Set clear mentoring goals
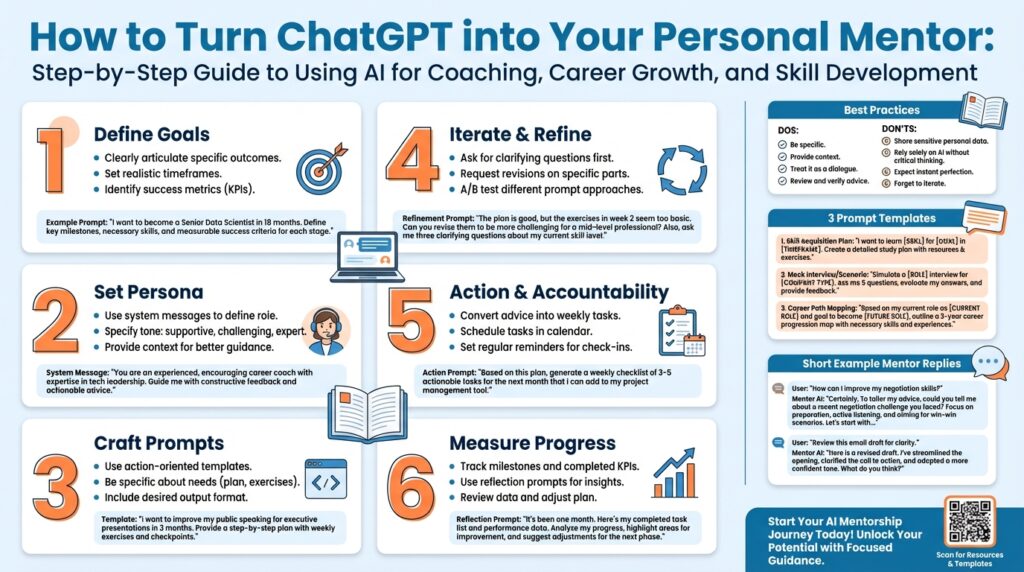
If you want to turn ChatGPT into an ongoing learning partner, start by defining precise mentoring goals that map to real work outcomes. Treat the model as a ChatGPT mentor and an engine for AI coaching: clear goals tell it when to push back, when to provide examples, and when to escalate to hands-on exercises. What specific skills do you want to level up in the next 3–6 months? Framing goals up front saves time and prevents aimless conversations that don’t translate into measurable progress.
Adopt a goal template that makes expectations explicit and testable. Use an adapted SMART structure: make goals Specific about the technology and deliverable, Measurable with quantitative milestones, Achievable given your calendar, Relevant to your role, and Time-bound with checkpoints. For example, instead of saying “get better at observability,” define “integrate distributed tracing into three microservices, create a Grafana dashboard with three key SLOs, and reduce mean time to detect (MTTD) by 40% within 12 weeks.” This clarity helps you evaluate progress and helps the ChatGPT mentor generate concrete tasks and code examples.
Translate goals into prompt-ready artifacts so you can reuse them in sessions. Provide the model with a short goal statement, constraints, success criteria, and existing artifacts to inspect. For instance, paste: Goal: Instrument payments service with OpenTelemetry; Constraint: no schema changes; Success criteria: traces appear in Jaeger and 90% of requests have trace IDs in logs; Timeline: two sprints. Then ask the model to produce a prioritized sprint plan, code snippets for instrumentation, and a list of test cases. This pattern—goal, constraints, success criteria, timeline—lets your AI coaching session immediately generate actionable work items.
Break large goals into micro-goals and schedule iterative reviews to keep momentum. Define weekly or biweekly checkpoints where you and the model review PRs, run retrospective prompts, and adjust success criteria based on real feedback. We should treat those checkpoints like lightweight sprints: review what shipped, identify blockers, and rewrite the next iteration of mentoring goals accordingly. That cadence prevents scope creep and makes the coaching relationship adaptive rather than static.
Building on this foundation, anchor each goal to artifacts and metrics you already collect in your workflow. For example, if your objective is skill development in container orchestration, tie it to a concrete artifact: “Deploy a canary release pipeline using Argo CD for service X, with automated rollback on increased error rate, measured by a 30% drop in failed deployments over 8 weeks.” Define terms like MTTD or canary release on first use so the model and future readers align. When goals are tied to pull requests, dashboards, and CI jobs, the ChatGPT mentor can produce PR comment templates, test plans, and monitoring queries that integrate directly into your engineering process.
