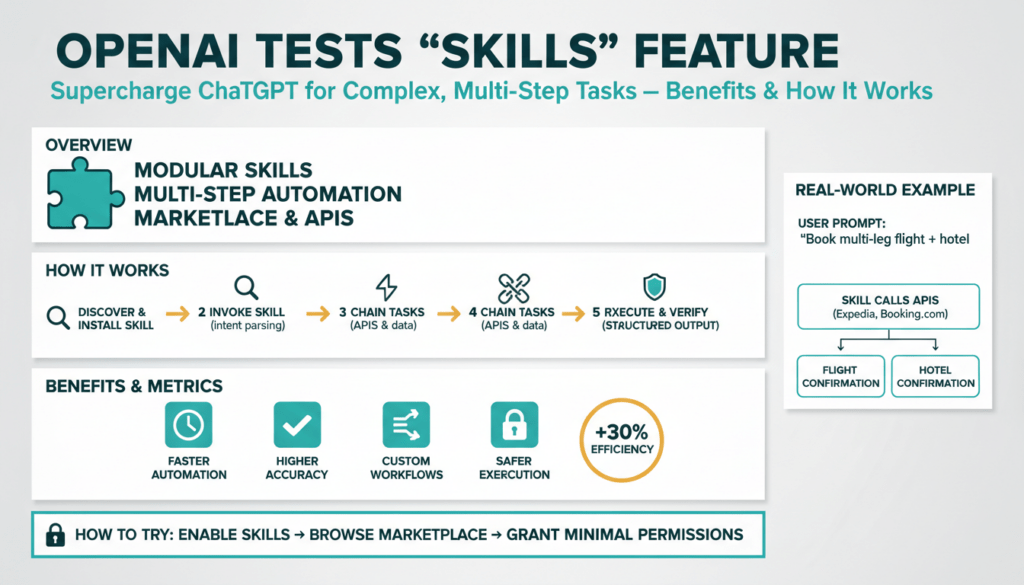
What are ChatGPT Skills?
Building on this foundation, think of ChatGPT Skills as discrete, self-contained capabilities that extend the model’s reasoning into external systems and long-running processes. At their core, these Skills act like typed function endpoints the model can call when a conversation requires domain-specific logic, authenticated API access, or deterministic side effects. You’ll see them referenced as a Skills feature, and they’re designed to make the model reliable for complex, multi-step tasks where plain generative text alone is insufficient.
A Skill bundles three things: a clear interface (input/output schema), an execution handler (the code or service that performs actions), and metadata for safety and routing. The interface enforces types and validation so the model produces structured calls rather than ambiguous text; the handler performs actions such as querying databases, invoking CI pipelines, or calling third-party APIs; and the metadata defines permissions, rate limits, and user-facing descriptions. This separation reduces ambiguity during orchestration and gives you observability points for debugging and auditing.
Technically, Skills let you move from a single-turn completion to orchestrated, stateful flows. When the model decides a Skill is appropriate, it emits a structured invocation (for example, an object with named fields and types) that your runtime maps to a handler. The handler executes, returns a typed response, and the model consumes that response to continue planning the next step. Because the Skill contract is explicit, you can compose multiple Skills in sequence, parallelize calls, and persist intermediate state for checkpointing or retries in failure scenarios.
To illustrate, imagine a release automation workflow. You ask the assistant to “ship the hotfix.” The model reasons about required steps, calls an authentication Skill to obtain deploy credentials, invokes a CI Skill to run tests and collect artifacts, then uses an orchestration Skill to deploy to staging and create a production rollout ticket. Each step produces structured outputs the model uses to decide next actions: whether tests passed, which artifact to promote, or whether to abort and notify stakeholders. This pattern maps directly to real-world developer tasks like incident triage, deploy gating, and cross-system reporting.
Why choose Skills over ad-hoc prompts or single-purpose plugins? Skills give you predictable input/output contracts, tighter access controls, and lifecycle management for capability code. That makes testing, versioning, and continuous delivery of Skills practical: you can run unit tests against a Skill handler, roll out new versions behind a feature flag, and audit calls in production. There are trade-offs—designing good schemas and handling partial failures requires engineering effort—but the payoff is reliable automation for multi-step tasks that would otherwise require brittle prompt engineering or custom middleware.
