Introduction to Tokens in Large Language Models
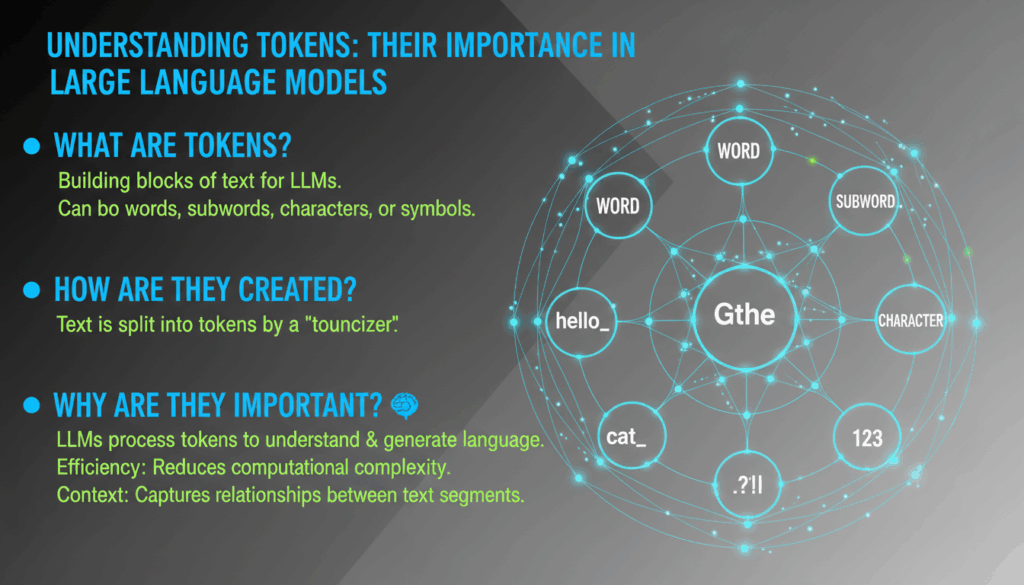
Tokens play a crucial role as the foundational elements within large language models (LLMs), such as GPT-3 and beyond. Understanding what tokens are and how they function can demystify how these complex systems process and generate human-like text.
A token can be thought of as a chunk of text that might represent a word, a subword, or even a single character. How these models tokenize input depends heavily on the model’s architecture and the language or context it is designed to handle. When a user inputs text into an LLM, the text is broken down into these tokens, which the model then processes to generate a response.
In the context of LLMs, tokens are primarily defined by their use in the tokenization process. Tokenization involves splitting textual data into tokens that the model can analyze and understand. For instance, in English text processing, a sentence like “The quick brown fox” might be tokenized into [“The”, “quick”, “brown”, “fox”] if each word is treated as a token.
More sophisticated tokenization methods using subwords are also employed, especially when dealing with languages with complex morphology or when aiming for efficiency in handling out-of-vocabulary words. Subword tokenization divides words into smaller units, enabling models to better handle unknown words or compose new words from the familiar building blocks. For example, “unbelievable” might be broken down into subwords like [“un”, “believe”, “able”]. This method is particularly beneficial in languages with rich inflectional systems or adaptive requirements.
Tokens serve multiple purposes in large language models. Firstly, they streamline data processing: breaking text into manageable units allows the model to parse and analyze data more efficiently, ensuring that complex linguistic structures are understood and relevant patterns are recognized. This segmentation makes it possible for models to achieve a higher level of semantic comprehension and generate more coherent responses.
Furthermore, the way tokens are utilized in training influences the model’s ability to capture contextual meanings. For LLMs, each token is associated with a vector in a high-dimensional space. The relationships and proximities between these vectors are learned during the model’s training phase, allowing it to grasp contextual nuances and syntactical relationships. This is critical for maintaining accuracy and producing outputs that are not only statistically likely but also contextually relevant.
