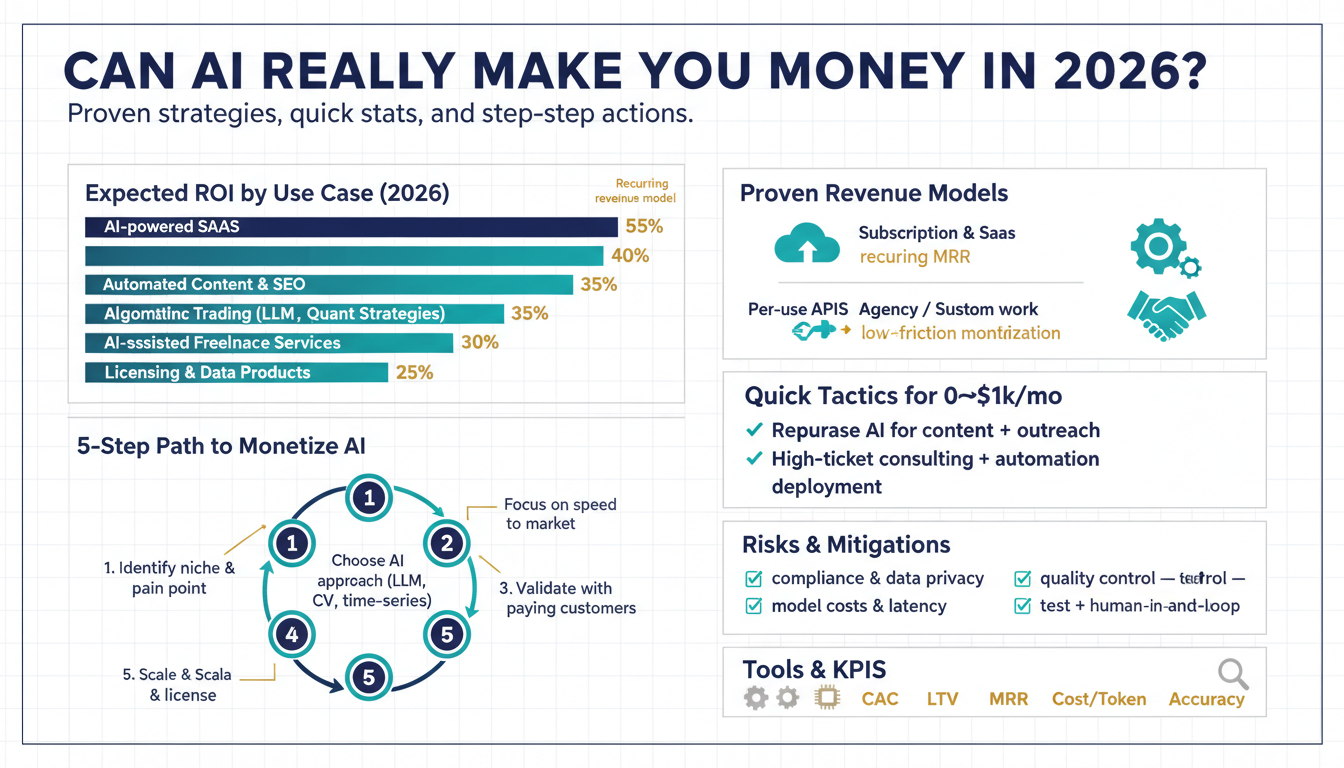
Why AI profits in 2026
Building on this foundation, the business case for AI profits is now concrete rather than speculative: AI profits come from lower inference costs, richer data network effects, and verticalized model-product fit that turn machine learning into predictable revenue. Early in the model economy you paid for novelty; today you monetize repeatable automation and augmentation. How can you actually profit from AI in 2026 when so many vendors are selling the same buzzwords? The short answer is you focus on operational unit economics and differentiated data that make model-driven features defensible and chargeable.
The structural drivers are what change a hobby project into a scalable business. Inference — the runtime prediction step of a trained model — has become much cheaper and faster, which reduces per-request cost and enables real-time features in customer-facing products. Fine-tuning and adapter techniques let you specialize large foundation models to narrow domains without training from scratch, so you get domain accuracy with lower investment. Meanwhile, MLOps maturity (production pipelines, observability, model versioning) turns occasional wins into repeatable deployments that survive audit, latency, and compliance constraints.
