Define scope and requirements
Building on this foundation, defining scope and requirements for an AI voice assistant is the make-or-break phase that transforms a vague idea into an implementable architecture and product roadmap. We start by naming the primary capabilities you must deliver — wake-word detection, automatic speech recognition (ASR), natural language understanding (NLU), dialog management, text-to-speech (TTS), and integrations — and then translate those into concrete requirements. Front-loading these functional and non-functional goals early prevents scope creep and brings clarity to trade-offs between on-device processing and cloud services. How do you balance responsiveness, privacy, and cost while keeping the architecture extensible for future features like personalization and multimodal input?
Begin by separating functional requirements from non-functional requirements so your team can prioritize deliverables and system behavior independently. Functional requirements answer what the assistant must do: support multi-turn conversational flows, control specific device functions, query enterprise data, or place phone calls via PSTN. Non-functional requirements describe how it must perform: end-to-end latency targets, availability (SLA), concurrency (requests per second), speech recognition word error rate, and permitted error budgets for intent classification. Defining these quantitatively—e.g., intent accuracy ≥ 90%, median response latency ≤ 400 ms—lets us validate trade-offs under realistic load.
Identify stakeholders, primary user personas, and contextual constraints to avoid building features no one needs. List internal stakeholders (product managers, privacy/security, devops, data science) and external stakeholders (end users, IT integrators, compliance auditors). Map user journeys for each persona—hands-free driving commands, call-center voicebot interactions, or smart-home ambient activation—and capture environmental constraints like noisy backgrounds, low-bandwidth networks, or intermittent connectivity. These scenarios drive choices in ASR model size, noise-robust frontend processing, and error-recovery strategies.
Specify data, privacy, and compliance requirements up front because they fundamentally change architecture and deployment options. Decide whether you must keep PII on-device, whether audio transcripts are stored, and what retention policies apply; these decisions determine whether encryption-at-rest, hardware-backed key stores, or zero-audio-storage modes are required. If you target regulated domains (healthcare, finance), include explicit requirements for HIPAA, PCI-DSS, or regional data residency. Concrete constraints such as “no cloud audio storage for EU customers” or “voiceprint enrollment stored only in secure enclave” steer implementation choices early.
Enumerate integration points and platform constraints to make interfaces explicit rather than ad hoc. Define the APIs and data contracts for identity/auth, calendar, CRM, knowledge graphs, telephony gateways, and third-party skills ecosystems. Specify interface patterns—REST, gRPC, event-driven webhooks—and authentication modes (OAuth 2.0, mTLS). Also call out hardware and deployment constraints: edge CPU/GPU limits for on-device models, available memory, and whether you’ll deploy via container orchestration or directly to embedded firmware.
Define measurable success metrics and acceptance criteria so you can objectively evaluate releases. Translate user-facing expectations into KPIs: wake-word false reject rate < 3%, ASR WER < 10% for controlled vocabulary, median NLU intent latency < 150 ms, session completion rate, and post-interaction user satisfaction (CSAT). Include operational metrics like cost per 1,000 requests, error rates by integration, and scaling thresholds. These metrics let you accept an MVP release or decide a feature needs more iteration.
Prioritize features into an MVP and roadmap using risk, value, and effort as axes so we ship fast and iterate safely. For example, target a single-device control domain and one language for the MVP, deliver reliable single-turn commands and TTS, and postpone personalization and proactive suggestions to later milestones. Explicitly document trade-offs: choosing on-device ASR improves privacy and latency but increases development and testing effort, while cloud ASR simplifies updates at the cost of higher operational expense and potential privacy exposure.
With scope, stakeholders, measurable requirements, integrations, and compliance constraints nailed down, we have a clear contract to convert into system design and implementation. Next we’ll translate these requirements into concrete architecture components, deployment targets, and a development plan that aligns teams and milestones.