Finally, make the goals discoverable and repeatable so the mentoring relationship scales. Store goal templates, success criteria, and session transcripts in a shared doc or repo so you can rerun, fork, or hand off mentoring plans. Ask the model to generate a weekly prompt it should start with, such as: Give me a 30-minute checklist to advance Goal A this week, surface one blocker, and propose one coding exercise. That way, we convert ad-hoc AI coaching into a reliable workflow that you can slot into standups, pairing sessions, or PR reviews. Taking this approach ensures your mentoring goals drive concrete outcomes rather than abstract intentions, and prepares us to convert those goals into prompt patterns and session templates in the next section.
Provide background and context
Think of a ChatGPT mentor as a continuously available, context-aware collaborator you can query for technical advice, learning paths, and code-level feedback. In practice, treating ChatGPT as your personal mentor and as an AI coach means you can accelerate skill development and career growth by converting real work artifacts—PRs, CI logs, telemetry, design docs—into teachable moments. How do you trust the guidance when the stakes are high? We approach that by combining clear goals, verifiable artifacts, and repeatable prompt templates so the model’s suggestions map to measurable outcomes rather than vague advice.
Understanding what these models can and cannot do is essential before you lean on them for mentorship. Large language models (LLMs) like ChatGPT excel at synthesizing patterns from text, generating example code, proposing debugging strategies, and producing learning plans, but they can hallucinate facts, lack execution context, and may not reflect the absolute latest ecosystem changes. Therefore, we always treat model outputs as draftable artifacts: safe to iterate on, but subject to verification against tests, static analysis, and runtime telemetry. Use the model to generate candidate solutions and hypotheses, then validate them with CI, local runs, and peer review.
Prepare your environment and artifacts to get consistent, high-value responses from your AI coach. Start each session with a short system-style context (role, constraints, and what you’ll share) and paste minimal reproducible artifacts rather than entire repositories; chunk larger files to respect the model’s context window. For example, open a session with a compact starter prompt like:
System: You are my senior backend mentor. Constraint: do not expose secrets. Artifact: service A’s instrumentation diff + failing test output. Goal: reduce error rate by 20% this sprint.
This pattern helps the model prioritize remediation steps and produce focused code snippets, test cases, and CI adjustments you can run immediately.
Apply concrete workflow patterns that map directly to engineering practices you already use. Use the model to draft PR descriptions and review comments, to convert flaky test logs into triage steps, or to author telemetry queries and alert runbooks. For instance, paste a failing test trace and ask, “Generate three likely root causes and one reproducible test case to isolate each cause.” The model will often provide plausible hypotheses and test scaffolding that you can run, iterate on, and then feed back results—creating a tight experiment loop that mimics pairing with a senior engineer.
Address privacy, security, and governance up front so mentorship scales safely across teams. Treat personally identifiable information (PII) and secrets as out-of-band artifacts; redact API keys, credentials, and customer data before sharing. If you operate in an enterprise setting, consider private model deployments or vendor features that provide data retention controls and audit logs. We recommend maintaining a versioned repo of approved prompt templates and sanitized session transcripts so you can audit decisions and reproduce advice during performance reviews or incident retros.
Define how you’ll measure progress and what early success looks like to keep the mentoring relationship productive. Early wins typically include executable artifacts: a passing test suite generated from a model suggestion, a merged PR that improved observability, or a scheduled playbook for on-call runbooks. Track quantitative signals—time-to-merge, test coverage on targeted modules, mean time to detect (MTTD), or the number of independent coding exercises completed—and combine them with qualitative feedback from code reviews and interviews. Building on this foundation, we’ll convert those measurable goals into concrete prompt patterns and session templates that let you run repeatable AI coaching workflows in your day-to-day engineering practice.
Write high-impact coaching prompts
High-impact coaching prompts are the difference between scattered advice and a repeatable mentorship workflow you can rely on. If you want useful, actionable output from your ChatGPT mentor and to make AI coaching drive measurable progress, start each prompt by stating role, context, and success criteria in plain terms. Front-loading those elements tells the model how to prioritize suggestions, which lets us move from vague guidance to verifiable artifacts you can run, test, and merge.
