Why RAG noise matters
Retrieval errors and low‑quality matches inject irrelevant or misleading text into the LLM’s context; the model then treats that material as authoritative. That single failure mode cascades: factual contradictions and hallucinations become more frequent, answers drift off-topic, and confidence scores no longer correlate with truth. Practically, noisy retrieval increases token usage and latency because the model must read and reconcile more content, and it makes debugging much harder since errors originate in both retrieval and generation stages.
Noise arises from many concrete sources: poor embedding alignment that surfaces semantically distant chunks, stale or corrupted documents, overly large chunks that mix topics, OCR artifacts, duplicate passages that bias outputs, and weak rerankers that leave low‑precision hits near the top. These lead to brittle behavior in downstream tasks like summarization, question answering, and decision support, and they amplify bias when low‑quality sources dominate retrieval.
Mitigating noise is essential for reliability: clean, well‑chunked corpora, strict score thresholds, provenance metadata, reranking with cross‑encoders, and lightweight filters (deduplication, language checks, date checks) reduce the chance that irrelevant text will sway the model. When retrieval is dependable, the LLM’s outputs become both more accurate and more predictable—saving compute, improving user trust, and simplifying maintenance.
Identify noise types
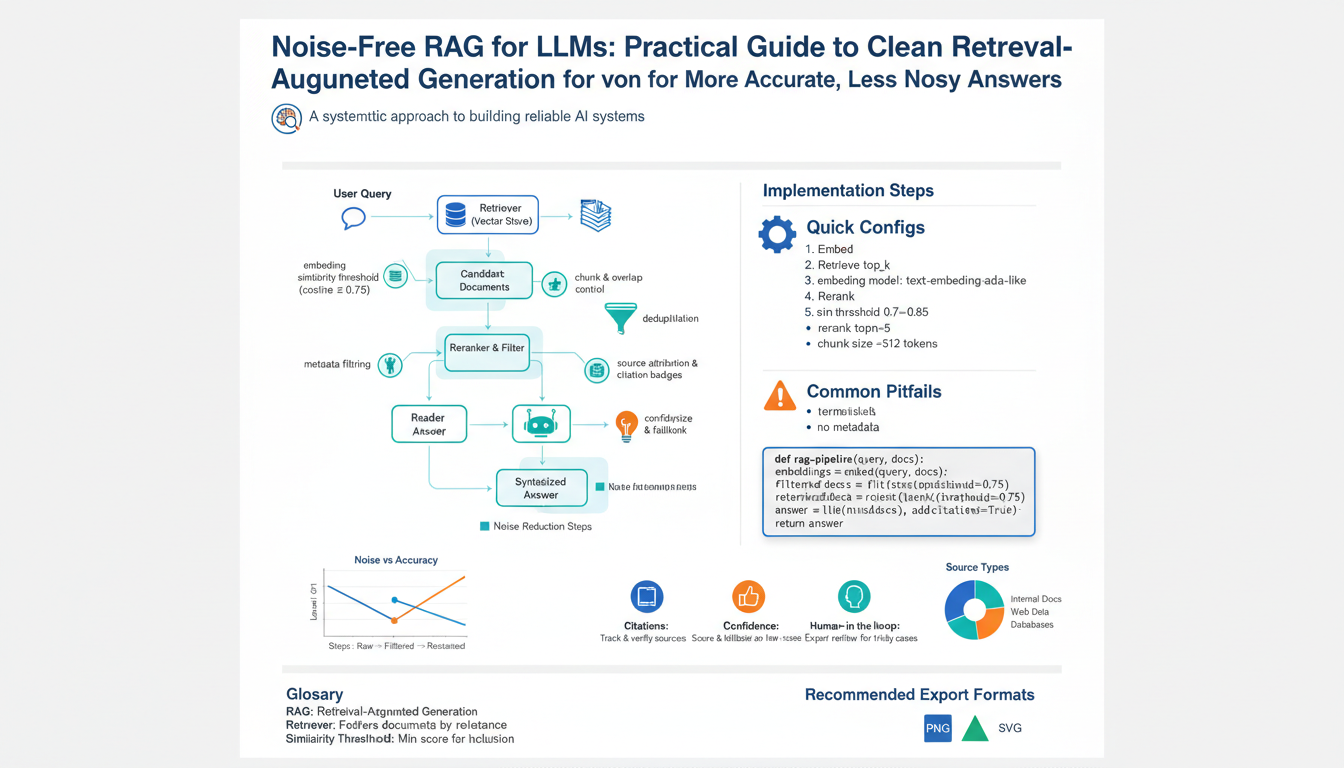
Start by grouping the retrieval errors you actually see into concrete categories so fixes map to root causes. Semantic mismatch occurs when embeddings surface topically or lexically similar but factually irrelevant chunks; signals include low cross‑encoder rerank scores and user queries answered by contradictory passages. Stale or time‑drifted content shows up as out‑of-date dates, versioned docs, or policies that conflict with recent facts. Chunking errors arise from oversized or mixed‑topic segments that confuse context—detection: abrupt topic shifts inside a single chunk and unusually long token spans. OCR/transcription noise produces garbled tokens, missing diacritics, or character substitution; check OCR confidence and language detector drops. Duplicates and near‑duplicates bias retrieval toward repeated opinions; detect with hashing or high pairwise cosine similarity. Metadata and provenance failures (wrong dates, missing source IDs) break trust and traceability. Low‑quality source content—spam, forum noise, scraped aggregators—yields high perplexity or shallow factuality on verification prompts. Reranker failures surface when lexical‑based scores disagree with semantic reranks. Finally, adversarial or poisoned passages intentionally mislead; detect via anomaly detection on retrieval distributions and manual spot checks. For each type, capture automated signals (scores, timestamps, OCR confidence, similarity metrics) so triage and mitigation become systematic rather than ad hoc.
Improve retrieval accuracy
Start by staging retrieval: run a fast bi‑encoder or lexical pass to produce a candidate set, then rerank the top N with a cross‑encoder (or poly‑encoder where latency matters) so the model judges query–document interactions rather than relying only on embedding proximity. (arxiv.org)
