Define goals and requirements
When you design AI agent orchestration for production, unclear goals are the primary cause of brittle systems and wasted engineering effort. Start by naming the specific outcomes you want the orchestration layer to deliver—throughput, latency, cost, fault isolation, explainability, and regulatory auditability—and prioritize them. This upfront clarity forces trade-offs early: for example, optimizing for low p95 latency usually increases operational cost and constrains choice of state management. Building on the foundation we established earlier, translating high-level aims into measurable targets will save weeks of rework during integration and scaling.
Define functional goals first so everyone agrees on what the agents must do and how they coordinate. Specify core capabilities such as task delegation (who assigns work), capability discovery (how agents advertise skills), and escalation (when to route to a human). Then state the non-functional requirements—SLOs/SLA targets, availability zones, cost-per-request budget, and acceptable consistency models for shared state. What does success look like when a surge doubles request volume; how should the system degrade? Asking concrete operational questions like this uncovers hidden architectural constraints early.
Turn goals into measurable requirements that feed design and testing. For example, translate “low-latency inference” into SLOs such as p95_inference_latency_ms: 200 and throughput targets like min_throughput_rps: 100 per agent pool; express durability as availability: 99.99%. Define failure budgets (e.g., 0.1% monthly error budget) and observable signals: request_rate, error_rate, queue_depth, and end-to-end_trace_latency. Embed these values into deployment pipelines and load tests so each change is validated against real numbers rather than vague promises.
Map requirements directly to architectural choices so you can make repeatable trade-offs. If you require strict coordination and ordered workflows, prefer an orchestrator-driven control plane where a coordinator manages state transitions; if you need resilience and loose coupling, choose choreography with event-driven agents and idempotent handlers. For stateful agents or long-running reasoning pipelines, accommodate sticky sessions or a durable state store; for ephemeral reasoning tasks prioritize fast cold-starts and autoscaling. These decisions also determine your container orchestration footprint and whether to use serverless functions, containerized agents, or a hybrid approach—each option carries different implications for boot time, cost, and observability.
Treat security, governance, and observability as first-class requirements rather than add-ons. Specify data retention limits, encryption-at-rest and in-transit, role-based access control for agent actions, and tamper-evident audit logs that include causation IDs and trace_ids for every decision. Define when a human-in-the-loop is required (high-risk actions, policy violations) and what approval latency is acceptable. Instrument pipelines with distributed tracing and lineage so you can answer questions like: which agent produced this decision, what inputs were used, and how long did each reasoning step take?
Finally, convert goals into a lightweight implementation checklist that drives your next sprint: declare SLOs and failure budgets, define agent contracts and telemetry schema, choose orchestration tools that meet your state and scaling needs, and design human-approval hooks where required. First, codify measurable targets in the CI/CD pipeline; second, build representative load and chaos tests; third, validate security and audit paths with real datasets. Building on this foundation, the next step is selecting runtime and deployment patterns that satisfy these requirements while keeping orchestration predictable, observable, and cost-effective.
Choose orchestration patterns
When you move from goals to implementation, the most consequential decision is choosing how agents coordinate at runtime—because that choice shapes latency, cost, and operational complexity. AI agent orchestration often falls into a few repeatable orchestration patterns, and selecting one is less about picking the “best” option and more about matching trade-offs to your SLOs and failure budgets. How do you decide which pattern maps to your throughput, explainability, and auditability requirements?
