Agentic AI: Definition and Overview
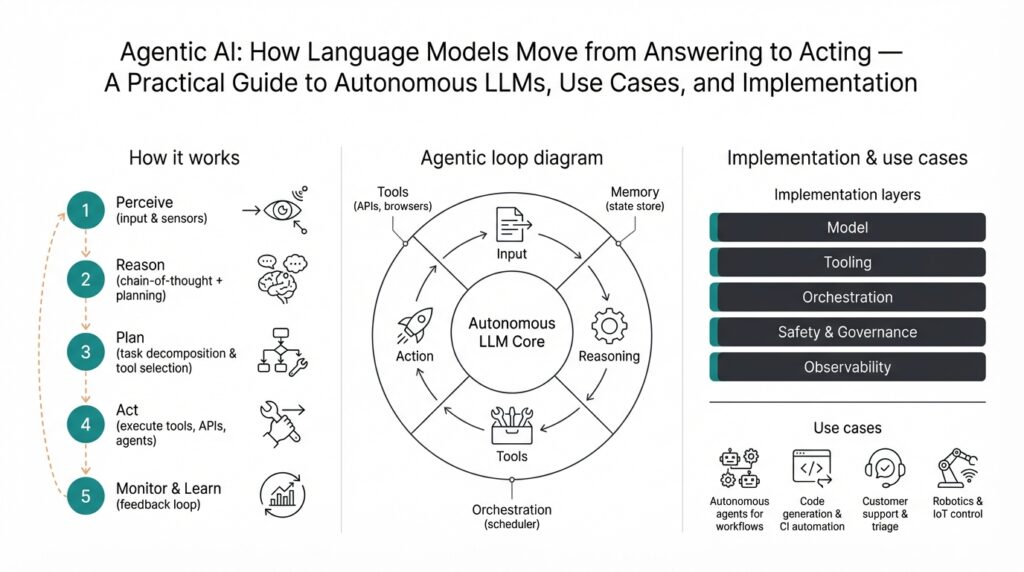
Agentic AI transforms language models from passive answer generators into goal-driven systems that take actions in the world. In practice, Agentic AI means composing an autonomous LLM with planning, state, and tool access so the model can pursue objectives over multiple steps rather than only responding to a single prompt. This shift matters because it changes the interaction model: you no longer call a stateless API and get text back—you give a goal, the system plans, executes actions (APIs, scripts, queries), observes results, and iterates until the objective is met. Agentic AI and autonomous LLMs sit at the intersection of orchestration logic, grounding data, and runtime safety controls.
At the core of these systems are four explicit components: a planner that decomposes goals into tasks, an executor that invokes tools and APIs, a memory store that preserves context across steps, and an environment adapter that mediates side effects and permissions. Each term matters: a tool is any callable interface (HTTP API, shell command, database query) and memory is structured state you can read/write (vector DB, key-value store, or event log). Architecturally, you typically implement a control loop—sense → plan → act → observe—so the agent can react to unexpected outputs and replan when an action fails. This modular separation makes testing, observability, and safety engineering tractable.
Understanding how agentic systems differ from synchronous language model usage helps decide when to adopt them. Traditional language models excel at single-turn tasks—summaries, translations, code completion—where latency and determinism matter. When should you prefer an agentic system over a synchronous API call? Choose agentic workflows for multi-step processes, long-running automation, or tasks that require external state and chaining of tools (for example, triaging an incident, updating tickets, and deploying a hotfix). If you need low-latency, highly deterministic responses with no side effects, a standard model API remains the right tool.
Concrete use cases illustrate practical trade-offs. For incident response, an agent can ingest alerts, run diagnostics (curl, kubectl), triage root cause using logs via retrieval-augmented queries, open or tag tickets, and escalate if thresholds are met—reducing mean time to resolution. In data work, autonomous LLMs can orchestrate ETL steps: detect schema drift, generate transformation SQL, validate sample outputs, and commit migrations behind feature flags. For developer productivity, an agent can run tests, propose a patch, and create a pull request while annotating reasoning and test results. Each example shows why you need persistent context, tool authorization, and structured feedback loops rather than isolated completions.
