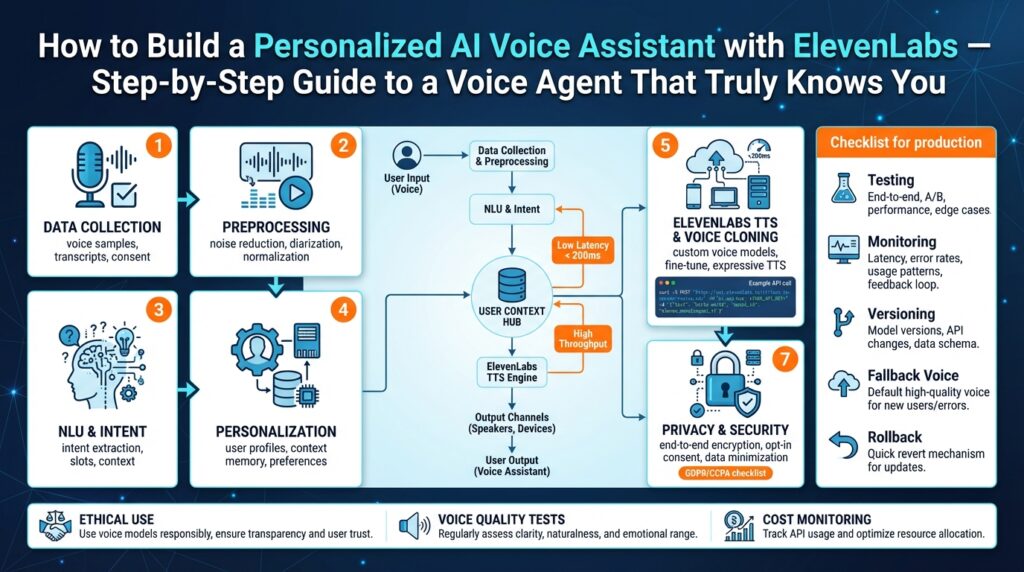
Overview and project goals
Building a truly personalized AI voice assistant starts with a crisp set of goals that balance voice quality, contextual intelligence, privacy, and operational reliability. In this project we use ElevenLabs for high-fidelity TTS and combine speech recognition, dialogue management, and user memory to produce a voice agent that sounds like a colleague who knows your preferences. We’ll prioritize measurable outcomes—perceptual quality, latency, personalization depth, and safety—so engineering decisions map directly to product value from day one.
The first engineering goal is natural, consistent voice that maintains identity across sessions. We want a voice model that preserves timbre, prosody, and emotional range while supporting dynamic content (notifications, long-form responses, short confirmations). The second goal is contextual relevance: multi-turn memory that surfaces recent and long-term user preferences without leaking private data. The third operational goal is reproducible performance: sub-200ms response latency for short replies, predictable scaling for peak loads, and clear SLIs/SLOs that let us detect regressions quickly.
To make these goals actionable we define concrete success criteria and testing signals. For audio quality, target a MOS (mean opinion score) above industry baselines for synthesized speech and A/B test against human-read baselines; for latency, measure end-to-end RTT for the critical path (STT → NLU → TTS → playback). How do you validate personalization? Track retention of personalized slots (e.g., preferred phrasing, home/work locations) and measure accuracy of slot usage in downstream tasks. We’ll rely on modular components—speech-to-text, intent/entity extraction, dialogue state management, and ElevenLabs TTS—so we can iterate on individual failure modes without rewriting the whole pipeline.
Data and model objectives guide both training and privacy design. We’ll collect opt-in voice samples and interaction logs with explicit consent, then apply speaker-adaptive fine-tuning and data augmentation to build robust voice profiles with minimal data per user. To avoid overfitting and privacy risk, we’ll use federated learning or differential-privacy-aware aggregation for global model updates while keeping user-specific embeddings local and encrypted. For personalization, the system stores compact user embeddings and a time-decayed memory store so the assistant remembers recent context but forgets according to retention policies you can configure.
Operational architecture goals determine where inference runs and how we maintain reliability at scale. Real-time streaming inference (server-side or edge-accelerated) reduces latency for interactive flows, while batch synthesis can handle long-form content generation. Container orchestration with autoscaling, robust retries, and circuit breakers handles load spikes; observability (traces, latency heatmaps, audio-quality regression alerts) makes degradations visible fast. Authentication and key management must protect the ElevenLabs API credentials and user voice models, and rate-limiting plus per-tenant quotas prevent noisy neighbors from impacting latency guarantees.
