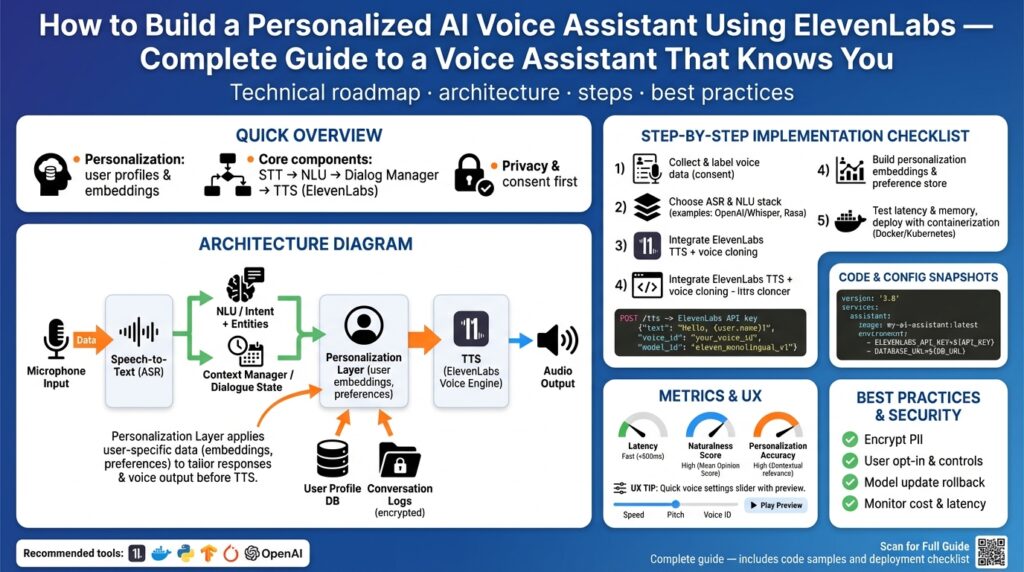
Overview: Project goals and scope
Building on the concepts we’ve already introduced, this project aims to deliver a production-ready, personalized AI voice assistant that feels like it knows you—leveraging ElevenLabs for high-fidelity text-to-speech and voice cloning. Our primary objective is to combine robust natural language understanding, persistent user memory, and expressive synthesis so interactions are contextually relevant, fast, and privacy-aware. We’ll prioritize deployable components: an intent/NER pipeline, a compact dialogue manager, secure user profile storage, and an ElevenLabs-driven TTS layer that supports voice selection and persona tuning. How do you balance expressive audio quality with low latency and user privacy?
The next objective is clear: define what “personalized” means in measurable terms. For this project personalization includes adaptive dialogue context (recent interactions and preferences), voice timbre matching or cloning for a user-chosen persona, and per-user behavioral signals that influence phrasing and proactive suggestions. We’ll operationalize these as concrete artifacts: a user vector embedding updated after each session, a voice profile schema (pitch, cadence, timbre weights), and a preferences store accessible only to authenticated sessions. These definitions let us write tests that assert when the assistant is “personalized” versus generic.
Scope boundaries determine what we build now versus later; setting them up front prevents scope creep during implementation. In-scope features include short-term and long-term memory (session context plus retrievable facts), assistant wake/activation handling, integration with ElevenLabs for TTS and optional voice cloning, basic local fallback TTS for offline mode, and analytics for latency, MOS-style audio quality, and personalization effectiveness. Out of scope for the initial release are full multimodal vision inputs, large-scale federated learning, and complex multi-user household management—those add substantial privacy and orchestration complexity that should be phased in later.
Technical constraints and nonfunctional requirements shape architecture choices and trade-offs. We will target sub-300ms TTS latency from request to audio start for an interactive feel, maintain end-to-end encryption for profile data at rest and in transit, and cap per-user storage to a configurable quota to limit costs and GDPR-like data exposure. For voice generation we’ll rely on ElevenLabs’ API for quality and prosody control while implementing local caching of generated audio and selected voice embeddings to reduce repeated API calls. Metrics include average response time, personalization lift (A/B measurable improvements in task success or user satisfaction), and cost per 1,000 interactions.
