Introduction to Natural Language Processing (NLP)
Natural Language Processing (NLP) is an interdisciplinary field that combines linguistics, computer science, and artificial intelligence to facilitate communication between humans and computers using natural language. It encompasses a wide array of tasks, each aiming to enable computers to understand, interpret, and generate human language in a valuable way. With the rise of machine learning and deep learning, NLP has become increasingly sophisticated, making it an integral component in diverse applications such as chatbots, translation services, and sentiment analysis.
Historical Background and Evolution
Early NLP systems relied heavily on handcrafted rules, where linguists manually defined the logic required for language processing. These rule-based systems had significant limitations due to the complexity and variability inherent in natural language. As computational power and data availability increased, statistical methods became prevalent, leveraging large corpora to develop probabilistic models.
A significant breakthrough came with the advent of machine learning, which automated model training by discovering patterns within data. By utilizing algorithms such as Hidden Markov Models (HMMs) and Support Vector Machines (SVMs), NLP tasks were addressed with improved efficiency and accuracy. The development of neural networks propelled the field further, offering new mechanisms to capture language semantics. Today, architectures like transformers have revolutionized NLP, setting new benchmarks in understanding and generating human language.
Key Components
-
Tokenization: This is the fundamental process of splitting text into smaller units called tokens, which could be words, phrases, or subwords. Tokenization forms the basis for further processing and analysis. Modern tokenizers, such as those used in transformer models, incorporate subword tokenization techniques to handle rare and out-of-vocabulary words efficiently.
-
Part-of-Speech Tagging: Involves identifying the role each word plays within a sentence, such as nouns, verbs, adjectives, etc. This information can be used to infer syntactic and semantic meaning.
-
Dependency Parsing: Maps out grammatical structures by identifying relationships between “head” words and words that modify them, aiding in understanding nuances of sentence structure.
-
Named Entity Recognition (NER): Identifies and classifies key entities in the text into predefined categories such as people, organizations, locations, among others. NER is crucial for extracting significant information from unstructured data.
-
Sentiment Analysis: Evaluates and assigns sentiment scores to text segments, gauging emotional tones such as positive, negative, or neutral, widely used in customer feedback and social media monitoring.
Transformers: The State-of-the-Art
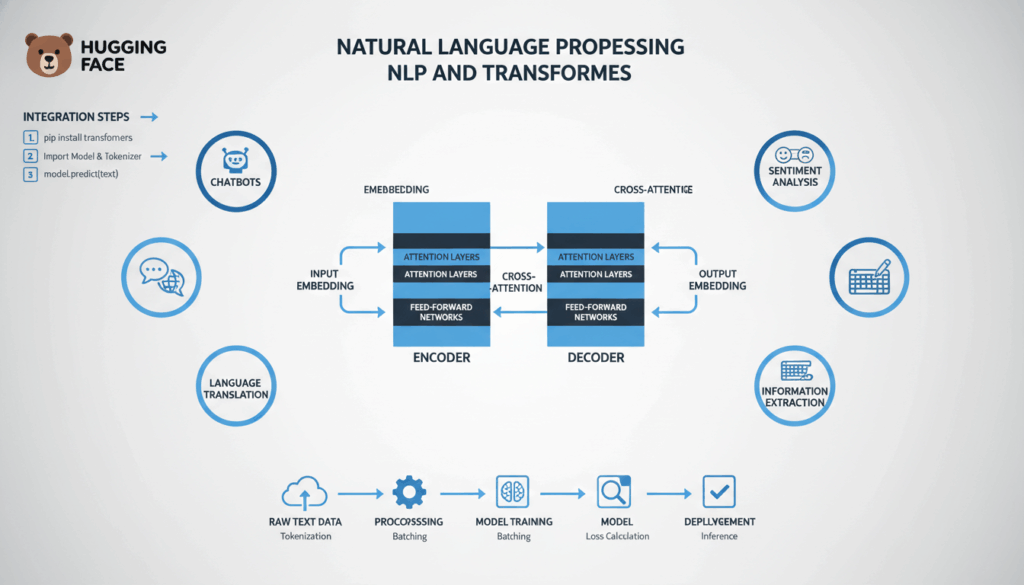
Transformers have fundamentally changed the landscape of NLP. Introduced with the paper “Attention Is All You Need,” the transformer architecture utilizes self-attention mechanisms to weigh the relevance of different words irrespective of their position in a sequence. This ability to process entire sentences in parallel, rather than sequentially, enhances performance for complex NLP tasks.
Successive models like BERT (Bidirectional Encoder Representations from Transformers) demonstrate the power of pre-training on massive text corpora, and subsequent fine-tuning for specific tasks (e.g., Q&A, classification). BERT’s bidirectional approach enables context understanding from both preceding and succeeding words, unlike unidirectional predecessors, offering superior context awareness.