Agentic designs introduce new failure modes and safety considerations we must plan for before deployment. Goal mis-specification can lead to unintended actions, so validate objectives and constrain capabilities with action whitelists and sandboxed environments. Hallucination risk increases when the agent issues commands based on incorrect assumptions; mitigate by grounding decisions with retrieval, schema validation, and deterministic validators (unit tests, type checks). Observe compound error accumulation by building transaction-like rollback paths and idempotent actions, and ensure robust auditing so you can trace each agent decision and its triggering context.
When you implement one of these systems, focus on integration and operability: instrument every action with structured logs, expose a human-in-the-loop approval step for high-impact flows, and run agents first in simulation or dry-run mode to validate behavior against canonical scenarios. We typically roll out agentic capabilities incrementally—start with read-only tools, add constrained write access, then expand scope as confidence grows—so you can measure and tune policy, latency, and cost. Taking this concept further, we’ll next walk through a minimal agent architecture you can deploy locally, showing how to wire planning, memory, tool adapters, and safety checks into a reproducible pipeline.
Core Components: Planning, Memory, Tools
Building on this foundation, the practical heart of any agentic AI system is how planning, memory, and tools are designed to work together at runtime. If you’re converting an LLM into an autonomous system, you must treat planning, memory, and tools as first-class engineering concerns rather than afterthoughts. We’ll show concrete design patterns and actionable trade-offs you can apply immediately when you build autonomous LLMs for incident response, ETL orchestration, or developer automation. How do you balance expressiveness against safety and cost while keeping the system observable and testable?
Start with planning as the agent’s cognitive architecture: planners decompose a high-level goal into actionable tasks, prioritize them, and expose dependencies and failure modes. Choose between a lightweight prompt-based planner for short, deterministic flows and a layered planner (hierarchical task networks or tree-of-thoughts style exploration) when tasks require branching, lookahead, or conditional retries. Implement a planning output schema your executor can parse—e.g., an ordered JSON list with fields {“id”,”action”,”args”,”preconditions”,”estimated_cost”}—so you can validate plans automatically before any side effects occur. For real workloads, add a cost model that factors API costs, latency, and blast radius; that lets you prune expensive plan branches early and prefer safe, idempotent steps.
Memory is the agent’s working state and its long-term knowledge base, so design memory tiers that match temporal needs and access patterns. Use short-term context (conversation state and recent observations) stored in transient buffers for immediate reasoning, and a semantic vector store for episodic and long-term memory you’ll retrieve with embeddings. Decide retrieval strategies: exact-match for configuration or credential lookups, similarity search for past troubleshooting examples, and summarized checkpoints to avoid reloading huge contexts. How do you pick which memory store is right for your agent? Benchmark retrieval latency and relevance on representative queries, enforce TTLs and pruning policies, and version each memory snapshot so you can roll back when a corrupted entry causes hallucinations.
Tools are the agent’s actuators; implement each as a wrapped, well-typed interface that returns structured results and explicit error classes. Treat any HTTP API, shell command, or database call as a tool with a contract: input schema, output schema, idempotency guarantees, and security scope. Wrap tools so they return a canonical response object (status, stdout/stderr, structured payload, and provenance metadata) and make your executor validate responses against expected schemas before allowing plan continuation. For example, a database migration tool should return {“status”:”dry-run-passed”,”sql_hash”:”…”,”rows_affected”:0} in dry-run mode, enabling the planner to decide whether to promote the change.
Integration is where these components either create value or become brittleness sources; make the control loop explicit and observable. When an executor calls a tool, log the plan id, the memory snapshot used for retrieval, the exact prompt sent to the model, and the tool’s canonical response—this gives you deterministic traces for debugging and compliance. Build simulation harnesses that replay these traces so you can unit-test planners against synthetic tool responses and validate rollback logic without hitting production systems. Implement circuit breakers, retry policies, and compensating transactions for non-idempotent operations so that failures lead to safe, reversible states rather than cascading side effects.
For production rollouts, operationalize safety and progressive authorization: start by exposing read-only tools, then gated write capabilities with human approvals, and finally automated flows behind capability flags and canary policies. Instrument cost and latency metrics per tool call, expose audit trails for every decision the planner made, and surface confidence scores alongside low-level logs so operators can triage model-driven mistakes quickly. With these practices—well-typed planners, tiered memory, wrapped tools, explicit observability, and staged authorization—you can move from experimental prototypes to robust autonomous LLMs while keeping control over risk and operability, preparing us to wire those components into a minimal deployable architecture next.
