Recognize failure symptoms
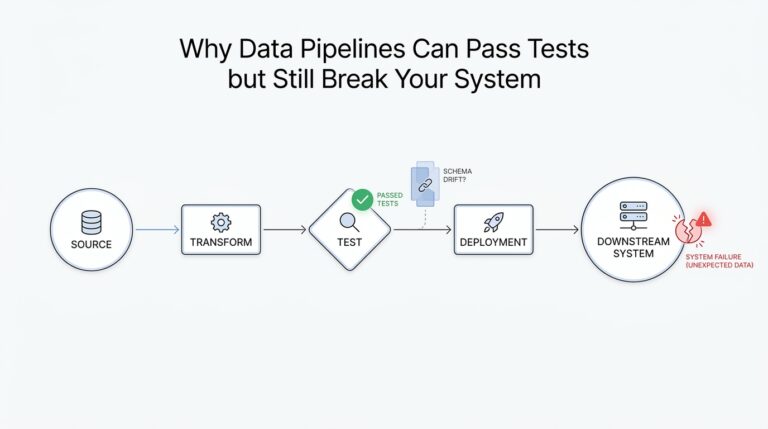
Building on this foundation, the first thing we do is learn to spot early-warning signs when a small change breaks a machine learning pipeline. A single failing test or one bad batch can be the visible tip of deeper issues like data drift or dependency changes, so we prioritize symptoms that reliably indicate systemic problems. How do you tell a harmless blip from an actual pipeline break? We look for repeatable anomalies across data, model, and infrastructure layers and treat correlated signals as higher priority.
Start by separating symptoms into three classes: data-layer, model-layer, and infrastructure-layer signals. Data drift—changes in input feature distributions or label proportions over time—means your training and serving distributions diverge; define data drift as any statistically significant shift in the joint or marginal distributions of inputs or labels. Model regression refers to degradation in predictive performance relative to a baseline; define model regression as a sustained drop in evaluation metrics that is not explained by natural variance. Infrastructure symptoms include job failures, increased latency, or resource exhaustion that prevent the pipeline from completing.
Data-layer signals are the most common and the easiest to detect automatically. Watch for schema changes (new/missing columns), unexpected null rates, feature-value ranges outside production norms, and sampling-rate changes that alter class balance. For example, a front-end change that stops sending a user feature will silently skew downstream predictions; detect that by asserting column sets and validating distributions, e.g.,
expected = {"user_id","age","country","feature_x"}
assert set(df.columns).issuperset(expected)
# quick distribution check
if (df['age'].min() < 0) or (df['age'].max() > 120):
raise ValueError("Age distribution out of bounds")
These programmatic checks plus periodic statistical tests (KS test, PSI, or simpler quantile checks) give you an early alarm for data drift and ingestion regressions. Store short-term snapshots and compare the current batch to the training snapshot to avoid chasing natural seasonal shifts.
Model-layer symptoms reveal when the learned function no longer maps inputs to the expected outputs. Track your core metrics (accuracy, AUC, precision/recall, calibration error) per cohort and per version; a sudden drop on a single cohort often points to upstream feature changes. Model inference anomalies—large shifts in prediction distributions or increases in prediction entropy—often indicate feature permutations or normalization errors introduced by a code change. Implement quick smoke tests in CI that load the production model, run a canonical test set, and fail the build when regression exceeds a small predefined delta.
Infrastructure signals tell you the pipeline is broken even if data and model look fine. Look for failing jobs, OOM (out-of-memory) errors, timeouts, or sudden increases in retry rates from your orchestration tool. Dependency or environment changes (for example, a minor library upgrade that alters numerical semantics) can silently change outputs; pin runtime environments and use reproducible containers. When you see flaky task restarts or delayed downstream triggers, prioritize stability checks—replay the same input through the isolated preprocessing and inference steps locally or in a sandbox to reproduce the failure.
