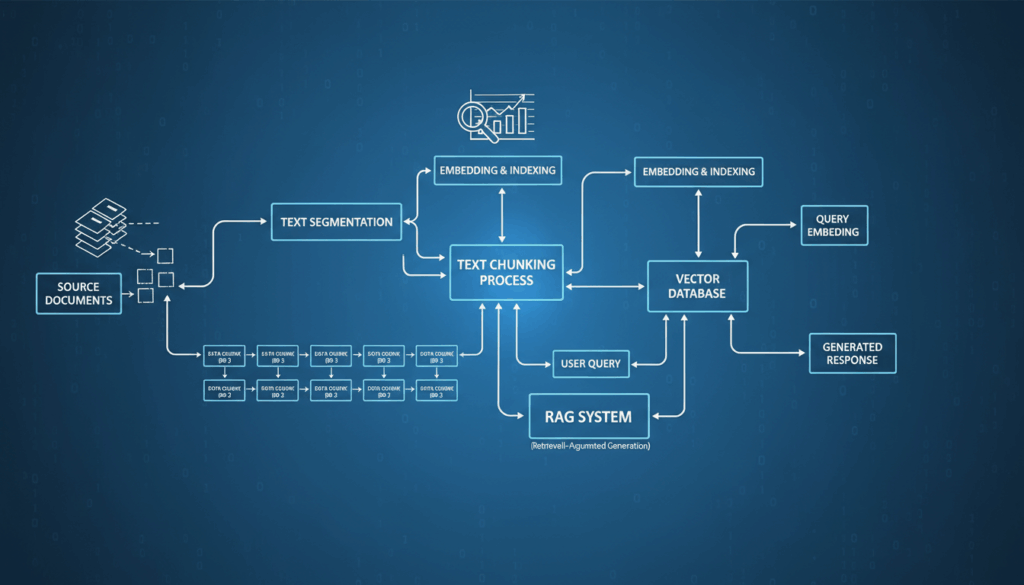
Introduction to Text Chunking in RAG Systems
In modern information retrieval systems, Retrieval-Augmented Generation (RAG) models have emerged as a groundbreaking technology, blending retrieval-based and generation-based approaches to handle vast amounts of data effectively. A pivotal process within this framework is text chunking, which involves dividing large text documents into smaller, manageable pieces or “chunks.” This process is crucial for enhancing both the efficiency and effectiveness of RAG systems.
Text chunking serves several purposes in a RAG system. Primarily, it enables the model to process and retrieve relevant information from expansive data sources quickly. Large documents can be unwieldy, containing vast quantities of information irrelevant to specific queries. By segmenting these documents into smaller sections, RAG models can more accurately identify and retrieve the chunks that are most pertinent to a given query.
The process of chunking typically begins with the identification of logical sections within a document. These might be paragraphs, sentences, or sub-sections, depending on the granularity required and the nature of the data. For instance, a scientific article might be chunked into sections such as the abstract, introduction, methodology, results, and discussion. This method allows the RAG system to target queries more precisely, navigating directly to sections that are more likely to contain the desired information.
In practice, chunking can be implemented using various techniques depending on the complexity and format of documents. Simpler methods may involve splitting text at sentence boundaries, using delimiters such as periods or new line characters. More advanced techniques might deploy natural language processing (NLP) algorithms to detect semantic changes and boundaries by analyzing the coherence and syntactic structures within the text.
For example, NLP models trained to understand linguistic nuances can detect topic shifts within a document, thus identifying optimal points for chunking. These models evaluate textual cues—like transitions in topic, style, or focus—which often signal logical divisions. By employing these intelligent models, chunking not only becomes efficient but more contextually aware, improving the relevance of retrieved information.
Another consideration in text chunking is the size of each chunk. It must be delicately balanced: too large, and the chunks may include unnecessary information; too small, and the relevance between extracted information could be lost. Many RAG implementations utilize heuristics or learned parameters to determine chunk size, optimizing this balance for specific use cases.
