Define Threat Model & Goals
Building on this foundation, the first practical step is to be explicit about who or what can attack your integration and what success looks like when it doesn’t fail. Secure real-time data access for LLMs expands the attack surface compared with batch pipelines: you now have streaming feeds, persistent connections, ephemeral credentials, and sub-second processing paths that all need protection. We need to translate those characteristics into a concise threat model and concrete goals so you can prioritize controls that preserve both safety and the low-latency integrations your users expect.
Start by enumerating the assets and trust boundaries you must protect. Assets include inbound data streams, model prompts and context windows, inference outputs, metadata (timestamps, routing), key material, and monitoring telemetry. Trust boundaries run across client devices, edge proxies, message brokers, the model-serving cluster, and any third-party connectors. You should treat each boundary as a potential compromise point: an attacker who controls the broker can inject or replay messages; an insider with logging access can exfiltrate prompts and outputs. Naming these assets and boundaries forces precise trade-off conversations about confidentiality, integrity, availability, and privacy.
Next, characterize realistic adversary capabilities and attack vectors so you can prioritize mitigations. Consider eavesdroppers on streaming channels, malicious downstream consumers attempting prompt injection, data-source poisoning, replay and timing attacks, denial-of-service and resource-exhaustion attacks that raise latency, and insider misuse of stored context. Which of these are most likely in your environment depends on deployment model: are you using customer-managed connectors, multi-tenant brokers, or public APIs? How do you weigh confidentiality against latency and complexity when every millisecond counts?
Translate threats into measurable security goals that align with operational SLOs and compliance constraints. For confidentiality, require end-to-end encryption in transit and per-message authentication (for example, mTLS plus message MACs) so that only authorized services can read or inject context. For integrity and non-repudiation, guarantee tamper-evident logs and HMAC-verified message headers. For availability and latency, set targets like 99.95% availability for inference and a 200–500 ms tail latency budget for the real-time path; every security control must be evaluated against that budget. For privacy, minimize retained context, redact or tokenise PII before it reaches the model, and require auditable access controls with short-lived credentials.
Be explicit about the trade-offs you’ll accept and the operational patterns that enable them. Stronger encryption and token validation increase CPU and can add microseconds to round-trips; batching reduces cryptographic overhead but increases latency—use adaptive batching thresholds where throughput is high and strict per-message guarantees where latency is critical. Rotate keys automatically and use ephemeral service tokens for connectors to limit blast radius. Implement selective logging that preserves auditability without retaining raw prompts, and enforce rate limiting and circuit breakers upstream to protect your model-serving cluster from surge and abuse.
Finally, codify the threat model and goals into short statements and SLOs you can reference during design and incident response. For example: “Adversary can observe network traffic but cannot decrypt messages; goal is to prevent unauthorized prompt injection and maintain 200 ms median inference latency, 99.95% availability, immutable audit logs for 90 days, and zero persistent storage of raw PII.” Attach specific acceptance tests: replay attempt rejected within 1s, HMAC failures logged and alerted, and key compromise rotation completes within 5 minutes. With these statements in place, we can now map mitigations to each risk and validate them under realistic latency budgets.