Triage by isolation and reproducibility: reproduce the failing run with identical artifacts, compare inputs to the last-known-good snapshot, and run unit-level asserts across preprocessing, feature store reads, and model inference. Use canary runs on a small percentage of traffic, fail-fast assertions in preprocessing, and guardrails (schema enforcement, range checks, and simple sanity asserts) that stop bad data from flowing downstream. When possible, automate rollback to the last passing model or container while you debug, and add a postmortem note that maps the symptom to its root cause so future detection improves.
Taken together, these detection patterns let you move from “something broke” to “here’s where to look” quickly. In the next section we’ll use a concrete incident—where a minor normalization change caused both data drift and model regression—to show the exact debug steps and code-level fixes we apply in practice.
Inspect recent code and configs
Building on this foundation, start by treating recent commits and configuration changes as primary suspects when a machine learning pipeline regresses. The fastest wins come from comparing the last-known-good run to the failing run: commit diffs, config updates, and environment changes often reveal one-line regressions that cascade into data drift or model regression. Front-load your inspection on version control and deployed configuration because those artifacts map directly to code, dependencies, and runtime behavior you can reproduce. How do you know which recent change caused the regression? We answer that by narrowing scope with targeted diffs and artifact comparison.
First, interrogate version control history and PR metadata to short-list candidate changes. Start with dated queries like git log –since=‘3 days’ –pretty=oneline –name-only and review pull request descriptions and CI status for each merge; if you need a surgical approach, run git bisect to find the exact commit that introduced the failure. Pay attention to changed files in preprocessing, feature-extraction, deployment manifests, and any serialization code—the smallest change in a normalization function or column reorder is a common root cause in a machine learning pipeline. Check commit authorship and linked issue trackers to see whether a config tweak, hotfix, or dependency upgrade accompanied the code change.
Next, compare deployed configuration to repository configuration to catch drift between source and runtime. Inspect runtime environment variables, feature-flag values, and configuration stores (ConfigMaps, AWS Parameter Store, HashiCorp Vault) and diff them against the repo version-controlled configuration; infrastructure-as-code (IaC) like Terraform or CloudFormation should be audited for recent changes because they can silently alter networking, storage, or resource limits. For Kubernetes, for example, run kubectl get configmap -n prod my-config -o yaml and compare with the file in git—mismatched defaults, a flipped boolean, or a missing key often causes silent downstream failures. Treat configuration as code: the deployed config is just as authoritative as the code that references it.
Dependency and image changes are another high-leverage area to inspect. Look at lockfiles, dependency diffs, and container image digests in the recent builds—semantic-minor upgrades can change numeric precision, default behavior, or serialization order. Run pip freeze or npm ls on the build artifact and compare to the last-good artifact; inspect your CI artifact registry for image digests rather than tags (docker images –digests) to ensure you’re reproducing the exact runtime. If a dependency update is implicated, recreate the environment using the historical lockfile and run the same smoke tests to confirm whether the dependency change reproduces the regression.
Focus on preprocessing parity and artifact metadata because training-serving skew is a frequent culprit. Confirm that the feature order, missing-value strategy, and normalization parameters saved with the model match the serving code: check model.metadata for feature_order and scaler parameters, and run a small canonical input through both training and serving preprocessing to compare outputs. Serialization mismatches—changing from JSON to msgpack, or modifying a schema—can silently permute fields and produce high-entropy predictions; validate schema evolution by replaying serialized examples through both deserializers. When you find a mismatch, you’ll often see the exact symptom described earlier: a shifted prediction distribution or cohort-specific regression.
Finally, audit CI/CD runs, artifact storage, and deployment logs to connect code changes to failing jobs. Reproduce the failing job locally or in a sandbox using the same artifact digest and environment variables, capture logs, and compare diagnostics like memory usage or feature-value histograms between runs. If smoke tests or canonical test-set evaluations fail only with the deployed artifact, the problem is in build-time packaging or deployment configuration rather than model logic. Record the exact artifact hashes and pipeline steps so you can roll back cleanly while debugging.
Taking these inspection steps in sequence—VCS diffs, runtime configuration comparison, dependency/image verification, preprocessing parity checks, and CI/CD artifact replay—lets us move from symptom to a small, actionable set of suspects. We’ll use that narrowed set in the next section to perform targeted debugging and code-level fixes that restore parity and stop the regression from reoccurring.
