Introduction to Generative Pre-trained Transformers (GPTs)
Generative Pre-trained Transformers, often abbreviated as GPTs, represent a revolutionary advancement in the field of artificial intelligence and natural language processing. These models are fundamentally designed to understand and generate human-like text, making them invaluable across various applications, from conversational agents to creative writing.
The inception of GPTs is closely tied to the idea of pre-training followed by fine-tuning. This methodology allows the model to gain an initial understanding of language by being exposed to a vast and diverse corpus of text data. During pre-training, the GPT absorbs patterns of language, grammar, facts about the world, and even some reasoning abilities. What makes GPTs particularly powerful is their ability to leverage this learned information to produce coherent and contextually relevant text outputs.
One of the key innovations of GPTs is the “transformer” architecture, introduced initially in the paper titled “Attention is All You Need”. This architecture utilizes a mechanism known as “self-attention,” which enables the model to weigh the importance of different words in a sentence relative to each other. This capability is crucial for understanding context, especially in longer text sequences. Unlike earlier models that processed text sequentially, transformers can handle entire chunks of text simultaneously, enhancing efficiency and accuracy.
Generative capabilities are demonstrated through tasks such as text completion, where given a prompt, GPTs can generate plausible continuations. For instance, if a user begins a story, the model can seamlessly extend it, maintaining narrative coherence and stylistic consistency. The mechanics behind this include the ability to predict the probability of the next word in a sequence, based on the context provided by all preceding words.
One of the defining characteristics of GPTs is their size and complexity, typically measured in “parameters.” These parameters are parts of the neural network that are learned from data and dictate the output. For example, OpenAI’s GPT-3 boasts 175 billion parameters, allowing it to capture intricate subtleties of human language and deliver outputs that reflect nuanced understanding.
Real-world applications of GPTs are vast and expanding. In customer service, they enhance chatbots’ capabilities, allowing them to handle complex queries with human-like proficiency. In content creation, they aid writers by suggesting ideas or even drafting content. Their aptitude in language translation and summarization further demonstrates their versatility.
Despite their enormous potential, GPTs are not without challenges. They can occasionally produce text that seems plausible but is factually incorrect or biased, reflecting issues in the training data. Researchers are actively working to address these limitations, improving model transparency and fairness.
Overall, GPTs signify a monumental step forward in AI development, offering tools that mimic human-like understanding and generation of language. Their ability to learn from vast data and apply this knowledge creatively and practically continues to push the boundaries of what machines can achieve in the realm of communication.
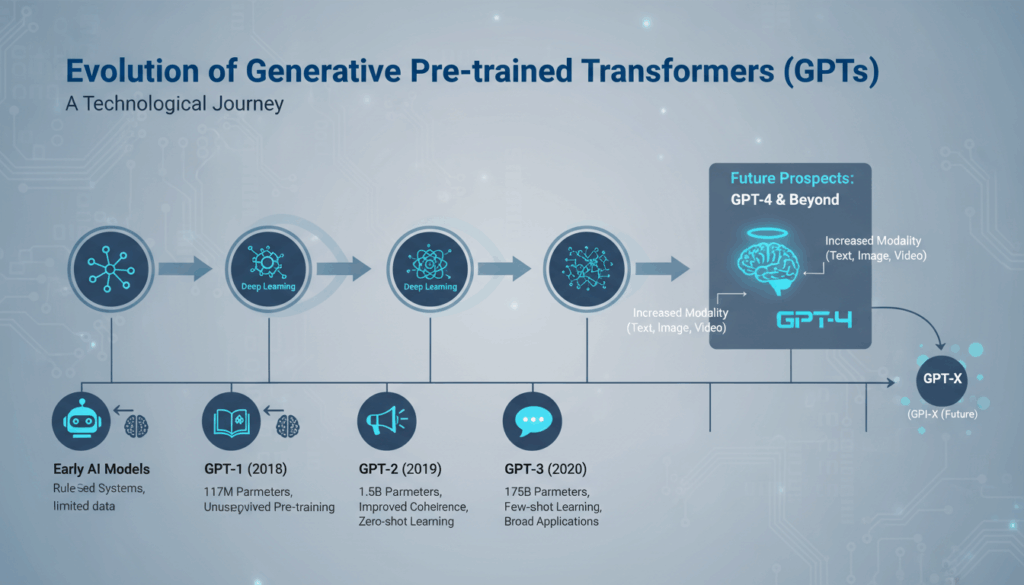
The Genesis: GPT-1 and Its Impact
The development of the first Generative Pre-trained Transformer, or GPT-1, marked a pivotal moment in the evolution of natural language processing and AI. Created by OpenAI and unveiled in 2018, GPT-1 laid the foundational architecture for subsequent GPT models, fundamentally shaping how machines comprehend and generate human language.