To make this real, we’ve split the project into pragmatic milestones that map to deliverables and validation scenarios. Phase 1 implements core NLU, session context, and a minimal dialogue manager plus a simple ElevenLabs TTS integration with one selectable voice and automated playback. Phase 2 adds user profiles, secure persistence, voice cloning or persona tuning, and richer personalization signals. Phase 3 focuses on optimization: caching, batching, latency reduction, and polished privacy controls with export/delete flows. Each phase includes end-to-end tests: functional tests, load tests, subjective audio quality checks, and privacy compliance verification.
Finally, we’ll use these goals and scope to guide engineering decisions and trade-offs as we move into implementation. By keeping the project goal-focused—high-quality personalized speech, measurable personalization, and strict privacy controls—we can make explicit choices about cloud vs. edge inference, how aggressively to cache ElevenLabs outputs, and when to introduce richer features. In the next section we’ll translate this scope into a concrete architecture diagram and an initial tech stack so you can start implementing the first milestone with clarity and confidence.
Prerequisites and required tools
Building on this foundation, the first practical step is assembling the tools and platform access you’ll need to implement an ElevenLabs-driven TTS pipeline for a personalized voice assistant. You should have credentials and an operational API workflow in place before implementing synthesis or voice cloning to avoid mid-project blockers. This upfront readiness accelerates development and helps you validate latency, cost, and privacy trade-offs while you wire together NLU, dialogue management, and TTS. How do you verify readiness quickly? Run a smoke test that issues a single synthesis request and validates audio playback and metadata handling.
Start with a reproducible developer environment as your base requirement. You’ll want a recent LTS runtime for your application stack (for example Node.js 18+ or Python 3.10+), Docker for containerized local testing, and a package manager you use in CI. Optionally provision a machine with a discrete GPU if you plan to train or run heavy voice-cloning pipelines locally; otherwise plan for cloud GPU jobs. Configure your terminal tooling (e.g., curl, httpie) and a robust editor or IDE with linting and type-checking enabled so you catch integration errors between NLU models and the TTS layer early.
Account and API access are non-negotiable prerequisites. Create an ElevenLabs account and obtain an API key, then store it in a secrets manager or environment variable and never check it into source control. Plan for rate limits and per-request cost by designing a local caching strategy for generated audio and voice embeddings to reduce repeated calls. We also recommend a fallback local TTS engine for intermittent offline operation or during testing so you can separate audio rendering problems from API integration problems.
On the software side, assemble the SDKs and libraries that connect NLU to synthesis. You’ll need an HTTP client or the official ElevenLabs SDK for synthesis calls, a lightweight dialogue manager (or a small LLM + prompt template pipeline), and a NER/intent library such as spaCy, Rasa, or an LLM client depending on your latency and accuracy targets. For voice cloning, prepare tools that accept WAV/FLAC uploads, enforce sample-rate/bit-depth expectations, and respect consent workflows; a minimal API pattern looks like POST /voices to register a voice sample followed by POST /synthesize referencing the voice ID.
Infrastructure and observability deserve attention before orchestration. Containerize the synthesis worker and the dialogue service, run them under an orchestration tool for local integration tests, and define CI steps that run unit tests and synthetic end-to-end audio checks. Instrument latency metrics (time-to-audio-start), error rates, and a MOS-like subjective metric pipeline so we can guard the sub-300ms target from the spec. Implement caching layers and a CDN for pre-generated clips to lower TTS cost and improve perceived latency in production.
Hardware and privacy tooling are practical prerequisites you must not skip. For recording voice samples collect at least 10–30 seconds of clean speech at a consistent sample rate (16 kHz or higher) and capture metadata for provenance and consent. Encrypt stored voice samples and user profile vectors at rest and enforce access controls so only authenticated sessions can retrieve a user’s voice profile. Legal and compliance checks (consent logging, deletion flows) should be integrated into the onboarding flow so personalization features remain auditable and reversible.
With these pieces in place we can move from checklist to architecture: wired API keys, SDKs, containers, caching, monitoring, and privacy controls form the launchpad for the Phase 1 implementation. Once you confirm end-to-end synthesis from text to audio and validated user-consent handling for voice cloning, we’ll map those components onto the architecture diagram and begin iterative integration and testing.
Create and secure ElevenLabs API key
When you wire ElevenLabs into your assistant, the first practical step is creating a dedicated API key and treating it like any other high-value secret for TTS and voice cloning workflows. This is not an optional convenience: without a properly scoped API key you cannot authenticate requests, track usage, or enforce per-environment limits, and you’ll quickly run into accidental exposure or quota overruns if keys are handled casually. Getting this right up front reduces risk and gives us predictable billing and operational controls as we integrate synthesis into the dialogue pipeline.
