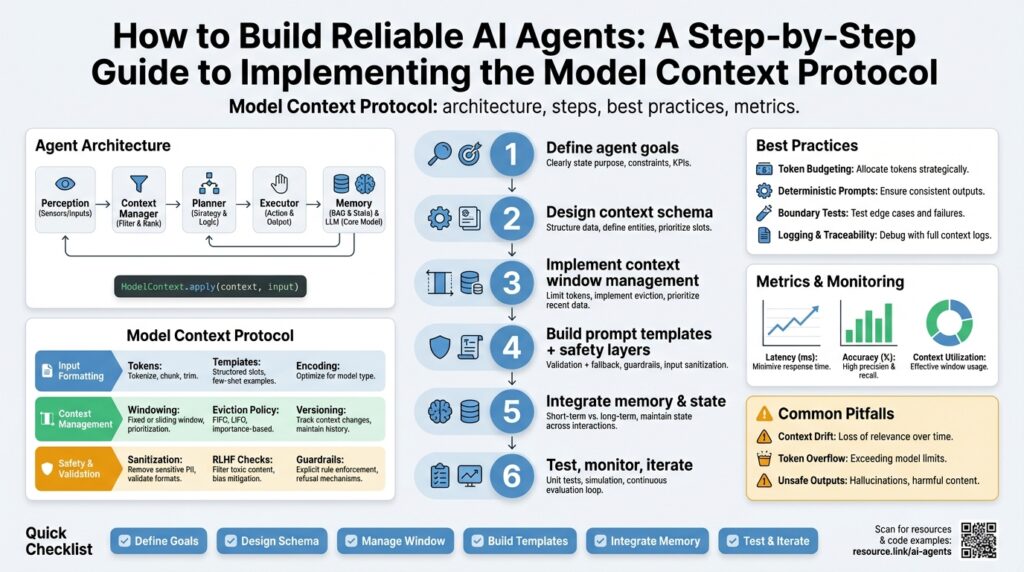
MCP overview and use cases
Building on the foundation we established earlier, the Model Context Protocol (MCP) is the mechanism that turns ephemeral model outputs into durable, queryable state for AI agents and toolchains. If you want reliable multi-turn behavior, predictable tool invocation, and recoverable workflows, you need a consistent approach to context management that the Model Context Protocol defines. MCP and its primitives let you version, annotate, and lease pieces of conversational or operational context so agents can coordinate without re-computation or brittle ad-hoc wiring. This section explains what the protocol does and how you can apply it to real engineering problems with AI agents.
At its core, MCP standardizes three capabilities: contextual storage, semantic annotation, and lifecycle controls. Contextual storage means preserving a model’s inputs, outputs, and intermediate symbols (we’ll call these context objects) in a way that other processes can retrieve deterministically. Semantic annotation attaches typed metadata — for example, provenance, confidence, or schema — so downstream agents can filter or validate data. Lifecycle controls (leases, checkpoints, expirations) let you control ownership and garbage collection of context objects so stale state doesn’t corrupt long-running automation.
Let’s define a couple of terms you’ll use frequently. A context window is the set of context objects an agent considers when generating a response; a checkpoint is an immutable snapshot of that window; a lease is a short-lived ownership token that prevents concurrent updates during critical operations. These primitives let you enforce deterministic behavior: for instance, an agent can take a lease on a user session, write a checkpoint after a successful tool call, and release the lease to allow other agents to continue. By using these building blocks, MCP moves you from ad-hoc state passing to a robust protocol that supports retries, audit logs, and compliance controls.
How do you apply this in practice? Imagine a customer-support pipeline where separate agents handle intent classification, knowledge retrieval, and response generation. With MCP you persist the classifier’s output as a context object annotated with confidence and source document IDs. The retriever agent queries only objects with sufficient confidence and a matching schema, reducing hallucinations and redundant calls. For long-running workflows like order fulfillment or infrastructure automation, MCP lets you checkpoint the workflow state after each external side-effect so you can replay or rollback safely after failures.
Operationally, you’ll make tradeoffs around consistency, latency, and storage. Use strong leases and synchronous checkpoints when you need ACID-like guarantees for financial or safety-critical agents; prefer optimistic leases and eventual consistency for high-throughput conversational assistants where throughput matters more than tight coordination. Protect private data by encrypting context items at rest and tagging sensitive schema fields so policy agents can redact or truncate before reuse. Also plan retention policies: shorter retention for transient chat logs, longer retention for audit trails and models that learn from historical context.
