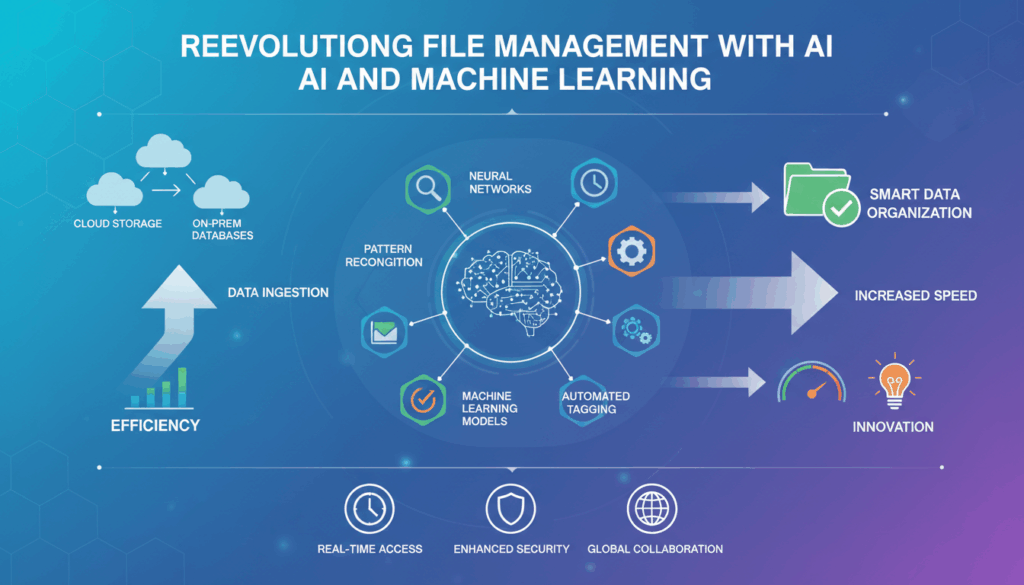
Introduction to AI and Machine Learning in File Management
In recent years, artificial intelligence (AI) and machine learning (ML) have emerged as transformative technologies across various industries, including file management. As businesses grapple with exponentially growing volumes of data, AI and ML offer unprecedented opportunities to enhance efficiency, accuracy, and functionality in managing files.
AI and ML can automate tasks that traditionally require human intervention, such as organizing, tagging, and retrieving files. In practical terms, this means developing systems that intelligently interpret and classify content based on patterns and characteristics within the data. For instance, a machine learning algorithm can be trained to recognize specific document types like invoices or resumes by analyzing features such as structure, keywords, and metadata.
Moreover, AI-enhanced file management systems can improve search functionalities. Traditional search methods often rely on basic keyword matching, which may yield unsatisfactory results when dealing with extensive file repositories. AI-powered solutions enhance these capabilities by understanding context and intent, thus enabling more accurate and relevant search outcomes. This is accomplished through the deployment of natural language processing (NLP) techniques that can gauge the nuances in user queries, thereby providing more intuitive search experiences.
Additionally, file version control, a critical aspect of file management, benefits from AI-driven insights. By predicting and highlighting potential conflicts in file versions, AI helps maintain data integrity. For example, when multiple users are working on the same document, an AI system can suggest the best version to consider as the master copy based on analysis of user changes and contributions.
Security is another area where AI and ML play a pivotal role. With files frequently exchanged across different platforms, ensuring their security is paramount. Machine learning models are adept at detecting anomalies and potential threats in real-time, thereby thwarting unauthorized access attempts. These models continuously learn from new data, improving their detection capabilities over time. By recognizing unusual patterns of access or apparent breaches, AI systems can alert administrators promptly, minimizing the risk of data breaches.
File management also involves routine maintenance tasks such as deleting redundant files and freeing up storage space. AI systems offer smart recommendations by identifying duplicate files or outdated documents, allowing organizations to streamline their data stores efficiently. This kind of automation not only saves time but also reduces storage costs, as AI algorithms optimize the utilization of available resources.