Create the key from your ElevenLabs dashboard after you sign in to your account: open the Developers area and choose API Keys, then click Create Key and give it a name. When you generate a key you’ll see the full secret only once, so copy it into your secrets manager or CI secret store immediately; after creation the UI shows only the name and the final four characters. Use the dashboard controls to enable only the features you need (for example Text to Speech and Voices read access) and set an optional credit or character quota per key to limit accidental spend. (help.elevenlabs.io)
Store the API key as a managed secret and never embed it in client-side code or commit it to source control. Pass the key to SDKs or the API through environment variables, Kubernetes secrets, or a cloud secrets manager and restrict access with IAM policies so only the synthesis worker can read the secret at runtime. All ElevenLabs API requests should include the xi-api-key header; SDKs accept the key in their constructors so you can load from process.env or your equivalent runtime config. These measures keep your TTS credentials out of logs, browser bundles, and accidental public repositories. (elevenlabs.io)
Limit scope and apply quotas at key creation to follow the principle of least privilege. Each API key can be restricted by endpoint permissions and by monthly character or credit limits so you can provision separate keys for development, staging, and production. For client-side features that must talk to ElevenLabs indirectly, use short-lived single-use tokens rather than exposing your persistent API key to reduce blast radius. Designing a distinct service-account key for each environment makes auditing, monitoring, and incident response straightforward. (elevenlabs.io)
Operational hygiene matters: rotate and revoke keys proactively, enable usage alerts, and instrument any synthesis service to log key usage metadata (key_id, environment, request latency) so you can detect anomalous patterns early. How do you rotate keys without downtime? Create the replacement key, update the secret in your deployment pipeline, perform a short staged rollout, then delete the old key once telemetry confirms no failures. For multi-seat organizations, provision service accounts and bind keys to those accounts so you avoid tying production access to an individual user and can rotate privileges cleanly. (elevenlabs.io)
In practice you’ll pair these controls with local optimizations to reduce cost and exposure: cache synthesized audio for repeated prompts, pre-generate common phrases, and batch minor TTS requests so you minimize per-request billing and limit the number of times the API key is used. Monitor time-to-audio-start and request error rates so you can correlate cost spikes with app behavior; that telemetry helps decide when to tighten quotas or introduce additional caching. This approach keeps the TTS experience responsive while protecting the API key that enables production voice synthesis.
As a quick implementation example, load the key from an environment variable in your worker and send it in the xi-api-key header for each request. For instance:
# .env
ELEVENLABS_API_KEY=sk_live_XXXXXXXXXXXXXXXXXXXX
# curl example
curl 'https://api.elevenlabs.io/v1/text-to-speech/voice-id' -H 'Content-Type: application/json' -H "xi-api-key: $ELEVENLABS_API_KEY" -d '{"text":"Hello world"}'
We’ll keep these secrets management and key-rotation patterns in mind as we map ElevenLabs into the architecture diagram and move from a single-voice proof-of-concept to per-user voice profiles and optional voice cloning in Phase 2.
Set up STT and NLU pipeline
Building on this foundation, the first engineering milestone is turning raw audio into structured meaning quickly and reliably. Speech-to-text (STT) converts buffered or streaming microphone input into timestamped transcripts; natural language understanding (NLU) then converts those transcripts into intents, entities, and semantic frames we can act on. Define clear latency and privacy budgets up front: for interactive assistant behavior we target sub-300ms time-to-audio-start and under-500ms total for a round of recognition-plus-intent when possible. If you don’t constrain those budgets now, you’ll make trade-offs later that hurt UX and cost.
Start the pipeline with robust input handling so downstream models get clean data. Implement a recorder with sample-rate normalization, voice activity detection (VAD), and per-session diarization if you expect multi-speaker input; these steps reduce false intents and improve entity extraction. For on-device prefiltering use short-term caching and energy-based VAD to avoid sending silence to cloud services, and encrypt every audio chunk in transit to protect consented voice samples. These practical measures reduce API calls, lower cost, and preserve privacy while improving downstream NLU accuracy.
Choose STT and NLU implementations based on latency, accuracy, and maintainability constraints. For low-latency interactive flows prefer an edge or self-hosted hybrid model (e.g., a lightweight ASR like Vosk or on-device Whisper variants) and fall back to cloud services for complex audio or heavy load. For intent and entity extraction you can use a compact classifier plus a rule-based slot-filler, or a small LLM serving as a semantic parser when you need flexible utterance coverage; each approach trades determinism for recall. A minimal integration looks like: capture audio → VAD → short STT call → confidence check → NLU intent classification → dialogue manager invocation.