Combine lexical and semantic signals instead of choosing one. Hybrid fusion (BM25 + dense vectors) or rank‑fusion methods capture exact keyword matches and paraphrased semantics; normalize score ranges and calibrate weights on a small dev set to reduce cases where dense vectors return lexically irrelevant hits. (elastic.co)
Make chunks atomic and consistent so similarity maps to single facts. Prefer paragraph‑level or semantic chunks with a practical target (roughly 200–500 tokens or ~50–150 words for many corpora) and add modest overlap (10–20%) to preserve context across boundaries; use recursive or semantic splitting for long, mixed‑topic documents. Smaller, coherent chunks improve precision and reduce contradiction in the LLM prompt. (machinelearningmastery.com)
Remove duplicates and junk before indexing. Apply near‑duplicate detection (LSH/minhash or scalable variants like LSHBloom), drop low‑confidence OCR text, filter by language and date, and tag provenance so you can trace which source produced a retrieved passage. Deduplication and basic quality filters stop noisy, repeated content from biasing downstream answers. (arxiv.org)
Enforce strict thresholds and measure retrieval quality continuously: track Precision@K, MRR and nDCG on representative queries, tune candidate size N and reranker cutoffs to optimize precision@top‑k, and log scores plus provenance for post‑hoc triage. Use small, labeled query sets to recalibrate as documents or query patterns drift. (github.com)
Chunking and contextual compression
Split source text into atomic, single‑fact segments so each retrieved chunk maps to one coherent idea—semantic or paragraph boundaries work better than fixed‑character slices. Target chunks around 200–500 tokens (~50–150 words) with 10–20% overlap to preserve connective context across boundaries; treat named entities, dates, lists and tables as chunk anchors that shouldn’t be split mid‑item. Apply contextual compression to reduce token load while keeping truth: produce a short, query‑focused extractive summary (or neural compressor) that preserves entities, numeric facts, and any hedging language from the original. Index both the compressed snippet and a pointer to the original text plus token offsets so you can fall back when the compressor removes critical detail. Validate compressed outputs with a fast cross‑encoder or an NLI/entailment check: if the compressor introduces contradictions or low confidence, prefer the uncompressed chunk for retrieval. Use lightweight importance scoring (TF‑IDF, attention/Salience scores, or simple heuristics like sentence position and presence of entities) to choose which sentences survive compression; strip boilerplate, navigation text, and filler before summarization. Monitor metrics (Precision@K, MRR, hallucination rate on a dev set) and tune compression aggressiveness accordingly—when answers require high fidelity, reduce compression or increase chunk granularity. Finally, keep provenance metadata (doc ID, offset, original length, compression confidence) in every retrieval hit so downstream prompts can show source context or trigger fallback retrieval when needed. This balances lower token cost with safer, less noisy context for the LLM.