Choose tools and frameworks
Building on this foundation, choosing the right tools and frameworks determines whether the AI voice assistant hits the latency, privacy, and scalability targets you defined. Start by mapping each quantitative requirement—ASR word error rate, median NLU latency, wake-word false reject rate—onto the implementation choices you can realistically support. That mapping should appear in your tech-spike plan so we can prototype alternatives quickly and measure trade-offs rather than debate them abstractly. Early keyword decisions—ASR, NLU, TTS, on-device versus cloud—will guide vendor evaluation, CI/CD design, and cost modeling.
The most useful criterion for picking a stack is alignment with constraints: compute budget, data residency, development velocity, and maintenance surface area. Ask the practical question: How do you decide between on-device models and cloud services given your latency and privacy requirements? Use small benchmarks that mirror real-world noise and concurrency instead of vendor claims. Prioritize tools that offer both a clear integration API and a path for model updates; that lets you start with a managed cloud ASR for speed of delivery and later add an optimized on-device model if latency or privacy demands it.
When evaluating ASR, compare three axes: accuracy under noise (WER), end-to-end latency, and update cadence. Cloud ASR services give you high accuracy and frequent acoustic-model improvements with minimal ops work, but they carry networking latency and potential privacy exposure. On-device engines and open-source stacks let you control inference latency and keep audio local; consider lightweight runtime options and model-quantization workflows to fit embedded CPU/GPU budgets. Prototype with a representative noise corpus and measure wake-word and ASR performance together—wake-word false accepts amplify downstream ASR load, so tune them jointly.
For NLU and dialog management, decide whether to use a rule-augmented ML framework or a full end-to-end neural dialog system. If you need strict auditability and predictable failure modes for enterprise integrations, a hybrid approach—stateless intent classification plus a stateful policy engine—keeps behavior understandable. Frameworks like open-source NLU libraries let you train custom intent/slot models and own the data, while managed platforms speed up intent lifecycle and provide built-in entity extraction and multilingual support. Design the NLU contract as an API: intent, confidence, slots, and session metadata, so backend services can react deterministically to low confidence or ambiguous intents.
Voice synthesis choices affect perceived responsiveness and brand experience. Neural TTS with expressive prosody is valuable for consumer-facing assistants, but it increases compute and storage needs if you host voices yourself. Use SSML to control pacing and emphasis and design fallbacks for network loss—short canned prompts or concatenative segments—to keep interactions coherent. If voice personalization or voice cloning is a roadmap item, pick TTS tooling that supports voice adaptation pipelines and clear consent workflows to satisfy privacy requirements.
Infrastructure choices bind these components into a reliable product: favor lightweight model-serving runtimes (ONNX Runtime, TorchServe, TensorFlow Serving) behind gRPC for low-latency binary payloads, and use container orchestration tools to scale NLU and business-logic services. Plan for model versioning, A/B rollout of acoustic and intent models, and automated canarying of new inference code. Account for edge constraints by building quantization and pruning into your ML pipeline so you can target both cloud containers and constrained devices from the same CI/CD process.
Finally, select observability and security tools that make compliance and iteration practical. Integrate telemetry for per-feature KPIs—wake-word FRR, ASR WER, intent-latency percentiles—and tie those signals into automated alerts and retraining triggers. Enforce encryption-at-rest and hardware-backed key storage for voiceprint or PII, and choose frameworks that allow you to implement data-retention policies programmatically. With toolchains chosen to match your requirements, we can move into concrete architecture diagrams and deployment plans that translate this stack into an actionable implementation.