GPT-1 introduced a new approach to training models for understanding language. It was built on a transformative architecture called the “transformer” model, which was initially described in the influential paper “Attention is All You Need.” The transformer model leveraged the self-attention mechanism, allowing it to process and generate language more efficiently than previous models that required sequential data processing. This architecture enabled GPT-1 to consider all parts of an input simultaneously, understanding context more comprehensively.
One of the groundbreaking aspects of GPT-1 was its two-stage training process: pre-training and fine-tuning. During pre-training, GPT-1 was exposed to a massive corpus of diverse text from the internet. This phase involved learning the statistical structure of language, such as syntax, semantics, and some factual knowledge about the world. The fine-tuning stage then adapted the pre-trained model to specific tasks by further training it on task-specific datasets. This approach drastically differed from earlier models that required task-specific training from scratch, making GPT-1 more versatile and efficient.
With 117 million parameters, GPT-1 was large for its time, though dwarfed by the sizes of later models like GPT-3. Despite its smaller size compared to its successors, GPT-1 demonstrated significant advancements in generating coherent text. It was able to perform a variety of language tasks, such as question answering, language translation, and text summarization, showcasing the potential for AI to generate human-like text with context awareness.
The impact of GPT-1 extended beyond its technical contributions. It set a new benchmark for machine learning models, inspiring extensive research and development within the AI community. Its release prompted a broader exploration of transformer-based architectures in other disciplines beyond natural language processing, influencing areas like computer vision and game playing.
Moreover, GPT-1’s emphasis on pre-training followed by fine-tuning shifted how researchers approached AI tasks, encouraging a focus on building models that learn from vast amounts of data to improve contextual understanding and creative capabilities. This methodology paved the way for subsequent advancements, establishing a paradigm that remains integral to modern machine learning developments.
In conclusion, while GPT-1 may have been just the beginning, its formulation was revolutionary, setting the stage for the sophisticated models that followed. Its introduction altered how we harness AI for natural language processing tasks and heralded a new era where models could approximate the nuances of human communication more closely than ever before. This transformative impact has resonated throughout the AI industry, guiding future innovations and applications.
Advancements with GPT-2: Scaling Up
GPT-2 represented a significant leap forward from its predecessor, building on the transformer architecture introduced by GPT-1. This advancement was marked by an increase not only in the number of parameters but also in the model’s capabilities to generate more coherent and contextually accurate text. GPT-2’s development, released by OpenAI in 2019, marked a pivotal moment in the evolution of natural language processing models thanks to its scalability and enhanced features.
One of the standout features of GPT-2 is its expanded size, consisting of 1.5 billion parameters. This dramatic scale-up from GPT-1’s 117 million parameters allowed GPT-2 to internalize a broader scope of linguistic intricacies and details. With an expanded dataset during its pre-training phase, GPT-2 was exposed to a more diverse array of text inputs, furnishing it with a richer understanding of varying styles, tones, and subject matters. This extensive dataset improves the model’s ability to perform tasks with minimal fine-tuning, enhancing its versatility out of the box.