Building on the goal templates we described earlier, design every prompt around five explicit parts: role, artifact, constraints, task, and acceptance criteria. Tell the model who it should behave like (senior backend mentor, SRE reviewer, career coach), provide the minimum reproducible artifact it needs to inspect, name constraints it must respect (no schema changes, no external network calls), and end with specific acceptance criteria tied to measurable outcomes. This structure reduces hallucination risk and gives you deterministic hooks for follow-up prompts.
Put that structure into a reusable prompt template so you can paste it into sessions without rethinking format. For example:
System: You are my senior backend mentor. Role: diagnose and fix regression. Artifact: failing test output + instrumentation traces. Constraints: no infra changes, no secrets. Task: list 3 likely root causes, one minimal reproducer, and a step-by-step remediation with code snippets. Acceptance: reproduce failure locally using provided steps and a proposed CI test that fails before fix and passes after.
This template is compact but precise: we name the role, deliverables, and how we’ll validate success. Keep variations of this template for different purposes—career coaching, architecture reviews, and hands-on debugging—so you reuse proven patterns instead of rewriting prompts each time.
Use concrete, scenario-driven prompts when you want code-level guidance. For example, if you’re instrumenting a payments microservice, paste the relevant snippet and ask: “Produce an OpenTelemetry instrumentation diff that adds trace propagation, include unit tests for trace headers, and provide a Grafana query to verify 90% trace coverage.” That question-driven style—How do you add deterministic trace IDs across asynchronous jobs?—forces the model to return working code, test scaffolding, and observability checks rather than vague recommendations. Ask for edge-case tests and failure-mode examples so you can verify fixes in CI.
Adopt iterative prompting tactics to drive depth without overwhelming the model. Start broad (hypothesize why a pipeline is failing), then narrow into one hypothesis and ask for a reproducible test case and a pull-request-ready change. Request explicit output formats: a changelog-style PR description, a 5-step rollback plan, or a one-paragraph summary for stakeholders. When you want critique rather than fixes, ask the model to play devil’s advocate: produce three counterarguments to the design and suggest mitigations. Parallel prompts like these speed decision-making and keep the coaching workflow tightly coupled to concrete artifacts.
Finally, lock prompts to validation steps that mirror your engineering process so results are auditable and repeatable. Always ask for acceptance tests, expected log lines, sample telemetry queries, and a one-minute summary for reviewers—this lets us run the model’s suggestions through CI, static analysis, and peer review before we merge. As you iterate, store the most effective prompt templates and checkpoints in a repo or shared doc so your next session can start from a known-good state and we can automate recurring coaching prompts into your cadence.
Build a personalized learning roadmap
Building on our goal-setting work, start by translating high-level objectives into a compact personalized learning plan you can execute weekly. Front-load each plan with a short goal statement, measurable success criteria, and the artifacts you’ll use for validation so your ChatGPT mentor can produce actionable tasks rather than abstract advice. How do you turn broad career goals into a repeatable schedule that maps to pull requests, tests, and telemetry? Treat this plan as a contract: role, constraints, deliverables, and a sprint-length timeline.
Begin the roadmap by defining four core sections per milestone: objective, artifacts, acceptance criteria, and cadence. The objective ties directly to a work outcome we care about—deploy a canary rollout, reduce MTTD by X, or add distributed tracing across services—while artifacts are the minimal reproducible inputs you’ll paste into sessions. Acceptance criteria should be testable (unit or integration tests, dashboard queries, or PR checks), and cadence defines how often you’ll iterate—one week for focused experiments, two weeks for feature-level work. This structure keeps the plan measurable and verifiable.
Break milestones into micro-goals that you can complete in a pairing session or an evening of focused work, and commit each micro-goal to a calendar slot. For example, split an observability objective into: add OpenTelemetry SDK to service A, propagate trace IDs through async queues, and author a Grafana panel with an SLO. Each micro-goal has one acceptance test (a CI job, a passing unit test, or a trace that surfaces in Jaeger) so you can ask the ChatGPT mentor to produce the exact code diff, test scaffold, and monitoring query you’ll run.