Productization is where theoretical value becomes cash flow. Build a paid workflow not a research demo: embed an LLM into a SaaS flow that replaces a $X/hr human task and bill per-seat or per-action; wrap an inference endpoint into a microservice (POST /predict -> model.predict(payload)) and sell it as an API; license a vertical dataset or predictive signal to enterprise teams that need stable SLAs. For example, a claims-automation pipeline that reduces average handling time and error rate creates clear ROI you can price against — that’s how you turn model improvements into customer renewals and upsells that sustain profit from AI.
Competitive moats in 2026 look different than traditional software moats. Data and integration replace pure code as the primary barrier: access to longitudinal, high-quality signals lets you iteratively improve models and offer measurable business outcomes. Operational excellence — low-latency inference, robust retraining loops, and strong privacy/compliance posture — becomes a selling point for regulated industries. When should you license a foundation model versus building a bespoke solution? Choose licensing for speed and cost control; choose bespoke models when proprietary data and custom evaluation metrics produce materially better business outcomes.
Risk-adjusted execution matters more than raw model accuracy. To protect margins you must instrument everything: per-call costing, drift detection, human-in-the-loop fallbacks, and billing aligned to value (per-document, per-resolution, per-insight). Focus pilots on narrow, high-value workflows so your metrics (time saved, churn reduction, error reduction) are clean and attributable. Profit from AI comes not from flashy demos but from predictable improvements to top-line or cost-line metrics that survive audits and integration complexity.
Taking this concept further, the practical path forward is iterative: launch a vertical pilot, prove unit economics, harden MLOps, then scale into adjacent use cases where your data and integration provide advantage. As we discussed earlier, you’re not selling models — you’re selling outcomes, SLAs, and operational reliability. If you keep pricing tied to measurable business impact and invest in the operational plumbing that sustains model performance, the economics of artificial intelligence convert into durable profit streams rather than one-off hype.
Identify high-demand AI niches
Building on this foundation, start by focusing on high-demand AI niches where verticalized model‑product fit, predictable unit economics, and defensible data moats converge. You want niches where customers pay for measurable outcomes — lower cost, faster decisions, or regulatory certainty — not for novelty. Early validation should prioritize industries with existing price-per-action economics (claims, underwriting, content moderation) because they let you map model performance directly to revenue. When you front-load these business constraints, technical choices (fine‑tuning, adapters, latency budgets) follow naturally.
Begin by applying a clear filter to shortlist opportunities: demand density, price elasticity, integration depth, and data exclusivity. Demand density means many buyers experience the same pain repeatedly; price elasticity captures whether customers will trade money for incremental accuracy or speed; integration depth assesses whether your model must be embedded into workflows or can run as a standalone API; and data exclusivity captures how unique your signals are for long-term improvement. We use these four criteria when deciding where to invest engineering time and MLOps budget because they map directly to retention and margin.
Several niches repeatedly meet those criteria in 2026: healthcare diagnostics and prior‑authorization automation, financial risk scoring and anti‑money‑laundering (AML) workflows, industrial predictive maintenance across heavy machinery, legal contract review and obligation extraction for compliance, and verticalized content intelligence (brand safety, localization, and regulatory filtering). Each of these areas has recurring transactions, measurable cost-savings, and domain data that improves with scale — the ingredients for a durable data moat. For example, predictive maintenance becomes defensible once you combine time-series telemetry, maintenance logs, and failure labels to raise precision above off‑the‑shelf baselines.
Monetization patterns vary by niche and should align with customer procurement models: per‑resolution pricing for document automation, per‑API‑call for real‑time risk checks, per‑seat for analyst augmentation tools, and outcome‑based SLAs for productivity gains. You can also license vertical datasets or predictive signals to enterprise teams that cannot build the pipeline themselves; that’s a high-margin recurring revenue path if your retraining loop and data quality are institutionalized. Pricing must reflect the avoided cost or incremental revenue you deliver — design contracts around clear KPIs (time saved, error rate reduction, chargeback avoided) so customers can justify renewal.
How do you know which niche is worth the investment? Run narrowly scoped pilots that instrument unit economics from day one: measure per-call inference cost, human fallback rate, time‑to‑resolution, and churn impact over a 90‑day window. Combine customer interviews with a small A/B test that replaces a single manual step with your model and observe end‑to‑end ROI. If the pilot shows sustainable gross margin after accounting for labeling, inference, and support, scale the MLOps pipeline; if not, iterate on the data collection or target a different vertical pain point.