Design system architecture
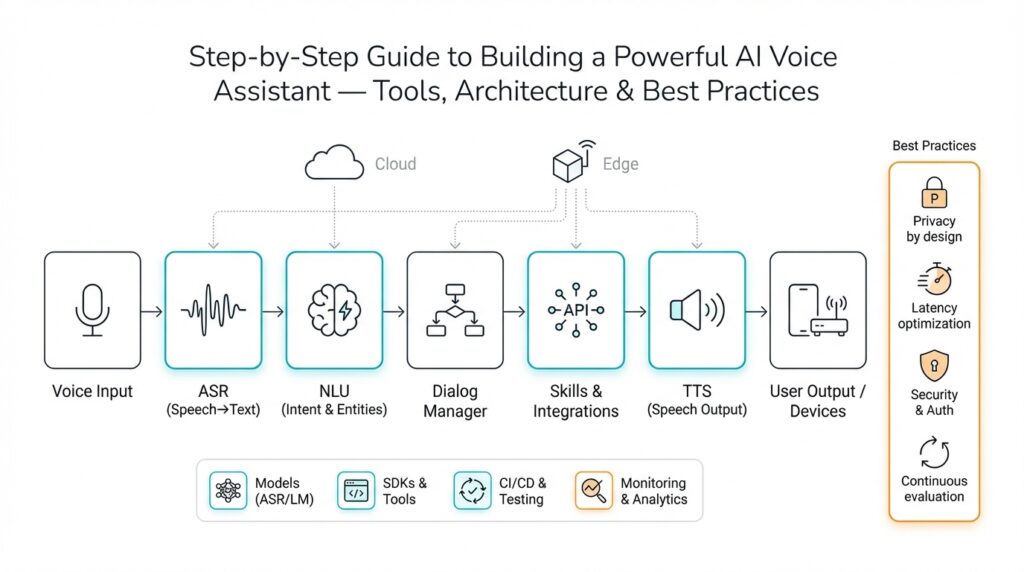
Building on this foundation, the architecture we choose determines whether your AI voice assistant meets the latency, privacy, and resiliency targets you defined earlier. Start by thinking in layers: a low-latency audio frontend and wake-word processor, a noise-robust ASR (automatic speech recognition) pipeline, an NLU and dialog management tier, a fulfillment layer that talks to integrations, and a TTS (text-to-speech) renderer with sensible fallbacks. Each layer should expose a small, well-documented contract so components can be swapped or scaled independently; that separation of concerns makes it possible to iterate on models without rewriting orchestration logic. Framing the system this way turns vague requirements into concrete interfaces and performance budgets you can measure against the KPIs you already set.
Define clear communication patterns between those layers so latency and failure modes are predictable in production. Use binary RPC (gRPC) or low-overhead messaging for synchronous hops where you need sub-200 ms intent latency, and event-driven queues for eventual work like analytics or long-running fulfillment tasks. How do you decide between on-device and cloud processing for each hop? Use the rule of proximity: place components that need millisecond response times or must keep PII local on-device, and keep heavy model training, logging, and non-real-time aggregation in the cloud.
Make contracts explicit and machine-checkable so engineers and models operate against the same expectations. For NLU, for example, define a compact JSON contract that returns intent, confidence, slots, and session metadata such as session_id and turn_index so downstream fulfillment can make deterministic decisions: {"intent":"TurnOn","confidence":0.92,"slots":{"room":"kitchen"},"session_id":"abc123"}. When you treat these contracts as part of your API — versioned and tested — you can run A/B tests that swap out NLU models without changing the fulfillment surface. That predictability reduces integration bugs and enables parallel work across teams.
Choose topology with operational constraints in mind: hybrid edge/cloud deployments are common because they balance privacy, cost, and update cadence. Host wake-word and a lightweight ASR on-device when you need always-on responsiveness and to minimize audio leaving the client, and run larger ASR/NLU variants in the cloud for complex queries and knowledge-graph access. For cloud components, container management and model-serving runtimes (ONNX Runtime, TorchServe, TensorFlow Serving) behind gRPC deliver low-latency inference and smooth rollouts; for edge, bake quantization and pruning into your CI so the same model artifact can target both environments.