Use Cases, Architectures, and Patterns
Building on this foundation, start by matching concrete business problems to the strengths of agentic AI and autonomous LLMs so you don’t overengineer for the wrong use case. If your workflow needs persistent context, conditional branching, and safe side effects—like automated incident remediation, multi-step data migrations, or hands-off developer CI tasks—an agentic design pays for itself in reduced human toil and faster resolution. We’ll explore practical patterns and architectures that make those wins repeatable in production without rehashing the basic control-loop components you already know.
Choose your dominant use cases before you choose an architecture; that decision drives trade-offs in complexity, latency, and governance. For high-trust, auditable workflows (finance approvals, compliance remediation), prefer a centralized orchestrator that enforces policy, human approvals, and a canonical plan schema. For throughput-oriented, loosely coupled tasks (web crawling, parallel ETL jobs), favor a decentralized fleet of lightweight worker agents that pull plans from a queue and execute sandboxed tools. How do you know which model to pick for a given problem? Prototype both with read-only tools and measure failure modes, cost, and developer velocity under representative load.
When you design the planner-executor boundary, adopt patterns that keep reasoning interpretable and actions constrained. Implement a hierarchical planner when tasks require lookahead or conditional branches: a top-level goal decomposes into subgoals, each with explicit preconditions and estimated cost. Use a strict plan schema your executor can validate automatically; for example:
{"id":"p-123","steps":[{"action":"run_diagnostics","args":{"target":"pod-7"},"preconditions":[],"estimated_cost_ms":1200}]
}
This structure lets the executor perform deterministic validation and enables rollbacks or dry-run simulations without invoking side effects.
Make memory and tool integration patterns first-class to avoid brittle behavior at runtime. Treat tools as typed contracts with idempotency guarantees and canonical response objects that include provenance and error classes; persist short-term context in a transient buffer and long-term signals in a vector store or versioned KV for episodic recall. Favor retrieval strategies tuned to the question—exact-match for credentials, similarity for prior incident reports—and surface retrieval provenance in every decision so you can trace why the agent recommended an action.
Operational resilience depends on predictable failure and mitigation patterns, not on model cleverness. Use simulation harnesses and replayable traces to unit-test planners against synthetic failures, implement circuit breakers for noisy third-party APIs, and require human approval for any non-idempotent or high-blast-radius action. For example, in incident triage an agent can autonomously collect diagnostics and propose a rollback SQL, but gate the final execution behind a human approval step and a canary rollout policy that limits impact.
Finally, deploy agentic features incrementally and instrument aggressively so you can measure impact and tune policy. Start with read-only capabilities, add constrained write operations with audit trails, and only then enable fully automated flows behind feature flags and capacity-based kill switches. Capture structured logs that link plan IDs, memory snapshots, prompts, tool responses, and outcome metrics—this traceability is what turns experimental agents into dependable automation.
Taking these use cases, architectures, and patterns together lets you choose the right balance of autonomy, safety, and cost for your organization. In the next section we’ll wire these patterns into a minimal deployable architecture so you can reproduce the examples above and run controlled experiments in your environment.
Integrating Tools, APIs, and Services
When you move from model completions to an agent that acts, the hardest engineering work is integrating the external world reliably—your agents succeed or fail based on how well you connect tools, APIs, and services. Start by treating every external interface as a first-class contract: document its input schema, expected outputs, error classes, and blast radius before wiring it into the executor. This upfront discipline prevents the nightly surprise where a provider response shape or auth change breaks an automation flow. Build adapters that make these contracts explicit so the planner never reasons against undocumented behavior.
How do you safely expose third-party APIs to an autonomous agent? We apply a layered adapter pattern: the agent calls a thin runtime adapter that performs authentication, rate-limit guarding, schema validation, and provenance stamping, and that adapter calls an SDK or HTTP client. For example, wrap a payment API call in an adapter that enforces idempotency keys, validates success codes, and returns a canonical object like {status, payload, error_type, provenance}. This isolates retries and circuit-breaker logic from the planner and gives us deterministic failure modes the planner can programmatically reason about.
