Introduction to Transformers in AI
In the realm of artificial intelligence, transformers have emerged as a groundbreaking development, powering some of the most advanced capabilities in natural language processing (NLP) and other domains. To truly grasp their significance, it’s essential to delve into the core concepts and the innovative architecture that sets transformers apart.
Traditional sequence-to-sequence models, such as recurrent neural networks (RNNs) and their variants like long short-term memory (LSTM) networks, were the precursors in handling sequential data tasks. However, these models struggled with long-range dependencies due to the inherent structure of sequential processing, which often led to vanishing gradient problems. Transformers addressed these limitations through a novel approach that eliminates the need for these sequential reminiscences by leveraging attention mechanisms.
Attention Mechanism: At the heart of transformer architecture is the attention mechanism, specifically the self-attention mechanism. The concept might initially seem abstract, but think of self-attention as a way for the model to selectively focus on different parts of the input data when generating each part of the output. In simpler terms, it assesses how much attention each word needs during processing, allowing the model to weigh the significance of each word dynamically. This capability facilitates the model to capture contextual relationships more effectively than its predecessors.
Multi-head Attention: This mechanism is further amplified by the use of multi-head attention. Instead of having a single attention focus, the model splits the attention mechanism into multiple heads that work in parallel. Each head can attend to different parts of the sequence, gathering information from various perspectives or subspaces. This diversification enriches the model’s ability to understand complex semantics and amplify its contextual learning capability, making it particularly powerful in language models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer).
Positional Encoding: One striking feature of transformers is their ability to process data as a whole instead of serially. This creates a challenge in understanding sequential order, which is skillfully resolved by positional encoding. Transformers use positional encoding to inject information about the position of each word in the sequence. This encoding is critical because, unlike RNNs, transformers process the entire sequence at once and need a way to differentiate between words’ positions. The encoding often uses sine and cosine functions of varied frequencies, which effectively captures sequential information and retains the order integrity.
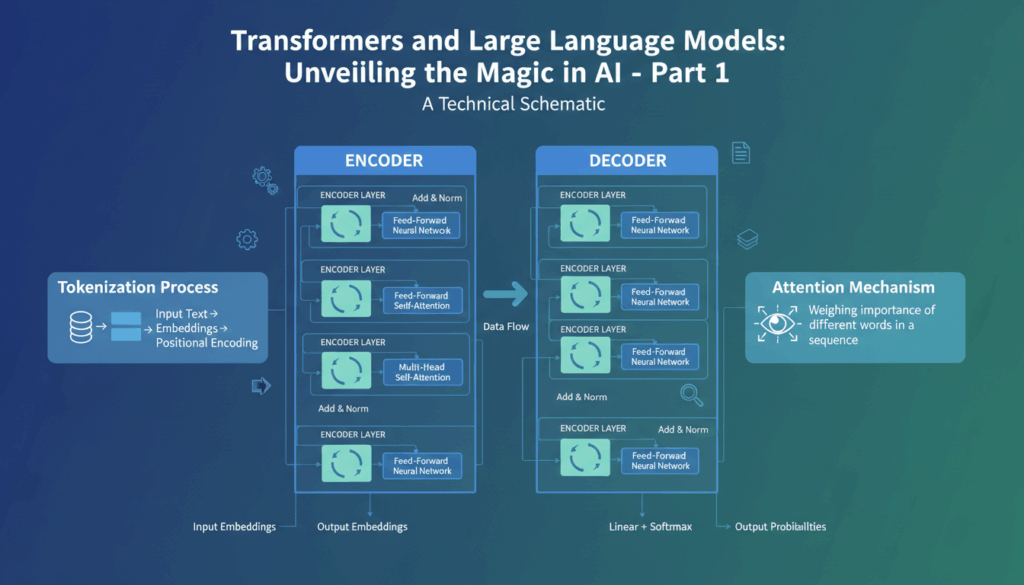
Layered Architecture: Transformers are composed of an encoder and a decoder, both of which consist of multiple layers. Each layer in the architecture integrates the above mechanisms, including feedforward neural networks that act as a nonlinear transformation layer. The encoder processes input data to build an understanding, while the decoder generates predictions. The intricate layering allows for the hierarchical capture of information, enhancing the model’s depth and versatility.