To make MCP concrete, start with a minimal server API: createContext(obj), annotate(id, metadata), acquireLease(id, owner, ttl), checkpoint(id), and query(filter). Implementing these endpoints with idempotent semantics and stable identifiers gives you a foundation to build higher-level patterns: agent chaining, cascade retries, and multi-agent arbitration. As we proceed to implementation details, we’ll map these primitives into sample code, storage designs, and failure-recovery patterns so you can deploy the Model Context Protocol in your own agent architectures and achieve predictable, maintainable behavior from your AI agents.
Prerequisites and environment setup
Building on this foundation, the first thing we need is a reproducible developer environment that lets you iterate on the Model Context Protocol (MCP) without surprising state or hidden dependencies. Start by pinning language runtimes and SDK versions so your tests exercise the same protocol semantics developers will see in production; for example, lock Node.js or Python versions in your CI matrix and use a shared virtual environment. Ensure your repository contains automated checks for schema changes to context objects so accidental metadata drift (which breaks semantic annotation consumers) is caught early. Treat the environment as part of the protocol: consistent runtimes, schemas, and SDK behavior reduce subtle bugs when agents coordinate via contextual storage.
For storage, plan for two data planes: a fast read path for retrieval and a durable write path for auditability. Use a vector database (for example, Milvus or similar) or a search index to power semantic queries, and a relational or document store for canonical metadata and checkpoint records; this separation keeps queries for semantic similarity fast while preserving strong consistency for leases and checkpoints. You should also provision an object store for larger model artifacts or payloads that belong to context objects, and expose stable identifiers so createContext and checkpoint operations can be idempotent. By separating responsibilities—semantic retrieval, durable metadata, and blob storage—you keep MCP primitives performant and auditable.
Infrastructure tooling matters: containerize the MCP service and run it behind a service mesh in staging to simulate production networking and retries. Use Docker for local parity, and run orchestration (Kubernetes or an equivalent) in integration testing so lease expirations, TTLs, and circuit-breaker behavior are observable under realistic load. Integrate secrets management (Vault, SOPS, or cloud KMS) for encryption keys and ensure your CI/CD pipeline injects secrets only at runtime. Observability should be baked in from day one: structured logs, distributed traces, and metrics for lease contention, checkpoint latency, and query hit rates let us detect coordination bottlenecks early.
Local development and automated testing should validate determinism and failure modes, not just happy paths. Run unit tests that mock downstream tools and integration tests that spin up a transient database and object store; include deterministic RNG seeds and replayable fixtures so we can reproduce race conditions. How do you verify idempotency and lease semantics? Create fuzz tests that simulate concurrent agents acquiring and releasing leases, then assert checkpoint invariants and absence of duplicate side effects. Include end-to-end scenarios that exercise rollback and replay: simulate a failed external side-effect, then confirm the checkpoint and lease flow allow a safe retry without duplicating actions.
Security and data governance must be explicit requirements, not afterthoughts. Classify fields in context objects and tag sensitive schema attributes so policy agents can redact or apply differential retention automatically; encrypt context payloads at rest and use field-level encryption for high-sensitivity attributes. Implement fine-grained ACLs around acquireLease and checkpoint endpoints so only authorized agents can mutate session state, and emit immutable audit entries for each lease lifecycle transition to support compliance reviews. These controls make MCP safe to deploy for workflows that require audit trails or handling of personally identifiable information.
Finally, make the initial deployment iterative and measurable: start with a single integration—perhaps the classifier-to-retriever pipeline we discussed earlier—and instrument key metrics (checkpoint frequency, query latency, lease conflicts). Create migration scripts that backfill essential context objects and verify downstream consumers against the new contextual storage shape before switching traffic. By phasing rollout and validating both semantic annotation consumers and lifecycle controls, we reduce operational surprise and set the stage for implementing the protocol endpoints and sample code in the next section.
Design MCP server architecture
Building on this foundation, the starting point is to treat the Model Context Protocol (MCP) service as a coordination plane for durable conversational state and semantic metadata. If you’ve experienced brittle multi-agent flows, it’s usually because contextual storage and lifecycle controls were scattered across services with no single source of truth. By front-loading a clear contract for createContext, annotate, acquireLease, checkpoint, and query, you give agents deterministic primitives they can rely on under retries and failures. How do you avoid state-duplication and race conditions when many agents operate on the same session concurrently?