Central to the advancements seen in GPT-2 was the improved understanding achieved through the self-attention mechanisms of the transformer architecture. This took the model’s capability for coherence in text generation to new heights. By weighting the significance of different words in a given context, GPT-2 was able to comprehend and generate longer passages of text with a continuity and fluency that more closely resembles natural human writing.
Moreover, GPT-2 excelled in zero-shot learning, whereby it could perform a variety of tasks without needing additional task-specific data. This is fundamentally different from many earlier models that required retraining or fine-tuning for each new task. For example, given a piece of text, GPT-2 could generate nuanced summaries, create dialogue based on user prompts, or even translate languages, without having been explicitly programmed for these tasks. The model’s proficiency in generating text with a specific format or style, such as poetry or realistic fiction, highlighted its potent generative capabilities.
The application of GPT-2 extended into creative domains as well as practical implementations in business and technology. Businesses began utilizing GPT-2’s capabilities to automate routine writing tasks, such as generating emails or drafting reports, significantly reducing the workload on human staff and increasing productivity. In creative industries, the model served as an inspiration and tool for writers and artists, where, for example, it helped in crafting narratives or generating ideas for storylines. The model’s ability to emulate diverse voices was powerful in enhancing user experiences in conversational AI applications, making interactions feel more personal and engaging.
GPT-2 did not come without challenges or ethical debates, however. Its release was initially delayed due to concerns about misuse, such as generating deceptive or harmful content. These discussions illuminated the inherent risks of advanced language models, highlighting the need for responsible use and further research into safeguarding mechanisms. This included implementing checks for inappropriate content and ensuring outputs were as unbiased and accurate as possible.
Overall, GPT-2’s contributions to the field of artificial intelligence underscored the potential and power of scaling up models. Its advancements served as a foundation, paving the way for future models like GPT-3, which continued to push the boundaries of how machines comprehend and generate human-like language.
Breakthroughs in GPT-3: Expanding Capabilities
In the evolution of Generative Pre-trained Transformers, GPT-3 stands as a monumental leap forward, pushing the boundaries of what artificial intelligence can achieve in natural language processing. This model, developed by OpenAI, is not just about incremental improvements; it signifies a transformative expansion in capabilities that opens up a vast array of possibilities.
GPT-3’s architecture is built upon 175 billion parameters, making it significantly larger than its predecessor, GPT-2, which had 1.5 billion parameters. This substantial growth in size enables GPT-3 to grasp language nuances and context with unparalleled intricacy. The increase in parameters allows for a richer and more complex understanding of text, powering enhanced performance in generating natural language output.
One of the most striking aspects of GPT-3 is its ability to efficiently handle few-shot, one-shot, and even zero-shot learning scenarios. This means that the model requires little to no fine-tuning to perform a wide range of tasks, showcasing its adaptability. For example, GPT-3 can execute mathematical calculations, interpret code, or generate complex narrative stories when given just a minimal prompt. It excels at understanding vague user instructions and completes them with surprising accuracy and creativity.
GPT-3’s proficiency extends to various applications, particularly in generating human-like text that can convincingly mimic many writing styles, dialects, and formats. Whether drafting emails, composing poetry, or creating dialogue for interactive storytelling, the model approaches each task with contextual sensitivity that closely mirrors human capability. This flexibility is demonstrated by its ability to switch seamlessly between different writing styles, enhancing its utility across diverse fields, including customer service, creative writing, and content generation.
A noteworthy breakthrough is GPT-3’s capacity to perform complex reasoning tasks, translating abstract ideas into coherent explanations and solutions. This reasoning capability is evident in its ability to answer intricate questions by analyzing context and drawing from its vast pre-trained data pool. For instance, given an ambiguous question, GPT-3 can identify and reference multiple relevant sources of information, synthesizing answers that reflect comprehensive understanding.
Beyond traditional text generation, GPT-3 marks a step forward in interactive AI applications. It powers developments in conversational agents by delivering nuanced and contextually aware responses that contribute to more natural and engaging user interactions. This potential has been realized in applications ranging from virtual assistants to educational tools, where interactive learning is enhanced through engaging and responsive narratives.