For businesses aiming to leverage AI and ML in file management, the implementation begins with data organization. It is crucial to ensure that data is well-structured and clean because AI systems rely heavily on large sets of high-quality data for training and operation. Organizations should invest in infrastructure that supports robust data input and storage, while also considering data privacy and ethical concerns associated with AI deployments.
In summary, AI and ML are revolutionizing file management by introducing intelligent automation, thereby facilitating more efficient operations, improved search experiences, enhanced security, and smarter data organization practices. As these technologies continue to evolve, their applications in file management promise to become even more sophisticated and indispensable.
Automating File Organization with AI
Utilizing artificial intelligence to streamline file organization tasks offers the benefit of leveraging algorithms that mimic human decision-making patterns, thereby eliminating the need for manual sorting and categorization. AI achieves this through a sophisticated analysis of metadata, content, and contextual information, allowing it to intelligently classify and index files.
AI-Driven File Classification
AI systems employ machine learning models to comprehend different file types by analyzing structure and content. For instance, they can distinguish between formats like PDF and Word documents, and further categorize based on content, such as invoices, presentations, or reports. The initial step involves training the AI model using a robust dataset containing examples of each file type. This dataset needs to be diverse and comprehensive to enhance the algorithm’s ability to generalize from its training phase to actual application scenarios.
Metadata Extraction and Utilization
One of the vital tools in this process is metadata extraction. AI can automatically extract and interpret metadata, such as author, date of creation, and keywords. This eliminates the manual entry of metadata, which is often time-consuming and prone to human error. By focusing on metadata, AI ensures that files are organized not just by their format but also by the context and relevance, thereby enhancing retrieval efficiency.
Dynamic Tagging Systems
Beyond static categorization, AI systems can deploy dynamic tagging. Tags are assigned based on the content, context, and use-case scenarios dictated by the data. For example, in a corporate setting, documents could be tagged under categories such as ‘Financial’, ‘HR’, or ‘Marketing’. This tagging is continuously updated as new data comes in or as file contents change, ensuring that the system is always using the most relevant and up-to-date information.
NLP for Content Analysis
Natural Language Processing (NLP) is another crucial component, enabling AI to understand and process human language within documents. Through NLP, AI systems can analyze text content for sentiment, themes, or entities, and categorize files based on analyzed themes or topics. For instance, an AI might scan project documentation for phrases indicating stages of a project and classify them accordingly.
Machine Learning for Predictive Analysis
Implementing machine learning models also facilitates predictive file organization. These systems predict how files might be used in the future, organizing them pre-emptively. For instance, if certain project documents are frequently accessed together, AI can infer a relationship and organize them into a cohesive project bundle, enhancing user accessibility and workflow efficiency.
Automating Routine Organizational Tasks
AI solutions can be programmed to perform recurring tasks such as identifying obsolete files or duplicates. By setting thresholds for file relevance based on metrics like last access date or specific usage patterns, AI can recommend or automatically purge outdated files, maintaining an efficient and clutter-free data environment.
Implementing AI in File Systems
Deploying AI for file organization requires a supportive infrastructure capable of handling AI workloads. This includes investing in scalable cloud solutions or on-premises hardware that supports AI tasks. Furthermore, organizations should ensure compliance with data privacy regulations, as AI systems often necessitate examining detailed personal and organizational file contents.
By applying AI to automate these organizational tasks, businesses not only streamline file management but also empower their teams with the capacity to focus on more strategic initiatives, thereby driving operational productivity and innovation.
Enhancing Search and Retrieval through Machine Learning
Machine learning has significantly enhanced search and retrieval capabilities within file management systems, transforming how users interact with vast repositories of data. Traditional search methods often struggled with limitations such as keyword dependency, which could lead to irrelevant results in complex databases. However, by integrating machine learning algorithms, search mechanisms now leverage semantic understanding and context awareness to deliver more accurate and efficient outcomes.