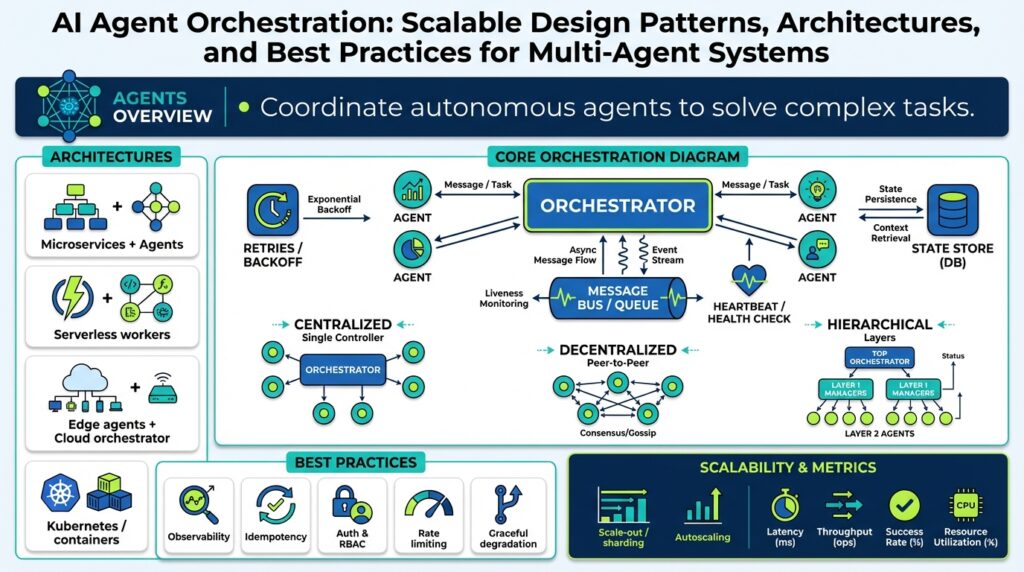
Start by separating control models: orchestrator-driven versus choreography. In an orchestrator-driven model a central coordinator sequences tasks, enforces ordering, and persists workflow state; this is ideal when you need strong causal traces, strict ordering, or compensating transactions. In a choreographed model agents react to events and reach eventual consistency through idempotent handlers; this pattern scales horizontally and isolates failures but trades off global ordering and can complicate end-to-end explainability. Building on the state and SLOs we defined earlier, pick orchestrator-driven when you require p95 latency guarantees tied to ordered steps, and choreography when loose coupling and fault isolation are higher priorities.
There’s a third, pragmatic family: hybrid patterns that combine a lightweight coordinator with an event mesh. Use a coordinator to handle critical handoffs and human-in-the-loop escalation while letting agents publish intermediate observations to an event bus for asynchronous enrichment and analytics. For example, implement a short-lived workflow manager that issues task tokens and writes causation IDs to a durable store, while downstream opinionated agents subscribe to those tokens and append their reasoning traces to a lineage log. This gives you ordered control for high-risk decisions without forcing every agent to be synchronously orchestrated, which reduces tail-latency during load spikes.
Consider runtime and deployment constraints as first-class inputs to pattern selection. Container orchestration, serverless functions, and containerized agents each change practical trade-offs: serverless is cheap for spiky inference but raises cold-start variance; containerized pools with warm instances reduce p95 latency at the cost of baseline compute expense. If your target SLO is p95_inference_latency_ms: 200 (from our requirements), favor warm pools and sticky routing for stateful reasoning; if throughput is bursty and cost-sensitive, favor event-driven serverless handlers with a small synchronous orchestrator for time-sensitive steps. Weigh observability too—distributed tracing across serverless invocations can be noisier than tracing a single orchestrator-managed workflow.
Design choices also affect governance and auditability. Orchestrator-driven flows make it straightforward to produce tamper-evident audit logs that include trace_id and causation_id for each decision, which helps meet regulatory requirements and simplifies incident forensics. Choreography requires disciplined telemetry standards—uniform event schemas, signed events, and lineage aggregation—to reconstruct decisions after the fact. Whatever pattern you choose, bake RBAC controls and human-approval gates into the orchestration plane so you can stop high-risk actions before they execute and meet the auditability goals we established earlier.
Make the decision process procedural: translate your SLOs and failure budget into a short decision tree. Ask: Do we need strict ordering or compensating transactions? Do we require low tail latency under sustained load? Is auditability and traceability a compliance requirement? If you answered yes to ordering and compliance, prefer orchestrator-driven; if you answered yes to independent scaling and fault isolation, prefer choreography; if you need both, design a hybrid with a coordinator + event mesh. Prototype the chosen pattern with representative load tests and tracing instrumentation to validate assumptions before broad rollout.
Choosing orchestration patterns is a series of trade-offs rather than a binary pick; by mapping your measurable targets—latency, throughput, auditability—directly to coordination models, you reduce integration surprises and make scaling predictable. In the next section we’ll translate the selected pattern into concrete runtime components and deployment templates so you can implement a repeatable, observable orchestration plane.
