Design goals and requirements
Design decisions should start from measurable goals: data correctness and integrity, predictable latency (SLA), throughput, availability targets, cost limits, and maintainability as the system evolves. Translate those goals into requirements such as read/write ratio, acceptable consistency (strong vs eventual), transaction scopes, retention and archival policies, compliance and security constraints, and expected growth rates.
Map requirements to concrete schema choices. Use normalization to eliminate update anomalies and keep write paths simple; apply denormalization selectively for hot read paths where join cost violates latency targets. Pick primary keys that suit partitioning and joins (surrogate keys like integer/UUID for stability, natural keys only when immutable). Design foreign keys and constraints where data integrity matters; consider enforcing integrity in the application only when constraints would create unacceptable write contention.
Index and partition with the workload in mind: create covering and composite indexes following left-prefix rules, avoid over-indexing on heavy-write tables, and choose partition keys that align with query predicates to limit scan scope. For scale, prefer predictable partitioning/sharding keys, and plan for re-sharding/migrations. Specify monitoring, alerting, and capacity thresholds up front, plus a migration/versioning strategy (backward-compatible changes, phased rollouts). Finally, document trade-offs clearly so future engineers can reason about performance, consistency, and operational costs.
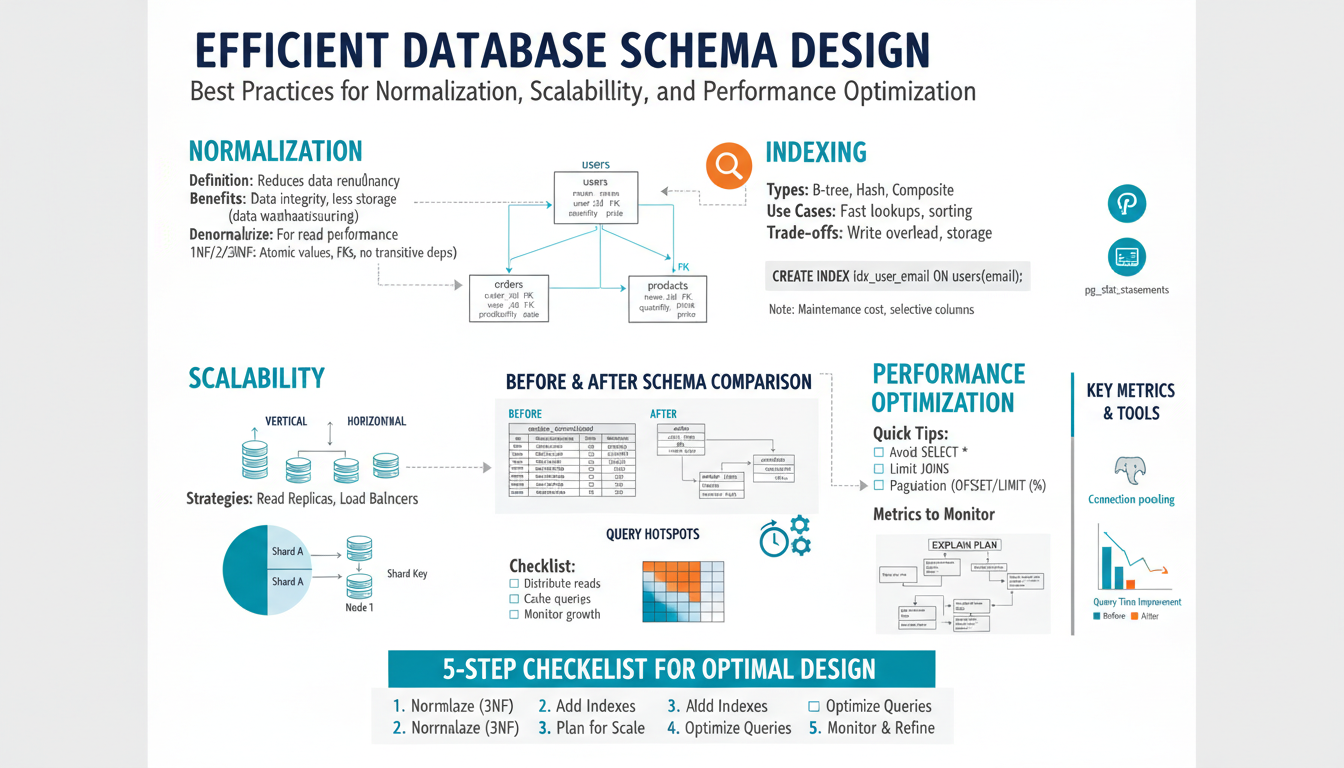
Normalization fundamentals
Normalization organizes data to eliminate update anomalies, reduce redundancy, and make write operations predictable. Start by enforcing atomic columns and consistent row structure so each field holds a single value and repeating groups are removed; this prevents ambiguity during inserts and simplifies indexing. Remove partial dependencies by separating attributes that depend on only part of a composite key into their own table, then remove transitive dependencies so non-key columns depend directly on the primary key. Aim for third normal form for most OLTP schemas; use Boyce–Codd Normal Form when overlapping candidate keys introduce subtle anomalies.
Model relationships explicitly with foreign keys to express intent and enable declarative integrity, but weigh enforcement cost: in high-concurrency write paths you may enforce integrity in application logic to avoid locking hotspots. Choose stable primary keys—surrogate keys are generally safer for joins and partitioning, natural keys only when truly immutable.
