2025 Breakthrough Timeline
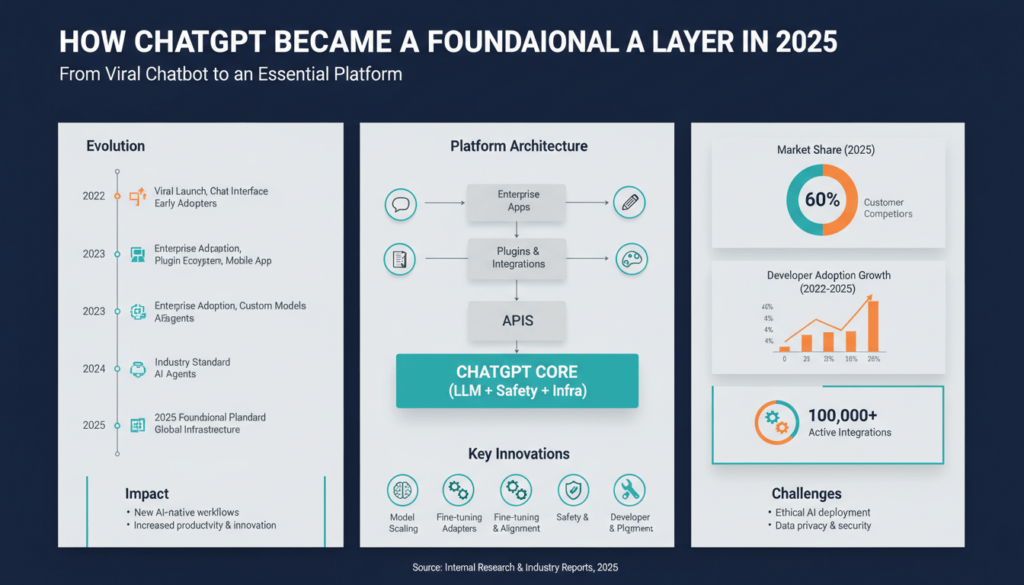
Building on this foundation, 2025 was the year ChatGPT moved from a viral chatbot into a platform you integrate into core systems and workflows. In the first half of the year, product changes and developer features converged: model upgrades increased multimodal and coding capability, extensibility features made it scriptable inside bespoke processes, and enterprise controls reduced friction for adoption at scale. Those shifts turned ChatGPT from a point tool into a foundational AI layer that teams could bind into CI/CD, observability, and data governance pipelines. How do you trace that transformation across the year and pick the moments that mattered most?
The technical pivot began with a wholesale model transition that reshaped capabilities available inside the hosted product. OpenAI replaced the older GPT‑4 runtime in ChatGPT with GPT‑4o, a natively multimodal, more instruction‑robust model, and iterated on it aggressively to improve coding, STEM problem solving, and conversational flow, effectively raising the baseline fidelity that every integration relied on. That replacement changed expectations: latency, multimodal inputs, and the model’s reasoning behavior now had to be treated as first‑class considerations when architects designed AI‑centric features for products. These improvements established a more consistent runtime target for teams building production connectors, client SDKs, and observable model interfaces. (help.openai.com)
At the same time, OpenAI broadened the model mix available inside the platform and made specialized variants directly usable by developers and power users. GPT‑4.1 and other focused models landed in the ChatGPT environment, offering stronger coding and precise instruction following for tasks you would embed in automation or developer tooling; parallel support for smaller, faster “mini” variants made it practical to route high‑throughput paths to cheaper models while reserving the larger models for critical reasoning tasks. Equally important, the Custom GPTs and model selector updates let teams choose the model that matched their latency, cost, and accuracy profile when composing workflows, enabling a true model‑selection strategy inside the product rather than an all‑or‑nothing choice. That flexibility is what allowed us to design hybrid pipelines that mix expensive reasoning calls with lightweight classification or summarization steps. (help.openai.com)
Platform features completed the picture by closing the gaps between experimental usage and production readiness. ChatGPT added workspace features like Projects, stronger memory controls, and recording/transcription capabilities that turned ephemeral chats into artifacts you could index, audit, and replay; these changes enabled event sourcing of conversations and programmatic extraction of insights for downstream automation. The launch of recording and meeting‑capture tooling made it straightforward to generate structured outputs (summaries, TODOs, follow‑ups) directly from real interactions, which teams then fed into ticketing systems or analytics pipelines. Those features meant you could build end‑to‑end flows—capture voice or meeting transcripts, call a summarization model, enrich results with a domain GPT, and persist outputs under organizational retention policies—without stitching together ad hoc services. (help.openai.com)
Enterprise and regulatory accommodations accelerated adoption by removing deployment and compliance blockers. During 2025 OpenAI expanded enterprise controls and announced regional data residency initiatives and government pilot programs that convinced regulated organizations to pilot ChatGPT inside legal, finance, and public‑sector workflows. Those agreements and residency plans directly addressed data locality, logging, and auditability requirements, making the platform suitable for regulated production use instead of only experimental deployments. As a result, you could embed the ChatGPT layer behind enterprise identity, log model decisions into your SIEM, and meet scope‑limited compliance checks without custom on‑prem re‑implementations. (itpro.com)
In practice, teams used this combination of model quality, pickable runtimes, platform features, and compliance controls to rewire core processes. Customer support moved to semi‑automated triage where ChatGPT drafted responses and generated structured intents for downstream systems; developer tooling pipelines used specialized GPTs to generate PRs, run static analysis checks, and create test scaffolding; and product teams used meeting capture plus custom GPTs to convert decisions into tickets and timelines. Taken together, these examples show why 2025 felt like a tipping point: the platform matured into a composable service you treat as a dependable infrastructure layer rather than an experimental assistant.