These choices have direct technical consequences: prioritize robust MLOps, low-latency inference, drift detection, and privacy-preserving data pipelines in regulated niches. Architect for retraining loops that ingest labeled corrections, store model lineage, and expose feature importance for audits. Use embedding stores and smaller fine‑tuned adapters for domain specificity rather than training whole models from scratch; this reduces costs and speeds iteration. Taking this pragmatic, business‑driven approach helps you select high‑demand AI niches that convert operational improvements into durable revenue and prepares you to scale into adjacent verticals where your data and integrations create continued advantage.
Build AI products and services
Building on this foundation, the real work is converting model capability into chargeable workflows you can operate and scale. You should think of AI products and AI services as outcome engines rather than experimental models: customers pay for predictable reductions in cost, time, or risk, not novelty. That means instrumenting inference cost, latency, and human-fallback rates from day one, and building MLOps practices that make those metrics auditable. When you frame features as measurable outcomes, engineering priorities — retraining cadence, feature storage, and deployment topology — follow naturally.
Pick the right product form factor before you write another line of model code. Will you ship an embedded feature inside existing SaaS, a standalone API for platform partners, an analyst-facing augmentation tool, or an SDK that developers embed into pipelines? How do you decide which form factor to ship first? Choose the option with the fastest path to a paid metric: shortest integration effort, clean contract for billing, and direct linkage between model output and customer ROI.
Architect for predictable unit economics and observability from day one. Expose a minimal prediction API (for example, POST /v1/predict returning {prediction, score, provenance}) and measure cost-per-call alongside accuracy and fallback rate. Use adapter-based fine-tuning and retrieval-augmented techniques to narrow domain error without retraining whole models, and colocate embedding stores or feature stores with low-latency inference to keep tail latencies predictable. Instrument model versioning, lineage, and explainability hooks so you can prove improvements to customers and enforce SLAs.
Price against measurable business impact rather than token counts or model flops. Per-action pricing works when a prediction replaces a billable human task; per-seat is appropriate for analyst augmentation where adoption maps to value, and outcome-based SLAs sell when you can quantify avoided losses. You can also license a vertical signal or dataset if your collection and labeling pipeline produce unique predictive advantage. Map each pricing model to the KPI the buyer cares about (time saved, error reduction, cost avoided) and make the math explicit in the contract.
Operational controls are what let you win enterprise buyers and protect margins. Implement drift detection that triggers retraining pipelines and human review, and charge for premium latency or guaranteed accuracy tiers to offset inference expense. Maintain a human-in-the-loop escalation path with clear attribution so corrections feed your retraining loop and become assets rather than costs. Finally, bake observability into billing so each invoice reflects real usage and value delivered rather than opaque model calls.
To make this concrete, consider a contract-abstraction service for legal teams: embed an API into contract management systems to extract obligations, populate key-value stores, and surface risk flags in the review UI. Charge per-resolved-clause or per-contract review, tie SLAs to false-positive rates, and ingest reviewer corrections into a retraining loop that improves extraction quality over time. That workflow creates a data moat—longitudinal labels plus integration hooks—that raises switching costs and compounds improvements as you scale.
Start with a narrow pilot, instrument everything you can, and harden the MLOps pipeline before broad distribution. Validate unit economics over a 60–90 day window, then expand into adjacent workflows where the same signals or integrations compound value. If we keep pricing aligned to measurable outcomes and operationalize inference and retraining, we convert spinning-up models into durable, sellable software and services—not one-off demos but repeatable revenue engines that survive real-world complexity.
Monetize: subscriptions, licensing, ads
Building on this foundation, the practical question becomes which revenue levers you pull first to actually monetize AI: subscriptions, licensing, or ads. In the first 100–150 words we need to be explicit about tradeoffs because pricing choices shape architecture, MLOps, and sales motion; subscriptions drive predictable ARR, licensing captures enterprise margin, and ads scale user acquisition at lower per-user yield. If you want to monetize AI you must align pricing to measurable outcomes—time saved, errors avoided, or transactions enabled—so your engineering work maps directly to customer ROI and renewal calculus.