Begin by partitioning responsibilities into clear components: a lightweight, stateless API gateway for authentication and request validation; a lease manager that issues short-lived ownership tokens; a checkpoint service that writes immutable snapshots; a semantic query engine backed by a vector index; and a metadata store for provenance and ACLs. This separation keeps hot-path requests fast while pushing durability and auditability to the checkpoint pipeline. Keep the API idempotent—require clients to supply stable identifiers or client-generated idempotency keys—so retries don’t create duplicate context objects or side effects.
For the data plane, separate semantic retrieval from canonical metadata and blobs. Use a purpose-built vector database for similarity searches and a relational or document store for strong consistency of leases and checkpoint records; place large payloads in an object store with stable URIs referenced by context objects. This two-plane approach lets you tune replication and consistency per workload: synchronous commits and strong leases for financial or safety-critical flows, eventual consistency with background reconciliation for high-throughput chat assistants. Cache query results where semantics are stable and invalidate on relevant checkpoints to reduce query latency without breaking correctness.
Define lease and checkpoint semantics up front and encode them into the API surface. Implement leases as bearer tokens with a TTL and owner ID—acquireLease(sessionId, owner, ttl) -> token—and require the token for any mutating checkpoint call; use a compare-and-swap (CAS) or version number on checkpoint records so writers detect staleness. Prefer pessimistic leases when you must prevent concurrent side effects; prefer optimistic leases plus idempotent checkpoints when throughput matters. For distributed coordination, rely on a consensus-backed key-value store or a well-tested locking algorithm (for example, using Redis with careful expiry semantics) and treat lease expiration as a first-class failure mode that your replay logic must handle.
Scale by sharding sessions and parallelizing the semantic query layer independently from the metadata plane. Route requests by session namespace or tenant ID so lease contention is localized, and autoscale vector query nodes separately from checkpoint writers. Instrument metrics for lease contention rate, average checkpoint latency, query hit rate, and orphaned-lease counts; wire distributed traces through the entire checkpoint path so you can reconstruct what agents observed and why a retry occurred. Design your GC process to respect retention policies and audit requirements: background reclaimers should move expired context into cold storage rather than deleting immediately, enabling compliance and post-mortem replay.
Treat security and governance as integrated concerns, not add-ons. Encrypt context payloads at rest and use field-level encryption for high-sensitivity attributes while keeping searchable embeddings separate and policy-tagged. Enforce fine-grained ACLs on acquireLease and checkpoint endpoints, emit immutable audit events for every lifecycle transition, and provide a redaction pipeline that policy agents can invoke before context is materialized into a model prompt. These controls let you operate MCP for regulated or privacy-sensitive workflows with confidence.
Taking this concept further, prototype the smallest possible service that enforces stable identifiers, idempotent checkpointing, lease ownership, and semantic annotation—then iterate. By decoupling retrieval, durability, and coordination and by making leases and checkpoints explicit protocol primitives, you get predictable agent behavior, recoverable workflows, and a straightforward path to production-grade observability and governance. In the next section we’ll map these concepts into concrete API examples and sample storage schemas so you can implement the service incrementally and validate invariants under load.
Implement MCP server connectors
Building on this foundation, the first thing to accept is that connectors are the boundary where the Model Context Protocol becomes operational. We treat MCP as a contract: connectors translate agent intentions into idempotent storage operations, lease requests, and semantic queries. If you design this boundary carefully, you prevent race conditions and ambiguous ownership—two common causes of duplicated side effects in multi-agent workflows. This paragraph frames why connector design matters before we dive into concrete patterns and APIs.
Start by defining a small, explicit API contract that your connectors implement and validate. Require stable identifiers or client-generated idempotency keys on createContext and checkpoint calls, and emit deterministic responses for retries so clients can reason locally about success. Implement acquireLease(sessionId, owner, ttl) -> token as a bearer token that mutating calls must present, and enforce a CAS or version check on checkpoint writes so stale writers detect conflicts. These choices reduce the need for complex distributed locking and keep the metadata plane strongly consistent while letting the semantic plane be tuned separately.
Choose transport and authentication based on your latency and interoperability constraints. REST is pragmatic for HTTP-native clients and easy to observe in meshes, while gRPC gives you lower latency and streaming semantics for high-throughput agents; both can expose the same protocol semantics. Authenticate connectors with short-lived mTLS certificates or OAuth tokens and bind lease tokens to the connector identity to make audits meaningful. How do you make connectors resilient to lease churn and network partitions? Implement retry policies with jitter, treat lease expiration as a first-class event, and design replayable checkpoints so a connector can safely resume after a transient failure.
