’s CUDA installation page.
Step-by-Step Installation
With prerequisites in place, you can proceed with the installation. Follow these steps:
-
Clone the Ollama Repository:
– Open your terminal and run the following command to clone the latest version from GitHub:bash git clone https://github.com/ollama/ollama.git -
Navigate to the Ollama Directory:
– Enter the directory containing the cloned repository:bash cd ollama -
Install Ollama:
– Use the package manager to install the necessary Python dependencies:bash pip install -r requirements.txt– Run the Ollama setup script:
bash python setup.py install -
Verify Installation:
– Confirm that Ollama has been installed successfully by checking its version:bash ollama --version– If installed correctly, this command will display the current version number.
Troubleshooting Installation Issues
- Permission Errors: If you run into permissions issues during installation, try executing the command with
sudo(Linux) or administrative privileges (Windows). - Dependency Conflicts: Conflicts might occur with different versions of libraries. Create a virtual environment to isolate dependencies:
bash python -m venv ollama_env source ollama_env/bin/activate
Post-Installation Configuration
Once installed, configure Ollama to optimize performance:
- Model Configuration: Use configuration files to specify model parameters suitable for your use case.
- Resource Management: Adjust resource allocation settings in Ollama’s configuration to make full use of your hardware capabilities.
For more specific customization and usage, consult the official Ollama documentation. This will provide deeper insights into optimizing Ollama for your computational environment and particular domain challenges.
Downloading and Running Pre-trained Models with Ollama
To effectively utilize Ollama for running pre-trained large language models, follow these detailed guidelines to ensure a smooth setup and execution.
Obtaining Pre-trained Models
Pre-trained models are a crucial resource as they come equipped with parameters informed by extensive learning processes. Here’s how you can download and prepare them for use with Ollama:
-
Identify the Suitable Model:
– Consider your specific application needs. For instance, GPT models are best for text generation, while BERT excels in understanding context and nuances in text.
– Research available models online to determine which fits your requirements, both in terms of capability and computational demand. -
Download from Trusted Sources:
– Access repositories like Hugging Face or TensorFlow Hub to find a wide selection of pre-trained models.
– Use the following command to download a model from Hugging Face:bash pip install transformers from transformers import AutoModel model = AutoModel.from_pretrained('model_name')– Ensure you have enough disk space to accommodate the model.
-
Ensure Compatibility:
– Verify that the chosen model is compatible with Ollama. Some models might require additional dependencies or specific configurations.
– Check the Ollama documentation for supported models and their requirements.
Setting Up Models in Ollama
Once you have downloaded the desired model, the next step involves setting it up for execution using Ollama:
-
Installation of Required Libraries:
– Make sure all necessary dependencies for the model are installed. Use the package manager to handle this efficiently:bash pip install -r requirements.txt -
Integration with Ollama:
– Navigate to the directory where Ollama is installed.
– Integrate the pre-trained model with Ollama by placing the model files in a designated folder as specified by the Ollama configuration.
– Update the configuration files to register the model with Ollama, specifying any model-specific parameters. -
Configure Runtime Environment:
– Adjust Ollama’s configuration settings to ensure optimal usage of your local system’s hardware.
– Configure memory allocation, processing threads, and GPU utilization if applicable.
– Use configuration scripts provided by Ollama to automate setup:bash ollama configure --model-path=/path/to/model
Running the Model Locally
Once setup is complete, you can proceed to run the model and enjoy the benefits of local inference capabilities:
-
Initialize the Model:
– Use the command-line interface or Ollama’s UI to start the model.
– Verify that the initialization is successful by checking logs for any error messages. -
Testing and Validation:
– Run a series of test inputs to validate the model’s performance.
– Adjust the input parameters to suit specific needs or improve model efficiency. -
Troubleshoot Common Issues:
– Compatibility Errors: Ensure all software dependencies are correctly installed.
– Performance Bottlenecks: Re-evaluate resource allocation to ensure efficient processing.
– Model Accuracy: If results are not as expected, consider further fine-tuning or selecting a more suitable pre-trained model.
By effectively downloading and executing pre-trained models with Ollama, users gain the powerful ability to perform complex tasks locally, harnessing the potential of large language models without reliance on external infrastructure. For further optimizations and advanced configurations, refer to the comprehensive Ollama documentation.
Customizing Models Using Modelfiles
Understanding Modelfiles
Modelfiles are configuration files that allow you to customize machine learning models, making them more flexible and tuned to your specific needs. These files act as blueprints for models, detailing various parameters, structures, and instructions that define how a model should behave. This customization is crucial when working with Ollama, as it enables users to optimize models for various specialized applications without altering the core code.
Benefits of Using Modelfiles
- Flexibility: Quickly adjust model parameters without modifying the source code.
- Reusability: Create templates that can be reused across different projects or scenarios.
- Efficiency: Streamline the deployment and running processes by predefining necessary model configurations.
- Adaptability: Easily adapt models for various tasks by changing specifications tailored to different datasets or objectives.
