Introduction to Large Language Model Hallucinations
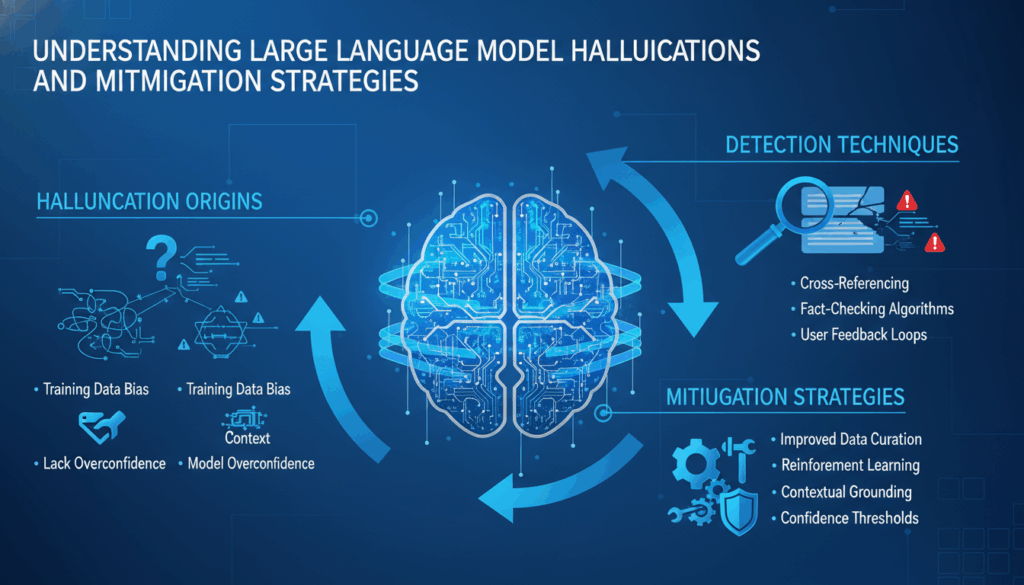
In recent years, large language models (LLMs) have become pivotal tools in the field of artificial intelligence, celebrated for their ability to understand and generate human-like text across various contexts. Despite their remarkable capabilities, these models are not without their flaws. One of the most critical issues they face is the phenomenon known as “hallucinations.” These are instances where the model generates text that is inaccurate, misleading, or nonsensical.
Understanding the nucleus of hallucinations in LLMs begins with recognizing their primary function: pattern recognition and probability prediction based on training data. Unlike human cognition, these models lack inherent comprehension or factual awareness. Instead, they predict the next word in a sequence by evaluating probabilistic connections across massive datasets. When the pool of examples is unclear or insufficient, the model might deviate, producing information that appears reasonable but is factually incorrect or fabricated.
An illustrative scenario of hallucination can occur when an LLM is prompted with queries related to niche or poorly-documented subjects. Due to the scarcity of data on these topics in their training set, language models might extrapolate from unrelated contexts, yielding outputs that blend plausible phrasing with imaginary details. This challenge often magnifies when models attempt to generate creative writing or handle complex cross-dataset inferences, where the demand for novel synthesis exceeds their training scope.
To further dissect how hallucinations appear, consider tasks requiring external, up-to-date information such as news summarization or scientific analysis. An LLM trained on a dataset that lacks the latest updates might confidently present outdated or obsolete insights. This problem highlights a critical limitation: the static nature of training data that doesn’t adapt or update in real-time, leading the model to hallucinate current facts based on historical patterns.
Moreover, hallucinations may manifest differently depending on linguistic or semantic ambiguity inherent in a prompt. For instance, vague or overly broad questions might induce the model to create embellished narratives that fulfill the form but not the substance of an inquiry. This outcome reflects a fundamental reliance on surface prediction paired with structural fluency, rather than true interpretative reasoning.
Addressing this issue requires multi-faceted strategies involving continuous refining of training data, implementing sophisticated feedback loops, and integrating human oversight. For example, one approach might involve data curation and augmentation strategies that focus on enriching datasets with accurate, contextually diverse examples. This enhancement provides broader and more relatable patterns for the model to learn from.