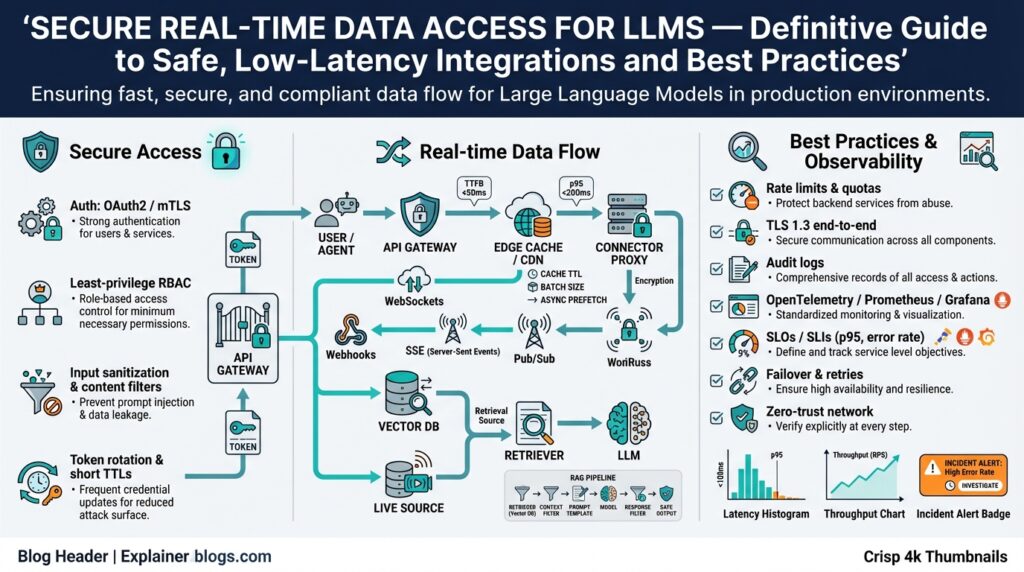
Choose Secure Architecture Patterns
Building on this foundation, the first design choice you should make is which architectural family will encode your security trade-offs—this decision determines whether you can achieve secure real-time data access for LLMs while preserving strict low-latency requirements. Start with a hook: if a millisecond of cryptographic verification costs you user abandonment, you must pick patterns that move heavy checks off the critical path. We’ll treat latency and confidentiality as co-primary constraints and evaluate options—proxy-based sidecars, brokered pub/sub, and direct client-to-model streaming—against those constraints so you can choose pragmatically.
The simplest pattern for predictable control is a fronting API gateway or sidecar proxy that enforces authentication, rate limits, and token exchange before any message reaches the model-serving plane. In this setup the gateway handles per-connection TLS and policy checks while the data plane remains optimized for throughput, which helps keep tail latency low. However, that centralization creates a stronger trust boundary and increases blast radius unless you combine it with mutual TLS (mTLS) and per-message HMACs for end-to-end integrity. How do you balance per-message authentication with tight latency budgets? Use hybrid placement: authenticate and authorize at the gateway, then attach short-lived attestation tokens or MACs for fast data-plane verification.
An alternative is a brokered streaming architecture (message broker or pub/sub) that decouples producers and consumers and gives you built-in delivery semantics and replay controls. This brokered approach simplifies indexing, audit, and selective replay, but multi-tenant brokers require strict tenant isolation and strong encryption-at-rest and in-transit to protect prompts. To reduce exposure, separate control-plane credentials (for topic management) from data-plane tokens (for publishing/subscribing) and enforce ephemeral credentials via a secure token service (STS). Per-message nonces and HMAC headers prevent replay and make tampering evident without expensive public-key ops on every message.
When privacy is paramount, consider moving redaction and minimalization to the edge: strip PII, tokenise identifiers, or convert high-risk fields to opaque references before context reaches the model. This approach reduces the volume of sensitive data that traverses your system and simplifies compliance. For workloads requiring stronger confidentiality, integrate Trusted Execution Environments (TEEs)—hardware-backed secure enclaves that isolate computation and keep data encrypted outside the enclave—so you can run inference without exposing raw context to host operators. TEEs add complexity and measured latency, so evaluate them for high-value, high-risk flows rather than blanket use.
Resilience and anti-abuse patterns matter because security controls that increase CPU can also create denial-of-service vectors through contention. Protect the model-serving path with backpressure and adaptive batching: aggregate messages when throughput is high to amortize crypto and reduce syscall churn, and process singletons when latency budgets are tight. Implement circuit breakers and graceful degradation so authentication or broker failures cause controlled fallbacks (token-only validation, degraded feature set) instead of full outages. Finally, design idempotency and sequencing logic into message handlers to prevent replay and ordering attacks while keeping retry behavior predictable.