How do you integrate them into an existing pipeline? Start by identifying repeatable decision points in your workflows where the model needs deterministic actions—creating tickets, running test suites, provisioning resources—and model each as a Skill with a tight schema. We recommend instrumenting each Skill with clear logs and idempotency keys so you can replay or compensate when things go wrong. In the next section we’ll walk through a concrete implementation pattern and sample schemas so you can prototype a Skill-based automation in under an hour.
How Skills work technically
Building on this foundation, ChatGPT Skills function as a typed bridge between model reasoning and real-world side effects, enabling reliable, multi-step automation and making skill-based automation practical for engineering teams. At runtime the model emits a structured invocation rather than free-form text, and that contract—input schema, output schema, and metadata—drives deterministic routing, validation, and execution. You’ll see the same primitives we already discussed: a clear interface, an execution handler, and metadata for permissions and observability. This upfront typing is what shifts orchestration from brittle prompt engineering to engineering-grade automation.
Invocation begins as a small JSON-like object the model produces when it decides a Skill should run; for example {“skill”:”ci.run_tests”,”input”:{“sha”:”abc123”,”matrix”:”smoke”}}. The first technical responsibility is schema validation: use a schema language (JSON Schema or OpenAPI components) to validate fields, types, ranges, and required semantics before any handler executes. This prevents class-of-errors where the model emits a malformed call and creates a surface for safe retries and deterministic error messages, which you can then surface back into the reasoning loop.
Handlers live behind a routing layer that maps skill identifiers to endpoints—these can be serverless functions, containerized services, or managed third-party integrations. The router handles authentication exchange (short-lived tokens, mTLS, or signed assertions), rate limiting, and enrichment (injecting request metadata like correlation IDs and idempotency keys). For long-running or side-effectful operations, the handler should support asynchronous patterns: return an immediate accepted response with a job ID and provide a callback or status endpoint so the assistant can poll or subscribe to completion events.
State and orchestration are where Skills unlock multi-step flows. Because each Skill returns typed outputs, the model can checkpoint intermediate results into a workflow store and decide whether to continue, branch, or compensate based on those outputs. Implement durable checkpoints (database rows or workflow engine state) with idempotency keys so you can replay failed steps without duplicating effects. We often compose Skills in sequence for linear workflows and in parallel for fan-out tasks; the typed contract lets you merge results deterministically and resume from the last successful checkpoint after partial failures.
Security and auditability must be first-class. Attach scoped metadata to each Skill—required OAuth scopes, allowed caller principals, and an audit policy—so your router enforces least privilege automatically. Sign or timestamp invocations to prevent replay, log structured events for tracing, and keep an immutable audit trail (which includes request, response, and user attribution) for compliance. How do you ensure idempotency across retries? Use unique idempotency keys derived from the user request and inputs, and make handlers de-duplicate side effects based on those keys.
Productionizing Skills requires testing, versioning, and observability as core workflows. Write unit tests for handlers, contract tests against schemas, and integration tests that run in a sandboxed environment to validate end-to-end behavior. Canary new Skill versions behind feature flags and record metric-backed SLAs (success rate, latency, and cost per invocation). Building these practices turns ad-hoc automations into repeatable, auditable capability surfaces.
Taking this concept further, we’ll move from architecture to a hands-on implementation pattern that shows concrete schemas, sample handler code, and orchestration patterns you can use to prototype a Skill-based automation in under an hour. That next step will make these technical guarantees—validation, idempotency, async handling, and observability—concrete in code so you can evaluate how ChatGPT Skills fit into your CI/CD, incident response, or provisioning pipelines.
Benefits for multi-step tasks
Building on this foundation, ChatGPT Skills transform how you approach complex, multi-step tasks by replacing brittle, hand-crafted prompts with explicit capability contracts. You get a system that speaks typed schema instead of guesswork, which immediately reduces ambiguity when the assistant must coordinate across CI systems, cloud APIs, and ticketing tools. That clarity matters in the first interaction: the model emits a structured invocation you can validate and route deterministically, so the odds of a malformed request or a mistaken side effect drop dramatically. For engineers who automate releases, incident response, or provisioning, this shift is the difference between occasional magic and repeatable automation.