Real-World Applications and Impact
NLP technologies are omnipresent in today’s technology landscape, embedded in personal assistants (like Siri and Alexa), customer service bots, translation tools, and text analytics solutions. By continuously evolving through research and technological advancements, NLP not only enhances user interaction but also opens up realms for new services and efficiencies. As open-source libraries like Hugging Face democratize access to advanced NLP tools, individuals and organizations are empowered to incorporate cutting-edge solutions in their domains without extensive computational resources.
The rapid progress in NLP is driven by a virtuous cycle: as data accumulates and computing capabilities expand, models improve, fueling further innovation and applicability across numerous sectors.
Overview of Hugging Face and Transformers
In the rapidly growing field of Natural Language Processing (NLP), Hugging Face has emerged as a pivotal player, providing a highly-accessible interface for complex machine learning models, notably transformers. Hugging Face is renowned for democratizing access to sophisticated NLP models through its open-source library, Transformers, which simplifies the implementation of state-of-the-art architectures like BERT, GPT-2, and T5.
Hugging Face was initially founded as a chatbot company but quickly pivoted to focus on NLP models, leveraging the power of transformers. Its library, Transformers, contains both pre-trained models and tokenizers, covering over a hundred languages and tasks ranging from text classification to translation and beyond. This flexibility allows developers and researchers to utilize cutting-edge technologies with minimal computational overhead.
The key strength of Hugging Face lies in its ability to simplify the integration and adaptation of transformer models. For those new to machine learning, setting up a model is often daunting; however, Hugging Face minimizes this complexity by allowing users to access pre-trained models with just a few lines of code. These models can be easily fine-tuned for specific tasks, thanks to the library’s intuitive APIs.
To illustrate the workflow, consider a typical use case where a developer wishes to implement sentiment analysis using a transformer model. By leveraging Hugging Face, one can seamlessly load a pre-trained model like DistilBERT—a smaller, faster, yet still highly effective variant of BERT—and begin processing text almost immediately. The steps are straightforward:
-
Installation: Begin by installing the Transformers library using pip:
pip install transformers -
Model Loading: Load a pre-trained model and its corresponding tokenizer via Hugging Face’s API:
python from transformers import pipeline sentiment_pipeline = pipeline("sentiment-analysis") -
Text Analysis: Pass the desired text to the model to obtain predictions:
python result = sentiment_pipeline("I love using Hugging Face's library!") print(result)This simplicity empowers even those without extensive expertise in data science or machine learning to deploy robust NLP solutions.
Beyond simplifying access, Hugging Face drives innovation through its collaborative community. Researchers continually contribute to and enhance model functionalities, providing users with ever-improving tools. The Transformers library also supports dynamic model updates, ensuring that integrations keep pace with the latest research developments.
Moreover, Hugging Face plays a significant role in educational endeavors, providing comprehensive documentation and a plethora of tutorials to guide users through varying levels of complexity. The company’s commitment to bridging the knowledge gap in AI technology results in a rich ecosystem where both seasoned professionals and newcomers can thrive.
In summary, Hugging Face, with its transformative approach to NLP and commitment to accessibility, ushers in an era where cutting-edge models like transformers are within reach for all, fostering an inclusive technological environment that accelerates innovation across industries.
Setting Up the Development Environment
Setting up the development environment for working with Hugging Face’s Transformers library is critical to ensuring that you can smoothly execute NLP models and workflows. This setup process involves several steps that allow you to seamlessly integrate machine learning models into your tasks.
Begin by ensuring that your system meets the basic requirements for running NLP models using Python. You’ll need Python 3.6 or later, as Transformers library requires features and optimizations present in these versions.
Install Python following these steps:
For Windows:
– Download the latest version of Python from python.org.
– Run the installer and ensure you check the box that says “Add Python to PATH” before clicking on “Install Now.”
For macOS:
– Open Terminal.
– Use Homebrew (a package manager for macOS) to install Python by running:
bash
brew install pythonFor Linux:
– Python 3 comes pre-installed on newer distributions. Verify by running:
bash
python3 --versionIf it’s not installed, use your distribution’s package manager. For example, on Ubuntu:
bash
sudo apt update && sudo apt install python3Once Python is installed, the next step is to create a virtual environment. This isolates your Python environment for your NLP projects, avoiding conflicts with other projects or system packages.
Create a virtual environment with the following commands:
python3 -m venv nlp_env
Activate the virtual environment:
– Windows:
bash
nlp_env\Scripts\activate– macOS/Linux:
bash
source nlp_env/bin/activateAfter activating the virtual environment, you’ll have an isolated space to install packages specific to this environment.