Applications and Impact: The introduction of transformers has revolutionized many facets of AI. From language translation and sentiment analysis to sophisticated applications in image processing with Vision Transformers (ViTs), their influence is expansive. Their ability to capture dependencies regardless of distance and context has led to substantial improvements in task performance, propelling forward the capabilities of AI models in tasks that were once considered challenging, such as text generation and completion.
Transformers have become the cornerstone of modern NLP tasks, largely driven by their ability to manage complex relationships within data. Their impressive adaptability and potential for further innovation continue to challenge what is conceivable with machine learning systems, making them a pivotal subject of study for both current researchers and anyone interested in the future of AI.
Understanding the Transformer Architecture
At the core of the transformer model lies a unique architecture that reshapes how networks handle sequential data, overcoming many of the limitations faced by its predecessors. Transformers utilize a mechanism that eschews the recurrent nature of traditional models, allowing for parallel processing and substantially improved efficiency in handling dependencies regardless of their distance.
Encoder-Decoder Structure
The architecture of a transformer is typically divided into two main components: the encoder and the decoder. The encoder’s primary responsibility is to process the input data and extract salient features, while the decoder takes these features to generate desired outputs.
The encoder is made up of a stack of identical layers, each containing two main components: self-attention and a feedforward neural network. When data flows through the encoder, the self-attention mechanism examines all parts of the sequence simultaneously, determining which elements are most relevant to the task at hand. This is in stark contrast to RNN architectures where each element can only attend to its predecessors sequentially.
Self-Attention Mechanism
Central to the transformer’s ability to learn dependencies is the self-attention mechanism. Each word in a sequence is transformed into a query, key, and value vector. The self-attention process determines the importance of each word in understanding the entire sequence by calculating a weighted sum of the value vectors, proportional to the attention scores derived from query and key interactions.
For instance, in a sentence like “The cat sat on the mat,” if the model is trying to understand the relevance of “cat,” it will consider how “sat,” “on,” and “mat” impact its importance, allowing it to build meaningful contextual representations.
Multi-Head Attention
Multi-head attention allows the model to focus on various parts of the sequence from different perspectives. This is achieved by running multiple attention operations in parallel, known as attention heads. Each head results in different focus and captures various linguistic features, ultimately combined and concatenated for more robust feature representation. For applications like machine translation or text summarization, this ability to look at data from diverse angles enriches the output quality significantly.
Positional Encoding
Since transformer models lack the inherent sequence information provided by RNNs, they employ positional encoding to integrate explicit information about the relative position of tokens in a sequence. This is typically achieved using sinusoidal functions, allowing the model to distinguish between “I wrote to him yesterday” and “Yesterday, I wrote to him,” despite their similar word structures.
Feedforward Networks
Each layer of the encoder (and similarly the decoder) also incorporates a fully connected feedforward network applied identically to each position separately. These networks provide nonlinear transformations to the extracted features, enhancing the model’s ability to capture complex patterns and relationships within the data.
The use of normalization layers and residual connections between these components helps in maintaining stable and efficient training by preventing gradient issues, promoting smoother flow of gradients through the network.
Decoder Enhancements
In the decoder, the inclusion of an additional attention layer that attends to encoder outputs allows the model to align its generation process based on the encoded input sequence. The decoder architecture’s ability to look at previous elements of its own sequence through self-attention, combined with this cross-attention to the encoder, makes it proficient in generating coherent and contextually accurate outputs.
Advances and Practical Impact
Transformers have led to significant breakthroughs in AI technologies, such as language models that generate human-like text, translate languages, and even generate complex code snippets. Their ability to parallelize processing and concentrate on meaningful aspects of input data accounts for the rapid adoption and remarkable improvements seen across various AI applications today.
The Role of Attention Mechanisms in Transformers
The remarkable progress in transformer models is primarily driven by the innovative use of attention mechanisms, which redefine how models interpret and manage input data. Unlike traditional approaches, the attention mechanism enables transformers to focus on specific elements of input sequences, dynamically adjusting these focus points based on relevance, context, and the specific task at hand.