Use the model to auto-generate a sprint plan from a short prompt so you don’t manually craft schedules every time. Paste a compact prompt like:
System: You are my senior backend mentor. Goal: reduce payment-service latency by 30% in 8 weeks. Artifact: current latency P50/P95, Dockerfile, metrics dashboard screenshot. Constraints: no database schema changes. Task: create a 4-sprint roadmap with weekly deliverables, one PR template per sprint, and acceptance tests. Return tasks prioritized with estimated hours.
This prompt pattern produces a prioritized backlog, estimated effort, and PR-ready descriptions that slot into your existing workflow. Request explicit output formats—GANTT-like sprint list, checklist-style PR description, or a one-paragraph summary for stakeholders—so you can paste results directly into issues or standup notes.
Measure progress with instrumentation and CI gates rather than gut feel; make telemetry and tests the single source of truth for success. Ask ChatGPT to generate monitoring queries and expected log lines alongside code changes, then wire those into your CI pipeline as acceptance tests. When the model proposes fixes, validate them with a failing-then-passing CI job and keep those logs as artifacts for the next coaching session; this closes the loop between AI coaching and engineering verification.
Plan for regular retrospectives and dynamic replanning: schedule short review prompts at the end of each sprint to surface blockers, rewrite acceptance criteria, and rebalance priorities based on real data. We should store prompt templates and sanitized session transcripts in a versioned repo so you can fork successful roadmaps, hand them off, or replicate them across teammates. Over time, the repo becomes a library of proven mini-sprints that scale mentorship across projects.
Finally, be realistic about time budgets and blend active experimentation with curated study. Block specific pairing windows with the ChatGPT mentor, reserve one session for hands-on coding and CI runs, and another for reading or guided exercises generated by the model. This mixed cadence—practice, validate, reflect—gives you a repeatable learning roadmap that turns AI coaching into measurable skill growth and deliverable outcomes, and prepares us to convert those roadmaps into reusable prompts and session templates in the next section.
Use role-play and mock interviews
Building on the goal-driven coaching framework we described earlier, an effective way to practice hard technical conversations is to run structured role-play and mock interviews with your ChatGPT mentor. These simulated sessions put you into realistic pressure scenarios—system design whiteboards, coding rounds, and behavioral debriefs—so you can rehearse answers, timing, and trade-off communication. How do you run an effective mock interview with ChatGPT to make each minute count? Start by treating the session as a measurable experiment: a clear prompt-driven scenario, a timer, and acceptance criteria you can validate after the run.
Begin each session by defining the role, constraints, and success metrics so the model behaves like the interviewer you need. State the interviewer persona (senior backend engineer, SRE on-call lead, hiring manager), paste the minimal artifact (problem statement, failing test, or architecture diagram), and set a clear acceptance test—compileable code, a gradable rubric, or a one-paragraph trade-off summary. This front-loading maps directly to the prompt template pattern we used for technical tasks earlier: role, artifact, constraints, task, and acceptance criteria. When the model knows how you’ll validate answers, it will generate targeted follow-ups and scoring guidance that make the practice actionable rather than vague.
Use short, repeatable prompt templates to run multiple rounds and to vary difficulty programmatically. For a timed coding interview, open with a compact system prompt like:
System: You are a technical interviewer focused on algorithms. Role: ask a medium-hard coding question, enforce 30-minute timebox. Artifact: allow Python or Java. Task: give partial hints at 10 and 20 minutes, provide a grading rubric (correctness, complexity, readability). Acceptance: provide failing test cases and one optimized solution.
That single prompt seeds deterministic behavior: you get an interviewer that provides incremental hints, returns failing tests you can run locally, and scores the submission against explicit criteria. Reuse and tweak this template to practice behavioral interviews or system-design rounds by swapping the role and acceptance tests.
Structure each practice like a mini-experiment: warm-up, main task, reflective feedback, and targeted drills. Start with a two-minute elevator summary to practice communication under time pressure, move into a 20–30 minute coding/design segment, and then spend 10 minutes on critique and corrective practice. Ask the model for a line-by-line code review, alternative algorithms, and one concrete follow-up exercise that closes the gap it identified. This iterative loop—attempt, validate with tests or diagrams, receive critique, and repeat—mirrors the rapid feedback cycles we use for PRs and CI, converting practice into measurable skill gains.