Ultimately, effective chunking is a blend of art and science, requiring a nuanced understanding of both the text structure and the information retrieval needs of the RAG system. By refining the chunking process, developers can substantially enhance the performance of RAG models, resulting in faster, more accurate responses to complex queries, and a more streamlined interaction with expansive datasets. Such advancements underscore the foundational role of chunking in the architecture of cutting-edge information retrieval solutions.”
Importance of Text Chunking for Retrieval Accuracy
In the realm of Retrieval-Augmented Generation (RAG) systems, the precision and accuracy of information retrieval are paramount. Text chunking plays an indispensable role in achieving this goal by dividing complex documents into smaller, coherent segments that are more manageable and relevant for processing. Understanding why text chunking is crucial for improving retrieval accuracy involves appreciating how it directly impacts the effectiveness of data handling and query response.
One primary benefit of text chunking lies in its ability to reduce the noise associated with retrieving extraneous information from large documents. By breaking down texts into logical and thematic sections, chunking allows RAG systems to zero in on pieces of text that are truly pertinent to the input query. Consider a user searching for specific information within a vast research paper; an entire document might overwhelm the retrieval system with tangential data. However, identifying and retrieving only the section that discusses the pertinent findings minimizes irrelevant content, thus sharpening the focus of the retrieved information.
Moreover, chunking enhances the RAG system’s ability to harness context. In natural language processing, context is crucial for understanding and generating accurate responses. By maintaining contextual connections within individual chunks, the system can better understand subtle nuances or specific information localized within that segment. For instance, a chunked text concerning financial data will include related commentary and figures, maintaining coherence and aiding the system in providing more precise answers.
Example scenarios illustrate the role of chunking in various domains. In a legal setting, when a query relates to a particular legal precedent or ruling within a lengthy case document, chunking allows the system to home in on the exact passages detailing that precedent. Similarly, in academic research databases, when looking for specific experimental results, chunked sections such as the “Results” or “Discussion” provide direct and relevant access without wading through entire documents.
Another facet of demonstrating the importance of chunking involves the reduction of computational expense. Smaller segment chunks require less processing power, enabling quicker retrieval times and reducing the strain on computational resources. This efficiency is crucial in large-scale systems where millions of documents are processed continuously. Thus, chunking not only improves accuracy but makes the entire retrieval process more resource-efficient.
The implication of improved retrieval accuracy through chunking is profound in adapting RAG systems to meet diverse user needs. By refining the selection of information retrieved, chunking supports more personalized and context-aware user interactions. This leads to a user experience where responses are not only fast but precisely aligned with user intent, thereby increasing user satisfaction and trust in automated systems.
These advantages emphasize the necessity of adopting optimized chunking strategies as a standard within information retrieval frameworks. As the demand for quick and precise information retrieval grows, chunking remains a core component of ensuring that RAG systems meet these expectations, paving the way for more sophisticated and effective data interaction platforms.
Common Text Chunking Techniques
Text chunking can be approached through various techniques, each offering a unique advantage in segmenting large documents into manageable pieces. Here, we will explore some common methods implemented in Retrieval-Augmented Generation (RAG) systems, focusing on their application and effectiveness.
One basic but widely-used technique is sentence-level chunking, where text is divided at each sentence boundary. This approach is straightforward, leveraging natural linguistic structures to create coherent chunks. This method is particularly effective for documents where the sentence boundaries delineate clear, self-contained ideas. It’s often utilized in simpler text processing tasks and can be implemented using regular expressions or punctuation as delimiters.
A more advanced approach involves paragraph-level chunking. This technique leverages the inherent structure and logic within paragraphs, which are typically organized to contain a central idea or argument. Paragraph-level chunking is beneficial for processing text documents such as articles, reports, or essays. By maintaining the integrity of paragraphs, this method preserves the narrative flow and context, essential for understanding transitional and supporting information.