At the heart of a transformer’s attention abilities lies the concept of self-attention. This allows each word in a sequence to consider other words in the sequence during its processing. For example, when interpreting a sentence, the model evaluates which words contribute most significantly to the meaning of each target word. This context-aware processing helps in capturing subtle dependencies and relationships more effectively. This mechanism is performed by creating three vectors – the query, key, and value vectors – for each word. The interaction between these vectors dictates the attention score, enabling the model to determine the proportionate impact of each word on the others.
In a sequence like “She gave him her book,” the model’s self-attention logic will analyze how “gave” relates not just directly to “her” and “book” but also to “she” and “him,” constructing an intricate map of relationships. This comprehensive relationship mapping helps in preserving contextual integrity, allowing downstream tasks such as text summarization or translation to produce outputs that are coherent and contextually accurate.
Multi-head attention expands the versatility of self-attention by allowing the model to focus on different parts of an input sequence simultaneously. By dividing the attention mechanism into multiple “heads,” each head can learn different relationships within the data. This multiplicity of perspectives enhances the model’s capacity to capture diverse patterns and contexts. For instance, in complex language structures or ambiguous sentences, multi-head attention allows transformers to reconcile multiple interpretations or nuances simultaneously, enriching their overall understanding and output.
Adding depth to this system is the strategic use of positional encoding. Because transformers do not inherently process input data sequentially, they require a scheme that allows the model to recognize the order of input tokens. Positional encoding injects signals about token positions into the input embeddings, usually through sine and cosine functions. This allows the model to discern the order and relative positions of tokens, ensuring that the input’s linearity and the semantic impact of positional shifts are accounted for. This becomes especially crucial in tasks where the sequence matters, such as machine translation, where the position of “to” in “to him” carries specific syntactical meaning.
Finally, the influence of attention mechanisms extends beyond just the processing of input sequences; they profoundly impact the training efficiency of the model. Attention mechanisms facilitate parallel processing by eliminating the need for processing each word one by one, as seen in RNNs. This results in faster training times and the ability to scale, making transformers particularly advantageous when handling massive datasets or complex language models.
The successful application and scalability of attention mechanisms in transformers have set a new benchmark in the field of NLP, transforming not only how language tasks are tackled but also opening avenues for their application in other domains like computer vision and beyond. The flexibility and depth offered by attention mechanisms are foundational to the success and widespread adoption of transformer-based models, positioning them at the forefront of AI innovations.
Training Large Language Models: Techniques and Challenges
Training large language models (LLMs) involves a carefully orchestrated process that integrates a variety of advanced techniques while facing numerous challenges. One of the primary methods involves the use of extensive datasets to ensure that models like GPT and BERT can generalize effectively across different contexts and tasks.
The first step in training large language models is data preparation. This involves curating vast amounts of text data from diverse sources such as books, websites, and articles. The data must be preprocessed to convert it into a suitable format, including tokenization, filtering irrelevant or harmful content, and balancing for bias. Tokenization is crucial as it breaks down text into manageable pieces, typically words (or subwords), which the model can process. Additionally, maintaining a balance in the dataset ensures the model’s fairness across different languages and subjects, reducing the risk of systematic biases.
The core training process relies heavily on supervised and unsupervised learning techniques. While traditional supervised learning uses labeled data with direct task specifications, LLMs often start with unsupervised learning, where the model discerns patterns and structures from unlabeled data. This is where techniques like masked language modeling (used in BERT) and autoregressive modeling (used in GPT) come into play, allowing models to predict missing words or generate coherent text sequences.
Transfer learning is another pivotal concept. Large language models typically undergo a two-phase training involving pre-training and fine-tuning. During pre-training, models learn general features from unstructured data without specific task instructions, absorbing as much linguistic context as possible. Fine-tuning then narrows down this broad knowledge to specialize in specific tasks such as sentiment analysis or question answering, using smaller, task-specific datasets.
A significant challenge encountered in training such enormous models is computational resource demands. LLMs require substantial computational power and memory resources. High-performance GPUs (Graphics Processing Units) and TPUs (Tensor Processing Units) are widely employed to handle the vast number of parameters, which can range from millions to billions. Optimizing these resources involves techniques like data and model parallelism, where different sections of the model or dataset are processed simultaneously across multiple devices, enhancing speed and efficiency.