Demand precise, actionable feedback rather than generic praise; the value of role-play is in high-fidelity correction. Request explicit error cases, complexity analysis with Big-O notation, and suggested micro-exercises (small katas or refactors) to target weaknesses. When you want behavioral feedback, have the ChatGPT mentor score you on a rubric (clarity, empathy, decision rationale, trade-off awareness) and then role-play the interviewer pushing back on a weak answer. That kind of adversarial questioning surfaces blind spots you can transform into concrete learning tasks for the next sprint.
Make the practice scenarios realistic and relevant to your goals: simulate an on-call postmortem with real logs, a design interview focused on fault tolerance for your stack, or a coding round using the exact language and libraries you use day-to-day. For example, ask for a design prompt that requires integrating OpenTelemetry across microservices, then have the model act as an interviewing architect who asks for trade-offs around latency and schema changes. Score responses on correctness, deployability, and observability coverage—this keeps practice tightly coupled to the artifacts and success criteria in your learning roadmap.
Schedule these sessions and capture transcripts so you can iterate on them as artifacts in your learning repo. Store the prompts, the model’s feedback, and your revised answers next to the goals and acceptance tests we already track; that lets us quantify progress over time and hand off proven session templates to teammates. As we move to the next section, we’ll convert the most effective mock-interview prompts and scoring rubrics into reusable templates that slot into sprint plans and CI-friendly acceptance tests.
Track progress and stay accountable
Establishing measurable checkpoints is the single most effective way to convert advice from a ChatGPT mentor into sustained progress and real deliverables. If you want AI coaching to move the needle, you must front-load metrics and artifacts into every session so the model can produce verifiable tasks rather than vague suggestions. How do you keep the momentum between sessions? Treat each interaction as an experiment with a hypothesis, acceptance criteria, and a single artifact (PR, failing test, dashboard snapshot) that proves or disproves the hypothesis.
Building on the goal and roadmap structures we described earlier, create a lightweight progress ledger that you update at each checkpoint. Start each week with a one-line objective, a short list of acceptance tests, and the artifacts you’ll paste into the session; close the week by recording results, time spent, and whether the acceptance criteria passed. This ledger can live as a markdown file in a repo, an issue template in your tracker, or as a dedicated note in your learning repo—what matters is that you and the model read from and write to the same canonical state.
Pick a small, consistent set of metrics that align with your acceptance criteria so progress is unambiguous. Use test-level gates (failing-then-passing CI job), telemetry (P50/P95 latency, error rate, trace coverage), and work metrics (number of micro-goals completed, PR review time) as your primary signals; define each metric up front—MTTD is mean time to detect, for example—so the model and future reviewers interpret results consistently. For instance, require a PR to include one unit test, one integration test, and an observability query that verifies the change; when those three gates are green, treat the micro-goal as done.
Automate accountability by turning recurring prompt templates into session starters that the model itself can use to audit progress. Open a session with a short system prompt such as: “You are my senior mentor. Context: weekly ledger entry + failing CI logs. Task: summarize progress, surface one blocker, propose one prioritized fix, and return a PR-ready diff fragment.” That single pattern anchors the model’s output to your artifacts and produces a checklist you can paste into issues or standup notes, which keeps follow-ups deterministic and repeatable.
Integrate the model’s outputs into your existing toolchain so accountability is visible to reviewers and peers. Attach the model-generated checklist to PR descriptions, copy the proposed acceptance tests into CI, and wire Grafana or your metrics provider to the acceptance queries the model suggests. In enterprise contexts, redact secrets and store sanitized transcripts in a versioned repo for auditability; this preserves governance while letting the mentoring workflow drive real engineering change.
Keep the feedback loop tight: prefer short iterations with clear remediation paths rather than long, ambiguous goals. When a proposed fix fails in CI, paste the failing logs back to the model and ask for three hypotheses and one minimal reproducer; when it passes, record the before/after telemetry and tag the ledger entry with the change set. Over time, these pass/fail artifacts become the most persuasive evidence of growth—we can point to merged PRs, cleaner dashboards, and faster MTTD as objective indicators that mentoring generated impact.
Treat accountability as a design problem: plan the cadence, instrument the gates, and automate the prompts that bind artifacts to outcomes. By making progress auditable and repeatable—ledger entries, CI gates, telemetry queries, and session templates—you transform adhoc coaching into a reproducible engineering process. Next, we’ll convert the most effective checkpoints and session templates into reusable prompt patterns you can slot into sprint plans and CI pipelines.