Finally, product and UX goals translate engineering trade-offs into user value. We’ll design onboarding that captures voice consent, a short personalization script, and toggles for privacy controls so users understand what the assistant stores. Fallback strategies—text-only responses, reduced-personalization safe mode, and explicit clarification prompts—keep interactions smooth when inference or connectivity fails. We’ll validate impact with feature-flagged experiments and qualitative voice focus groups, then iterate: next we’ll map these goals onto a pragmatic architecture and an integration plan that gets a playable, privacy-respecting voice agent into hands quickly.
Prerequisites and required tools
Building a production-grade ElevenLabs-backed TTS pipeline for a personalized voice assistant starts with a disciplined toolchain and a checklist you can reproduce across environments. In the first iterations you’ll provision an ElevenLabs account and API keys, pick a speech-to-text provider for reliable transcripts, and confirm your development workstation has a stable audio stack for capture and playback. These early choices determine whether you’re optimizing for fidelity, latency, or privacy, so decide which you prioritize before wiring components together.
You need credentials and key management that scale securely: create scoped API keys for ElevenLabs and any STT/LLM providers, store secrets in a vault (HashiCorp Vault, AWS Secrets Manager, or equivalent), and enforce short-lived tokens for runtime services. For local development, generate a separate sandbox project and mirror production IAM roles so you can test permission boundaries without risking live customer data. Rotate and audit keys regularly and instrument access logs so you can detect accidental key leakage early.
On the developer workstation and CI side, ensure you have an audio toolchain that matches production: a consistent sample rate, mono 16-bit WAV support for STT, and optional higher-rate files for TTS quality checks. Configure your local microphone and playback device to use the same codecs and buffering strategy your service will use in production; mismatches between WebRTC capture and server-side decoding are a common source of “it sounds different” bugs. Include simple CLI utilities (ffmpeg, sox) in your repo for deterministic conversions and automated audio tests in CI.
Choose a speech-to-text and NLU stack that fits your latency and accuracy goals; for example, run a small, on-premise ASR for low-latency commands and fall back to cloud STT for noisy audio or longer transcripts. Pair STT output with a robust NLU or LLM-based intent extractor—Rasa or a lightweight transformer-based intent classifier can handle structured tasks, while a conversational LLM handles open-ended queries and personalization. Define input/output contracts between modules early so you can swap models without touching orchestration or storage layers.
For voice synthesis and personalization, validate the data you’ll feed ElevenLabs: a short, consented voice sample set, annotated phonetic variants for tricky names, and text prompts for emotional or contextual styles. Keep per-user voice embeddings or speaker profiles encrypted at rest and evaluate speaker-adaptive fine-tuning only after explicit opt-in. Plan tests that measure perceptual quality (MOS) and identity consistency across session durations so you can iterate on balance between personalization depth and data minimalism.
Infrastructure requirements are concrete: container images for your STT, NLU, and TTS adapters, a container orchestration platform (Kubernetes or managed alternatives) for autoscaling, and GPU-enabled nodes if you run heavy on-device inference. Define resource requests/limits, horizontal pod autoscalers, and a traffic-splitting strategy for canary releases to avoid noisy-neighbor effects. If edge inference matters for latency, prepare an edge deployment pattern with smaller models and clear fallbacks to cloud synthesis.
Observability, testing, and CI/CD must be in place before user-facing experiments: instrument traces across STT→NLU→TTS, collect latency heatmaps, and run continuous audio-regression tests that compare synthesized output against baselines. Include SLI/SLO dashboards, alerting for degraded audio quality, and automated smoke checks that exercise personalization slots. Integrate privacy-preserving telemetry so you can diagnose failures without exposing raw user audio.
How do you guarantee that personalization respects user privacy? Build opt-in flows and retention policies into onboarding, encrypt user voice profiles and embeddings, and provide UI controls to export or delete data. Apply rate-limiting and per-tenant quotas to protect latency SLAs and separate production from research datasets to avoid accidental re-identification. These controls become part of your developer checklist and are as operationally important as container orchestration and model selection.
Taking this toolset approach ensures we can move quickly from prototype to measurable service-level guarantees: you’ll have the accounts, secure keys, audio tooling, STT/NLU choices, ElevenLabs integration patterns, and orchestration plan needed to build a reliable, private, and personalized voice assistant. Next, we’ll map these prerequisites into a concrete architecture and integration plan so you can deploy a playable voice agent with predictable latency and clear privacy controls.