Separate semantic retrieval from canonical metadata inside the connector implementation. Translate annotate and query calls into two paths: write a small, canonical record to the metadata store (includes provenance, schema, and ACLs) and push embeddings or large payloads to the vector index or object store referenced by a stable URI. Cache semantic results where embeddings are stable and invalidate those caches on relevant checkpoint events; this keeps similarity queries fast without sacrificing correctness. For example, when a classifier produces a document ID and confidence, the connector should persist the record and asynchronously upsert the embedding so retrievers see consistent semantics under eventual consistency.
Operational robustness comes from thorough testing and instrumentation of connectors. Write concurrency fuzz tests that simulate dozens of agents acquiring and releasing leases on the same session, assert no duplicate external side effects, and verify checkpoint version monotonicity. Use integration tests that spin up a transient vector DB and simulate slow network I/O so you can validate timeout behavior and idempotent retries. Instrument key metrics—lease acquisition latency, lease contention rate, checkpoint commit time, and orphaned-lease counts—and export traces that let you reconstruct the exact sequence of connector calls for post-mortems.
Security, governance, and rollout are the final pieces you must encode in connector policy. Enforce field-level encryption for sensitive attributes, tag schema fields for automatic redaction in the connector pipeline, and require ACL checks before acquiring a lease or emitting a checkpoint. Roll out connectors incrementally by routing a small percentage of sessions through the new path and backfilling context objects as needed, and make the connector surface backward-compatible by honoring legacy idempotency keys. Taking this approach, we can implement reliable, observable connector code that lets agents trust the Model Context Protocol primitives; next, we’ll map these contracts into concrete API examples and storage schemas for incremental implementation.
Build agent client integrations
Building on this foundation, integrating agent clients with the Model Context Protocol (MCP) is the moment the protocol delivers operational value. You need agent client integrations that translate intent into idempotent createContext, annotate, acquireLease, and checkpoint calls while preserving ownership semantics, and that’s what we’ll make concrete. How do you design connectors that keep leases, checkpoints, and semantic annotations consistent under retries and partial failures? Start with a tight contract: require stable identifiers or client-generated idempotency keys, return deterministic success markers, and make acquireLease(sessionId, owner, ttl) produce a bearer token the client must present for any mutating checkpoint. This front-loads correctness where agents interact with contextual storage and reduces ambiguity during replay or retry.
Design each connector to separate control path actions from semantic writes so you avoid coupling lease lifecycle to heavy embedding updates. The connector should synchronously write a small canonical metadata record (provenance, schema, ACLs, version) and asynchronously upsert embeddings and large blobs to the vector index or object store referenced by stable URIs. Use a compare-and-swap (CAS) or monotonic version number on checkpoint writes so clients detect stale writes and surface conflicts early. Prefer synchronous checkpoint commits when side effects must be atomic; prefer optimistic leases with idempotent checkpoints where throughput matters. These decisions map directly to the tradeoffs we discussed around consistency, latency, and storage.
Choose transport and authentication to match your latency and interoperability needs while keeping protocol semantics identical across transports. REST works well for broad compatibility and easy observability in service meshes, while gRPC offers streaming and lower-latency semantics for high-throughput agents; implement the same idempotency and lease semantics in both. Bind lease tokens to connector identity using short-lived mTLS certs or OAuth, and enforce token checks server-side for checkpoint mutations. Implement client retries with exponential backoff and jitter, treat lease expiration as a first-class event in the client state machine, and make every mutating call tolerant of duplicate invocations by honoring idempotency keys.
Operationalize the semantic vs canonical data paths inside the connector implementation to keep queries fast and correctness tractable. Push embeddings to your vector index and index only lightweight references in the metadata store so semantic queries remain performant; invalidate caches on checkpoint events and support a background reconciliation job to heal eventual consistency gaps. When a classifier produces document IDs and confidence scores, persist the canonical record atomically and then publish embeddings asynchronously—retrievers will see monotonic updates without blocking critical checkpoint paths. This pattern reduces hallucination surface area by ensuring retrievers only query annotated, versioned context objects.