For more contextually nuanced applications, semantic-based chunking is employed. This technique utilizes natural language processing (NLP) to identify semantic shifts within a text, such as changes in topic or argument. By analyzing linguistic features like word embeddings or topic models, the system can detect where new concepts or discussions begin and end. Semantic chunking is highly effective in complex documents like research literature or legal texts, where it enhances the precision and relevance of information retrieval by focusing on meaningful transitions and context changes.
Another technique includes threshold-based chunking, which involves defining chunks based on a fixed word count or character limit. This is often used in conjunction with other strategies to ensure chunks do not become too unwieldy. Setting such limits helps manage computational resources, keeping retrieval times efficient while still allowing for comprehensive content analysis.
Discourse-based chunking adds another layer to text processing by considering the overall discourse structure. It involves analyzing discourse markers and cohesion devices to establish boundaries based on thematic and conversational elements. Techniques like Rhetorical Structure Theory (RST) can be deployed to identify these structures, allowing the system to preserve the logical and hierarchical order of the text.
Each of these techniques can be further enhanced with machine learning models. Using training data, RAG systems can learn to predict optimal chunk boundaries, adapting to specific genres or document types. Machine learning models offer the flexibility to tailor chunking strategies to the unique requirements of different datasets, improving retrieval effectiveness and user satisfaction.
Adopting these diverse text chunking techniques allows RAG systems to handle a wide array of documents and queries with heightened accuracy and efficiency. By aligning chunking methods with document structure and user needs, developers can significantly improve the performance and usability of information retrieval systems.
Implementing Text Chunking in RAG Pipelines
Implementing text chunking in a Retrieval-Augmented Generation (RAG) pipeline requires a blend of strategic planning and practical application, ensuring that text segments are optimized for effective and accurate retrieval. Here’s how this can be achieved.
Initially, the process must account for the nature and type of documents processed by the RAG system. Understanding the content, format, and typical end-user queries helps determine the optimal chunking strategy. For example, scientific articles may benefit from paragraph-level chunking due to their structured sections, while legal documents may require semantic or discourse-based chunking to appropriately delineate case arguments or legal precedents.
The first actionable step in implementing text chunking is data pre-processing. This stage involves cleaning the text data to remove unwanted elements such as headers, footers, or references that could skew results. Pre-processing may also involve language normalization techniques such as stemming or lemmatization to standardize word forms, enhancing the consistency of chunking results.
Once pre-processing is complete, the focus shifts to selecting an appropriate chunking technique. Sentence-level chunking uses simple rules, making it suitable for documents with clear boundaries marked by punctuation. Implementing this in a RAG pipeline can involve utilizing regular expressions to split text effortlessly.
For documents requiring more nuanced segmentation, paragraph-level chunking could be used. This involves recognizing paragraph breaks, often indicated by new lines or indentation, and can be handled using scripting languages like Python. Libraries such as NLTK or SpaCy might assist in parsing document structures and facilitating this segmentation automatically.
In more complex scenarios, semantic-based chunking becomes essential. Here, leveraging NLP models is crucial. These models can be integrated into the RAG pipeline to detect changes in topics or themes. For instance, using a pre-trained BERT model fine-tuned for topic segmentation can help identify natural breaks in subject matter within long documents.
To implement semantic chunking, one might start by configuring a transformer model that processes text input, outputs embeddings, and uses techniques like cosine similarity to detect shifts in thematic content. Once such shifts are identified, logical boundaries for chunks are established.
Furthermore, discourse-based chunking could be implemented using Rhetorical Structure Theory (RST). This involves analyzing the discourse and relationship between different parts of the text by identifying markers and cohesive devices. Although more intricate, this technique provides a robust framework for segmenting complex and interrelated documents. Python libraries such as SpaCy or specialized discourse parsing tools could facilitate this process in a RAG pipeline.