Another potential solution lies in the training and validation phases themselves, where embeddings and language understanding abilities are constantly tested against benchmark cases of factual accuracy. By employing mechanisms such as reinforcement learning from human feedback (RLHF), developers can guide models away from hallucinatory responses and towards more factually grounded outputs.
Understanding hallucinations is not only crucial for model improvement but also plays a significant role in setting realistic expectations for AI applications. By acknowledging these limitations, users and developers can work together towards building more reliable, accurate, and ethically sound AI systems.
Common Causes of Hallucinations in LLMs
Large language models (LLMs) often exhibit hallucinations due to several interrelated factors that impact their performance. The primary source of these hallucinations is rooted in the nature of the datasets these models are trained on. Since LLMs operate based on patterns and probabilities, any gaps, inconsistencies, or inaccuracies within the training data can lead to flawed outputs.
One major cause is the training data’s coverage and quality. If a dataset is overly biased, contains misinformation, or lacks diverse examples, an LLM may learn incorrect associations or make implausible connections. For instance, if specific topics are underrepresented, like niche scientific domains, the model may fill in gaps with imaginative but incorrect information when prompted with related queries.
Moreover, the completeness and recency of data directly affect the model’s output. LLMs are static once trained; they do not update in real-time. Consequently, training datasets that do not incorporate recent developments or current events predispose the model to generate outdated or inaccurate responses. This is particularly problematic in rapidly evolving fields like technology or world events, where the factual landscape changes frequently.
Another significant factor is the ambiguity in prompts received by the LLM. Vague or complex prompts increase the likelihood of hallucination as the model attempts to produce coherent text based on the syntax and semantics it understands. This situation often results in embellishing gaps with fictional or loosely accurate details.
Additionally, generalization and overfitting problems contribute to hallucinations. When a model is excessively exposed to specific patterns or simplified contexts during training, it becomes less adept at generalizing to new, unseen inputs. On the other hand, models that overfit might memorize irrelevant details, which can resurface inappropriately when generating text, giving rise to erroneous interpretations.
The lack of real-world knowledge and contextual understanding exacerbates these issues. LLMs do not possess intrinsic knowledge or comprehension; they lack awareness of factual data to verify their generated content. Consequently, any reasoning that seems logical within the statistical framework of the model may not hold up under factual scrutiny.
Finally, the complex architecture of LLMs sometimes contributes to misalignment between the model’s intrinsic biases and user expectations. Since the generation process heavily relies on patterns observed during training, particularly opaque interconnections within the model can lead to deviations from expected responses. This aligns with cases where output generation conflicts with normative or factual expectations based on unquantifiable associations learned from training data.
Addressing these issues requires more than just refining algorithms; it involves curating comprehensive, balanced datasets and integrating advanced techniques such as feedback loops with human input to continually calibrate and correct outputs. Embedding mechanisms that can contextualize and affirm their responses against live data streams are also burgeoning areas of research, promising to reduce the dependency on static dataset accuracy.
Impact of Hallucinations on AI Applications
The phenomenon of hallucinations in large language models (LLMs) presents significant challenges and implications for various AI applications. Understanding these impacts is vital for both developers and users aiming to leverage AI technologies effectively.
In areas like customer service, hallucinations can lead to incorrect information dissemination, affecting user trust and satisfaction. For example, automated chatbots that rely on LLMs to interpret and respond to user inquiries may generate factually inaccurate responses, resulting in customer frustration. If a chatbot mistakenly provides incorrect procedural information due to hallucinated outputs, it can undermine the perceived reliability of AI solutions, necessitating human intervention and additional resource allocation to manage escalations.
In the healthcare domain, hallucinations pose particularly severe risks. AI systems used to analyze medical data or assist in diagnostics must be exceptionally precise. Hallucinated outputs in this context could lead to misdiagnoses or incorrect treatment recommendations, potentially compromising patient safety. The reliance on probabilistic patterns without a comprehensive understanding of nuanced medical data emphasizes the need for stringent validation processes where AI models interface with sensitive health-related decisions.
Legal applications of AI, such as document analysis or predictive analytics in law firms, also suffer from the potential missteps caused by hallucinations. Hallucinated interpretations of legal texts or inaccurate predictions based on past case data can lead to flawed legal advice or misguided strategic decisions. The success of AI in this sector heavily depends on the model’s ability to accurately understand complex legal language and context, which hallucinations can easily distort.