Creating a Modelfile
To create a modelfile, follow these detailed steps:
-
Identify Model Parameters:
– Determine the model parameters that are necessary to configure, such as learning rate, number of epochs, and batch size.
– Other parameters might include architecture definitions, optimizer settings, and checkpoint paths. -
Define Modelfile Structure:
– Typically, modelfiles are defined in YAML or JSON format for easy readability and editing.
– Here is a basic outline of a YAML modelfile:yaml model: name: "example_model" architecture: "transformer" parameters: learning_rate: 0.001 epochs: 10 batch_size: 32 optimizer: type: "adam" paths: checkpoint: "/path/to/checkpoints" -
Include Metadata:
– Add additional comments or metadata within the file for clarity, such as description, version, or author information.yaml # Model customization for text generation task # Author: Your Name # Version: 1.0.0
Integrating Modelfiles with Ollama
Once the modelfile is created, it’s essential to integrate it into your Ollama setup:
-
Place the Modelfile:
– Ensure that the modelfile is saved in a location that Ollama can access, often within the project directory or a designated configuration folder. -
Load the Modelfile:
– Modify the Ollama setup script or interface to load this modelfile during initialization:bash ollama load --config /path/to/your_modelfile.yaml -
Adjust Runtime Configuration:
– Confirm that the adjustments specified in the modelfile are applied during model execution. This may require reviewing log outputs or performing validation tests. -
Testing and Validation:
– Run a series of trials to ensure that the parameters specified in the modelfile perform as expected.
– Use monitoring tools or custom scripts to verify that all configurations have been correctly implemented.
Best Practices for Modelfiles
- Maintain Consistency: Use consistent naming conventions across different modelfiles to streamline integration and collaboration processes.
- Version Control: Manage different versions of modelfiles using version control systems like Git to track changes and revert if necessary.
- Documentation: Thoroughly document each section within the modelfile to aid yourself and others in understanding and utilizing its configurations.
- Validation: Regularly validate models after changes to ensure configurations align with performance objectives and project requirements.
By leveraging the power of modelfiles, users can effectively customize machine learning models, making them more aligned with their unique requirements. This approach not only enhances model performance but also accelerates the process of adapting models to new tasks and environments. Researchers and developers can thus maximize the benefits of running large language models locally with complete control over their configuration and execution environments.
Integrating Ollama with Python Applications
Integration Overview
Integrating Ollama with Python applications can greatly enhance the power and flexibility of your projects, enabling you to use large language models (LLMs) locally. This integration allows Python developers to leverage LLMs for various AI tasks such as natural language processing, text generation, and more using familiar libraries and frameworks.
Prerequisites
Before integrating Ollama with your Python application, ensure:
- Ollama Installation: Confirm Ollama is installed and configured on your machine. Refer to prior sections on installation if needed.
- Python Environment: Ensure a suitable Python environment with a version compatible with Ollama, ideally Python 3.8 or later.
- Dependencies: Install relevant Python libraries, such as
transformersandtorch, which may be required for model operations.
Installing Required Python Packages
Begin by installing the necessary Python packages that will allow Ollama to work with your applications effectively. Use pip to manage these installations:
pip install ollama
pip install transformers
pip install torch
Setting Up Ollama for Python
-
Initialize a Python Script:
– Create a new Python file or use an existing script where you plan to integrate the Ollama functionalities. -
Import Required Modules:
– Import Ollama’s API and any other libraries needed for interfacing with the language models.
python
from ollama import Ollama
from transformers import pipeline- Configure Ollama:
– Set up Ollama to recognize the desired models and configurations via your Python script.
– Define the model parameters and load the pre-trained model of choice.
python
ollama = Ollama()
model = ollama.load_model('path/to/your/model')- Creating a Processing Function:
– Write a function to handle input data, process requests, and return results using the capabilities of the language model.
python
def process_text(input_text):
response = model.generate_text(input_text)
return responseExample Integration
Here is an example of how you might integrate and use a large language model for a text summarization task:
# Import necessary modules
from ollama import Ollama
from transformers import pipeline
# Initialize Ollama and load a pre-trained model
ollama = Ollama()
summarizer = pipeline("summarization", model='model-name')
# Function to summarize text
def summarize_text(text):
summary = summarizer(text, max_length=50, min_length=25, do_sample=False)
return summary[0]['summary_text']
# Execute the summarization
input_text = "Ollama provides tools to leverage LLMs locally, allowing for processing...
print(summarize_text(input_text)) # Output: Summary text
Best Practices
- Exception Handling: Implement robust error handling mechanisms for network or processing errors.
- Parameter Tuning: Experiment with model parameters to optimize the performance of your Python application.
- Resource Management: Efficiently allocate system resources, especially if using GPU acceleration.
By integrating Ollama with Python applications, developers can harness the full potential of local LLM execution, facilitating tasks that range from generating creative content to performing complex data analyses. The seamless integration ensures that Python developers can easily incorporate advanced AI capabilities into their projects while maintaining the flexibility and convenience of running computations locally.