Moving forward, the architectural implication is clear: design your integrations around model selection, observable decision logs, and configurable residency/retention settings so the ChatGPT layer can serve as a predictable, auditable component of product and engineering stacks. Building these primitives now lets us iterate safely on higher‑level automation and reasoning features without rearchitecting the entire pipeline each time the models improve.
Viral Launch and Early Adoption
ChatGPT exploded into the public consciousness not because of a single feature but because the product combined an irresistible surface experience with a platform-grade API that developers could wire into real systems. From day one, people shared conversations, code completions, and demo videos that showcased surprising productivity improvements, and those organic moments drove downloads, signups, and inbound developer experimentation. Because the system was both a consumer-facing assistant and a callable platform, the attention curve translated quickly into integration demand: engineers wanted the same behavior inside IDEs, support stacks, and automation pipelines.
The virality mechanics were straightforward and technical: a low-friction share button, embeddable chat widgets, and examples that fit into social formats. When a developer could paste a 20-line prompt and get a runnable test scaffold, or when a customer could embed a transcript widget that turned meetings into structured tasks, those artifacts spread across teams and Twitter threads. Social demos acted like living API docs—engineers reverse-engineered patterns from screenshots and built lightweight integrations (for example, a webhook that serializes convo JSON and pushes it to a Kafka topic or a VS Code extension that calls a completion endpoint for in-editor doc generation).
Building on this foundation, the developer features mattered more than marketing: clear SDKs, predictable rate limits, and a simple key model for authentication lowered the barrier for prototypes to go production. Early adopters favored predictable behavior, so features that allowed model selection, deterministic prompts, and response logging were the difference between a toy and a service you could monitor. We saw teams route high‑volume classification to cheaper runtimes while reserving heavy reasoning calls for larger models—this routing pattern turned the platform into a composable execution fabric rather than an opaque endpoint.
Adoption patterns followed a classic inside‑out trajectory: individual engineers and product managers brought the assistant into workflows, then platform and SRE teams standardized it. Startups used it to bootstrap documentation, create test scaffolds, and auto-generate API clients; mid‑market teams used it to automate triage and enrich observability pipelines with human-friendly summaries. For enterprises, the shift came when auditability and residency controls removed compliance blockers; pilots then expanded from sandbox experiments to guarded, audited integrations (for instance, generating redlines for contracts inside a tracked, versioned workflow).
Converting viral interest into sustainable product usage required technical investments that many teams overlooked. How do you turn a one-off demo into steady active usage? The answer is instrumented onboarding, predictable latency SLAs, and cost-aware routing. Instrumentation means logging prompt/response hashes, embedding trace IDs into conversation artifacts, and surfacing model decisions in your observability stack; predictable SLAs let downstream services treat the AI layer like any other backend; and cost-aware routing—using smaller models or cached summaries for common queries—keeps the bill manageable at scale.
There were practical lessons we learned while integrating the platform into production systems. First, treat conversational outputs as events: index them, version them, and store minimal provenance to reconstruct decisions. Second, design your fallbacks: when latency spikes or a rate limit triggers, default to cached responses or a rule-based classifier to preserve user experience. Third, expose model selection to your architecture: define which paths need high-fidelity reasoning and which can use economical classifiers, and enforce that in your request router.