Design the NLU layer to be composable and testable so you can iterate without retraining large models constantly. Treat intent classification, named-entity recognition (NER), and slot resolution as separate microservices or modules with clearly defined schemas: intent name, slots with types and confidence, and canonicalized entities. Use entity linking for persistent profile lookups (map “my favorite coffee” to a stored user preference) and attach provenance metadata so you can trace predictions back to examples during debugging. When confidence is low, route to a clarification subflow rather than guessing — that preserves trust and lets the assistant learn incrementally.
How do you validate this pipeline? Instrument three core metrics: word error rate (WER) or transcript confidence distribution for STT, intent accuracy and slot F1 for NLU, and end-to-end latency from user speech to action. Create synthetic utterance suites and replay recorded sessions through the pipeline in CI to catch regressions. Add continuous monitoring that correlates low-confidence events with user complaints or fallbacks, and implement automated retraining or prompt template updates for the NLU when systematic errors appear.
Finally, wire outputs into the dialogue manager and synthesis layer so semantics become action and speech. Emit a compact semantic payload (intent, slots, entities, confidence, timestamps) that the dialogue manager consumes deterministically; this keeps your ElevenLabs-driven TTS and voice profiles agnostic to NLU internals. Taking this approach lets us iterate NLU models, swap STT providers, or tune voice personalization independently while preserving observable contracts between components — a practical architecture for building a personalized, privacy-aware voice assistant.
Integrate ElevenLabs TTS and streaming
Building on the prerequisites and key-management guidance above, the fastest way to make the assistant feel immediate is to treat ElevenLabs TTS as a streaming-first service rather than a batch-only audio generator. Start by deciding whether your interaction model needs time-to-first-audio (playback starts while synthesis continues) or full-file determinism (complete audio produced before playback). That decision drives whether you call the HTTP chunked streaming endpoint or the WebSocket “input streaming” flow and heavily influences latency, buffering, and error-recovery design. (elevenlabs.io)
There are two practical streaming patterns you should consider: server-sent chunked streaming for when the full prompt is available up front, and bidirectional WebSocket input streaming for when text is generated incrementally (for example, from an LLM token stream). The chunked HTTP stream returns raw audio bytes progressively so you can feed a player buffer as chunks arrive; the WebSocket path accepts partial text and can begin emitting audio before the whole utterance is sent, which minimizes time-to-first-sound but requires careful chunking and context management. Choose chunked streaming for predictable voice quality and WebSockets when lowest-latency, token-by-token playback matters. (elevenlabs.io)
In implementation, use the official SDK streaming helpers to avoid low-level socket plumbing and to make incremental playback simple. For example, call the SDK’s stream method, pipe received binary chunks into an in-memory buffer or audio player, and start playback as soon as you have a steady buffer (typical player warm-up is 100–300ms). If you need to stitch generated segments (regeneration or multi-turn continuity), send request IDs or next_request_ids so the service can preserve prosody across adjacent clips. Buffer management, backpressure handling, and graceful reconnection are the engineering workhorses that determine whether streaming feels smooth or choppy. (elevenlabs.io)
Expect trade-offs between latency and audio fidelity and plan for them explicitly. ElevenLabs documents parameters and patterns to reduce latency—flash/low-latency models, smaller websocket chunk sizes, reusing TLS sessions, and an optimize_streaming_latency flag (deprecated in some contexts) can shave milliseconds but may change pronunciation or prosodic richness. In practice, premade/synthetic voices produce faster render times than freshly cloned voices; if you need both personalization and interactivity, consider hybrid strategies: use a premade persona for immediate replies and enqueue high-quality personalized clones for follow-up or pre-generated content. Instrument latency, dropouts, and MOS-like quality scores so you can tune these trade-offs empirically. (elevenlabs.io)
How do you wire an LLM-driven output into real-time audio without losing coherence? Stream the LLM tokens to your server, aggregate into sentence-level chunks (or use a small lookahead), and forward those chunks to the WebSocket input stream so audio generation begins early but still has adequate context. Watch out for partial-context artifacts: when the TTS receives only word-by-word fragments it can occasionally switch accent or phrasing mid-sentence; mitigations include chunk-length scheduling, a short sentence buffer, or post-generation stitching using next_request_ids to preserve continuity. Also plan fallbacks: if the websocket fails, retry to the chunked HTTP streaming endpoint rather than falling back to a local low-quality voice immediately. (help.elevenlabs.io)
Operationally, integrate caching, consent, and observability from day one. Cache frequently used phrases and pre-generate welcome/notification audio to reduce API calls and cost; enforce consent and encryption for any cloned-voice samples; and measure time-to-audio-start, first-byte latency, per-request CPU usage, and user-rated MOS to correlate perception with telemetry. Building on our earlier API-key and privacy patterns, provision separate keys for streaming workers, enforce quotas, and add short-lived tokens for client-driven recording or real-time features so you minimize exposure. With those pieces in place we can wire streaming into the dialogue manager and move on to tuning voice profiles and persona persistence in the next section.