Filter and rerank passages
Start by treating retrieval hits as a candidate pool, not final answers: run a fast bi‑encoder or lexical pass to collect a broad set (e.g., 100–200 candidates) then rerank the top slice with a stronger interaction model (cross‑encoder or poly‑encoder when latency matters). Use normalized scores so hybrid signals (BM25 + dense) compare fairly, and calibrate reranker cutoffs on a small labeled dev set to hit your desired Precision@K.
Apply deterministic filters before reranking to remove obvious noise: drop duplicates and near‑duplicates, exclude low‑confidence OCR or wrong‑language hits, and enforce date or provenance constraints when timeliness matters. Add a lightweight diversity penalty so multiple near‑identical passages don’t dominate top slots; prefer unique evidence spanning different sources.
Rerank with both relevance and fidelity signals. Combine a semantic relevance score from the cross‑encoder with a quick entailment/NLI or fact‑consistency check against the query or a canonical knowledge base. Boost passages that score high on provenance (trusted domains, recent timestamps) and penalize those with known low quality (thin pages, boilerplate). Keep the raw scores and a composite score so thresholds remain interpretable.
Implement soft and hard cutoffs: a hard lower bound removes obviously irrelevant passages; a softer threshold limits how many lower‑confidence passages the LLM sees. When the top hit’s margin is small or contradiction appears across top passages, trigger a fallback: fetch more candidates, run a targeted verifier, or surface provenance to the user.
Continuously monitor Precision@K, MRR and hallucination rate on representative queries and log per‑hit metadata (doc ID, offset, scores, compression confidence). Tune candidate size, reranker depth, and thresholds based on those metrics to keep the retrieval context high‑precision and low‑noise.
Grounding, verification, and provenance
Treat retrieved passages as evidence, not truth: always attach a compact evidence packet (source domain, document ID, timestamp/version, byte/token offsets, compression confidence) to every chunk returned to the LLM. Use that metadata to build answer text that can show which exact snippet supports each claim and to enable fast fallbacks to the original passage when verification fails.
Run automatic verification before answer synthesis. First rerank top hits by relevance and fidelity, then apply a lightweight entailment/NLI check between the claim and its supporting snippet; flag low‑entailment pairs for exclusion. Where numeric or date facts matter, run deterministic extractors (regex/NER) and cross‑compare values across multiple high‑confidence sources; require a minimal consensus or a trusted‑source override. When the top evidence margin is small or sources disagree, trigger an expanded search and a targeted verifier rather than letting the LLM guess.
Score provenance and make it actionable. Compute a composite trust score combining source reputation (whitelist/blacklist tiers), freshness, compression confidence, and reranker/fidelity outputs; expose that score in logs and in any user‑facing attribution alongside quoted snippets. Persist hashes and offsets so auditors can reproduce exactly which bytes produced an answer.
Fail safely: suppress confident answers when verification is weak, surface partial results with clear attributions, and escalate to a human reviewer for high‑risk queries. Continuous logging of per‑hit metadata, verification outcomes, and downstream hallucination incidents lets you tighten thresholds and reduce noise over time.