Those early days left a clear operational playbook: capture the viral attention with compelling surface experiences, then cement value by exposing the platform in developer workflows with robust SDKs, observability, and cost controls. As we move into designing longer‑lived systems, the emphasis shifts from novelty to reliability—if you instrument, route, and fallback correctly, the initial burst of adoption becomes sustainable integration inside product and engineering workflows.
Core Architectural Innovations
Building on the platform shifts we described earlier, the technical heart of ChatGPT’s move from a viral assistant to a foundational AI layer was a set of architectural primitives that made models reliable, routable, and observable in production. We began treating the model runtime like any other infrastructure component—defining SLAs for latency, availability, and cost per call so teams could design around predictable behavior rather than experiment with an opaque endpoint. That shift started with a wholesale runtime upgrade that standardized a natively multimodal default model and changed what you assume about inputs and latency. (help.openai.com)
A second major innovation was explicit model selection and the emergence of specialized runtimes you can target for distinct fidelity and cost profiles. Instead of a single “big model or bust” choice, we now design pipelines that route high‑value, low‑throughput reasoning to large models and push high‑volume classification, summarization, or extraction to compact, fast variants. OpenAI’s rollout of GPT‑4.1 and mini variants made this practical: you can pick models that optimize for coding fidelity, instruction following, or throughput and expose that choice in your request router and CICD integration. Why does this matter for your architecture? Because model selection becomes an operational knob you tune for cost, latency, and correctness. (openai.com)
We also built a model‑abstraction layer in front of the API that codifies routing rules, caching, and fallbacks. Implement this layer as a lightweight service or sidecar that accepts a high‑level intent and returns a model decision plus an execution plan: call GPT‑4.1 for a PR generation, use a mini model for intent classification, consult a policy cache for rate‑limit fallbacks, and persist a decision log with a trace ID. This pattern lets you change which model powers a workflow without touching business logic, enforce cost budgets, and roll forward newer models with canary routing. The result is a composable execution fabric rather than a hardwired endpoint, which is essential when models evolve frequently. (help.openai.com)
Observability and decision logging became non‑negotiable primitives: treat every prompt/response as an event with provenance metadata, model version, latency, token cost, and a deterministic hash of the prompt. By indexing these events into your observability stack you can correlate model decisions with downstream state changes, surface regressions when a new model release changes output distributions, and replay conversations for debugging. For example, embed trace IDs into meeting capture workflows so you can trace from a generated ticket back to the transcript, the model prompt, and the chosen model variant; that traceability is what lets SREs and compliance teams accept the ChatGPT layer as infrastructure. (help.openai.com)
Memory, event sourcing, and the conversion of ephemeral chats into structured artifacts changed how teams built closed‑loop automation. Instead of discarding conversational context, capture salient state with retention and residency controls, index it for retrieval, and expose it through an internal retrieval‑augmented generator (RAG) interface that your domain GPTs can query. That approach turns meeting capture into an auditable input stream: you can run summarization, extract action items, enrich with CRM data, and persist the results under organizational retention policies so downstream systems act on consistent, versioned inputs. This pattern reduces hallucination surface area and makes outputs reconstructable for audits and post‑mortems.
Regulatory and residency features completed the platform story by removing compliance blockers that previously forced on‑prem rewrites. Built‑in controls for regional data residency, structured audit logs, and granular retention settings let you embed the AI layer behind enterprise identity and SIEMs without shadow IT workarounds. Those capabilities changed procurement conversations: teams stopped treating the model as a pilot and started instrumenting it into legal review, finance automation, and customer support flows that require strict locality and audit trails. (help.openai.com)
Taken together, these architectural innovations shift how you design integrations: plan for model selection as a first‑class design decision, implement a routing/sidecar abstraction to enforce budgets and fallbacks, instrument every interaction for observability, and bake residency/retention into storage and governance layers. If you architect with those primitives, the ChatGPT layer becomes a predictable, auditable building block you can iterate on as models improve—without reengineering your whole pipeline each time a new runtime lands.
APIs, Plugins, and App Stores
Building on this foundation, the trio of APIs, plugins, and app stores is what let ChatGPT evolve from a standalone assistant into a predictable integration layer you can embed across products. APIs provide the low‑level, programmatic contract; plugins expose curated capabilities and sanctioned connectors; and app stores create discoverability, governance, and a monetization surface for third‑party extensions. If you’re evaluating integrations today, treat each of these as a different integration surface with distinct operational and security tradeoffs.