Add personalization, memory, and privacy
Making an assistant feel like it knows you requires explicit design choices for personalization, memory, and privacy from the start. We want the assistant to recall relevant facts across sessions, adapt phrasing and voice, and do all of that without creating an unacceptable privacy surface. How do you balance personalization with strict data controls and low-latency interactions? The strategy is to split responsibilities: ephemeral session context for fast responses, retrievable user facts for long-term relevance, and hardened controls for any sensitive artifact such as voice samples or personal identifiers.
Start with a clear memory hierarchy so each piece of data has a purpose and lifecycle. Keep short-term working memory in-memory or in a fast KV store for the duration of a session (transient chat history, recent turn embeddings). Store long-term user facts—preferences, frequent locations, role information—in an encrypted document store or vector index for retrieval. Represent memories with a compact schema that includes provenance and TTL, for example:
{
"id": "mem_123",
"user_id": "user_456",
"type": "preference",
"embedding": [0.012, -0.45, ...],
"text": "Prefers concise answers and British accent",
"created_at": "2026-01-10T12:00:00Z",
"expires_at": "2027-01-10T12:00:00Z",
"consent": "opt_in_voice_personalization"
}
Retrieve memories with similarity search and confidence thresholds so you only surface high-relevance items. Generate an embedding for the current session state and run a nearest-neighbor search against your vector store, then filter by recency, type, and explicit consent flags. Tune retrieval rules to prefer recent session history for dialog coherence and older factual memories for personalization signals; when confidence falls below a threshold, present a clarification prompt instead of making risky assumptions. This reduces hallucination risk and makes memory usage auditable.
Personalization is more than voice selection—it’s how you shape prompts and response style using signals. Capture signals such as response-length preference, domain expertise level, and voice profile (timbre weights, target pitch). At runtime, assemble a prompt template that merges the assistant persona with retrieved memory snippets and guardrails, for example: You are a concise assistant for {{user.name}} who prefers {{user.style}}. Relevant facts: {{memories}}. Use these signals to pick either a premade ElevenLabs voice for instant responses or a queued cloned voice for high-fidelity replies, letting us trade off latency and expressiveness predictably.
Privacy engineering must be concrete: require explicit consent before storing voice samples, encrypt all at-rest artifacts with per-tenant keys, and use short-lived tokens for client-side uploads so the raw API key never leaves your backend. Provide a one-click export and deletion flow tied to the id in the memory schema, and log deletion events to an immutable audit trail. Apply data minimization by truncating or hashing sensitive attributes where possible and limit retention with configurable TTLs to meet compliance needs while preserving personalization value.
Practical caching and hybrid strategies lower cost without widening the privacy surface. Cache synthesized audio for frequently used confirmations and pre-generate onboarding phrases; store cached blobs encrypted and expire them when the underlying voice profile or consent status changes. Use ephemeral client tokens for real-time streaming to ElevenLabs so clients never hold persistent credentials, and fall back to locally hosted TTS when consent or connectivity limits cloning workflows. These patterns keep time-to-first-audio low while respecting privacy constraints.
Measure, iterate, and govern: instrument personalization lift (task success or NPS delta), retrieval precision/recall for memory hits, and privacy events (consent granted, deletion completed). Run A/B tests that compare tailored phrasing and voice variants against a control to quantify benefit, and bake delete-and-verify checks into CI to ensure compliance with user requests. With explicit memory tiers, consented voice handling, and operational telemetry, we can deliver meaningful personalization that scales without sacrificing user trust — next we’ll map these components into the deployment and orchestration diagram so you can implement them end-to-end.