Authentication and authorization must be integrated into the runtime path rather than sprinkled across prompts. Use short-lived credentials and service identities (mTLS or OAuth client credentials) scoped to the minimum required capability; never embed long-lived secrets in prompts or memory. For highly sensitive operations, add a policy gate that requires a signed authorization token from an operator or an approval microservice; the executor should test capability flags and approval state before executing any write operation. We recommend automatic rotation, token hashing in logs, and clear audit trails that link plan IDs to the credential used.
Network and API reliability matter to agentic behavior more than raw model accuracy. Add backpressure and batching for high-throughput services, and prefer asynchronous call patterns when an action takes a long time (webhooks, message queues, or background jobs) so the agent can yield and replan on completion events. Implement exponential backoff with jitter for retries, and surface deterministic retry counters and error classes to the planner. When possible, use provider dry-run endpoints (or a sandbox) during simulation and testing so the planner can validate outcomes without side effects.
Observability and provenance tie the whole integration story together; if you can’t trace why an agent acted, you can’t fix it. Log the exact prompt, the memory snapshot used, the adapter input, the raw API response, and the normalized result under a single trace ID—this enables replayable traces and deterministic simulation. Instrument latency, error rates, and cost per tool call so you can prune expensive plan branches automatically and set circuit-breaker thresholds. We also surface a confidence metric and retrieval provenance in the planner’s decision record so operators can triage model-driven mistakes quickly.
When you design for progressive rollout, integration choices drive the risk envelope. Start with read-only adapters and simulated write responses, then enable gated writes with human approvals and capability flags, and finally consider runbooks or canary policies for fully automated flows. Make every adapter testable in isolation: unit-test schema validation, run integration tests against a sandbox, and use trace replays to validate rollback and compensating transactions. Building robust adapters, scoped auth, and deterministic observability turns fragile integrations into dependable automation and sets up the agent for safe scale.
Implementing An Autonomous LLM Pipeline
Building an autonomous LLM pipeline starts with a clear dataflow: ingest the goal, produce a validated plan, execute typed tools, and persist outcomes and provenance for replay. If you’ve read the previous sections, you know the components—planner, executor, memory, adapters—but the engineering challenge is wiring them into a predictable, auditable runtime that supports incremental rollout. How do you structure the pipeline to balance autonomy and control? We’ll show pragmatic integration patterns you can implement today for agentic AI and autonomous LLMs that prioritize safety, observability, and recoverability.
Design the pipeline as a sequence of deterministic handoffs rather than opaque model calls. First, normalize inputs (webhook, CLI, or UI) into a canonical goal object and push that into a queue so the system supports retries and parallel workers. The planner consumes the goal and emits a structured plan object that your executor can parse; define a strict plan schema with fields like id, steps:[{id,action,args,preconditions,estimated_cost,rollback}] and validate it against a JSON Schema before any side effects. This separation keeps the control loop explicit: sense → plan → act → observe, enabling dry-run validation and automated cost pruning for expensive branches.
Implement the planner so its outputs are machine-verifiable, not free-form prose. For short flows use a prompt-based planner that emits a small JSON plan; for branching or lookahead, use a hierarchical planner that produces subgoals with explicit dependencies and abort conditions. Attach a lightweight cost model and confidence score to each step so the executor can decide whether to execute, delay, or request human approval. Always perform schema validation and a simulated dry-run on high-impact steps; failing fast prevents the agent from taking irreversible actions based on a hallucinated plan.
Wrap every tool behind an adapter that enforces a contract: input schema, idempotency guarantees, auth scope, and canonical response shape. The adapter should return a result object such as {status, payload, error_type, provenance, idempotency_key}, and it should support dry_run and replay modes. For example, a migration adapter can run in dry_run and return {status:"dry-run-passed",sql_hash:"...",rows_affected:0} so the planner can decide whether to promote the change. Use idempotency keys and strict retry logic with exponential backoff and circuit breakers for flaky external services.
Treat memory as layered storage tuned to access patterns and temporal needs. Keep a transient context buffer for the current control loop, store episodic recall in a vector database (semantic embeddings) for similarity searches, and archive canonical checkpoints in a versioned KV store for rollback. Enforce TTLs and retention policies, and record retrieval provenance (which snapshot and which embedding model produced the match) so you can explain why the agent chose a particular action. Benchmark retrieval latency under realistic load—slow vector lookups are a common bottleneck in autonomous LLM pipelines.