Now, install the necessary Python packages, starting with transformers. You can use pip, which is pre-installed with Python:
pip install transformers
Hugging Face’s transformers library depends on several other libraries, so it’s often beneficial to also install these in the same go:
pip install torch tqdm numpy
torch: This is the PyTorch library, whichtransformersis often built on.tqdm: A library to add progress bars, which is useful when loading models or datasets.numpy: Essential for numerical computation tasks within models.
With the libraries installed, test your setup by executing a simple script to make sure everything works. Create a new Python file, test_setup.py, and add the following code:
from transformers import pipeline
nlp = pipeline("sentiment-analysis")
result = nlp("Hugging Face is the best!")
print(result)
Run the script using:
python test_setup.py
This code initializes a sentiment analysis pipeline, uses it to analyze a simple sentence, and prints the result, thereby testing the environment setup.
Keep your environment updated regularly by running pip install --upgrade transformers to leverage the latest enhancements and features released by Hugging Face.
If you encounter issues, check the Hugging Face documentation or their community forums, which are rich resources for troubleshooting and community-driven support.
By following these steps, you’ll establish a robust development environment conducive to efficient NLP model deployment using Hugging Face’s powerful tools.
Loading and Using Pretrained Models
Loading pretrained models in Hugging Face is an efficient way to harness the power of advanced machine learning models without having to train them from scratch. These models have been trained on vast amounts of data, making them ideal for fine-tuning on specific NLP tasks or for use directly as pre-trained solutions.
To begin, ensure that your development environment is set up with Python and necessary libraries such as transformers and torch. You might also want to have a basic understanding of the model architectures provided in the Hugging Face repository, like BERT, GPT, T5, etc.
Start by importing the required classes from the transformers library. The key components you need include the model class and the tokenizer class. Hugging Face provides a straightforward API to access these components:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
The AutoTokenizer and AutoModelForSequenceClassification classes help you load the tokenizer and model respectively. Hugging Face uses “Auto” classes to automatically retrieve the correct architecture based on the model name you provide.
The next step is to load a pretrained model and its tokenizer. Below is an example using the popular bert-base-uncased model:
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
Explanation of Tags:
– bert-base-uncased is a string identifier for the specific model configuration. “Uncased” means the model was trained without case sensitivity (e.g., it treats “dog” and “Dog” the same).
Once you have the model and tokenizer ready, you can use them to process input text. Tokenization is the first step, which involves converting text into a format that the model can understand—typically tokens:
inputs = tokenizer("Hello, this is a test sentence!", return_tensors="pt")
Here, return_tensors="pt" specifies that the output should be in the form suitable for PyTorch, which the transformers library commonly uses.
With the text tokenized, you can now pass it to the model to obtain predictions:
outputs = model(**inputs)
The result of this operation typically includes logits, which you need to process to get meaningful predictions. For classification tasks, this means applying a softmax function to convert logits into probabilities:
import torch
probabilities = torch.nn.functional.softmax(outputs.logits, dim=1)
print(probabilities)
The above code prints the probabilities for each class the model was trained to predict. In a sentiment analysis model, for instance, you might interpret these probabilities as the likelihood of the text being positive, negative, or neutral.
Pretrained models can also be fine-tuned to improve their performance on specific tasks. Fine-tuning typically involves continuing the training of the model on a task-specific dataset for a few more epochs until performance metrics stabilize.
Leveraging pretrained models in Hugging Face thus accelerates the deployment of sophisticated NLP systems by efficiently reusing knowledge embedded within these models, offering a breadth of capabilities from sentiment analysis to complex question answering, all tailored via transfer learning and the flexibility of Hugging Face’s tools.
As you enhance your proficiency with these models, explore various layers and attention mechanisms that transform how language is understood and generated, pushing the boundaries of what is possible in Natural Language Processing.
Understanding Tokenization and Pipelines
Tokenization and pipelines are fundamental components in Natural Language Processing (NLP) that underpin effective text analysis and model implementation. Understanding these concepts is crucial in using tools such as the Hugging Face library efficiently.
Tokenization is the initial step in transforming raw text into inputs that models can process. At its core, tokenization involves breaking down text into smaller semantic units called tokens. These tokens can range from words and subwords to characters, depending on the level of granularity required for the task at hand.
In traditional approaches, text was split based on spaces, punctuation, or a pre-determined set of rules, resulting in word-level tokens. However, this approach often resulted in inefficiencies, especially with languages that do not have clear word boundaries. With the advent of deep learning, especially transformer-based models, the tokenization process has evolved to incorporate subword tokenization using techniques like Byte-Pair Encoding (BPE).
Subword Tokenization:
Modern tokenizers such as those used in Hugging Face’s Transformers library utilize subword tokenization to address out-of-vocabulary issues and improve handling of inflected forms and compound words. For example, the word “unhappiness” might be tokenized into subwords “un”, “happy”, and “ness.” This allows the model to understand and generalize better by focusing on the common and uncommon parts of words.