Moreover, in the field of content generation, hallucinations can result in the dissemination of misinformation. Journalism or scientific publishing that employs AI to draft articles or papers must account for the inherent risk of fabricating data or creating misleading narratives. The possibility of AI inserting non-factual statements can harm the credibility of publications and require meticulous human verification processes.
In autonomous systems, such as self-driving vehicles, hallucinations could result in critical safety issues. If a system hallucinates a non-existent obstacle or misinterprets traffic signs, it could make erroneous driving decisions, leading to accidents. The importance of real-time data updating and feedback mechanisms in these systems cannot be overstated, as they help ensure that AI decisions remain grounded in reality rather than erroneous assumptions.
Addressing these impacts involves improved model training and robust verification mechanisms. AI researchers are increasingly focusing on refining datasets to minimize biases and gaps that lead to hallucinations. Integration of real-world feedback, along with advances in reinforcement learning from human feedback (RLHF), holds promise in enhancing the accuracy and reliability of AI systems.
The overarching consequence of hallucinations in AI applications underscores the necessity for transparency, accountability, and continual improvement in AI training methodologies. While advancements are being made to mitigate these risks, understanding the profound implications of hallucinations helps better prepare industries to integrate AI responsibly and effectively.
Techniques for Detecting Hallucinations
One effective strategy to detect hallucinations in large language models (LLMs) is to implement a multi-layered verification process. This involves cross-referencing generated outputs with trusted data sources. For instance, while developing applications reliant on LLMs, incorporating APIs that access up-to-date databases or encyclopedic resources can be invaluable. By comparing the model’s output against these real-time sources, discrepancies arising from hallucinations can be swiftly identified.
Another technique is to employ model interpretability tools. These tools help in visualizing and understanding how LLMs make predictions or generate responses. By analyzing attention weights and patterns, developers can identify when the model is straying from factual domains or relying on unsupported correlations, which might lead to hallucinated outputs.
Ensemble approaches can also prove beneficial. By leveraging multiple LLMs, each trained or fine-tuned on different datasets or tasks, the variability in outputs can be assessed. If one model provides information not corroborated by the others, it might signal a hallucinatory response. Such techniques utilize comparative evaluations to ensure consistency and accuracy in outputs.
Incorporating human-in-the-loop feedback mechanisms is another crucial technique. Through continuous collaboration with human experts, AI systems can be iteratively refined. After generating outputs, models can be subjected to expert review, where human operators flag potential hallucinations. Incorporating their feedback into the model’s training loop enhances its robustness and reliability over time.
Automated fact-checking mechanisms are increasingly critical. These systems can automatically verify the claims made by the model against pre-vetted, authoritative datasets. For instance, using tools powered by natural language understanding techniques, developers can integrate automated scripts that cross-check data represented in the model’s output with established facts, allowing for immediate detection and correction of hallucinations.
Additionally, employing targeted testing processes is essential. This involves designing specific scenarios or prompts known to potentially induce hallucinations in LLMs. By stress-testing models with these controlled environments, developers can better understand the triggers of hallucinations and refine model settings to enhance accuracy under ambiguity.
Reinforcement learning from human feedback (RLHF) has also emerged as a prominent technique in recent developments. Through RLHF, LLMs learn from interactions, where human feedback guides the model in adjusting responses to align more closely with factual and expected outcomes. This iterative process of feedback and refinement can significantly reduce the incidence of hallucinations.
Finally, integrating periodic model audits ensures ongoing quality control. By setting up schedules for regular evaluations and updates, models can be assessed against updated datasets and emerging trends, thereby minimizing the risk of generating outdated or incorrect information. Regular audits maintain the relevance and factual accuracy of model outputs and facilitate continuous adaptation to new data.
Strategies for Mitigating Hallucinations in LLMs
One effective approach to mitigate hallucinations in large language models (LLMs) is data refinement and augmentation. Ensuring that the model’s training data is comprehensive and well-balanced across multiple domains significantly reduces the risk of hallucinations. By curating datasets that are expansive and diverse, one can mitigate biases and knowledge gaps that lead to inaccurate outputs. This involves incorporating continuously updated information from reliable sources into the training pipeline. For instance, news archives or validated scientific databases might be scheduled for regular integration, allowing the model to adapt to the latest developments and diminish hallucination risks due to outdated data.