The most tangible benefit is predictable orchestration: because each Skill exposes an input/output schema, you can compose steps with deterministic expectations rather than relying on parsing free text. Typed schemas give you contract-driven control over branching, merging results, and handling partial failures; the runtime can validate fields before invoking a handler and reject invalid calls with clear, actionable errors. This predictability lets us parallelize where appropriate and serialize when necessary, which improves throughput without sacrificing correctness. In practice, that means fewer manual checkpoints and more confidence that the workflow will behave the same way in test, staging, and production.
Reliability improves because Skills make checkpointing and idempotency first-class concerns rather than afterthoughts. How do you maintain reliability when a workflow spans CI, infra, and notifications? Use durable checkpoints with idempotency keys derived from the user request so retries and replays are safe; record job IDs and statuses so the assistant can poll or resume after interruptions. When a test suite fails or an API times out, the assistant receives a typed response that explicitly encodes failure modes and retry recommendations, enabling programmatic compensation (rollback, notify, or escalate) instead of ambiguous human interpretation. That flow reduces mean time to recovery and prevents duplicated side effects.
Security and auditability become operational primitives rather than optional extras. Assigning scoped metadata to each Skill—required OAuth scopes, caller principals, and rate limits—lets the router enforce least privilege automatically and inject short-lived tokens or signed assertions at call time. Every invocation should carry correlation IDs and a signed timestamp so you can prove intent and prevent replay attacks; handlers should emit structured audit logs that include request payload, response, and user attribution. For compliance-sensitive workflows such as production deploys or billing changes, this audit trail is essential for post-incident analysis and regulatory reporting.
Testing, versioning, and observability are straightforward once you treat Skills like software components. Write unit tests for handlers, contract tests against the typed schema, and integration tests that exercise async patterns and failure modes. Instrument metrics for success rate, latency, and cost per invocation so you can canary new Skill versions and roll back if SLAs degrade. A minimal invocation pattern looks like this:
{"skill":"ci.run_tests","input":{"sha":"abc123","matrix":"smoke"},"idempotency_key":"user-42-abc123"}
The handler returns {“status”:”accepted”,”job_id”:”job-987”} immediately, and your workflow polls or subscribes to completion; use the idempotency_key to avoid duplicate artifact promotions during retries.
Operational velocity and developer productivity are the downstream payoffs. Because Skills are reusable, well-typed building blocks, teams can assemble complex automations from existing capabilities rather than rewriting integration glue for every request. That composability shortens time-to-automation for common scenarios—deploy gating, incident remediation, account provisioning—and gives operators clearer control over cost by isolating which Skill invocations are expensive. Taking this concept further, the next section will demonstrate concrete schemas and handler examples so you can prototype a Skill-based workflow end-to-end and validate these benefits in your own pipelines.
Enabling Skills in ChatGPT
Building on this foundation, the first step when you enable ChatGPT Skills is treating them like a deployable feature rather than a one-off prompt tweak. You should approach enabling as a short engineering project: confirm account eligibility, prepare a tight schema, and plan an integration test that verifies both function and safety. This early discipline prevents ambiguous or unsafe invocations later, and it frames skills as reusable, auditable capability surfaces you can ship and iterate on. ChatGPT Skills and skill-based orchestration behave very differently from informal prompt scripts, so treat them with the same lifecycle controls you use for any service.
Start by checking your workspace and access model because not every account surface exposes developer tooling by default. Developer-level features for connectors and tool integration are gated to specific plans and betas; enablement usually requires toggling developer mode or adding connectors in ChatGPT settings so the runtime can route structured invocations to your handlers. Verify which account roles can register or toggle Skills and restrict that ability to DevOps or automation owners to reduce blast radius. These platform-level steps are practical prerequisites before you deploy any schema or handler, and they’re documented in OpenAI’s developer-mode guidance for connectors and tools. (platform.openai.com)
Define the Skill contract before you wire up any runtime. Design a minimal input/output schema (JSON Schema or an OpenAPI component works well), include required fields, data types, and validation rules, and attach metadata describing required scopes, rate limits, and idempotency semantics. We prefer modeling idempotency keys and correlation IDs in the schema so handlers can deduplicate side effects automatically; include explicit error enums for transient vs permanent failures so the model can choose retries or compensations deterministically. This contract-first approach forces you to think through edge cases—what happens if the CI system returns a flaky test result, or if a deploy token expires mid-run—and it reduces the need for brittle prompt-level parsing later.