Design state and session management to minimize coupling while preserving context for multi-turn flows. Keep short-lived dialogue state close to the runtime that needs it — a lightweight session cache on-device or in a fast in-memory store like Redis — and persist only what is required for audit, personalization, or compliance. Use correlation IDs and idempotent commands for external integrations (CRM, calendar, telephony) so retries and partial failures don’t produce unsafe side effects. Thinking through consistency models up front prevents surprising UX regressions when you scale.
Observability and model lifecycle are first-class architectural concerns, not afterthoughts. Instrument wake-word FRR, ASR WER, NLU intent accuracy and latency percentiles, session completion rates, and cost per 1,000 requests so you can automate retraining triggers and alerting. Wire these signals into canary deployments and automated rollback policies so a degraded model doesn’t reach 100% of traffic. This telemetry-driven feedback loop is how you keep quality high while iterating rapidly.
Finally, embed privacy and security into the wiring rather than bolting them on later. Use hardware-backed key stores for voiceprint encryption when you must store biometric templates, support a zero-audio-storage mode for privacy-sensitive customers, and implement end-to-end encryption between device and cloud with mTLS and short-lived tokens. Architect consent flows and data-retention policies into the data path so compliance is verifiable and auditable by design.
With these architectural principles in place — explicit contracts, layered topology, hybrid deployment patterns, robust state management, and telemetry-driven model lifecycle — you create an extensible foundation that maps directly to the MVP and roadmap you defined earlier. In the next step we’ll translate this architecture into concrete deployment diagrams, CI/CD pipelines, and a rollout plan that align teams, testing, and observability for production readiness.
Implement STT pipeline
Building on this foundation, implementing a robust STT pipeline is the practical step that turns raw audio into actionable transcripts your NLU and fulfillment layers can rely on. Start with a clear quality and latency budget—define target metrics such as word error rate (WER) thresholds, median end-to-end latency, and real-time factor (RTF)—because those numbers drive choices for streaming vs. batch ASR, model size, and deployment topology. Front-load the keywords: STT pipeline, ASR, and speech recognition appear throughout our decisions because they directly affect responsiveness, privacy, and cost.
The core pipeline should be a sequence of well-defined stages so each can be optimized independently. Begin with an audio frontend that performs gain control, echo cancellation, beamforming if you have an array, and voice activity detection (VAD) to avoid sending silence to the recognizer. Next, extract features—log-Mel filterbanks or MFCCs with 20–30 ms frames and a 10 ms hop are standard—and feed those into a streaming acoustic model such as a CTC/attention or transducer (RNN-T/Conformer) variant tuned for low-latency inference. Finish with a decoder and language-model rescoring step that returns token-level timestamps, confidence scores, and a normalized transcript suitable for downstream slot filling.
Design for streaming from day one so you can meet tight latency budgets for conversational turns. Implement a chunked audio pipeline that streams frames to the ASR service over gRPC with backpressure and partial hypotheses exposed to the dialog manager. For example, a simple Python async pattern looks like this:
async def audio_chunks(file):
for chunk in read_frames(file, chunk_ms=100):
yield chunk
# client.send_stream(audio_chunks)
This pattern lets you surface interim transcripts to the dialog manager for faster turn-taking while still waiting for a final hypothesis to commit side effects.
As we discussed earlier about hybrid deployments, decide which stages run on-device and which live in the cloud based on your privacy and latency constraints. On-device wake-word and a lightweight ASR reduce round-trip time and keep PII local; larger, more accurate ASR and LM rescoring can run in the cloud for complex queries. Use model-quantization (int8 or mixed-precision), pruning, and optimized runtimes (ONNX Runtime, TFLite, or custom inference engines) to fit powerful models into edge constraints while preserving acceptable WER and latency trade-offs.
Noise robustness is where real-world systems win or fail, so bake it into training and preprocessing. Apply beamforming and multi-mic alignment when available, augment training corpora with room impulse responses and additive noise, and use online denoising or neural frontends for transient noise. How do you know when the pipeline is good enough? Measure WER across representative noise profiles, track wake-word false accept/reject rates, and monitor downstream intent success—if transcripts are accurate but intents fail, tune confidence thresholds and implement explicit clarification prompts.