Design agent roles
When you leave responsibilities for autonomous components vague, the orchestration plane becomes an argument about who should do what when the system fails. In AI agent orchestration we must front-load role design and agent responsibility modeling into the architecture conversation so teams share a single, testable contract for each agent. Start by naming each agent’s primary responsibility, the inputs it expects, the outputs it guarantees, and the failure modes it will signal; doing so prevents overlap, reduces duplicated compute, and clarifies escalation paths early in the project.
A clear contract is the foundation for predictable behavior and observability. By “contract” we mean a machine-readable description that includes capability tags, required permissions, input/output schemas, and SLOs—what we call a capability contract. Define capability discovery primitives so agents can advertise versions and runtime constraints (e.g., memory, GPU requirement, latencies) and let the orchestrator or event mesh match tasks to suitable implementations. When you codify contracts, you can also synthesize tests and mocks that validate behavioral expectations before agents reach production.
Choose granularity intentionally: specialist agents for focused work, or generalists that coordinate multiple sub-tasks. Specialist agents are easier to reason about for auditing and for enforcing strict RBAC because each agent has a narrow surface area; generalist agents reduce network hops and can improve p95 latency at the cost of harder-to-explain internal reasoning. Building on our earlier SLO and pattern choices, pick specialist agents when auditability, explainability, or compensation transactions matter; pick generalists when end-to-end latency and fewer context switches are the priority.
Practical role definitions must include behavioral constraints and side-effect controls. Give each agent explicit side-effect permissions—read-only, idempotent-write, external-action—and require traceable causation IDs for any state mutation so you can reconstruct decision lineage during incident response. For example, an agent contract expressed as a small JSON schema can declare allowed external APIs, expected trace fields, and an error-category enum so orchestration logic can route retries or escalate to humans deterministically:
{
"name": "evidence-verifier",
"capabilities": ["fact-check", "confidence-scoring"],
"io": {"input":"document_batch","output":"verdict"},
"permissions": ["read:kb","write:verdict_log"],
"slo_ms": 1500
}
How do you ensure resilient matching and graceful degradation when a capability disappears? Implement a capability registry and lightweight health protocol where agents periodically publish their capabilities, version, and latency percentiles. The orchestrator or event mesh should prefer warm, version-compatible instances but have deterministic fallback rules (alternate agent, approximate result, or human-in-the-loop) and a ranked escalation path. Versioned contracts let you run A/B compatibility checks, and health signals let you circuit-break to cheaper, eventual-consistency handlers under load.
Finally, bake role design into CI, telemetry, and governance rather than leaving it to architecture diagrams. Generate unit tests from each capability contract, run contract-aware load tests, and require signed audit logs that include agent_id, trace_id, and causation_id for every action. When you map agent responsibilities to measurable telemetry keys and failure budgets, we can automate deployment gates, enforce RBAC, and validate the chosen orchestration pattern under representative fault scenarios—making runtime behavior predictable and auditable as the system scales.
Communication and state management
Building on this foundation, effective AI agent orchestration requires a deliberate communication fabric and a disciplined approach to state management that match your SLOs and governance constraints. If you prioritize low p95 latency and strong auditability, design your communication channels and state strategy to minimize tail latency while preserving causal lineage. Use the terms we established earlier—trace_id, causation_id, capability contracts—and surface them in every message and state mutation so you can reconstruct decisions under load. These choices directly affect throughput, explainability, and operational cost, so treat communication and state as first-class architecture decisions from the start.
When you pick a coordination model, you also pick a communication and state pattern. Orchestrator-driven flows favor synchronous control messages and a centralized workflow state, which simplifies ordering and audit trails; choreography favors event-driven pub/sub and decentralizes state, which improves fault isolation and horizontal scale. How do you ensure consistency without creating a coupling bottleneck? Use a hybrid: keep critical handoffs synchronous through short-lived tokens managed by the coordinator, and publish intermediate observations to an event bus for asynchronous enrichment. This hybrid lets you enforce strict ordering for high-risk steps while retaining the scalability benefits of event-driven communication.
Design your message envelope for practicality and observability. Include a small, stable envelope on every inter-agent message containing trace_id, causation_id, capability_version, and a ttl_ms field so handlers can circuit-break stale work. For example:
{
"trace_id": "t-12345",
"causation_id": "c-67890",
"capability": "summarizer.v2",
"payload": {"doc_id": "42"},
"ttl_ms": 30000
}
This pattern keeps messages compact, searchable, and verifiable, and it makes it straightforward to sign or hash the envelope for tamper-evidence when auditability is required.