How do you validate a Skill before you flip it on for real users? Create a sandbox that mirrors production routing but uses test endpoints and synthetic credentials; run contract tests against your schema and unit tests for handler logic, and then run a small battery of integration flows through the developer-mode connector or your chosen orchestration gateway. Simulate long-running work by returning accepted/job_id responses from handlers and expose a status endpoint so the model can poll or subscribe to completion events. You should also run chaos cases—timeouts, partial failures, and duplicate invocations—to ensure idempotency keys and checkpointing behave as expected in real-world scenarios. These validation steps let you iterate on both schema and handler code with confidence before you expose the Skill to broader teams. (help.openai.com)
Operationalize security and observability as part of enablement rather than an afterthought. Enforce least privilege by attaching required OAuth scopes or signed assertions to the Skill metadata and let the routing layer inject short-lived credentials at call time; log structured events that include user attribution, correlation ID, and the full typed request/response for auditing. Implement an immutable audit trail and sample payload capture for post-incident analysis, and surface latency, success rate, and cost-per-invocation metrics so you can canary new Skill versions and roll back when SLAs degrade. Treat Skills like any other service you monitor: dashboards, alerts, and contract tests are what keep automation reliable under load. (help.openai.com)
Finally, enable discoverability and governance for the teams that will use these capabilities. Publish a short developer README for each Skill that explains its purpose, input contract, output schema, expected failure modes, and required scopes; version the Skill and release behind feature flags so you can test behavior in the wild with limited exposure. By integrating these practices into your CI/CD pipeline—unit tests for handlers, contract tests for schemas, and canary deployments for new versions—you convert experimental automations into repeatable, auditable workflows. Taking these steps when you enable skills gives your team the confidence to compose them into larger orchestration patterns without sacrificing security or reliability, and it sets up the next phase: implementing concrete schemas and handler examples to prototype a Skill-based automation end-to-end.
Build a basic Skill
Building on this foundation, we’ll implement a minimal, deployable ChatGPT Skills example so you can move from concept to running code quickly. What does the smallest useful Skill look like and when should you prefer a typed Skill over an ad-hoc prompt? The shortest path is a contract-first approach: define a tight input/output schema, write a small handler that enforces idempotency and returns typed responses, and wire the handler behind a router that injects credentials and observability. This pattern keeps the runtime deterministic and testable from day one.
Start by designing the contract. The primary purpose of the contract is to prevent ambiguous invocations from the model and to make validation trivial at the router level. A minimal JSON Schema for a CI test-run Skill might require a commit SHA and a matrix name and define explicit error enums so the assistant can decide retries deterministically. For example: { “type”:”object”,”required”:[“sha”,”matrix”],”properties”:{“sha”:{“type”:”string”},”matrix”:{“type”:”string”,”enum”:[“smoke”,”full”]},”idempotency_key”:{“type”:”string”}} } — include idempotency_key in the schema so the handler can deduplicate side effects on retries.
Next, implement a lightweight handler focused on deterministic behavior and idempotency. The handler should validate the request payload against the schema, check a persistence store (Redis or DynamoDB) for an idempotency record, and either return the previously recorded response or start a new job and persist the outcome. In Node.js the core flow looks like this:
// pseudo-code
app.post('/ci/run_tests', async (req, res) => {
const input = validate(req.body);
const existing = await store.get(input.idempotency_key);
if (existing) return res.json(existing);
const job = await ci.start({sha: input.sha, matrix: input.matrix});
const response = {status:'accepted', job_id: job.id};
await store.put(input.idempotency_key, response);
res.json(response);
});
Route and security are the next responsibilities. Your router maps the model’s skill identifier to this endpoint and performs three tasks automatically: schema validation, credential injection, and correlation enrichment. Use short-lived tokens or signed assertions injected at call time rather than embedding long-lived secrets in the Skill; attach a correlation_id and user principal so every invocation emits an auditable trace. This guarantees least-privilege execution and gives you structured logs for post-mortem analysis when a workflow fails.
Handle long-running work with an accepted/job_id async pattern so the assistant can poll or subscribe to completion events. The handler should return {“status”:”accepted”,”job_id”:”job-987”} immediately and expose /ci/status/:job_id to report {“status”:”success”,”artifacts”:[…]} or error enums such as TRANSIENT_TIMEOUT vs PERMANENT_FAILURE. The assistant uses these typed responses to choose retries, compensations, or human escalation instead of relying on ambiguous natural language.