The role of tokens extends to the generation of text, where the model predicts the next token in a sequence based on the analysis of preceding tokens. This sequential prediction is what enables these models to generate coherent and contextually appropriate text. By understanding both syntax and semantics through the token relationships, these systems can simulate human-like dialogue and generate creative content.
In practical applications, users and developers need to be aware of token limitations like maximum token capacity, as exceeding this can lead to truncation of input or output, potentially altering the intended content. This highlights the importance of efficient token management to ensure the models’ outputs meet the intended objectives without loss of information.
In summary, tokens are integral to the functioning of large language models, enabling efficient data processing and contextual understanding necessary for natural language generation. Mastery of the tokenization process is essential for anyone looking to leverage the full power of LLMs in various applications.
Types of Tokenization Methods
Tokenization is a pivotal step in processing natural language, especially for large language models (LLMs) that map raw textual data into manageable and meaningful units known as tokens. Different tokenization methods address various needs based on language complexity, efficiency requirements, and the specific architecture of language models like GPT-3. Each method has unique strengths and challenges, shaped by linguistic, computational, and practical considerations.
One basic form of tokenization is word tokenization, where text is split into individual words or units that are generally demarcated by spaces or punctuation marks. While this method works well for languages with clear word boundaries like English, it struggles with languages like Chinese, which do not use spaces between words, and with inflected languages where a single word can take multiple forms.
To address these limitations, subword tokenization methods such as Byte Pair Encoding (BPE) and Unigram Language Models are employed. BPE starts by treating each character as a token and then iteratively merging the most frequent pair of tokens into larger units, allowing it to effectively handle both known and out-of-vocabulary words by breaking them down into recognizable components. For example, “reading” might be tokenized into “read” and “ing”, which can be recombined to form other words like “readable” or “readability”. This flexibility is crucial in computational efficiency and generalization to novel inputs.
The Unigram Language Model, another subword method, begins with an initial set of subwords and iteratively filters the least likely candidates based on their probabilities of appearing in a language corpus. This probabilistic approach helps retain the most meaningful subword divisions, which can be particularly advantageous for languages with high morphological complexity.
Character-level tokenization breaks text into individual characters. This method is highly granular and can handle any natural language without requiring a predefined vocabulary, simplifying tokenization processes for languages with dense inflectional morphology. However, such granularity often leads to increases in sequence length, imposing higher computational demands on models.
In contrast, sentence-level tokenization, typically utilized as a preliminary tokenization step, involves separating text into distinct sentences using punctuation and syntactic cues. Although this is not commonly used independently in LLMs, it helps in organizing data for initial parsing, especially in tasks focusing on sentence-level processing like sentiment analysis.
Breaking ground in recent advancements, hybrid tokenization methods combine elements from multiple strategies to benefit from their strengths. For instance, integrating character and word-level tokenization allows models to maintain semantic comprehension through word-level clarity while tackling the morphological diversity with character-level precision.
Each tokenization method must consider trade-offs between the size of the vocabulary (and consequently the model) and its ability to handle diverse linguistic inputs. This balance directly affects the language model’s capabilities in understanding and generating human-like text. Thus, choosing the appropriate tokenization method is vital for optimizing model performance, particularly as LLMs evolve to incorporate more sophisticated natural language processing tasks across a wider range of languages and contexts.
Role of Tokens in Model Training and Inference
Tokens are pivotal in the lifecycle of large language models (LLMs), being integral to both model training and inference processes. Understanding their role offers insights into how these models achieve their impressive capabilities in natural language understanding and generation.
During model training, the primary goal is to enable the neural network to learn complex patterns and relationships within the data. Tokens act as the smallest units of data that the model encounters. These tokens, once encoded into numerical representations known as embeddings, serve as inputs to the model. The training process involves feeding sequences of these token embeddings into the model and adjusting the model’s parameters to minimize prediction errors. This adjustment is guided by backpropagation and gradient descent algorithms, which iteratively update the model weights to capture nuanced linguistic constructions.