Operationally, choose patterns that make observability safe: emit telemetry and metrics that reflect errors, latency, and HMAC failures but redact or hash prompts and sensitive metadata before logging. Maintain immutable, tamper-evident audit trails for token issuance and role changes, and map each architectural pattern to specific SLO tests—replay attempts rejected in under 1s, key compromise rotation under 5 minutes, and 99.95% availability for the real-time path—so you can validate both security and latency. With these architecture patterns selected and instrumented, we can move on to mapping concrete mitigations to the highest-priority risks and validating them against our latency budgets.
Authentication and Authorization
Real-time data access creates a different threat surface than batch pipelines, and the first defensive line is a pragmatic mix of strong authentication and fine-grained authorization that won’t blow your latency budget. When you stream prompts and context for live LLM inference, require mutual authentication at connection time (for example mTLS) andattach short-lived, per-connection attestations or per-message MACs so the data plane can verify integrity with microsecond checks. Use ephemeral credentials to limit blast radius: short TTLs, strict audience/scopes, and automated rotation reduce how long a stolen token can be abused while keeping throughput high.
Authentication answers who is speaking; authorization answers what they may do. Implement identity first: every client, edge proxy, connector, and model-serving node should have an identity issued by a centralized authority (a secure token service). Then express authorization as machine-readable claims (scopes, roles, topic IDs) that live inside those tokens. This separation lets us revoke or narrow privileges without reconfiguring services, and it enables per-flow decisions—publish-only tokens for producers, subscribe-only tokens for consumers, and admin tokens for control-plane operations.
Design your token flow for the real-time path rather than bolting checks onto it. Authenticate and perform heavy policy evaluation at an edge gateway or sidecar during session establishment, then hand the client a compact attestation token and a per-connection symmetric key for HMACs. In a brokered pub/sub model keep control-plane credentials (topic creation, ACL changes) separate from data-plane credentials (publish/subscribe). Per-message nonces and sequence numbers included in HMAC headers prevent replay without forcing asymmetric crypto on every packet, which is essential when you’re optimizing for low tail latency in real-time data access.
Make ephemeral credentials operationally robust: issue them from an STS with short TTLs (seconds to minutes depending on flow), bind them to connection metadata (client ID, IP range, session ID), and rotate signing keys automatically. Validate HMACs with a lightweight check in the data-plane handler; for example, in pseudocode:
# verify incoming message
expected = hmac_sha256(key=session_key, data=msg.headers + msg.payload)
if not constant_time_eq(expected, msg.hmac):
reject("hmac-failure")
This pattern keeps public-key operations off the critical path while preserving end-to-end authenticity for each message.
Which authorization model should you pick—RBAC, ABAC, or capability-based tokens? Use RBAC for predictable, coarse-grained controls (developer, analytics, inference) and ABAC when you need fine-grained context: time-of-day, quota remaining, request latency class, or data-sensitivity labels. Capability-based tokens (scoped, single-purpose credentials) work best for ephemeral connectors and third-party integrations where you need least-privilege guarantees without service-side policy lookups. Implement token introspection for long-lived sessions only; otherwise prefer locally verifiable claims to avoid synchronous policy lookups that add latency.
Measure the latency cost of each control and optimize the critical path: prefer session-level asymmetric auth and per-message symmetric MACs, enable TLS session resumption to amortize handshake costs, and cache verified token metadata close to your data plane. Implement adaptive batching to amortize crypto overhead when throughput is high, but ensure singleton paths for low-latency requests remain available. Map each control to an SLO: authentication latency budget, HMAC verification time, token issuance SLA, and revoke/rotation completion time so you can automate trade-offs under load.
Observability and incident response must respect privacy while remaining actionable. Emit HMAC-failure rates, token-revocation events, and per-credential usage metrics but redact or hash prompts and PII before logging. Automate revocation and rotation workflows so we can remove compromised credentials within the SLO you defined earlier, and integrate alerts for anomalous token behavior (sudden spike in use, geographic drift, or repeated HMAC failures). Taking these steps prepares the system to reject and contain attacks quickly while preserving the low-latency guarantees that make real-time data access for LLMs valuable.