Threshold-based chunking is useful for maintaining a consistent size for each chunk, especially in resource-limited scenarios. Developers can set parameters within their RAG pipeline to ensure each chunk adheres to a defined word count or character limit, striking a balance between granularity and efficiency.
One method to ensure these techniques work cohesively within a RAG pipeline is through the integration of machine learning models that learn and adapt from document training datasets. By continually training these models on a corpus representative of typical input data, the system can dynamically adjust chunking parameters to optimize retrieval based on past performance and evolving needs.
Effective implementation in practice involves frequent testing and iteration. Developers should conduct regular evaluations using metrics such as retrieval accuracy, response speed, and user satisfaction to gauge the performance of chunked data retrieval. Fine-tuning based on feedback and system metrics ensures that the chunking strategy remains optimal.
By carefully selecting, implementing, and adjusting these strategies, developers can enhance the RAG pipeline’s ability to retrieve relevant, precise information efficiently, ultimately improving user experience and system reliability.
Evaluating the Effectiveness of Chunking Strategies
Evaluating the effectiveness of chunking strategies in retrieval-augmented generation (RAG) systems involves various analytical approaches to gauge how well these strategies enhance the system’s capability to process, retrieve, and generate relevant information. Several key metrics and methodologies can be employed to measure this effectiveness, ensuring that chunking optimally supports the information retrieval goals of RAG systems.
One of the primary metrics to consider is retrieval accuracy. Retrieval accuracy refers to the percentage of correctly retrieved chunks in response to a given query compared to the total number of relevant chunks available. By performing precision-recall analysis, one can assess both the precision (the fraction of retrieved chunks that are relevant) and recall (the fraction of relevant chunks that are retrieved) within the RAG pipeline. High precision and recall indicate that the chunking strategy is effectively isolating and retrieving the most pertinent sections of the document.
For instance, in a scenario where the RAG system is applied to a database of medical research articles, evaluating chunking effectiveness could involve testing how accurately specific research findings or patient case studies are retrieved in response to detailed queries. By scoring the returned chunks against a pre-defined set of relevant passages, we can quantify how well the chunking strategy performs.
User satisfaction surveys and feedback can provide qualitative insights into the effectiveness of chunking strategies. Users interacting with RAG systems can offer valuable perspectives on the relevancy and usefulness of the retrieved information. For example, users might be asked to rate their experience with the quality and coherence of the information provided by the system. Consistently high ratings could affirm that the chunking strategy successfully enhances the user experience by delivering information that closely matches query intents.
Furthermore, efficiency metrics, such as retrieval time and computational resource utilization, must be considered. The effectiveness of a chunking strategy isn’t just about accuracy; it also involves how quickly and efficiently the system can operate. Evaluating the average retrieval times before and after applying a chunking strategy provides insight into performance improvements. Resource-intensive strategies may burden system performance, so they must be balanced against the benefits of improved retrieval accuracy.
Conducting A/B testing or controlled experiments can further validate the effectiveness of different chunking approaches. By deploying two variations of the RAG system, each using distinct chunking strategies, one can monitor and compare how each system version performs with real-world queries. Factors such as retrieval accuracy, user satisfaction, and system speed can be directly compared, providing clear evidence of which strategy yields better results.
Implementing benchmarking tools and datasets dedicated to evaluating text chunking is another method. Datasets like SQuAD or OntoNotes can be instrumental in testing chunking strategies against a broad range of documents. By using well-established datasets, developers can ensure that chunking strategies are tested against varied linguistic and structural challenges, offering comprehensive insights into their effectiveness across different contexts.
Finally, considering the adaptability of chunking strategies—how well they scale with the growth of dataset sizes and the introduction of new domains—is paramount. Effective chunking strategies should be flexible enough to accommodate changes in dataset complexity and domain specificity, maintaining high retrieval standards irrespective of the data landscape.
By systematically applying these evaluation methods, developers can identify the strengths and weaknesses of implemented chunking strategies within RAG systems, enabling continuous optimization and enhancing the overall value of information retrieval processes.