Create ElevenLabs account and API
Building on this foundation, the first live dependency you must provision is an ElevenLabs account and a set of API credentials you can trust in production. You’ll use these credentials to synthesize TTS audio for personalized voice profiles and to manage voice models and credits from the developer dashboard. How do you provision an API key that keeps user voice models private and production-grade? The short answer: create a dedicated workspace account, generate scoped API keys from the dashboard, and immediately move keys into a secret manager so they never live in client code or logs.
Start by signing up for ElevenLabs using either social sign-in (Google/Apple) or email/password, verify your account if required, and then sign in to the dashboard to reach developer controls. After logging in, open the Developers (or Workspace) area and find the API Keys tab to create your first key; the UI flows are documented in the ElevenLabs signup and help pages and will surface the API key creation workflow. Creating the account and the API key is a prerequisite for calling any TTS endpoints and for enabling features like voice cloning or model selection in your integration. (11labs.us)
When you create a key in the dashboard, ElevenLabs makes two important controls available: scope restrictions (which endpoints the key can call) and credit or quota limits (how much that key can spend). By default you can see the key only once when it’s created—after that the dashboard shows only a masked value or the last four characters—so copy it into your vault immediately or you’ll need to rotate a replacement. Configure scope and credit limits per key so that, for example, your short-lived client tokens can only call streaming or single-use endpoints while backend service keys have broader TTS permissions. (help.elevenlabs.io)
Security practices matter more when you’re synthesizing user voice data. Treat every API key as a secret: store keys in a secrets manager (AWS Secrets Manager, HashiCorp Vault, or equivalent), inject them as environment variables into runtime containers, and never embed them in front-end bundles. ElevenLabs supports single-use tokens for client-side interactions where you must avoid exposing a long-lived API key; these tokens and service-account patterns are useful for mobile or browser playback flows and multi-seat teams respectively. Rotate keys regularly and use service accounts or workspace-level keys for machine-to-machine access so you can revoke a compromised human user’s token without taking down background services. (elevenlabs.io)
Practically, wire the key into your app like any other cloud API: put ELEVENLABS_API_KEY in your environment and reference it from your TTS adapter rather than hard-coding. A minimal curl example demonstrates the authentication header that ElevenLabs expects, which you can mirror in any SDK or HTTP client:
ELEVENLABS_API_KEY=your_key_here
curl -H "xi-api-key: $ELEVENLABS_API_KEY" \
-H "Content-Type: application/json" \
-d '{"text":"Hello world","voice":"alloy"}' \
"https://api.elevenlabs.io/v1/text-to-speech"
Use server-side adapters to keep that header private; if you must support in-browser audio generation, mint single-use tokens on the server and expire them quickly. The ElevenLabs quickstart and API docs show this header-based pattern and recommend environment-based secret handling as part of the integration best practices. (elevenlabs.io)
Operationally, create separate keys for dev, staging, and production and apply per-key quotas to limit blast radius and unexpected cost. Tag keys with a clear name and purpose in the dashboard, add them to your routine rotation policy, and map each key to CI/CD pipelines or service accounts so you can audit usage and correlate spikes to deployments or tests. This practice ties directly to the SLIs and observability patterns we outlined earlier: with scoped keys and quotas you can detect anomalous spending or latency regressions that point to misconfigured clients or abusive calls.
Next, we’ll wire the official SDKs and build a secure TTS adapter so we can synthesize short confirmations under 200ms and longer, expressive responses for personalization experiments. With the account created, keys scoped, and secrets secured, we can move quickly to integrating ElevenLabs TTS into our dialogue pipeline and enforce the privacy and retention rules we designed earlier. (elevenlabs.io)
Prepare and record training audio
Building on this foundation, collecting high-quality training audio and curated voice samples is the single most important step for a convincing voice profile with ElevenLabs. Start by capturing clean, consistent recordings: mono 16-bit PCM WAV at 24 kHz or 48 kHz (use 16 kHz only for constrained ASR pipelines), disable AGC and software enhancements on the microphone, and record in a quiet, acoustically damped space to minimize room tone. Keep consistent mic distance and orientation across takes so timbre and proximity cues remain stable; inconsistent capture is the fastest path to a brittle voice model.
Decide how much material you need and why it matters: how much training audio produces a usable voice profile versus one that generalizes? For many speaker-adaptive fine-tuning workflows, 2–5 minutes of varied, consented speech is a pragmatic minimum for capturing timbre and prosody, while 10–20 minutes yields richer emotional range and lexical coverage. We recommend recording both scripted passages for phonetic breadth and spontaneous prompts for natural prosody—record a short read (news-style paragraph), five sentences with target names/terms, and three open prompts where the speaker answers questions naturally to capture cadence.