For example, consider training a model on the sentence “The cat sat on the mat.” The sentence might be tokenized into individual words or subwords, each mapped to a unique vector in a shared vocabulary space. The embeddings are then processed through various layers of the neural network, such as transformers in the case of advanced LLMs. The model learns to predict the subsequent token in the sequence, refining its internal representations to understand context and semantics progressively.
Embeddings derived from tokens help the model to internalize semantic relationships. For instance, the tokenized words “dog” and “puppy” might end up close to each other in the embedding space, reflecting their semantic similarity. Over time, as the model processes millions of such token sequences, it constructs a rich lattice of interrelated meanings that enable sophisticated language tasks.
In inference, tokens are equally critical. When given a new input, the model tokenizes the text to form a sequence of tokens. These tokens are then passed through the trained network to generate a response. This process involves predicting the next most likely token in a sequence based on the learned probability distributions from the training phase.
Consider an inference scenario where an input sentence like “What is the capital of” is provided. The token sequence generated by the text input primes the model to internally predict the next word, which could be “France,” translating into “Paris.” The accuracy in inference hinges on the model’s learned ability to correlate tokens representing “capital” and “France” with “Paris” through a cascade of contextual probabilities.
Tokens also play a role in defining the scope and limitations of inference. Each LLM has a maximum token limit it can handle, which affects how much of the input can be processed at once. Managing token counts is vital for developers seeking to optimize model outputs without truncation. For example, a model might not accurately process an input if the tokenized segment exceeds the model’s capacity, leading to incomplete or biased output.
Overall, tokens form the bridge between raw text data and the intricate computations within language models, transforming discrete linguistic inputs into a form amenable to intensive machine learning processes. Mastery over tokenization and token management is therefore essential for developers to fully harness the potent capabilities of large language models.
Impact of Tokenization on Model Performance
Tokenization plays a crucial role in the overall performance of large language models (LLMs), influencing both their accuracy and efficiency. An effective tokenization strategy can significantly enhance the model’s seamless understanding and generation capabilities, while a suboptimal approach may impede performance and distort the intended output.
The impact of tokenization stems largely from how it manages vocabulary size and model complexity. Tokenization methods that create a very large vocabulary can lead to inefficiencies, as the model needs to allocate more resources to handle such a comprehensive lexicon. This situation often requires larger model architectures or increased computational power, thereby raising the cost and time involved in both training and inference. Conversely, a smaller, more refined set of tokens can streamline these processes, improving both speed and scalability.
Moreover, efficient tokenization directly addresses issues related to generalization. Models trained on data tokenized at an optimal granular level are usually better at generalizing from their training data to unseen inputs. For instance, subword tokenization, such as Byte Pair Encoding (BPE) or Unigram, breaks down unknown or novel words into smaller, more frequent units. This allows the model to reinterpret these defined chunks in varied contexts, enhancing its adaptability to novel lexical inputs while maintaining meaningful representations.
Tokenization also affects contextual understanding and semantic comprehension. By breaking text into consistent and contextually relevant tokens, the model can incorporate a richer understanding of the input, capturing not just word-level semantics but subtle linguistic nuances. For example, in a sentence such as “The startup launched an unexpected success,” word-level tokenization would treat “success” as standalone. In contrast, subword-level tokenization might capture “un-“, “expect-“, and “ed” as building blocks, allowing the model to glean additional linguistic and semantic relationships.
Additionally, the choice of tokenization influences memory and computational resource requirements. A model must store and manipulate tokenized data during runtime, and a tokenization approach that leads to disproportionately lengthy sequences can exhaust memory resources, slowing down the computation. Choosing methods like subword tokenization can mitigate this, as they often result in shorter model inputs compared to character-level tokenization, without sacrificing the richness of data representation.
Furthermore, tokenization impacts how syntactical structures are represented. For complex languages with heavy inflection, traditional word tokenization can easily miss syntactical cues carried through morphemes. By adopting granular tokenization techniques such as BPE, models are equipped to handle a broader array of languages and linguistic structures, which is particularly beneficial in multilingual models or when the target audience encompasses diverse linguistic backgrounds.