The implementation of Natural Language Processing (NLP) is a cornerstone in this transformation. NLP allows the system to understand and interpret human language, enabling it to process user queries in a more intuitive way. Rather than relying on exact keyword matches, NLP models can grasp the intent behind a query. For example, if a user searches for “documents about our 2021 sales strategy,” an AI system equipped with NLP can parse the semantics to find related files, even if the precise phrase “2021 sales strategy” does not appear in the text of the documents.
Another aspect is semantic search, which uses machine learning to understand the meaning between words and queries more comprehensively. By analyzing the context and relationships within data, semantic search can efficiently align user intent with content, enhancing retrieval accuracy. This capability is beneficial when dealing with files that contain unstructured data, as the system can infer linkages and retrieve documents that might otherwise have been overlooked.
Machine learning also introduces contextual and personalized search, tailoring search results to individual user preferences and past behaviors. By learning from historical data regarding what users have searched for and accessed, the system can predict and elevate the relevance of search results for a given user. For instance, if a marketing manager frequently accesses particular promotional materials, the system can prioritize related documents in their search results.
Moreover, advanced clustering algorithms enable the categorization of documents into meaningful and relevant groups. By analyzing patterns in data sets, clustering identifies similarities and differences among files, allowing users to retrieve grouped results without specifying exact document names or content details. This enhances user experience by presenting comprehensive results that reflect underlying associations in the data.
The use of deep learning models in search and retrieval further refines output by training on large data sets to recognize intricate patterns beyond manual recognition capabilities. These models continuously improve as they are fed more data, adapting to subtle changes and new patterns over time, thereby refining the precision of search results.
Additionally, predictive analytics is employed to forecast which files might be relevant based on current trends or similar searches. This proactive approach helps users access necessary documents before they even execute searches, by suggesting files based on work trends and other context clues.
Implementing such an enhanced search and retrieval system requires a robust infrastructure capable of handling complex algorithms and large-scale data processing. This often means integrating cloud-based solutions that can scale according to demands, ensuring seamless access and real-time processing power. Organizations should also prioritize data security and privacy, ensuring compliance with regulations while harnessing the vast capabilities of machine learning.
By utilizing these machine learning techniques, file management systems not only improve their retrieval capabilities but also empower users to manage and access information with unprecedented ease and accuracy. This transformation is a testament to the potential of machine learning in creating smarter, more efficient data ecosystems.
Ensuring Compliance and Security with AI-Driven Systems
In the realm of AI-driven systems, ensuring compliance and maintaining security are paramount for organizations to protect sensitive data and adhere to various regulations. These systems, although advanced, pose unique challenges and require meticulous strategies to effectively safeguard information.
AI systems can be instrumental in maintaining compliance by automating the monitoring of regulatory requirements. Machine learning algorithms are adept at analyzing massive datasets and identifying patterns that could signify a breach in compliance or a potential security risk. This process involves the continuous aggregation and analysis of data from multiple sources, ensuring that the system stays abreast of any new regulatory changes or emerging threats. For example, a financial company employing AI can leverage these algorithms to scan transaction data, thereby identifying discrepancies that might indicate fraudulent activities or non-compliance with financial regulations.
Furthermore, AI-driven systems enhance security through advanced threat detection and response mechanisms. By utilizing machine learning models, these systems can quickly learn from existing data to predict and identify potential security breaches. Anomalies in system behavior—such as unusual access patterns or data movements—are flagged by the system, triggering automated alerts to the cybersecurity team. This preemptive action is crucial for mitigating threats before they can escalate into full-blown breaches. For instance, in cloud storage environments, AI can monitor file access logs to detect when unauthorized users attempt to access sensitive files, thereby preventing data exfiltration.
To facilitate these capabilities, robust AI models require access to quality datasets that capture the nuances of regulatory frameworks. These datasets should be inclusive of diverse scenarios to allow the AI to predict and respond to a wide range of compliance and security events. Organizations may often work in collaboration with regulatory bodies to ensure that their AI systems are trained on data reflective of all possible compliance requirements.
The transformative potential of AI in ensuring compliance and security necessitates a framework that includes strict adherence to ethical guidelines and privacy laws. Organizations must meticulously design their AI systems with transparency in mind, providing insight into AI decision-making processes to guarantee stakeholder trust. This transparency is essential, especially when deploying algorithms that affect user privacy, such as those involved in monitoring user behavior for compliance purposes.