Encrypt Transport and Storage
Building on the threat model and authentication patterns we just discussed, the next operational priority is encrypting both transport and stored data so you preserve confidentiality without breaking low-latency guarantees. Strong encryption and the right cipher choices protect prompts, context windows, and key material as they cross trust boundaries, while careful placement of cryptographic work keeps tail latency within your SLOs. We’ll focus on practical patterns you can measure and deploy: TLS negotiation and session resumption, mutual TLS for service identity, message-level authenticated encryption, and robust key lifecycle management for encryption at rest.
For transport, use modern TLS with ECDHE-based key exchange to guarantee forward secrecy and pick AEAD cipher suites (for example AES-GCM or ChaCha20-Poly1305) to provide combined confidentiality and integrity with minimal round-trips. Enable TLS session resumption and TLS 1.3 to reduce handshake costs; evaluate 0-RTT only after you understand replay risks because it trades lower latency for potential replay exposure. Where mutual identity matters—between edge proxies, brokers, and model-serving nodes—deploy mTLS so both endpoints authenticate during the handshake and you can bind session keys to identities for per-connection authorization checks.
In brokered or multi-hop flows, end-to-end encryption across intermediary services prevents a compromised broker from reading prompts. How do you get true end-to-end encryption while still using a broker for delivery? Use envelope encryption: perform an asymmetric key exchange once (or at session start) to derive a short-lived symmetric key, then encrypt each message with an AEAD cipher and include a per-message nonce, sequence number, and HMAC-like tag for quick integrity checks. This pattern keeps expensive public-key operations off the critical path and lets the data plane verify authenticity with microsecond symmetric operations.
Key management is the backbone of any encryption strategy. Store long-term wrapping keys in a KMS or HSM, and use them to envelope-encapsulate ephemeral per-session keys that live only in memory on the parties that need them. Derive session keys with HKDF from the TLS master secret or an authenticated key-exchange so keys are bound to connection metadata, and automate rotation and revocation workflows so a compromised node can be cut off within your SLO. Keep key lifetimes short (seconds to minutes for real-time flows), log issuance and revocation events to immutable tamper-evident audit trails, and restrict key-export operations in your KMS policy.
Encryption at rest must be layered and context-aware: enable full-disk or volume encryption for host compromise scenarios, use object-store server-side encryption for blobs, and apply field-level or column-level encryption for sensitive prompts and PII that require selective access. Be mindful of deterministic encryption when you need indexing or joins—deterministic modes leak equality information—so prefer tokenization or indexed hashes for searchable identifiers and reserve deterministic keys for limited, well-audited use cases. Backups, snapshots, and audit logs should also be encrypted with separate keys and rotated on the same schedule as primary keys to avoid a single point of failure.
Observability and incident response must respect encrypted data: redact or hash prompts before emitting telemetry, encrypt log stores and audit exports, and implement access controls that require dual authorization for decryption of sensitive archives. Instrument HMAC-failure, key-rotation, and unexpected-key-use metrics to trigger automated revocation playbooks; this gives you actionable alerts without exposing raw context. For compliance, map encryption controls to retention SLOs and proof-of-encryption checks so you can demonstrate both technical controls and operational readiness.
Finally, balance cryptographic strength with performance by benchmarking in your environment. Take advantage of CPU features (AES-NI) or hardware crypto offload on inference nodes, choose ChaCha20 for lower-power edges when appropriate, and push heavy asymmetric ops to an edge gateway or token service to keep the data path lean. Combine session-level asymmetric auth with per-message symmetric AEAD, use adaptive batching to amortize crypto overhead under load, and measure tail-latency impact continuously so we can trade microseconds for materially better confidentiality without surprising users or violating SLOs.
