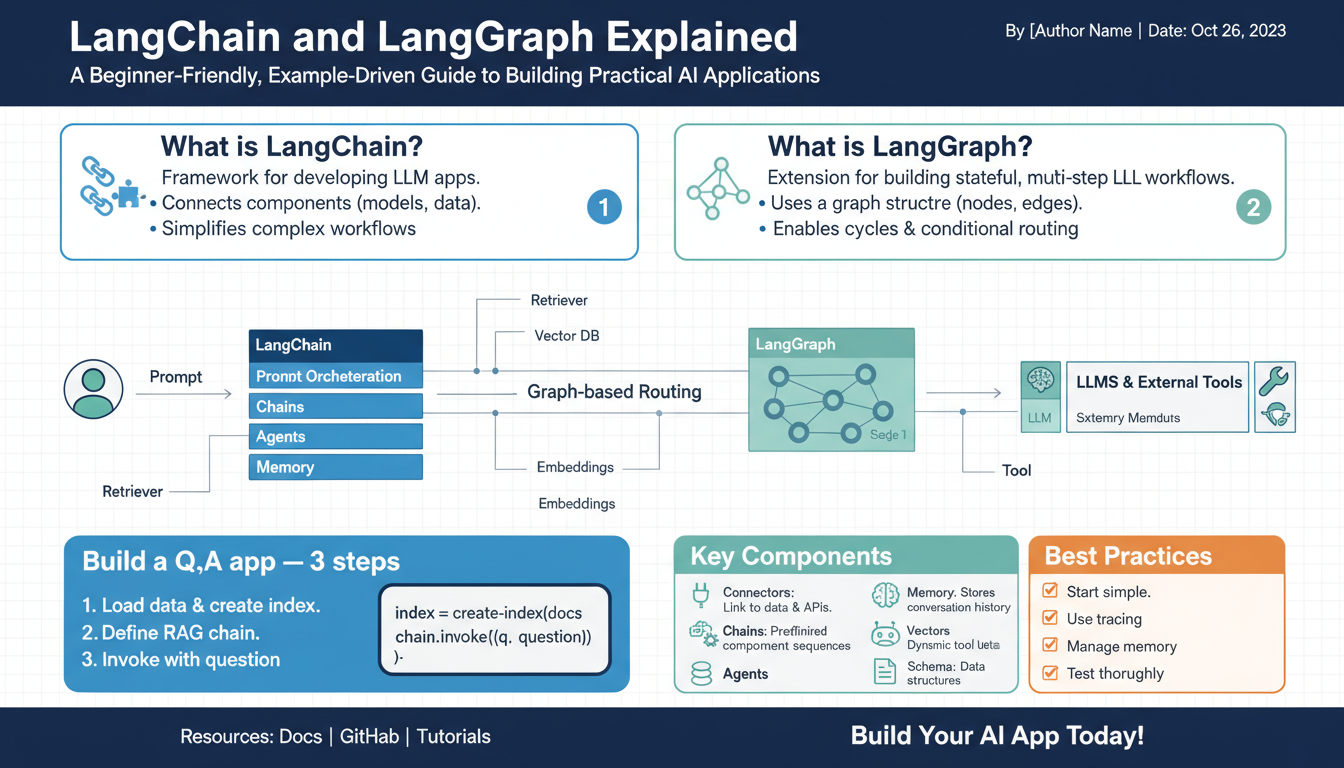
What are LangChain and LangGraph?