Normalization is a design baseline, not a dogma. For hot read paths where joins exceed latency targets, apply targeted denormalization: duplicate read-critical columns, use materialized views, or precomputed aggregates. When denormalizing, document invariants and implement single-writer patterns or background reconciliation to maintain consistency.
Validate normalization decisions by mapping common queries and write patterns to the schema: measure join costs, index selectivity, and write amplification. Keep schemas simple where correctness is paramount; selectively relax normalization only when driven by measurable performance constraints.
Denormalization trade-offs
Duplicating read‑critical columns or whole rows can drastically reduce latency by removing joins, enabling covering indexes, and simplifying query paths for hotspots. The payoff is faster, more predictable reads and often lower CPU/IO on read-heavy workloads, especially when SLAs require single-digit millisecond responses or when joins span sharded partitions and become expensive.
Those gains come with tangible costs: increased storage, more complex write logic, and a higher risk of inconsistency. Every duplicate copy creates an invariants problem — updates must be propagated (synchronously or asynchronously), introducing write amplification, possible latency spikes, and stale reads. Denormalization also complicates schema migrations, testing, and reasoning about correctness; multi-writer scenarios raise conflict resolution issues that normalized designs avoid.
Mitigate downsides by applying denormalization selectively and instrumenting it. Keep a single source of truth and implement deterministic update flows: single-writer ownership where possible, event-driven propagation or change-data-capture for eventual updates, and periodic reconciliation jobs. Use materialized or indexed views when the DB can maintain them atomically. Track divergence with metrics (staleness, failed syncs, reconciliation rate) and make rollback/repair paths explicit. Quantify benefits before committing: measure join cost, index selectivity, read/write ratio, and end‑to‑end SLA improvements. When in doubt, prefer targeted, reversible denormalization with clear ownership and automated repair over blanket duplication.
Choose data types wisely
Pick types that express intent and minimize storage and CPU work. Use the smallest numeric type that safely covers current and projected ranges: INT for counts under ~2 billion, SMALLINT/TINYINT for tight enums or flags, BIGINT only when growth or external IDs demand it. Prefer fixed‑precision DECIMAL (or NUMERIC) for money to avoid rounding errors; use FLOAT/DOUBLE only for scientific or approximate calculations. Store dates and times in native DATE/TIMESTAMP types instead of strings; choose timezone-aware types when your system spans regions and normalize to UTC for storage when appropriate.