Production concerns dictate architecture choices beyond accuracy: implement per-request correlation IDs, model versioning, and A/B rollout hooks so you can deploy new acoustic or LM models safely. Instrument metrics for ASR latency percentiles, WER by acoustic condition, and per-turn confidence distributions and wire these into automated canarying and rollback policies. Expose a compact ASR contract to downstream systems such as: {"transcript":"turn on lights","confidence":0.93,"is_final":true,"tokens":[{"word":"turn","start":0.12,"end":0.22}]} so fulfillment systems can make deterministic decisions about retries and side effects.
Taking this concept further, integrate the STT pipeline with your NLU and TTS contracts and plan telemetry-driven retraining loops that close the quality gap over time. By making each stage observable, versioned, and replaceable, we keep iteration low-risk and maintainable while meeting the latency, privacy, and accuracy goals you defined earlier. In the next section we’ll translate these runtime and operational choices into deployment diagrams, CI/CD flows, and monitoring playbooks that put the pipeline into production.
Build NLU and dialogue
Turning transcripts into useful actions is where the assistant becomes genuinely helpful; this is the realm of NLU and dialogue management. We start by treating NLU as a contract that converts a raw transcript into an intent, confidence, and structured slots so downstream systems can act deterministically. Front‑load intent classification and slot filling in your design: those components determine whether a user’s request becomes a side effect, a clarification question, or a short-term context update. Getting this contract right early reduces brittle integrations and makes A/B testing models straightforward.
How do you design an NLU contract that’s both expressive and stable under change? Define a compact JSON schema that the dialog manager expects and version it: intent, confidence, slot map, provenance (ASR hypothesis index), and session metadata such as session_id and turn_index. Keep confidence calibration in mind—raw softmax scores aren’t reliable across models—so expose calibrated probabilities or likelihoods and a discrete quality flag (e.g., LOW/MED/HIGH). Example minimal response:
{"intent":"SetThermostat","confidence":0.87,"slots":{"temperature":"72","room":"living_room"},"session_id":"xyz-123","is_final":true}
Treat that schema as your API: it’s how fulfillment, logging, and recovery logic interoperate.
When building the models themselves, choose architectures that match your data scale and update cadence. For intent classification, fine‑tuned transformer encoders give strong few‑shot performance; for slot filling, sequence‑tagging approaches (BiLSTM‑CRF or span/transformer models) reduce label sparsity. Augment ML with deterministic entity resolvers and gazetteers for canonicalization—dates, device names, product SKUs—so downstream code gets normalized values. Train on representative negative examples and noisy ASR outputs; this reduces false positives and improves robustness in real environments where WER varies.
Dialog management must preserve context while keeping behavior auditable. Use a hybrid strategy: a deterministic state machine or policy rules for high‑risk side effects (payments, device control) and a learned policy for routing, proactivity, and small talk. Implement a lightweight Dialogue State Tracker (DST) that stores canonical slots, confirmation status, and confidence history; keep short‑lived state close to the runtime (on‑device cache or Redis) and persist only what’s necessary. This separation between stateless NLU and stateful policy makes it possible to swap intent models without changing dialog flow logic.
Operational safety and graceful recovery are non‑negotiable in production. Design explicit confidence thresholds and multi‑turn clarification strategies: if confidence < low_threshold, ask a focused clarifying question rather than re-prompting broadly. Prefer confirmation prompts for destructive actions and implement idempotency tokens for external calls so retries are safe. A simple decision flow looks like: if confidence < C1 -> ask clarification; elif action_is_destructive -> request confirmation; else -> execute. This pattern minimizes frustrating loops and prevents unintended side effects.