GPT-3 also plays a crucial role in automating translation and transcription services, making it easier for global audiences to access content in their native languages. Its ability to interpret and translate text with subtlety and precision substantially reduces barriers to cross-cultural communication and information sharing.
Despite its advancements, GPT-3 is not without challenges. Ethical considerations remain paramount, particularly regarding the potential for misuse in generating misleading or harmful content. OpenAI has implemented stringent use guidelines and actively engages in ongoing research to mitigate such risks, striving to ensure that the technology is used responsibly.
Overall, the breakthroughs achieved with GPT-3 underscore the significant strides made in the field of artificial intelligence. It sets a new benchmark in AI-driven language modeling, opening pathways for future innovations and applications that will continue to redefine the landscape of computational creativity and communication.
Multimodal Integration in GPT-4 and Beyond
The evolution of artificial intelligence models towards multimodal integration signifies a transformative approach in how machines perceive and interact with the world. In the context of GPT-4 and beyond, this integration empowers models to process and generate not just text, but a rich tapestry of data types including images, audio, and more, thereby enhancing their versatility and applicability across various fields.
A critical advancement in multimodal systems is their ability to understand and synthesize information from different data sources. This capability allows models to draw contextual connections between disparate pieces of data, simulating how humans derive understanding from multisensory input. For instance, a model with multimodal capabilities can analyze a written news article alongside related images and videos to generate a comprehensive briefing that encompasses insights from all formats.
The fusion of multiple modalities enables these models to engage in more sophisticated interactions, suitable for applications such as virtual assistants that can interpret user speech, understand visual cues from a video, and respond with contextually relevant recommendations. This integration enhances user experiences by making AI interactions more intuitive and aligned with natural human communication patterns.
In the realm of healthcare, such multimodal systems can revolutionize diagnostic processes by combining patient textual data, medical imaging, and historical records to present more accurate and timely diagnoses. For instance, a physician could use a multimodal AI tool to scan a patient’s history, analyze their medical images such as MRIs or X-rays, and aggregate findings to assist in crafting a precise treatment plan. This holistic approach not only improves diagnostic accuracy but also speeds up decision-making processes, which are crucial in medical emergencies.
Education is another sector ripe with potential for multimodal AI. Imagine a platform that can integrate textual content from textbooks, videos of laboratory experiments, and interactive quizzes to provide a rich, engaging learning experience. Such a system could adapt lessons based on the learner’s interactions, offering personalized feedback and augmenting the traditional educational pathways with immersive learning experiences.
One of the essential steps towards achieving seamless multimodal integration involves enhancing the underlying AI architectures. This involves extending the transformer framework to better handle various data types concurrently. The development of specialized layers or modules that interact across different modalities could be crucial in creating this synergistic capability. By improving cross-modal attention mechanisms, models can prioritize and align relevant information from different sources effectively.
Moreover, training these comprehensive models demands large, diverse datasets that reflect the complexity and variety of real-world environments. This requirement poses a significant challenge but is essential to ensure that the AI can generalize well across different scenarios. Researchers are increasingly exploring synthetic datasets, which allow for controlled simulations of scenarios not easily captured naturally.
Furthermore, the application of reinforcement learning strategies and feedback loops can be instrumental in training multimodal AI. By iteratively refining the model’s ability to balance input from multiple sources, the resulting systems become adept at performing complex tasks in dynamic environments.
As we look forward to future developments beyond GPT-4, ensuring the ethical and secure use of multimodal models becomes paramount. There exists a need for robust frameworks that can minimize bias and prevent misuse, ensuring that these powerful systems remain tools for positive transformation. Initiatives focusing on transparency, accountability, and user-centric design are critical components that must accompany technological advancements.
Overall, the journey towards fully integrated AI systems that adeptly manage multimodal inputs is not only an endeavor to enhance technological capabilities but also a stride towards creating tools that better emulate human-like understanding and interaction. Such progress will undoubtedly push the boundaries of AI, opening new avenues for innovation across multiple domains.