Start by matching monetization form to buyer economics rather than product vanity. Subscriptions work best when customers want ongoing access to a workflow (per-seat analytics, per-user copilots) and value accrues with continued use; licensing fits when enterprises need an on-premise model or a predictive signal embedded in their stack; ads make sense when you can acquire lots of lightweight users and the product naturally supports attention monetization. Each approach implies different operational constraints: subscriptions demand retention engineering and usage telemetry, licensing demands SLAs and provenance, and ads demand privacy-safe telemetry and low latency at scale.
When you choose a subscription model, design tiers around clear business metrics and instrument them from day one. Use a hybrid of per-seat and per-action: charge a base seat fee plus a discounted per-resolution fee that reflects saved human hours. For example, if an automated claim-review prediction replaces a $40 manual review and your inference cost is $0.02 per call, a monthly tier of $499 for 200 resolutions aligns price to value and preserves margin. Implement metering endpoints (POST /billing/usage -> {customer_id, units}) and expose real-time usage to customers so they can reconcile ROI and you can reduce churn through transparent costing.
Licensing is where you monetize unique data, models, or predictive signals at enterprise scale. Structure contracts around delivery form (dockerized model, hosted API, or data feed), update cadence, and auditability: charge per-signal or per-month plus an integration fee and a minimum commitment that amortizes onboarding. Choose licensing when your proprietary labels or longitudinal datasets materially outperform off-the-shelf models and when customers require control over data residency or explainability for compliance. Architect for versioned model bundles, signed attestations of lineage, and a separate billing meter for premium SLAs so licensing margins remain predictable as models evolve.
Ads and ad-hybrid models can rapidly scale ARR for consumer-focused AI apps, but they change product priorities. If you opt for ads, optimize for session length, engagement signals that advertisers value, and privacy-preserving contextualization rather than invasive profiling; this reduces regulatory risk while keeping CPMs reasonable. Instrument ad revenue per thousand impressions (RPM) alongside inference cost to compute net yield per MAU, and consider feature gating where premium, ad-free tiers convert a percentage of heavy users into subscription revenue. Ads work best as a distribution lever that feeds paid funnels, not as the only path to long-term enterprise profit.
How do you choose among subscriptions, licensing, and ads for your use case? Run narrow pilots that hard-metricize unit economics: measure cost-per-inference, human fallback rate, time-to-resolution, and customer willingness-to-pay over a 60–90 day window. We recommend A/B pricing tests, explicit ROI calculators embedded in the trial, and billing telemetry tied to model provenance so you can justify price increases as accuracy and integration depth improve. By tying monetization to measurable outcomes and hardening billing and MLOps together, you turn model capability into repeatable revenue and create the operational levers necessary to scale into adjacent use cases.
Sell prompts, templates, and courses
Building on this foundation, packaging AI intellectual property as repeatable digital products is one of the highest‑leverage ways to monetize model work. If you focus on prompts, templates, and courses you turn ephemeral engineering knowledge into products that scale without proportional support costs. The real question is this: how do you design, price, and operate these assets so they convert curious users into paying customers? We’ll treat them as productized workflows—tested, versioned, and instrumented—rather than as ad‑hoc artifacts bundled with a README.
Start by defining the narrow workflow each asset solves. For prompts and templates, that means documenting inputs, expected outputs, failure modes, and a small automated test corpus so you can run regression checks as the underlying model changes. For courses, it means chunking learning into project‑based modules that map to skills customers will trade money for—e.g., building an RAG pipeline or fine‑tuning an adapter for domain data. We recommend treating every item like an API: include usage examples, sample inputs, and minimal reproducible environments so buyers can evaluate value within minutes.
Price to measurable impact rather than perceived novelty. For individual prompts or templates, a transactional price makes sense ($10–$50 for niche templates that save hours); for curated libraries, use subscription access tied to updates and private communities. For technical courses, use multi‑tier delivery: a self‑study tier for lower price, a hands‑on lab tier with sandboxed infra for mid price, and a cohort or mentoring tier priced per seat. Align pricing to the avoided cost or time saved (hours reclaimed, errors prevented) and bake an ROI calculator into your product page so purchasers can justify the spend to their managers.