Check data and schema changes
Building on this foundation, the fastest route to root cause is to treat data drift and schema changes as first-order suspects and verify them immediately. When a pipeline regression appears, ask: How do you quickly verify whether data drift or a silent schema change caused the regression? Start with small, targeted comparisons between the failing batch and the last-known-good snapshot—column presence, dtypes, null rates, and basic distributional summaries will catch the majority of problems before you dive into model-level debugging. Front-load these checks into your incident playbook so you and your team run the same checklist every time.
Begin with deterministic assertions that fail fast and provide actionable diagnostics. Validate column sets and types, but also capture per-column null-rate deltas and a few quantiles so you can see not just that a column exists but that its values are plausible. A compact sanity check might look like this:
expected = ["user_id","age","country","feature_x"]
assert set(df.columns).issuperset(expected)
meta = {c: str(df[c].dtype) for c in expected}
# record meta and null rates to your incident log
Collecting this metadata lets you quickly separate a schema change from true data drift—schema changes are structural (missing columns, renamed fields, dtype switches), whereas data drift is statistical (shift in distribution, class balance, or feature ranges). Implementing schema enforcement at the ingestion edge prevents many regressions: reject or quarantine batches with structural mismatches, emit a high-priority alert, and capture a reproducible sample for offline debugging. Decide whether enforcement should be strict (fail ingestion) or advisory (route to quarantine) based on business risk and recovery SLAs.
Consider schema evolution practices when you need to change production data contracts. Field renames, type loosening, and added optional fields are common sources of silent breakage; treat these as migrations, not ad-hoc edits. Version your schemas in your feature store or data lake, store migration scripts as part of the same PR that touches upstream code, and keep model metadata that records feature order and normalization parameters. That way you can replay a serving pipeline using the exact training-time schema and scaler to reproduce a regression deterministically.
Use concrete examples to illustrate how these tactics speed debugging. In one incident we saw a sharp increase in prediction entropy after a UI rollout; schema checks revealed the frontend stopped sending feature_x and began sending feature_x_id as an integer, which deserialized into a new column and shifted downstream column order. Because we had both ingestion-level schema enforcement and model.metadata.feature_order persisted with the artifact, we reproduced the failed prediction locally within minutes, rolled the bad change back, and pushed a migration that preserved backwards compatibility.
Finally, automate the guardrails you want to see during incidents: automated schema diffs in CI for any PR that touches ingestion, nightly jobs that compare training snapshots against production samples, and canary deployments that validate both data validation metrics and model smoke tests before full rollout. These controls let you catch schema changes and data drift before they cascade into model regression or end-user impact. Taking this approach makes triage faster and gives you deterministic paths for rollback or migration while you prepare permanent fixes and the code-level changes we’ll walk through next.
Validate dependencies and environments
Building on this foundation, the first thing we check when a pipeline breaks is whether a dependency or runtime environment silently changed. Dependencies and environments are part of your runtime contract: a library upgrade, a different BLAS build, or an altered container image can change numerical results or serialization order and cause model regression. How do you know a library upgrade or runtime drift caused the failure? We treat reproducible environments as a debugging first-class citizen and capture the exact runtime metadata alongside the failing run.
Start by treating the deployed artifact as the source of truth and compare it to the last-known-good artifact. Persist lockfiles, container image digests, and a small software bill-of-materials (SBOM) with every build so you can deterministically re-create the environment. If you use Python, include the pip-compile or poetry lockfile in the build artifact; if you package as a container, record the image digest rather than the tag. These immutable references let you recreate the exact dependency graph and avoid chasing transient tag-based differences.
Reproduce the environment locally or in a sandbox using the same artifact digests and lockfiles, then run the same smoke tests used in CI. Capture simple commands as part of your incident log so teammates can reproduce the run: for Python, record pip freeze > runtime-requirements.txt and for containers inspect the digest:
pip freeze > runtime-requirements.txt
docker inspect --format='{{index .RepoDigests 0}}' my-image:latest
Run your canonical test set against that artifact; if the failing metric reproduces, you’ve isolated the problem to dependency or packaging changes rather than data drift or model code.