Moreover, businesses implementing AI systems must invest in comprehensive employee training programs, ensuring that their workforce understands how to interpret AI-driven insights and alerts. This aligns human expertise with AI capabilities, enhancing the overall efficiency and responsiveness of compliance and security operations. Training not only includes understanding the technological aspects but also the ethical implications of AI decisions, fostering a culture of vigilance and responsibility.
Finally, organizations should implement continuous audit processes for their AI systems to ensure they remain aligned with compliance requirements over time. These audits involve regular checks on algorithm accuracy, bias assessment, and impact analysis on various compliance metrics. By establishing a cycle of evaluation and improvement, organizations can dynamically adapt their AI systems to meet evolving regulatory landscapes, ultimately ensuring their AI-driven approach to security is both compliant and resilient.
Implementing AI-Powered File Management Solutions
To successfully integrate AI into file management systems, an organization must first understand the requirements and potential challenges that come with AI-powered implementations. This process involves several key steps aimed at leveraging artificial intelligence to transform traditional file management practices into advanced, digital-first solutions.
Begin by identifying specific use cases where AI can add substantial value. Start by evaluating your existing file management processes to determine where automation and intelligence can overcome inefficiencies. For instance, if your organization struggles with categorizing vast quantities of documents, you might consider deploying AI to automate the classification and tagging processes using natural language processing (NLP). Consider AI’s potential to enhance search capabilities with machine learning, which increases accuracy and context awareness in file retrieval scenarios.
After pinpointing areas for improvement, select appropriate AI technologies and tools. Depending on the use case, different AI algorithms will be suitable. For file classification and organization, supervised learning techniques like decision trees or support vector machines might be effective. In contrast, for search enhancements, NLP models such as BERT or GPT are more relevant. Leverage AI frameworks like TensorFlow, PyTorch, or Scikit-learn, which offer pre-built models and extensive libraries that can accelerate development.
The next step is building a robust infrastructure to support AI operations. Implement either on-premises solutions or cloud-based platforms like AWS, Azure, or Google Cloud that provide scalable computing resources tailored for AI workloads. Ensure the infrastructure is designed to accommodate the storage and processing demands of large datasets necessary for training AI models. Cloud solutions can offer the added benefit of on-demand scalability and flexibility, ensuring that your systems can handle fluctuating processing loads without unnecessary expenditure.
Data preparation is a critical phase of implementation. Collect high-quality data that is relevant to your file management system. This data needs to be well-structured and diversified to ensure the AI models can learn effectively from wide-ranging examples. Cleanse and preprocess the data to remove inconsistencies and irrelevant information that could skew the training results. Techniques such as data normalization and augmentation may be applied to enhance the dataset’s quality further.
Proceed to train and test your AI models. Using the prepared datasets, train your models with a focus on the specific tasks they’ve been designed to perform, such as file categorization or metadata extraction. During this phase, continually assess the model’s performance using testing datasets, adjusting parameters and techniques to improve accuracy and efficiency. Consider employing cross-validation techniques to prevent overfitting, ensuring that the model generalizes well to new, unseen data.
Once the models are adequately trained, integrate them into your existing systems. This integration should be smooth and non-disruptive, allowing current operations to continue without interruption. Developers should work closely with IT and operations teams to ensure the integration aligns with technical and business requirements. AI models may be deployed using APIs or integrated directly into the application’s codebase, depending on the architecture.
Finally, establish a framework for continuous monitoring and improvement. AI systems are dynamic and require regular updates and fine-tuning as new data become available. Set up monitoring systems to track AI performance, identifying areas needing recalibration. Encourage feedback from end-users to gauge the effectiveness and accuracy of AI functionalities, adapting systems based on their input. Regular audits should assess both system performance and compliance with data privacy regulations.
By meticulously following these steps, organizations can effectively implement AI-powered file management solutions that enhance efficiency, accuracy, and user satisfaction, thereby driving significant business value.