Implementing real-time feedback loops is another crucial strategy. By embedding mechanisms where user interactions guide model refinement, developers can substantially reduce hallucination instances. This can be achieved through reinforcement learning from human feedback (RLHF), where human evaluators review model outputs and provide corrections or confirmations of accuracy. The model then uses this feedback to adjust its responses in future interactions, honing its precision over time through an iterative process.
Developers can also leverage ensemble methods to enhance model reliability. By combining outputs from multiple LLMs trained on varied datasets or with different architectures, any one model’s potential hallucinations can be cross-verified. If discrepancies arise, ensemble systems can flag inconsistencies, allowing for either secondary review or automated corrective measures, significantly lowering the chance of a hallucinated response entering the final output.
Incorporating interpretability tools within the development framework provides transparency in how predictions are generated, aiding in hallucination mitigation. By monitoring attention weights and the path of information flow within a model, developers gain insights into when and why a model might drift into hallucinatory outputs. This understanding can guide adjustments in the algorithms or training methods employed, ensuring tighter control over the model’s generative process.
Regular model evaluations and audits are essential to maintaining the accuracy of LLM outputs. Establishing a schedule for periodic analysis allows developers to verify the model’s performance against current real-world datasets, ensuring that the model’s knowledge remains relevant and factually sound. This process may involve benchmarking the model’s outputs against a set of well-defined accuracy metrics and refining its dataset exposure as new information becomes available.
Lastly, implementing automated fact-checking systems during prompt processing can preemptively identify potential hallucinations. By interfacing LLMs with fact-verifying APIs or databases, outputs can be checked against high-confidence sources before finalization. This real-time evaluation acts as a filter, sifting out errors that could degrade the model’s reliability, especially crucial in applications where accuracy is paramount.
Jointly, these strategies highlight a comprehensive and multifaceted approach to addressing the hallucination problem in LLMs, emphasizing ongoing interaction, dataset management, and real-time validation to foster improvements in AI accuracy and trustworthiness.
Implementing Mitigation Strategies: A Step-by-Step Guide
To effectively address hallucinations in large language models (LLMs), begin by enhancing the quality and depth of the training dataset. First, conduct a comprehensive dataset audit to identify areas of bias, outdated information, or underrepresented topics. This involves benchmarking current datasets against recent developments and ensuring diverse sources are represented.
Next, implement a process of dataset augmentation and curation. Introduce reliable and up-to-date data by integrating continually refreshed sources such as validated scientific journals and real-time data feeds. Tools like data scraping or subscribing to APIs from reputable data providers can ensure consistent updates.
Following the refinement of training data, apply reinforcement learning from human feedback (RLHF). Develop a protocol where outputs are regularly reviewed by domain experts. These experts should flag inaccuracies or hallucinations and provide corrective feedback. By incorporating this feedback into the model’s learning process, you guide it toward producing more accurate outputs over time.
Additionally, consider an ensemble learning approach. Utilize multiple models that are either architecturally distinct or trained on varied datasets. For instance, combining outputs from three different LLMs allows for cross-verification. If a generated output from one model diverges significantly, use this as a trigger for further review or adjustment, ensuring more consistent reliability in final results.
To enhance interpretability, use attention visualization tools during the model development phase. These tools can help you trace which parts of the input text the model focuses on when making predictions. Understanding these focus areas can highlight potential drift situations, allowing further tuning of model parameters or training methods.
Implement automated fact-checking plugins within your LLM’s operational system. Utilize APIs and networks from fact-checking organizations to validate real-time outputs against high-confidence sources. This integration acts as a preventive measure to catch hallucinated information before reaching users.
Furthermore, establish regular model auditing protocols. Schedule routine evaluations where the model’s performance is tested against new, real-world datasets. This ensures that the knowledge embedded within the model remains current and that predictive accuracy aligns with recent facts and trends.
Finally, incorporate human-in-the-loop mechanisms. Deploy a monitoring tool that seamlessly alerts human operators to anomalies or potential hallucinations. Ensure that this system can capture unexpected results and rapidly route these outputs for human review, thus creating an effective feedback loop that catalyzes continuous model improvement.
By meticulously applying these methods, you can systematically mitigate hallucinations, enhancing the robustness and trustworthiness of LLM outputs across diverse applications.