Finally, make NLU and dialogue a telemetry‑driven lifecycle rather than a one‑off project. Instrument intent accuracy, slot F1, dialog completion rate, and clarification frequency by acoustic condition and user cohort; feed low‑confidence utterances into an annotation queue for human review and active learning. Version models with model tags in your NLU contract, canary new policies on a small percentage of traffic, and automate rollback when session success metrics degrade. With observability and a retraining pipeline in place, we can safely iterate on NLU models and dialog policies while integrating them with fulfillment and TTS for a cohesive conversational experience.
Deploy, secure, and monitor
Building on this foundation, shipping a production-ready assistant requires that we treat how we deploy, secure, and monitor the system as first-class engineering problems—not afterthoughts. From the start you should map each SLA and KPI to an actionable deployment pattern so that deployment decisions reflect latency, privacy, and update cadence trade-offs. We recommend treating model artifacts and service images as immutable, versioned artifacts in the same CI/CD pipeline so you can trace any production behavior back to a specific model and container tag.
When you deploy models and services, automate the entire pipeline end-to-end: build, test, sign, image, and promote. Use declarative manifests and an orchestration strategy that supports rolling updates, canary traffic splits, and instant rollbacks; for example, namespace-isolated canaries with 1–5% traffic and automatic rollback on SLO breaches. Integrate model validation tests into CI that run representative acoustic/noise scenarios and intent-unit tests so a new ASR or NLU model never reaches production without measurable WER and intent metrics. Tag artifacts with semantic versions and include model metadata (dataset tag, training commit, evaluation seed) so deployments are reproducible and auditable.
To secure the stack, bake authentication, authorization, and encryption into the data path rather than bolting them on. Enforce mTLS between device and cloud endpoints, use short‑lived tokens (OAuth 2.0 or mutual TLS client certs) for service-to-service auth, and keep biometric templates in hardware-backed key stores (HSM or secure enclave) when required. Protect telemetry and transcripts by encrypting at rest and in transit and apply automated PII scrubbing before analytics ingestion if retention rules forbid raw audio or transcripts. Rotate keys regularly, use proof-of-possession or attestation for new devices, and enforce least privilege for all service identities so an exploit can’t turn into a full data compromise.
Monitoring is how we close the feedback loop between models and users: instrument fine-grained KPIs for wake-word FRR, ASR WER by acoustic profile, NLU intent-latency percentiles, session completion rates, and per-turn user satisfaction signals. How do you set SLOs that reflect user experience? Anchor SLOs to end-to-end user journeys (e.g., voice command → side effect completed within 400 ms) and derive alert thresholds from user-visible error budgets rather than raw infra metrics. Emit structured metrics and calibrated confidence distributions so you can determine whether failures are model regressions, noisy audio, or integration faults.
Observability needs distributed tracing and correlated logs so you can follow a single session across device, ASR, NLU, policy, and fulfillment. Include correlation IDs in every request and expose model-version tags in traces so regressions are easy to locate. Use sampling for full transcripts to control cost but route low-confidence or unknown-intent requests to a higher-fidelity capture pipeline for annotation. Apply retention and access controls to logs and traces: scrub PII at ingest, enforce role-based access, and retain audit trails required for compliance audits without keeping unnecessary user data indefinitely.
Operational safety demands playbooks and automated gates: wire metrics into deployment gates that block rollouts when canary WER or intent drop exceeds thresholds, and implement automatic rollback policies. Prepare runbooks for common incidents—model drift, noisy acquisition environments, credential compromise—and rehearse them with chaos or fault-injection tests that exercise fallbacks (local ASR, canned TTS prompts). For privacy incidents, have a verifiable audit path showing when and where audio was stored or deleted and implement notification flows that satisfy regulatory requirements.
Taking these practices together gives us an operational posture that supports rapid iteration without sacrificing safety or compliance. In the next section we’ll translate these operational controls into concrete deployment diagrams, CI/CD pipelines, and monitoring playbooks so your team can run safe, observable rollouts and iterate on models with confidence.