Understand common dependency failure modes so you can prioritize fixes. Minor numeric libraries (numpy, scipy, BLAS/MKL) often introduce subtle numerical differences that shift evaluation metrics; serialization or deserialization library changes can reorder maps or change default types; and transitive upgrades can alter behavior even when the direct dependency is pinned. Pinning every package to an exact version reduces ambiguity, but it increases maintenance cost; use semver-aware lockfiles in conjunction with scheduled dependency updates and automated tests to balance stability and security.
CI/CD should enforce reproducible builds and run fast regression checks against any dependency update before merge. Build artifacts with their lockfile and SBOM, publish immutable images with digest tags, and include a smoke test stage that loads the production model and runs a canonical input set. If a PR upgrades a dependency, fail the merge if the smoke test delta exceeds a small threshold; that prevents a dependency change from slipping into production without a correctness signal.
Don’t forget runtime environment differences beyond package versions: environment variables, hardware drivers, and native libraries matter. GPU driver mismatches, different MKL/OpenBLAS builds, or changed OMP_NUM_THREADS can materially change latency and numeric reproducibility. Capture these details in your runtime metadata (kernel, glibc, driver versions, OMP settings) and replay them in a sandbox when reproducing the failure.
Operationalize this with telemetry and guardrails so you can detect dependency/environment drift before it impacts users. Emit artifact digests and runtime metadata with every job, run dependency-diff checks in CI, and gate rollouts with canary deployments that validate both data validation metrics and model smoke tests. When you do hit a regression, having immutable artifacts and recorded environment snapshots reduces mean-time-to-resolution and gives you a safe rollback point while you perform targeted debugging in the following section.
Reproduce locally and isolate
Building on this foundation, the fastest way to stop a regression is to reproduce the failing run deterministically on a machine you control. If you cannot reproduce the failure locally, you cannot reliably debug, isolate, or test fixes; reproduction is the gating criterion for meaningful root-cause analysis. How do you reproduce the failure locally and isolate the fault? We start by collecting the exact artifacts and runtime metadata from the failing job—model artifact digest, lockfile or SBOM, container image digest, environment variables, and a representative sample of the failing input batch.
The next step is reconstructing the runtime contract precisely. Recreate the container or virtualenv using the recorded image digest or lockfile (for Python use the same pip-compile/poetry lockfile and run pip install -r runtime-requirements.txt), and mirror environment variables like OMP_NUM_THREADS, CUDA_VISIBLE_DEVICES, and driver versions where possible. Run the same pipeline steps in the same order you captured in production: ingestion → preprocessing → feature extraction → inference → postprocessing. When you match artifact digests and environment settings, any numeric or serialization mismatch that caused the regression becomes reproducible and therefore isolatable.
Isolate components by narrowing scope to the smallest unit that still reproduces the symptom. Start by replaying the raw failing sample through preprocessing only, then compare intermediate outputs—column lists, dtypes, null rates, quantiles, and hashed signatures—against the last-known-good run. If preprocessing outputs match, move to feature transforms and then to inference; if they diverge, you’ve located the layer where parity broke. Use deterministic seeds for random transforms, fix thread and BLAS settings, and disable non-deterministic acceleration layers so that stochastic elements do not obscure reproducibility.
Make your debugging evidence-driven with diffable artifacts. Persist and diff serialized intermediate artifacts (parquet, msgpack, or a compact protobuf) rather than eyeballing logs. Compute compact checksums or column-level hashes and compare histograms and summary deltas; a shifted quantile, a permuted feature order, or a dtype promotion often explains sudden entropy increases in predictions. When you find a structural mismatch—renamed field, new column, or changed serialization format—replay both deserializers locally to confirm how the pipeline interprets the same bytes and to reproduce the exact failure mode.