LangChain is an open-source framework (Python and JavaScript) for building applications that orchestrate large language models (LLMs) with external data, tools, and workflows. It provides composable building blocks — prompt templates, chains (multi-step pipelines), tool wrappers, and agent patterns — so you can rapidly assemble RAG systems, chatbots, document-Q&A, and other LLM-driven apps without wiring every integration from scratch. (langchain.com)
LangGraph is a complementary library focused on agent orchestration: graph-style, low-level primitives that make it easy to express cyclical control flow, multi-agent coordination, long-running state, and human-in-the-loop checkpoints. It’s built to add precision and persistence to agentic workflows so agents can maintain memory, stream reasoning, and handle complex control flows reliably. (blog.langchain.com)
In practice, use LangChain when you want fast composition of standard LLM workflows and integrations; reach for LangGraph when your application needs durable state, multi-actor logic, advanced control flow, or production-ready long-running agents (deployed via LangGraph Platform / LangSmith deployment options). (langchain.com)
Core concepts and differences
LangChain provides composable, high-level primitives for fast LLM app assembly: prompt templates, chains (linear or nested pipelines), tool wrappers, and agent patterns. It’s optimized for ephemeral, request-driven workflows like RAG-based document Q&A, chatbots, and simple agentic tool use where you mostly care about gluing models to data and external APIs quickly.
LangGraph focuses on graph-style orchestration and durable agent logic. Its primitives express cyclical control flow, stateful nodes, multi-agent coordination, retries, and human-in-the-loop checkpoints—features that matter when workflows must run over time, preserve memory, or coordinate multiple actors and decision points.
The practical differences boil down to composition vs orchestration. LangChain favors straightforward composition and rapid prototyping; state is typically short-lived and tied to a request. LangGraph targets complex control flows, persistent state, and observable, long-running processes where you need deterministic handoffs, checkpoints, and fine-grained orchestration of agents.
When to pick which: use LangChain for fast RAG pipelines, conversational assistants, or tool-enabled prompts you can model as chains. Use LangGraph for background agents, multi-step approval flows, distributed reasoning that requires retrying, pausing, or long-term memory. They’re complementary—LangChain components (prompts, tools, small chains) often live inside LangGraph nodes to combine quick composition with robust, orchestrated execution.
Install and setup
Quickly get a dev environment ready by using a dedicated virtual environment for Python or a modern Node runtime for JavaScript. For Python, create and activate a venv, then install the core packages and any provider integrations you need, for example:
python -m venv .venv && source .venv/bin/activate
pip install -U langchain langchain-openai langgraph
Set your provider credentials as environment variables (for OpenAI: OPENAI_API_KEY) before running code. Verify installation by importing the libraries in a short REPL or script (import langchain, langgraph). (docs.langchain.com)
For JavaScript/TypeScript, ensure Node.js 18+ and initialize a project, then install LangChain plus the LangGraph package and provider adapters you need:
node -v # confirm >=18
npm init -y
npm install langchain @langchain/core @langchain/langgraph @langchain/openai
Load credentials via environment variables (e.g., process.env.OPENAI_API_KEY) and run a tiny script to import langchain and @langchain/langgraph to confirm everything resolves. The JS ecosystem separates core and provider packages, so add integrations as needed. (js.langchain.com)
Once installed, start with a minimal example that calls an LLM through your chosen provider to confirm networking and API keys work; then add persistence or orchestration (datastores, LangGraph nodes) as your app grows.
Simple LangChain walkthrough
Build a tiny retrieval-augmented LangChain app to answer questions from a document set in a few lines. The flow: load and split documents, create embeddings, index with a vector store, attach a retriever, wire a chat LLM and a prompt, then run a retrieval chain.
# minimal Python example
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
# 1. load + split
loader = TextLoader("docs/manual.txt")
docs = loader.load()
splitter = CharacterTextSplitter(chunk_size=800, chunk_overlap=100)
chunks = splitter.split_documents(docs)
# 2. embeddings + vector store
emb = OpenAIEmbeddings(model="text-embedding-3-small")
vector_store = Chroma.from_documents(chunks, embedding_function=emb, persist_directory="./chroma_db")
retriever = vector_store.as_retriever(search_kwargs={"k": 4})
# 3. LLM + prompt
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
system = "Use the context to answer concisely. If unknown, say you don't know. Context: {context}"
prompt = ChatPromptTemplate.from_messages([("system", system), ("human", "{input}")])
qa_chain = create_stuff_documents_chain(llm=llm, prompt=prompt)
chain = create_retrieval_chain(retriever=retriever, question_answer_chain=qa_chain)
# 4. run
resp = chain.invoke({"input": "How do I reset the device to factory settings?"})
print(resp)
Tips: keep chunks <1k tokens, tune k for recall vs. noise, and pick an embeddings model that balances cost and quality. Persist your Chroma DB to avoid re-embedding on every run. This pattern is a compact, production-ready starting point for RAG Q&A with LangChain.