Structure your recording script to maximize phonetic and prosodic coverage without overburdening contributors. Begin with a phonetic-rich paragraph (covering plosives, fricatives, nasals) followed by domain-specific tokens (proper nouns, acronyms, product names), then include style prompts that cue emotion (neutral informational, friendly confirmation, brief emphatic exclamation). Label each take with metadata that includes speaker_id, take_id, microphone, environment, and prompt_type; for example alice_v1_read_20260115_mic1.wav and a companion JSON manifest with fields for consent_date and retention_policy. This metadata makes downstream augmentation, filtering, and privacy audits tractable.
Operationalize the capture and preprocessing pipeline so recordings are reproducible and auditable. Use deterministic conversions with ffmpeg or sox—for example, ffmpeg -i input.mp3 -ar 48000 -ac 1 -sample_fmt s16 output.wav normalizes sample rate and channel layout. Apply a non-destructive normalization (LUFS target for loudness consistency) and trim long silences while preserving natural breaths; avoid aggressive noise gating that alters vocal characteristics. Store raw originals separately from processed files so you can reprocess with different parameters if synthesis quality requires it.
Protect privacy and consent while you gather voice samples and training audio. Capture explicit opt-in that enumerates where voice embeddings will be used, retention windows, and export/delete procedures; mirror the retention policy you defined earlier and store per-user embeddings encrypted at rest with access logged. If you’ll perform any centralized fine-tuning, minimize risk by pseudonymizing manifests and applying data-minimization techniques—keep only the audio necessary to achieve the voice profile and use per-user keys or tenant scoping when calling ElevenLabs APIs for model creation.
Validate and iterate: run perceptual checks and automated tests that compare synthesized outputs against human baselines for identity consistency and intelligibility. Create short A/B tests that swap in the new voice profile for canned phrases and measure MOS or preference votes internally, and build small regression tests that synthesize phrases containing the domain-specific tokens you recorded earlier. Once your dataset produces consistent, privacy-respecting voices, we can wire the profile into the TTS adapter and tune inference parameters for latency and expressiveness in the next integration step.
Create and fine-tune voice model
Building on this foundation, the first engineering step is to turn your curated recordings into a reproducible voice model that balances identity, expressiveness, and safety. You want a voice model that preserves timbre across short confirmations and long-form responses while fitting the latency and memory constraints we defined earlier. Start by creating a canonical preprocessing pipeline so every training run receives identical inputs: deterministic resampling, LUFS normalization, silence trimming, and a concise JSON manifest that ties audio to metadata like prompt_type and retention_policy. This reproducibility makes A/B tests and regression checks meaningful and keeps personalization predictable as you iterate.
Next, adopt a two-stage creation process: build a generic base voice and then speaker-adapt with per-user data. Train the base model or select a high-quality ElevenLabs base if available, optimizing for broad phonetic coverage and robustness to noise. Then fine-tune on the user’s voice profile using small, consented datasets (2–20 minutes depending on fidelity targets). Use low learning rates (for example, lr ≈ 1e-5) and aggressive early stopping to avoid overfitting; with limited data, regularization and careful augmentation are what let you capture prosody without hallucinating idiosyncratic artifacts.
For practical fine-tuning, augment conservatively to expand coverage without destroying identity: speed perturbation (±5–10%), subtle pitch shifts, and room-impulse simulation for diversity. Keep augmentation scripts deterministic and log every synthetic sample so you can trace regressions. A minimal training recipe looks like: epochs 2–6, batch size tuned to GPU memory, lr 1e-6–1e-5, and validation checks every 1000 steps against a holdout of domain-specific tokens (names, acronyms). If you’re compressing a user embedding instead of full model weights, experiment with adapter layers or low-rank factorization so you can store compact speaker profiles client-side and keep global model updates centralized.
Privacy and operational safety must be integral to the fine-tuning loop. Apply data-minimization rules: only store audio that improved MOS or intelligibility during validation, rotate keys, and encrypt per-user embeddings at rest. If you aggregate updates for a global model, consider federated learning or DP-SGD (differentially private stochastic gradient descent) so updates don’t expose raw voice features. When you deploy user-specific voice profiles, serve them as encrypted blobs or ephemeral adapters rather than merging them into the shared model; this reduces re-identification risk and simplifies deletion workflows when users revoke consent.