When external services or large datasets prevent full local replay, create a minimal reproducible example by sanitizing and shrinking the failing batch to the smallest sample that still triggers the regression. Mock downstream dependencies (feature store reads, external APIs) using recorded responses or lightweight in-memory stores so you can run fast iterations. Use git bisect to narrow the offending commit if you suspect a code change, and run the canonical smoke tests used in CI against the reproduced artifact to confirm whether the fault is in code, packaging, or configuration.
Finally, instrument your local reproduction run with the same assertions and telemetry you expect in production. Add temporary asserts that check feature order, scaler parameters, and prediction distribution deltas; these guards both help you isolate the root cause and form the basis of automated regression checks. Once you can consistently reproduce and isolate the failure locally, you can craft a targeted fix, validate it against the canonical test set, and prepare a safe rollback or canary—all while keeping a clean, reproducible record that speeds future incident response and reduces mean-time-to-resolution.
Fix, test, and prevent regression
Building on this foundation, the fastest path from discovery to durable recovery is to fix the immediate failure, validate the fix with reproducible tests, and then harden the pipeline so the same regression cannot silently return. When a regression hits a machine learning pipeline, you need targeted fixes that are small, testable, and reversible; broad one-off changes increase blast radius and slow recovery. We focus first on localized corrective code or config changes that restore parity with the last-known-good run, then expand validation to prevent recurrence. How do you ensure a fix doesn’t reintroduce the regression?
Start by codifying the minimal repro and the corrective change so you can run deterministic smoke tests locally and in CI. Reproduce the failing batch through the exact artifact digest and environment snapshot you captured earlier, apply the proposed fix in a feature branch, and run the same preprocessing → feature-extract → inference steps to confirm the symptom disappears. Keep your fix atomic: a one-line normalization correction, a schema mapping, or a configuration toggle that you can roll back quickly if needed. Recording the artifact digest and the passing test output in the incident log makes rollback decisions and postmortems straightforward.
Complement manual verification with automated regression tests that capture the failing behavior and assert acceptable deltas against a canonical baseline. Convert the failing sample into a unit-level test that asserts feature order, dtype, null rates, and model scores within a narrow tolerance. For example, a pytest-style regression check might look like this:
def test_normalization_regression(canonical_sample, model_artifact):
out = run_pipeline(canonical_sample, model_artifact)
assert out['prediction'].mean() == pytest.approx(0.42, rel=0.01)
assert out['feature_x'].min() >= 0
This test captures the exact numeric behavior you care about and prevents a future change from silently drifting model outputs. Add similar checks for serialization parity and column ordering when your earlier inspection showed those as likely root causes.
Integrate those regression tests into CI and gate merges with a smoke test stage that runs the canonical suite on the produced artifact. CI should fail merges that introduce metric regressions beyond a narrow threshold or break deserialization parity; treat dependency upgrades or config changes as first-class test triggers. Use an isolated canary rollout for the actual deployment: route a small percentage of production traffic to the updated artifact and validate both data validation metrics and model performance in real time before full rollout. Canary deployments act as a safety net: they let you observe how the pipeline behaves under real traffic while keeping the blast radius minimal.
Prevention requires turning the temporary tests you wrote into durable guardrails. Promote incident-specific checks into the canonical regression suite, add schema and distribution assertions to ingestion, and record model.metadata that includes feature_order and scaler parameters so serving and training remain aligned. We should also schedule dependency-diff checks and smoke tests whenever lockfiles or image digests change, and fail the CI pipeline when numerical or API semantics shift. Monitoring matters too: emit per-deployment baselines, alert on prediction-distribution drift, and link failing alerts back to the precise regression test that would catch the issue in CI.
Finally, treat the postmortem as actionable code: translate root-cause notes into concrete artifacts (tests, schema migrations, configuration constraints, or runbook steps) and attach them to the PR that implements the fix. That practice closes the loop—your next incident responder can reproduce the failure, run the tests in CI, and rely on canary validation to prevent reintroduction of the same regression. By making fixes reproducible, tests authoritative, and rollouts incremental, we reduce mean-time-to-resolution and stop small changes from becoming recurring pipeline regressions.