Validate the Skill in a sandbox before broad enablement. Run contract tests against the schema, unit tests for the handler logic (including de-duplication and error branches), and integration tests that simulate timeouts and partial failures. Inject synthetic credentials in the sandbox router and exercise the polling flow; also run chaos cases—duplicate invocations using the same idempotency_key and intermittent CI failures—to ensure your checkpoints and retries behave predictably.
Make the Skill discoverable and maintainable for other engineers. Ship a one-page README that documents the input schema, output shapes, error enums, required scopes, and idempotency semantics; version the Skill and release behind a feature flag so you can canary new behavior. Instrument metrics for success rate, latency, and cost-per-invocation and emit structured audit logs containing correlation_id, request, and response so operations can debug or replay flows safely.
Taking these steps gets you from a concept to a safe, testable capability you can compose into larger orchestrations. In the next section we’ll show concrete schema files and a complete handler implementation you can drop into a CI/CD pipeline to prototype an end-to-end Skill-based automation.
Test, debug, and iterate
Building on this foundation, the first thing to accept is that Skills are software: you should treat ChatGPT Skills with the same test-and-debug rigor you apply to any microservice. Start by exercising the typed contract early and often—the input/output schema is your primary safety net and your best debugging lever. Run unit tests against handler logic, contract tests against the schema, and lightweight end-to-end simulations in a sandboxed router so you can catch schema drift, validation gaps, and authentication misconfigurations before they hit real users. By front-loading schema validation you reduce ambiguous failures and get deterministic error signals that are easy to automate in CI.
When a Skill fails in the wild, you want reproducible failure traces rather than vague logs. Instrument every invocation with a correlation_id and idempotency_key and capture the full typed request and response to a replay store; these artifacts let you run exact replays against a local or staging handler without changing inputs. Use synthetic fixtures (deterministic job IDs, canned third-party responses) to reproduce edge cases such as flaky CI jobs or expired tokens. We often record a minimal “flight record” for each invocation: {“skill”:”ci.run_tests”,”input”:{…},”id”:”user-42-abc123”,”corr”:”corr-0001”} — that artifact is indispensable when you need to debug async callbacks or race conditions.
Simulating failure modes is how you discover brittle behaviours before customers do. Introduce transient network errors, delayed callbacks, and partial success responses in your integration tests; validate how the assistant reacts to explicit error enums (TRANSIENT_TIMEOUT vs PERMANENT_FAILURE) defined in the schema. Apply contract fuzzing to probe schema boundaries and property-based tests to assert invariants (for example, that every successful run includes an artifact URL and a non-empty artifact checksum). Mocking upstream services with a programmable stub server lets you iterate faster and exercise retry/exponential-backoff logic without incurring real cost.
Debugging orchestration flows requires visibility into state transitions and decision points. Persist checkpoints for each Skill invocation and expose a timeline API that lists invoked skills, their typed outputs, and the assistant’s subsequent reasoning decisions; this timeline is what you and the model use to resume or compensate after a partial failure. When you hit inconsistent state, replay from the last durable checkpoint using the original idempotency_key so handlers de-duplicate side effects. Instrument metrics per-skill (success rate, median latency, cost per invocation) and correlate them with logs so you can quickly triage whether failures are due to model planning, router misconfiguration, or handler bugs.
Iteration is most effective when it’s automated and measurable. Gate new Skill versions behind feature flags and run a contract-test suite in CI that includes schema validation, auth flows, and async completion paths. Canary the new version against a small percentage of traffic and monitor key SLAs (error rate, median end-to-end latency, percentage of accepted→success transitions). How do you know when to unflag? Define quantitative thresholds up front—if success_rate > 99.5% and no regression in latency or cost for seven days, progressively increase exposure. Keep the developer README and schema docs close to the code so teams can update the contract and tests together.
Taking this concept further, instrumenting observability and running disciplined replay-driven debugging turns brittle automations into resilient, auditable capability surfaces you can compose confidently. We should now move from these testing and debugging practices to concrete schema files and handler examples that make safe rollouts and rapid iteration routine in your pipelines.