For strings, prefer VARCHAR with sensible length limits over unbounded text; use CHAR for short, fixed-length codes (ISO country codes, fixed hashes) to reduce overhead. Use database-native UUID types rather than CHAR(36) when using UUIDs. Avoid booleans stored as integers or strings. Prefer enums when the domain is stable and small—enums reduce storage and improve clarity—but use lookup tables if the set changes often. Use JSON/JSONB for semi‑structured data that varies per row, but keep frequently queried fields as first-class columns and index JSONB paths only when necessary.
Design for indexing and joins: use compact, fixed-size keys for primary/foreign keys to reduce index size and cache pressure. Make NULLability explicit—nullable wide columns increase storage and complicate indexes. Add CHECK constraints to encode invariants instead of relying on application logic. Finally, test with realistic data: measure row size, index footprint, and query latency; iterate when growth or query patterns reveal a different tradeoff.
Indexing strategies and maintenance
Design indexes to reflect actual query patterns: build single-column indexes for high-selectivity predicates and composite indexes where queries filter or sort on multiple columns, ordering columns by the most selective/most-used left-prefix first. Use INCLUDE (or equivalent) to create covering indexes so frequent SELECTs avoid lookup to the base table; prefer compact keys (integers/short UUID types) to reduce index footprint and cache pressure. Avoid indexing low-selectivity columns and be conservative on heavy-write tables—each index increases write amplification and storage.
Apply filtered/partial indexes and expression/index-on-computed-columns when predicates or computed values are common but sparse (for example, WHERE deleted = false or indexing lower(email)). For full-text or multi-value searches choose specialized index types (GIN/GiST) but test write/read trade-offs; bloom or hash indexes can help niche cases.
Operational maintenance must be proactive. Track index usage and effectiveness; remove unused indexes and measure latency/IO impact before and after changes. Schedule ANALYZE after bulk loads and ensure regular VACUUM (or the DB’s MVCC cleanup) to keep visibility maps current so index-only scans are possible. Set a sensible fillfactor for update-heavy tables to reduce page splits and consider periodic REINDEX or concurrent rebuilds to eliminate bloat without major downtime. Use online/concurrent index creation during maintenance windows for large tables.
For partitioned schemas, align index strategy with partition keys so queries hit fewer partitions and maintain per-partition indexes if supported. Finally, quantify index ROI: measure query latency, CPU/IO, and write amplification before adding or removing indexes and automate monitoring/alerts for growth, bloat, and unused-index trends.
Partitioning and sharding
Scale horizontally by splitting large tables so queries touch only a small subset of rows. Choose a distribution key that matches common predicates and join keys: use tenant_id or customer_id to colocate related rows, use time-range partitioning for append‑heavy series, and prefer a stable, low‑cardinality component combined with a high-cardinality identifier when needed. Avoid keys that create hotspots (strictly sequential IDs) or high cross-shard joins (unrelated foreign keys).
Pick a split strategy that fits operational constraints: hash-based placement gives even size distribution and simple routing; range-based placement supports efficient time/window queries and ordered scans but requires careful rebalancing. Implement a routing layer or lookup table for shard resolution and plan for online resharding: use background copy with dual‑writes, epoched metadata changes, and throttled backfills to limit impact. Use consistent hashing or virtual shards to simplify rebalancing and reduce data movement.
Keep related indexes and transactions localized by colocating frequently-joined tables in the same shard or using composite keys that include the shard identifier. For replicated systems, combine replication for durability with partition-aware failover to preserve locality. Monitor per-partition size, latency, and hotspot metrics; alert on skew and growth thresholds. Test reshard workflows, schema changes, and recovery paths with production-like data. Treat migrations as first-class features: versioned schemas, backward-compatible reads, and deterministic reconciliation jobs for eventual consistency. Prioritize predictable query paths and operational simplicity over theoretical balance—practical, observable behavior under real workloads wins.