APIs are the plumbing you rely on for deterministic integrations. Start by treating the API as a versioned contract: expose model selection, trace IDs, and cost metadata in every call so downstream systems can observe and reconcile behavior. In practice we implement a small model‑abstraction sidecar that accepts a high‑level intent and routes to a specific runtime (for example, GPT‑4.1 for PR generation, a mini model for intent classification). That sidecar enforces rate limits, caches deterministic replies, and logs prompt/response hashes to your observability stack; these patterns let you change runtimes without touching business logic and make the API behave like any other production backend.
Plugins are the sanctioned way to extend the assistant’s capabilities while keeping control over data flow and permissions. A plugin is essentially a bounded integration: it declares a manifest, capability scope, and explicit authorization rules so the platform can grant or revoke access at runtime. Build a meeting‑capture plugin when you need persistent artifacts—transcripts, action items, and tickets—pushed into a downstream system under enterprise retention rules. Plugins let you centralize policy checks (data residency, redaction, audit hooks) and reduce the surface area where the model sees sensitive data, which is why teams often prefer a plugin over ad hoc direct API calls for third‑party services.
App stores change how teams discover and adopt extensions inside organizations. A curated directory surfaces vetted plugins and prebuilt GPTs, packages them with metadata (security posture, required scopes, cost profile), and provides an approval workflow for platform teams. For enterprises, an internal app store becomes a governance layer: product managers can trial a plugin in a sandbox, SREs can review its telemetry, and legal can verify data flows before it’s published to the broader org. App stores also enable revenue or cost‑recovery models for vendors and internal teams, creating an operational incentive to produce well‑instrumented, supportable integrations.
How do you decide which surface to use for a capability? Use APIs when you need maximal control, lowest latency, and custom routing; use plugins when you want sanctioned, auditable connectors with fine‑grained permissions; and use app stores when you need discoverability, governance, and lifecycle management across many teams. Implement model selection as an explicit option in your router, and apply canary routing when you introduce a new plugin or model variant so you can catch regressions early. We’ve found that combining cost‑aware routing with cached responses and deterministic hashing keeps bills predictable while maintaining high‑fidelity paths for critical tasks.
Taken together, these three mechanisms change how you architect an AI layer: APIs provide composability and control, plugins provide safe extensibility, and app stores provide governance and discoverability. Design your integrations so the model‑abstraction layer and decision logs are first‑class citizens; that lets you swap models, revoke plugin access, or unpublish an app without a major refactor. As we move into patterns for production deployments, the next practical step is instrumenting observability and replayability so every model decision is reconstructable and auditable—this is what makes the ChatGPT platform trustworthy enough to be treated as infrastructure.
Enterprise Integrations and Partnerships
Building on this foundation, when you move an AI pilot into production the real bottleneck is rarely model accuracy—it’s how you structure commercial and technical relationships so integrations scale across the organization. You’ll hit procurement, identity, and lifecycle gaps long before you hit a model limitation, so we start by mapping trust boundaries, data flows, and operational responsibilities before writing any glue code. Treat partners as extensions of your engineering org: define who owns incident response, observability, and cost controls up front so rollout decisions don’t become political fights.
There are three practical partnership patterns we regularly use: OEM/embed relationships where you ship a white‑label capability, managed‑service arrangements where a vendor operates the stack for you, and ISV/reseller models that bundle connectors with domain logic. How do you choose between them and avoid surprises? Negotiate explicit SLAs (p99 latency, availability, and token‑cost transparency), a data processing agreement that codifies residency and retention, and a security addendum that requires SOC2 or equivalent attestations. Run a short technical pilot (4–8 weeks) with objective observability gates—trace IDs, token accounting, and prompt/response sampling—before broad rollout so both sides can prove the integration contract.
On the technical side, implement a model‑abstraction service that enforces routing, caching, and schema contracts so partners integrate against a stable interface rather than the runtime itself. For example, capture meeting audio, publish a transcription event to Kafka with a versioned JSON Schema, run RAG enrichment from your internal vector store, call the high‑fidelity runtime for synthesis, and emit a ticket event that includes trace_id and prompt_hash; that keeps vendor connectors idempotent and replayable. Use a schema registry and contract tests to fail fast when a partner or model changes, and require contract tests in CI so third‑party code can’t degrade your production pipeline. This pattern turns every external connector into a testable, predictable service rather than an ad hoc dependency.