Make observability and testability first-class: attach a single trace ID to the entire goal lifecycle and log the exact prompt, memory snapshot, plan JSON, adapter inputs, raw API responses, and normalized results. Build a simulation harness that replays traces with synthetic tool responses so you can unit-test planners and verify rollback logic without hitting production systems. Capture metrics per-tool (latency, error rate, cost) and per-plan (success rate, blast radius) so you can prune expensive branches programmatically and set automatic kill-switch thresholds.
Operationalize safety with progressive authorization and feature flags. Start with read-only adapters, then add gated write access that requires signed operator tokens or human approval microservices for non-idempotent steps. Roll out new capabilities behind canary policies that limit scope by environment, user role, or cost budget; surface confidence scores alongside prompts so operators can triage interventions quickly. These controls let you increase autonomy incrementally while maintaining auditability and rollback paths.
Taking these patterns together prepares you to wire the pipeline into a minimal deployable architecture: queue-backed planners, stateless executors, versioned memory stores, and adapter layers with built-in dry-run and audit modes. In the next section we’ll map these runtime patterns to concrete infrastructure choices and a reference repo so you can deploy an autonomous LLM pipeline in your environment and run controlled experiments without compromising safety or observability.
Safety, Security, and Governance Practices
Agentic AI and autonomous LLMs amplify value by acting on your behalf, but that capability simultaneously raises the stakes for safety, security, and governance from day one. You must treat those concerns as engineering primitives rather than add-ons: define explicit blast-radius limits, code capability gates, and map every action to an auditable policy before the agent touches production systems. Building on the control-loop patterns we described earlier, we recommend folding safety and governance into the planner, executor, memory, and adapter contracts so risk is visible at every handoff.
How do you prevent an agent from escalating beyond its remit? Start with least-privilege authentication and capability flags: issue short-lived credentials (mTLS or OAuth client credentials) tied to service identities that reflect exactly which tools and environments are writable. Require signed approval tokens or an approval microservice for any non-idempotent or high-blast-radius step, and enforce capability flags in the executor path rather than in prompts. Use role-based access controls (RBAC) and attestations so you can correlate plan IDs to operator authorizations and perform retroactive audits.
Runtime controls must prioritize containment and recoverability. Implement action whitelists and sandboxed adapters that support dry-run and replay modes, require idempotency keys for external side effects, and add circuit breakers with exponential backoff and deterministic retry counts. For example, a database migration adapter should expose a dry_run mode returning a structured result the planner can validate before promotion; the executor must then require human approval or a canary rollout when rows_affected > threshold. These patterns make side effects reversible and reduce the chance of cascading failures.
Observability and provenance are non-negotiable for effective governance. Attach a single trace ID to the entire goal lifecycle and log the prompt, memory snapshot, plan JSON, adapter inputs, raw API responses, and normalized outputs under that ID. Record retrieval provenance for every memory hit, persist schema validations and confidence scores, and store idempotency keys and credential hashes (never raw secrets). When you can replay a trace end-to-end with the exact prompts and synthetic tool responses, debugging and compliance investigations become tractable rather than guesswork.
Testing and validation should simulate real adversarial conditions before you open write access. Build a simulation harness that replays traces with synthetic, flaky, and malicious tool responses so planners and rollback logic are exercised against worst-case behavior. Red-team model prompts to probe hallucinations and privilege escalation, unit-test planner outputs against a strict JSON Schema, and create black-box integration tests for adapters with sandboxed provider endpoints. Require a failing dry-run to block promotion, and automate smoke tests that validate rollback and compensating transactions after every deployment.
Governance ties technical controls to policy and operations. Encode policies as code and bind them to capability flags and feature gates so you can audit policy versions and roll back rules quickly; map controls to compliance frameworks and document retention/TTL policies for memory and logs to satisfy data-minimization requirements. Operationalize incident response with runbooks that reference plan IDs and trace logs, and roll out autonomy incrementally: read-only tools, gated writes, canary policies, then automated flows behind kill switches. Taking this approach ensures safety, security, and governance are engineered into agentic systems rather than being retrofitted later, which sets us up to wire these controls into the minimal deployable architecture we’ll describe next.