Taking these measures together—transport-level TLS and mTLS, end-to-end message encryption, disciplined key management, and layered encryption at rest—lets us protect prompts and model outputs across the real-time path while preserving the latency and availability requirements that make low-latency LLM integrations practical. In the next section we’ll map these controls to specific threat scenarios and SLO-driven acceptance tests so you can validate them under realistic load and failure conditions.
Optimize Latency and Throughput
Building on this foundation, optimizing latency and throughput for real-time LLM integrations is an engineering problem and an economic decision: every millisecond you shave from the critical path changes user experience and every extra request-per-second you support changes cost and attack surface. Start by treating latency and throughput as first-class signals in your design—measure them, set SLOs, and encode trade-offs into your architecture so security controls don’t accidentally inflate response time. Using clear, measurable goals up front keeps us honest when we add authentication, encryption, or anti-abuse controls to a low-latency data path for LLMs.
Begin with precise metrics and real workload baselines rather than synthetic guesses. Define median (p50), tail (p95/p99) latencies, and throughput units (requests/sec or tokens/sec) for each flow; tie those to business impact—e.g., interactive assistants require sub-300 ms median response while telemetry ingestion can tolerate larger latency. Capture distributional behavior under representative concurrency and payload sizes, and instrument key micro-operations: TLS handshake time, HMAC verification time, model decode time, and queuing delays. How do you measure and trade off latency versus throughput in practice? Run controlled A/B tests and staged load tests that vary batching, connection counts, and crypto offload while observing p99 latency and sustained throughput.
Push heavyweight operations off the critical path and amortize fixed costs where safe. Authenticate and perform policy evaluation at session establishment, then hand clients compact session keys so per-message checks are lightweight symmetric ops. Use TLS session resumption and mTLS for identity, but avoid repeated asymmetric crypto on every message; instead verify per-message integrity with HMAC or AEAD tags. Employ adaptive batching: switch between singleton processing for latency-sensitive requests and small batches when throughput is high, using a dynamic threshold that increases with queue depth and drops when tail latency rises. A simple control loop looks like: if queue_depth > q_high then batch_size = min(batch_size + 1) else if p99_latency > target then batch_size = max(batch_size – 1).
Manage contention with resource isolation and admission control so throughput gains don’t collapse latency. Reserve CPU cores or use CPU pinning for cryptographic verification and model workers to avoid noisy-neighbor interference, and use cgroups or containers to enforce limits. Implement backpressure and token-bucket rate limiting upstream so bursts are smoothed rather than causing head-of-line blocking in the model-serving queue. Use priority queues for mixed-criticality workloads (interactive sessions first, analytics later) and circuit breakers that degrade gracefully—disable nonessential enrichment pipelines instead of letting auth or broker failures spike latency across all requests.
Make payload format and I/O efficient: prefer compact binary serialization (for example, protobuf or MessagePack) for frequent messages and stream outputs with chunked framing to reduce buffering. Avoid compressing tiny messages; compress only when payload size exceeds an empirically determined threshold because compression can add CPU latency despite saving network time. Use zero-copy patterns where possible—memory-map shared buffers, reuse buffers in pooled allocators, and enable gRPC or WebTransport streaming modes to reduce syscalls and copies that hurt throughput at high concurrency.
Measure, correlate, and automate tuning rather than guessing knobs manually. Instrument distributed traces that show crypto, serialization, and model-inference spans so you can pinpoint slow components, and emit HMAC-failure and token-revocation metrics to correlate security events with latency spikes. Automate load-shedding rules based on real-time telemetry: when p99 rises above the SLO, switch to degraded mode (reduced context, token-only validation) and alert operators. Regularly run chaos and spike tests to validate that adaptive batching, backpressure, and rotation workflows meet both security and latency SLOs under stress.
Iterate with safe defaults and small, measurable changes: start with session-level asymmetric auth plus per-message symmetric AEAD, conservative batching thresholds, and explicit SLOs for p50/p95/p99 and sustained throughput. We balance confidentiality, integrity, and availability by profiling the real-time path, moving heavy crypto to pre-session steps, isolating resources, and making degradation predictable. Taking an SLO-driven approach lets us tune latency and throughput without blind trade-offs, and in the next section we’ll map these optimizations back to specific threat scenarios and acceptance tests so you can validate both security and performance under realistic conditions.