Build a LangGraph pipeline
Start by modeling a central state (TypedDict or MessagesState) that every node reads and updates. Write small, single-purpose node functions that return partial state updates (not in-place mutations). Use StateGraph to wire nodes, edges, entry point, then compile and invoke the graph to run the pipeline.
Example (Python):
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START
from langchain.chat_models import ChatOpenAI
from langchain.messages import HumanMessage, AIMessage
class State(TypedDict):
messages: list
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
def add_user_message(state: State):
# accept incoming user text via state on invocation
return {"messages": state.get("messages", [])}
def generate_reply(state: State):
history = state.get("messages", [])
user_text = history[-1]["content"] if history else "Hello"
resp = llm([HumanMessage(content=f"Reply concisely to: {user_text}" )])
# normalize LangChain chat output into AIMessage-like dict
return {"messages": history + [{"role": "assistant", "content": resp.content}]}
builder = StateGraph(State)
builder.add_node("add_user_message", add_user_message)
builder.add_node("generate_reply", generate_reply)
builder.add_edge(START, "add_user_message")
builder.add_edge("add_user_message", "generate_reply")
graph = builder.compile()
result = graph.invoke({"messages": [{"role": "user", "content": "How do I reset the device?"}]})
print(result["messages"][-1]["content"])
Keep nodes focused, use reducers (Annotated fields) to accumulate lists safely, add retry policies or node caching where latency or external calls matter, and employ Send/Command for fan-out/fan-in or explicit control-flow hops. Persist compiled graphs and enable LangSmith/LangGraph tracing for observability in production.
Deployment, testing, and monitoring
Containerize and pin runtimes so deployments are reproducible: use a multi-stage Dockerfile (build → runtime), freeze dependency versions, and bake a small health-check endpoint. Keep secrets out of images—inject API keys and provider credentials at runtime via your orchestration platform or a secret manager. Persist vector stores and LangGraph state on durable volumes or managed stores; snapshot and restore procedures should be part of your runbook.
Automate quality gates in CI: run unit tests, linters, and static analysis on every PR; run fast integration tests with mocked LLM responses and a lightweight vector-store instance; run nightly end-to-end tests against a staging environment with real provider quotas. Deploy through a staged pipeline (CI → staging → canary/blue-green → production) and include automated rollbacks on elevated error rates or cost anomalies.
Test components at the right granularity. Unit-test prompt templates, input validation, and tool wrappers with deterministic fixtures. For LangGraph, unit-test node functions against representative state objects and assert state transitions. Use recorded-response fixtures or provider sandboxes for integration tests to avoid flakiness and cost. Add contract tests for retriever behavior (k, similarity thresholds) and for agent/tool interfaces.
Add observability from day one: structured logs (JSON) with request IDs, compact metrics for request count, latency, error rate, token usage, and embedding calls, and distributed traces that map chains or graph nodes to downstream calls. Mask or redact sensitive data in logs and sampled prompts. Configure alerts for high latency, increased hallucination rates (via QA checks), token-usage spikes, and storage fill levels.
Harden runtime resilience with retries + exponential backoff, circuit breakers, and rate-limiting. Cache embeddings and retriever results where appropriate to reduce cost and latency. Use canary traffic and progressive rollout to validate real-user behavior, and run periodic chaos/failure drills for backup, network, and provider failures.