Choose distribution with operational control in mind. Marketplaces accelerate discovery but limit pricing and customer data; a direct storefront gives you billing telemetry and customer lifetime value signals. You can vend artifacts as downloadable packages (versioned releases in a GitHub repo or package registry), as hosted microservices behind an API gateway, or as gated content delivered after purchase via an LMS. Whatever the channel, expose a metering endpoint (for example POST /billing/usage -> {customer_id, units, provenance}) so usage maps to invoices and you can detect abuse or drift.
Operationalize quality and trust with automated CI and provenance. Run nightly tests that execute prompts against a labeled test set and surface performance regressions; store prompt versions and example outputs as part of your release artifacts so customers can audit changes. Maintain a human‑in‑the‑loop feedback path that converts customer corrections into labeled examples and feed those back into fine‑tuning or prompt‑template iterations. These practices let you offer upgrade pathways—improved templates, updated prompt packs, or advanced course modules—while keeping churn and refund risk low.
Address licensing, privacy, and growth engineering early. Declare clear license terms for redistribution and derivative works, and provide enterprise licensing options if customers require on‑prem or private‑cloud deployment. Protect privacy by documenting what customer data is stored, and offer a privacy‑preserving hosted option if that unlocks enterprise deals. Taking this concept further, use free trials, case studies, and an embedded ROI calculator to convert technical buyers; with disciplined metering, versioning, and a productized support model, prompts, templates, and courses become recurring, defensible revenue streams that feed into larger licensing or SaaS plays.
Scale with automation and partnerships
If you want to turn a successful pilot into repeatable revenue, you must fuse automation with partnerships from day one — automation to drive predictable unit economics and partnerships to unlock distribution and exclusive data. The fastest compounder of value in 2026 is the combination of low-cost, instrumented inference pipelines and channel or OEM agreements that embed your model into existing workflows. How do you coordinate partner integrations without exploding support costs? Design contracts and telemetry so every partner action maps back to measurable KPIs before you scale.
Automation is the lever that shrinks marginal cost and makes per-action pricing viable. MLOps (machine learning operations) — the automation of training, deployment, monitoring, and retraining — turns ad hoc model results into stable endpoints you can meter and bill. In practice this means automated retraining loops that consume reviewer corrections, drift detectors that trigger validation jobs, and CI for model artifacts so each release has signed lineage. When you reduce human fallback rates and inference tail latency through automation, you convert uncertain accuracy improvements into clear margin improvements.
Partnerships multiply reach and create data moats when you embed models into partner stacks or co‑develop vertical integrations. Choose partner types that match your unit-economic goals: platform partners who drive volume, reseller partners who handle sales motion, and data partners who contribute longitudinal signals. For example, an analytics platform integration that surfaces your risk score inside underwriters’ dashboards both increases usage and feeds back claim outcomes that improve model precision. Commercially, structure deals as revenue share, per‑call licensing, or white‑label bundles depending on who owns billing and customer support.
Combine automation and partnerships to align incentives and preserve margin. When your automation brings inference cost down to cents per call, you can offer partners conservative rev‑share models and still hold healthy gross margin. For instance, if an automated claim resolution saves a $40 manual review while costing $0.02 per inference and $2 in support and labeling amortization, you have clear room to split economics with channel partners and still justify investment in data acquisition. That combination—repeatable automation plus partner access to exclusive labels—creates a defensible data moat that compounds as you scale.
Operational controls are what make scale safe and sellable. Instrument fine‑grained metering (for example POST /v1/predict -> {prediction,score,metadata} and POST /billing/usage -> {customer_id,units,provenance}) so invoices map to provenance and SLA-backed outcomes. Define SLAs (service level agreements) in contract language tied to measurable KPIs — latency percentiles, false-positive ceilings, or human‑fallback thresholds — and offer tiered pricing for premium latency or accuracy. Maintain human‑in‑the‑loop escalation with labeled corrections feeding the retraining pipeline so partner fixes are assets, not recurring costs.
Building on this foundation, run small, instrumented partner pilots where each integration is assessed for distribution lift, data exclusivity, and margin impact before broad rollout. We recommend you treat every partner as an engineering and commercial experiment: measure cost‑per‑acquired‑signal, partner‑sourced labels per month, and downstream churn impact for 60–90 days. If the math holds, automate the pipeline, tighten the SLA, and expand the partner footprint — that’s how you scale AI profitably without sacrificing control or product quality.