In the aspect of inference latency, tokenization methods that produce shorter token sequences can drastically reduce the time it takes models to generate responses. This optimization ensures that models working in real-time applications, such as conversational AI or interactive language tools, can maintain the fluidity and naturalness expected by users without compromising on response quality.
Lastly, the adaptability of tokenization methods to domain-specific applications is another performance-enhancing consideration. Domain-specific tokenization can optimize a model’s performance by tailoring the token set to reflect the unique vocabulary and syntactical features of specific fields such as law, medicine, or technology. Implementing customized tokenization strategies helps to ensure that models trained in these domains effectively understand context, jargon, and nuances pertinent to the field, critically enhancing their utility and effectiveness.
In essence, the tokenization process forms a foundational pillar that supports the efficiency, versatility, and capability of large language models. By impacting how vocabulary is managed, context understood, and data processed, tokenization is instrumental in determining the performance ceiling of LLMs, shaping their ability to execute sophisticated natural language tasks across varied domains. This underscores the necessity for careful and strategic tokenization in developing and deploying successful language models.
Challenges and Considerations in Tokenization
Tokenization, a critical process in natural language processing, involves several key challenges and considerations, particularly when applied to large language models (LLMs). These concerns are pivotal in shaping how efficiently and effectively models understand and process language data.
One primary challenge in tokenization is dealing with language variability and complexity. Languages differ vastly in terms of structure, grammar, morphology, and syntax. For example, languages like English, with clear word delimiters, offer more straightforward tokenization compared to languages like Chinese or Japanese, which lack spaces between words. Moreover, agglutinative languages like Finnish, which form complex words by stringing together morphemes, require advanced tokenization strategies to preserve meaning.
Another significant consideration is out-of-vocabulary (OOV) handling. No matter how extensive a model’s vocabulary is, it will inevitably encounter words or phrases it hasn’t been trained on, especially in domains with rapidly evolving jargon. Subword tokenization methods like Byte Pair Encoding (BPE) or WordPiece can mitigate this by breaking unknown words into smaller, known units that the model has encountered before. For instance, “unpredictable” might be split into “un-“, “predict-“, and “-able”, which are then processed separately.
Furthermore, the trade-off between vocab size and computational efficiency must be carefully balanced. A larger vocabulary can encompass more linguistic expressions and subtleties, but it demands more computational resources during both training and inference. Conversely, too small a vocabulary may lead to information loss or reduced model precision. Optimizing this balance is crucial, particularly given the higher computational costs associated with running large-scale models.
Standardizing tokenization across multilingual datasets poses another layer of complexity. Tokenization methods must be universally applicable to maintain consistency and prevent bias towards specific language features. For instance, using a universal subword vocabulary across languages can help models understand multilingual input efficiently but may not capture language-specific nuances, thereby potentially degrading performance on low-resource languages.
Maintenance and improvement of tokenization methods are vital as language models adapt to new languages and contexts. Continuous research and refinement of techniques to handle diverse languages and linguistic phenomena are necessary. Innovating in tokenization can lead to more robust models capable of adapting to a broader range of inputs, which is essential for models deployed in dynamic environments.
Tokenizing text efficiently also involves processing speed and latency considerations. In real-time applications, how quickly a model can convert text into tokens and back affects user experience. An inefficient tokenization process can introduce delays, reducing the practicality of models in conversational AI or live translation systems.
In addition, privacy and ethical considerations in tokenization cannot be overlooked. The choice of tokenization method could inherently privilege certain linguistic groups or expose sensitive information if not properly managed. These ethical considerations require tokenization processes to be designed with fairness and security in mind, ensuring that models equitably represent all language varieties and safeguard privacy.
Overall, the tokenization process in LLMs must navigate various challenges with foresight and precision. Careful consideration of language-specific and technical factors is essential to implement tokenization strategies that are not only efficient but also inclusive and adaptable to future linguistic developments.