Security and governance belong in the vendor lifecycle, not tacked on afterward. Require SSO provisioning (SAML/OIDC), SCIM for account lifecycle, and forward audit logs to your SIEM with model_version, token_cost, and response_latency fields. Insist on per‑tenant encryption options or BYOK for regulated workloads, and make regional data residency controls part of the purchase order for sensitive systems—these are common enterprise procurement blockers we can resolve with concrete contract language. Finally, bake a joint incident response plan into every agreement so RTO/RPO expectations are aligned when a model outage or data incident occurs.
Operationalizing partnerships means automating governance: an internal catalog of approved connectors, required telemetry baselines, and clear deprecation timelines so teams stop building shadow integrations. We gate promotions with canary routing (1% → 10% → 100%) and promote only on measurable signals—latency SLOs, hallucination‑rate thresholds, and cost‑per‑transaction. Treat ChatGPT‑enabled capabilities like any other dependency: version your connectors, pin model runtimes in CI, and provide migration tooling so you can roll forward a model without scrambling downstream services. That discipline preserves developer velocity while giving platform teams control over cost and behavior.
Finally, align procurement, legal, and engineering on a partner playbook that codifies onboarding steps, required telemetry, and rollback triggers so your organization can scale AI without shadow integrations. Treat partner roadmaps as inputs to your model‑selection strategy and include enterprise KPIs—cost per automation, mean‑time‑to‑restore, and compliance audit pass rates—in renewal conversations. When procurement understands observability metrics and engineering accepts commercial guardrails, we move from pilots to enterprise‑wide deployments with predictable SLAs, shared accountability, and integration primitives that survive the next model upgrade.
Safety, Regulation, and Governance
Model governance and observability are the non-negotiable primitives you must bake into any production integration of a generative AI layer. When you treat the model as infrastructure, you need explicit controls for who can call which runtime, telemetry that surfaces behavioral drift, and residency controls that satisfy legal and procurement teams. How do you balance safety, regulatory compliance, and developer velocity while still delivering value? We start by treating governance as an engineering problem: instrumented, testable, and automatable rather than a set of ad hoc checkboxes.
Enforceable runtime guardrails reduce risk at the point of inference. Implement a policy engine that evaluates prompts and responses against allow/deny rules, enforce SSO and RBAC for model access, and limit plugin scopes so third‑party connectors see only the minimal data they need. Model governance here means codifying which models are allowed for which intents (for example, high‑fidelity reasoning models for contract redlines, compact models for intent classification) and automating approvals through CI gates so teams can’t circumvent controls in production.
Observability and decision logs let you reason about behavior after the fact and detect regressions fast. Treat every prompt/response pair as an event with metadata—trace_id, model_version, latency_ms, token_cost, prompt_hash—and persist that event to your observability backend. For example, a single log line might look like {"trace_id":"abc123","model":"gpt-4.1","prompt_hash":"h1x2","latency_ms":120}; index those fields so you can query for spikes in hallucination rates, correlate model calls with downstream errors, and replay interactions during post‑mortems.
Regulatory expectations often hinge on locality and retention, so data residency and retention policies must be first‑class. Define where transient inputs, embeddings, and derived artifacts are stored and enforce per‑tenant residency controls so regulated workflows never leave approved regions. Combine retention settings with encryption-at-rest and BYOK options for sensitive tenants; that way, legal can demonstrate chain‑of‑custody and compliance teams can run audits without requiring on‑prem rewrites.
Operationalize safety with a model‑abstraction layer that centralizes routing, caching, and fallbacks. Implement a lightweight sidecar or service that maps an intent to an execution plan—route(intent) -> {model: "gpt-4.1", fallback: "mini-v1", cache_ttl: 300}—and enforce canary release rules there so new models or plugins start at 1% traffic and only roll forward on defined telemetry signals. This abstraction also makes cost‑aware routing straightforward: route high‑value tasks to larger models and high‑volume classification to compact runtimes without changing business logic.
Put the controls into real workflows so they become usable rather than blocking. For meeting capture, for example, capture audio, run transcription, enrich with a domain vector store, call a synthesis model for the executive summary, and write a decision log entry that links the summary back to the transcript and the chosen model variant. That chain makes outputs reconstructable for legal review, lets SREs trace regressions to specific model upgrades, and gives product managers metrics they can act on to tune prompts and routing.
Taking these steps turns safety, regulation, and governance from a procurement checkbox into operational capability. Building on the architectural primitives we discussed earlier, enforceable policies, indexed decision logs, and configurable data residency make the AI layer auditable and predictable so teams can treat it like any other backend. Next, we’ll examine the integration surfaces and developer tooling that let you expose these governed capabilities safely across products and teams.