Monitoring, Auditing, and Alerts
Building on this foundation, the single most important operational capability is continuous, privacy-safe visibility into the real-time data access path so you can detect integrity failures, latency regressions, and misuse before they impact users. You should instrument end-to-end telemetry that captures p50/p95/p99 latency, HMAC/AEAD verification times, token issuance and revocation events, queue depth and backpressure signals, and model decode time while ensuring prompts and PII are redacted or hashed before they hit your logs. Early visibility gives you the lead time to trade degraded features for availability without violating the confidentiality guarantees we established earlier. How do you detect a prompt-injection attempt in real time? Correlate sudden HMAC failures, unexpected sequence-number gaps, and anomalous downstream outputs with token usage patterns and source geography to surface likely attacks quickly.
Define the metrics that matter and make them actionable. Instrument both business-facing SLOs (inference latency p50/p95/p99, throughput) and security-specific indicators (HMAC-failure rate, token-exchange latency, replay-attempt counts, per-credential request rate, and unexpected-key-use). Emit these metrics as high-cardinality time series only where they add diagnostic value; aggregate and roll up at the edge to avoid exploding cardinality in your long-term store. For audit logs, produce immutable, tamper-evident entries for token issuance, key rotations, ACL changes, and replay-rejection events—log the fact of an event, not the raw prompt—and anchor them into a write-once store that supports efficient queries during an investigation.
Turn telemetry into precise alerts and escalation playbooks so your team can act fast with minimal noise. Translate SLO breaches and security signals into two classes of alerts: operational (latency, queue saturation, TLS/mTLS handshake errors) and security (HMAC-failure spikes, geographic drift of credential use, sustained token-revocation spikes). Use rate-threshold and anomaly-detection rules together; for example, alert on HMAC-failure-rate > 0.5% sustained for 5 minutes OR a 5x sudden spike versus the 1-hour baseline. Route alerts to differentiated channels—on-call engineers for critical p99 breaches, security ops for anomalous credential behavior—and attach an automated runbook that lists immediate mitigations (revoke token, switch to degraded validation mode, enable additional logging) and the owner for each step.
Correlate traces, logs, and metrics to reduce mean time to remediate. Distributed tracing should include crypto and token spans so you can quickly see whether a latency spike came from TLS handshakes, HMAC verification, or model decode. During an incident, pivot from a failed trace to an immutable audit log entry that shows which credential and which signing key were used, then examine token issuance events to determine blast radius and required revocations. Automate common containment actions where safe: an alert that shows a credential has suddenly moved across regions should trigger automated short-lived revocation and require a policy-driven reissue rather than manual intervention.
Keep monitoring and audit pipelines privacy-aware and tamper-resistant. Redact prompt text and replace identifiers with salted hashes or deterministic tokens when you need referential integrity for debugging; store full-bodied traces only in encrypted, access-controlled archives with dual-authorization for decryption. Keep audit logs write-once and checksumed, and instrument them with HMACs so tampering attempts are detectable. Retain logs long enough to satisfy compliance SLOs from earlier (for example immutable audit logs for 90 days), but avoid keeping raw prompts; instead retain pointer metadata that enables lawful replay under approved procedures.
Validate alerts and post-incident workflows with regular exercises and automated tests. Run chaos tests that simulate token compromise, replay attacks, and broker failure while asserting that alerts fire within your defined SLOs and automated playbooks perform expected mitigations within target windows (for example, rotation completes under 5 minutes). Treat measurement as a habit—dashboard burn-ins for new releases, weekly review of false-positive rates, and periodic tuning of anomaly detectors—so monitoring, audit logs, and alerts operate as a control loop that protects low-latency real-time data access for LLMs without eroding privacy or availability.