Test connectors against real-world concurrency and failure modes instead of hypothetical single-threaded flows. Build fuzz tests that simulate dozens of agents acquiring leases on the same session, assert no duplicate external side effects, and confirm checkpoint version monotonicity under retries. Instrument lease acquisition latency, contention rate, checkpoint commit time, and orphaned-lease counts, and export distributed traces so we can reconstruct the precise sequence of connector calls during a post-mortem. These tests and metrics are how we validate the guarantees the MCP contract promises, not optional extras.
Roll out integrations incrementally and bake governance into connector policy from day one. Route a small percentage of sessions through the new connector, backfill context objects when needed, and honor legacy idempotency keys for backward compatibility so agents can fail over gracefully. Enforce field-level encryption and schema tagging in the connector pipeline to allow policy agents to redact or truncate sensitive attributes before materialization. Taking this approach, we can implement robust agent client integrations that make MCP primitives—leases, checkpoints, and semantic annotation—reliable and observable in production, and prepare us to map these patterns into concrete API examples and storage schemas next.
Secure, test, and monitor agents
Building on this foundation, the first thing to accept is that securing, testing, and monitoring agent behavior is an operational discipline as much as an engineering one. We treat the Model Context Protocol as the source of truth for agent state, so permissions, telemetry, and validation must live alongside createContext, acquireLease, and checkpoint operations. If you fail to bake governance into those primitives, you get brittle agents that leak sensitive data, produce nondeterministic failures, or generate untraceable side effects. In the paragraphs that follow, we’ll turn high-level MCP concepts into concrete controls and test strategies you can apply today.
Start by hardening access around lease and checkpoint endpoints because those are the mutation surface for context objects. Require strong authentication (mTLS or short-lived OAuth tokens) and bind lease tokens to connector identities so every mutating call carries an auditable owner. Enforce attribute-level ACLs in the MCP metadata store and apply field-level encryption for high-sensitivity attributes while keeping searchable embeddings policy-tagged and segregated. By coupling authorization checks to the same API semantics agents already use, you minimize accidental privilege escalation and make audit trails actionable during post-mortems.
How do you validate agent correctness before production traffic touches real users? Build layered tests that exercise deterministic invariants: unit tests for idempotent createContext/checkpoint semantics, integration tests that spin up a transient vector index and object store, and concurrency fuzz tests that simulate lease contention. Include replay scenarios that force checkpoint rollbacks and verify no duplicate external side effects. Automate these tests in CI with deterministic seeds and fixture data so race conditions reproduce reliably; failing fast on lease conflicts or stale-version errors prevents subtle runtime surprises.
Observability should answer the practical questions you’ll need in an incident: which agent owned the lease, which checkpoint produced the side effect, and what embeddings were visible to retrievers at time T. Instrument structured logs for lease lifecycle events, emit traces for the full checkpoint path, and expose metrics for lease acquisition latency, checkpoint commit time, query hit rate, and orphaned-lease counts. Tag traces with session IDs and context-object identifiers so you can reconstruct behavior without pulling PII into logs; link immutable audit records to your tracer for forensic replay.
Testing must include privacy and policy checks as first-class assertions. Implement automated redaction tests that run policy agents against checkpoints and context objects to confirm sensitive fields are removed or encrypted before materialization into prompts. Create synthetic PII injection tests to validate field-level encryption and redaction pipelines, and fail the CI build when leakage thresholds are exceeded. These privacy tests pair naturally with MCP’s semantic annotations: use schema tags to drive policy decisions rather than brittle string-matching.
Run chaos and resilience experiments that target lease expiry, vector-db partitioning, and slow checkpoint writers. Create fault-injection jobs that kill connector instances mid-checkpoint and assert that idempotency keys prevent duplicate side effects on retry. Measure system behavior under eventual consistency by stressing the semantic plane separately from the metadata plane—this reveals tradeoffs between throughput and coordination you already considered in design. Use background reconciliation jobs to surface divergence and automatically reconcile embeddings or metadata when transient failures occur.
Finally, operationalize monitoring into SLOs and runbooks tied to the MCP primitives so your on-call rotation has clear remediation steps. Define SLOs for checkpoint latency and acceptable lease contention rates, create alerts for orphaned leases and high rollback frequency, and document replay procedures that use immutable checkpoints to reconstruct or rollback workflows. By treating security, testing, and monitoring as integrated features of the protocol—not add-ons—you make agents predictable, auditable, and safe to operate at scale, and prepare the system for the next phase of incremental rollout and observability improvements.