How do you know when the voice is production-ready? Combine objective and perceptual signals: automated WER and prosody drift metrics for regression detection, plus human MOS tests that include identity-consistency checks across 10–30 varied prompts. Run A/B comparisons where half of listeners hear the baseline voice and half hear the personalized model; measure preference and error rates on domain tokens you recorded earlier. Also validate latency under load—test synthesis for short confirmations and long paragraphs separately, and tune inference parameters (batch synthesis vs streaming, decoder temperature, and style prompts) to meet your sub-200ms goals for short replies while retaining expressiveness for longer output.
Finally, operationalize lifecycle management for voice profiles so personalization scales. Automate continuous regression testing that synthesizes a fixed test-suite, version each voice model or adapter, and tie releases to canary rollouts in your orchestration platform. Keep the user-facing controls visible: allow export, temporary safe mode, and irrevocable deletion of voice profiles. With a reproducible creation pipeline, conservative fine-tuning, privacy-aware aggregation, and strong evaluation gates, we can confidently wire the voice model into the TTS adapter and start tuning runtime parameters for real-time use.
Build backend and integrate APIs
Building the backend is where the voice starts to feel reliable and personal: you need a service layer that turns intents and user memory into low-latency, high-quality audio via ElevenLabs TTS while protecting user privacy and keeping costs predictable. In the first 100 words we’ve already named the core pieces you’ll wire together—STT, NLU, dialogue state, and TTS—so design the backend as a set of clear adapters with strict I/O contracts. By front-loading these responsibilities you reduce cross-team friction and make API integration visible and testable from day one.
Building on this foundation, define a modular adapter pattern for each external dependency so you can swap providers without refactoring business logic. Each adapter exposes a small, well-documented contract: inputs (text, voice_profile_id, style_hint, metadata) and outputs (audio_uri or audio_stream, synthesis_latency_ms, diagnostic_tokens). This contract approach keeps STT and NLU implementations independent from your ElevenLabs integration and forces you to think about schema evolution, versioning, and backward compatibility early.
Security is a primary backend concern—how do you keep ElevenLabs API keys and user voice profiles safe while still supporting browser playback or mobile clients? Host synthesis on the server and proxy client requests through short-lived, single-use tokens when you must enable direct playback from the browser. Implement a server-side TTS adapter that injects the xi-api-key from a secrets manager (not checked into code), rate-limits per-tenant, and logs usage with correlation IDs so you can trace an audio artifact back through the pipeline. Example (Express-style):
app.post('/synthesize', async (req, res) => {
const { text, profileId } = req.body;
const apiKey = process.env.ELEVENLABS_KEY; // injected from vault
const r = await fetch('https://api.elevenlabs.io/v1/text-to-speech', {
method: 'POST', headers: { 'xi-api-key': apiKey, 'Content-Type': 'application/json' },
body: JSON.stringify({ text, voice: profileId })
});
r.body.pipe(res);
});
Decide when to use streaming versus batch synthesis based on latency and output length: stream small confirmations and conversational turns to hit sub-200ms targets, and reserve batch or queued synthesis for long-form content like briefings or transcripts. Streaming reduces perceived latency because you can start playback while the rest of the audio generates, but it increases complexity (chunk reassembly, jitter buffers). For many agents we combine both: a fast streaming path for dialog and an offload path for long responses with retries and resumable downloads.
Make data contracts explicit between stages so you don’t leak context or break downstream consumers. Enforce a JSON envelope that carries user_id (pseudonymized), session_id, memory_snippet_version, style_hint, and an auditable consent_flag; attach a short checksum of the text-to-synthesize to aid regression testing. This lets you re-synthesize deterministically for A/B tests, attach MOS scores to specific envelopes, and revoke or delete user data cleanly when a user requests removal.
Operational robustness depends on observability and defensive patterns: instrument latency histograms for STT→NLU→TTS, track request success rates and MOS proxies, and enforce circuit breakers with exponential backoff when ElevenLabs or any upstream service degrades. Implement per-tenant quotas and throttling so noisy users don’t impact latency SLOs, and add automated smoke checks that synthesize a small test-suite on every deployment. These measures let us detect regressions early and correlate audio quality drops with code or data changes.
Finally, make integration testable and reversible: automate canary rollouts for new voice profiles, include privacy toggles in the onboarding flow, and provide export/delete endpoints tied to your retention policy. When we test the runtime adapter, we’ll validate both perceptual signals and SLA metrics—this prepares the system for iterative tuning of decoder parameters and style prompts in the next phase. With a disciplined backend and thoughtful API integration, your voice assistant will sound consistent, respect privacy, and scale predictably as personalization deepens.