State management must be pragmatic: separate transient reasoning state from durable decision state. Keep short-lived context (working memory, intermediate hypotheses) in fast in-memory stores co-located with warm agent instances to minimize network hops; persist final outputs, decisions, and audit logs to durable stores that support efficient queries for lineage and forensics. For long-running or multi-step reasoning, snapshot the working state and write an immutable event to an append-only store at each decision boundary so you can reconstruct execution without relying on a single mutable record. A simple state record might look like:
{
"agent_id": "a-3",
"trace_id": "t-12345",
"state_version": 42,
"last_mutation_causation_id": "c-67890",
"payload_hash": "sha256:..."
}
Choose storage models to match semantics: key-value stores or in-memory caches for low-latency ephemeral state, document stores for semi-structured context, and event stores when you need full append-only lineage.
Consistency, retries, and idempotency are the operational levers you will use daily. Require idempotent handlers and include deduplication keys derived from causation_id so retries are safe. Prefer optimistic concurrency controls for high-throughput paths and use explicit lease/sticky-session routing when you need strong session affinity for stateful agents. When end-to-end ordering matters, accept the cost of synchronous coordination; when eventual consistency is acceptable, design compensating transactions and idempotent reconciliation jobs to converge state without blocking the critical path.
Observability and governance close the loop between communication and state. Instrument every message path and state mutation with distributed tracing and expose trace-aware metrics—latency per hop, queue depth per topic, and mutation rate per agent version—so you can map performance back to capability contracts. Aggregate lineage logs periodically into a tamper-evident audit trail that includes signed causation chains; this makes it possible to answer questions like which agent produced a decision, which inputs influenced it, and how long each reasoning step took. By tying communication envelopes to persisted state snapshots and traces, we keep the system auditable without sacrificing scale.
Taken together, these patterns make communication and state management predictable and testable as you scale. In the next section we’ll translate these principles into runtime components and deployment templates that implement sticky routing, event meshes, and trace-aware persistence so you can validate the approach with load and chaos testing.
Scaling and performance strategies
Building on this foundation, the practical problem you face is scaling agent orchestration without blowing up latency, cost, or traceability. We need to treat scaling and performance as design constraints rather than afterthoughts: decide if you prioritize p95 latency, sustained throughput, or cost per request, then encode those priorities into autoscaling rules, routing policies, and placement decisions. How do you scale multi-agent pipelines so that throughput increases without the tail latency exploding or auditability disappearing? Answering that question up front makes the rest of the design deterministic.
Match capacity to behavior by partitioning agent workloads into distinct pools with explicit SLO-driven autoscaling. Start with capability-aware pools—CPU-bound, GPU-bound, and memory-heavy reasoning agents—and give each pool its own target metrics (e.g., target_p95_latency_ms and target_concurrency). Use target-tracking autoscalers for smooth demand and step-scaling for predictable bursts; supplement them with warm-instance pools for agents where cold-start variance would violate your latency SLOs. We recommend defining a baseline warm count per pool and letting autoscaling absorb the delta so you trade predictable cost for predictable performance.
Reduce per-request overhead by combining concurrency controls, batching, and asynchronous pipelines in the critical path. Micro-batching can dramatically improve throughput for large-model inference but increases per-request latency variance, so place batching behind a configurable latency budget and fall back to single-request paths when p95 must be preserved. Implement a small token-bucket or windowed-batcher in front of heavy agents and make batching explicit in the capability contract so callers understand latency/throughput trade-offs. This pattern gives you operational knobs to tune both performance and cost without changing the agent logic.
Partition state and work to avoid global hotspots and to scale linearly. Use consistent-hash routing for session affinity when agents maintain working memory, and split event topics by shard key in your event mesh so consumers scale independently. For decision-critical mutable state, prefer leases and optimistic concurrency to reduce contention; for append-only lineage, use partitioned event stores that allow parallel consumers to replay segments for reconciliation. Choosing the right partitioning strategy reduces cross-agent coordination and improves overall throughput while preserving the causal traces we need for auditing.