Another technique to optimize training is the implementation of gradient checkpointing, which strategically stores certain layers’ outputs during the forward pass and recalculates them during backpropagation to minimize memory usage. Mixed precision training is also popular, using lower precision for calculations to reduce memory load and enhance computational speed without significantly compromising accuracy.
Addressing overfitting is critical in this context. Given the size of LLMs and their vast exposure to training data, they are susceptible to overfitting, where the model learns the training data too well, including noise and outliers, thus losing its ability to generalize to new data. Regularization techniques such as dropout, which randomly ignores certain neurons during training, and batch normalization, which standardizes inputs to each layer, are essential to mitigate this.
Ethical considerations play a significant role as well. LLMs can inadvertently learn and amplify biases present in their training data, leading to prejudiced outputs. Continuous monitoring and adjustment of training datasets, alongside the integration of fairness algorithms, are necessary to reduce such risks. Deploying bias detection and fairness metrics allows developers to understand and mitigate biases prior to and during the deployment of these models.
Finally, evaluation metrics must be wisely chosen to accurately assess the model’s performance. Metrics such as perplexity and BLEU scores (for translation tasks) provide insight into how well the model understands and generates language. Furthermore, continual evaluation and adaptation post-deployment ensure that these models remain relevant and effectively tuned to the evolving linguistic landscape.
Overall, the training of large language models demands a blend of sophisticated techniques and a keen awareness of potential pitfalls. By navigating these challenges effectively, developers can harness the full power of LLMs, pushing the boundaries of AI applications.
Applications of Transformers in Natural Language Processing
In the realm of natural language processing (NLP), transformers have become indispensable, providing enhanced capabilities to a wide array of applications due to their unique architecture. These models have redefined NLP by addressing the limitations of prior technologies and enabling more nuanced and contextually aware processing of language.
One of the most transformative applications of transformers in NLP is machine translation. Prior to the advent of transformers, systems such as phrase-based translation models struggled with syntactical complexities and failed to capture nuances across languages effectively. Transformers have overturned these challenges through their parallel processing ability and attention mechanisms, which facilitate the understanding of context and meaning disambiguation. For instance, Google’s Neural Machine Translation (GNMT) system, now using transformers, achieves more fluent and accurate translations by considering the entire context of a sentence rather than translating word-by-word.
Sentiment analysis is another application where transformers significantly improve outcomes. Traditional models often failed to recognize the complexities of human sentiment, such as sarcasm or varying intensities of positive and negative expressions. By utilizing transformers, applications can evaluate sentiment more accurately by considering word importance through self-attention mechanisms, capturing subtleties in phrases like “It’s not bad, but I’ve seen better” to understand the mixed sentiment.
Transformers have also excelled in the area of text summarization. Unlike extractive methods that rely on selecting sentences directly from the text, transformers enable abstractive summarization, generating novel sentences through understanding and reconstructing the content in a condensed format. This capability provides more coherent, human-like summaries of documents, preserving the essence and meaning of the original text.
Another domain where transformers play a crucial role is question answering systems. Models like BERT (Bidirectional Encoder Representations from Transformers) effectively handle tasks that require understanding the context of both the question and the associated passage. This is achieved through fine-grained attention to relevant parts of the text. Such systems are applied in customer service bots, effectively responding to queries with human-level comprehension.
In text generation, transformers power applications that require creating new text content that is both contextually and syntactically coherent. Models like GPT (Generative Pre-trained Transformer) utilize this technology to produce essays, poems, or even code snippets. Their ability to generate text continues to improve as they learn from larger datasets, making them invaluable in creative and technical writing.
Named Entity Recognition (NER) benefits from the transformer’s ability to track entities across long text segments, identifying names of people, organizations, locations, and more with high precision. This is particularly useful in information extraction tasks where identifying key information from contracts or news articles can streamline data processing.
Finally, semantic search leverages transformers to understand user queries better by assessing the meaning, rather than relying on keyword matching. This facilitates more accurate search results in both enterprise and consumer search engines, enhancing user experience by providing relevant information quickly.
These applications demonstrate how transformers are reshaping our interaction with technology through enhanced language understanding and generation. Their sophisticated architectures enable deeper comprehension and provide more accurate and contextually aware processing across diverse NLP tasks.