Implementing Tokenization:
Using Hugging Face’s Transformers, you can implement tokenization in a few straightforward steps. Consider the BERT tokenizer:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokens = tokenizer.tokenize("Natural Language Processing makes it easy to interact with computers!")
print(tokens)
This code initializes a BERT tokenizer using a pre-trained model. The tokenize function splits input text into tokens, which are transformed into numerical input ids for the model.
Pipeline Concepts:
Pipelines in NLP, particularly in the context of Hugging Face, simplify the application of pre-trained models to various NLP tasks. A pipeline abstracts the complexities of text processing by combining tokenization, model loading, and prediction in one cohesive unit. This allows users to implement tasks like sentiment analysis, text classification, and named entity recognition with minimal code.
Creating and Using Pipelines:
The following demonstrates how to set up a sentiment analysis pipeline:
from transformers import pipeline
# Create a pipeline for sentiment analysis
a_sentiment_pipeline = pipeline("sentiment-analysis")
# Analyze text using the pipeline
result = a_sentiment_pipeline("I love learning about NLP models!")
print(result)
Here, the pipeline function automates the retrieval and setup of a model appropriate for the specified task. It encapsulates the model inference and post-processing logic, enabling quick deployment and testing of NLP capabilities without manual intervention.
Practical Example of Pipelines:
Suppose you’re interested in employing pipelines for extracting information using named entity recognition (NER). You can set up an NER pipeline like this:
ner_pipeline = pipeline("ner", aggregation_strategy="simple")
text = "Hugging Face, based in New York, is advancing NLP technology."
entities = ner_pipeline(text)
print(entities)
This implementation efficiently identifies named entities in text, outputting results with the entity types and positions in the original string.
By integrating tokenization and pipelines in NLP workflows, you streamline the process of model usage, paving the way for more scalable and versatile applications. With precise tokenization, you ensure that your text inputs are effectively interpreted by the models, while pipelines provide a user-friendly and cohesive interface to operationalize these models directly into production environments.
Mastering these foundational tools, you can harness the power of advanced NLP techniques and models, thereby propelling your projects with speed and scalability.
Fine-Tuning Models for Custom Tasks
Fine-tuning models for custom tasks involves adjusting pre-trained neural network models to perform specific tasks more effectively. This process builds on the existing knowledge of models like BERT, GPT, or T5, which have already been trained on vast corpora, making them highly adaptable through fine-tuning.
To begin fine-tuning, the initial step is to select an appropriate base model. Usually, this model should align closely with your task requirements. For instance, if you’re focusing on text classification, models like BERT or RoBERTa are ideal. These models leverage bidirectional transformers, allowing them to grasp context from both surrounding words, enhancing classification accuracy.
Here’s a detailed overview of fine-tuning:
Dataset Preparation: First, prepare a labeled dataset relevant to your task. This dataset should be split into training, validation, and test sets. The training set is used for fine-tuning, while the validation and test sets help evaluate the model’s performance.
Environment Setup: Set up your environment to enable seamless computation. This involves installing necessary libraries and ensuring a Python environment with dependencies like PyTorch or TensorFlow is available. Use virtual environments to manage dependencies specifically for your project:
python3 -m venv fine_tune_env
source fine_tune_env/bin/activate
pip install transformers torch
Model and Tokenizer Loading: Load both the model and its tokenizer from the Hugging Face Hub. This ensures that your data inputs align with what the model expects:
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
Data Encoding: Convert texts in your dataset to tokenized inputs, which the model can process internally. Hugging Face provides utilities to streamline this task:
train_encodings = tokenizer(train_texts, truncation=True, padding=True, return_tensors='pt')
Integrating a Training Loop: Build a training loop to adjust model weights based on the training set. Use backpropagation for iteratively refining model predictions against true labels. Use an optimizer like AdamW for efficient weight updates and a loss function suited to your task, such as CrossEntropyLoss for classification tasks:
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=3, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
)
trainer = Trainer(
model=model, # the instantiated Transformers model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset # training dataset
)
trainer.train()
Evaluation and Tuning: After training, use the validation set to evaluate the model’s performance. Adjust hyperparameters such as learning rate and batch size for optimal results. Fine-tuning might expose issues like overfitting, which can be mitigated by using techniques such as early stopping or dropout regularization.
Deployment and Testing: With the fine-tuned model ready, running evaluations on the test set confirms its applicability to real-world data. Fine-tuned models can be deployed using cloud services or integrated into software applications through APIs or frameworks.
Fine-tuning empowers models with enhanced adaptability and specificity to applicable tasks, maximizing the potential of pre-trained transformer architectures. This process ensures that models are not only performant but also adaptable to evolving needs and datasets, representing a critical bridge between general and task-specific AI capabilities.