Optimize placement and resource scheduling through targeted container orchestration and node labeling. Label nodes for special hardware (GPUs, high-memory) and use bin-packing policies to reduce per-agent cost while preserving headroom for autoscaling spikes. Apply pod disruption budgets, priority classes, and prewarming hooks to avoid eviction-induced tail latency. In mixed serverless/container environments, keep latency-sensitive agents in container pools with warm instances and move bursty, inexpensive tasks to serverless handlers—this hybrid placement minimizes cost without compromising performance.
Drive performance decisions with observability and adaptive controls rather than static rules. Instrument trace-aware metrics at each hop (latency per capability, queue depth, and retry rates) and implement adaptive backpressure—queue-based shedding, prioritized retry windows, and circuit-breakers—so the system degrades predictably under saturation. Use sampled traces to attribute tail events to specific agent versions or runtime classes, then automate canary rollbacks and capacity adjustments in CI/CD. When retries are necessary, require idempotency keys derived from causation_id to make retries safe and measurable.
Validate scaling assumptions through representative load and chaos tests before wide rollout, and bake those tests into your pipeline so capacity and performance are continuously verified. Run combined scenario tests that exercise warm pools, micro-batching, partition failover, and human-in-the-loop escalation paths to ensure SLOs hold under realistic failure modes. As we move from patterns to runtime components, we’ll translate these strategies into deployment templates and automation scripts you can reuse to make scaling predictable, observable, and cost-effective.
Monitoring, testing, and observability
Observability, monitoring, and testing form the operational nervous system for agent orchestration—without them you can’t reason about failures, drift, or compliance. When you design telemetry, start by tying metrics and traces directly to the SLOs and failure budgets we defined earlier: p95_inference_latency_ms, min_throughput_rps, and monthly error budget. That alignment forces concrete instrumentation choices instead of vague dashboards and ensures every alertable signal maps to an actionable remediation. In practice, this means we instrument request_rate, queue_depth, error_rate, and per-hop latency from the very first prototype so these signals are available during load and chaos tests.
Map each capability contract to a minimal telemetry schema so monitoring becomes deterministic rather than heuristic. For each agent capability declare the expected metrics (latency_histogram, success_count, retry_count), the trace fields (trace_id, causation_id, capability_version), and acceptable error categories; embed these keys in your CI so contract tests assert presence and semantics. This approach makes it straightforward to create SLO-based alerts and to compute burn rate for escalation. When an agent pool degrades, you want to see whether the problem is capacity, model quality, or an upstream schema change within the same dashboard and drilldown paths.
Distributed tracing and structured logs give you the causal context needed to reconstruct multi-agent decisions and to support auditability. Propagate a compact trace header across HTTP calls and message envelopes and sample aggressively for normal traffic while using tail-sampling to capture error traces; store a lineage pointer in each durable state mutation so you can replay execution. For message-based flows, include the same envelope we used earlier—trace_id, causation_id, capability—and sign or hash it if tamper-evidence is required. A small example for an HTTP call looks like: traceparent: 00-abcd1234abcd1234abcd1234abcd1234-0000000000000001-01 so you can correlate spans across serverless and container pools.
Testing must be layered and traceable to production observability so we can validate behavior under real-world constraints. Start with unit and contract tests generated from capability schemas, then run integration tests against a test harness that can spawn mock agents and inject latency, dropped messages, and malformed payloads. For end-to-end validation use replayable traces from production (redacted) and synthetic traffic that exercises warm pools, micro-batching, and human-in-the-loop escalation paths. How do you validate the whole pipeline before production? Automate canaries with trace-aware sampling and runbook-driven rollbacks so you can detect behavioral regressions within the same observability stack used in production.
Make alerts meaningful by coupling symptom-based detection with cause-based context. Create SLO burn-rate alerts for rapid triage and lower-priority system-health alerts for slow degradations, and attach automated runbooks that point to the exact trace and capability contract involved. Reduce noise with aggregated, version-aware alerting—alert on p95 deviations per capability_version rather than raw instance-level spikes—and use adaptive thresholds for ephemeral serverless pools. On-call responders should receive a reproducible link to the offending trace, the last state snapshot, and the capability contract so troubleshooting is deterministic rather than exploratory.
Design your observability pipeline to balance fidelity and cost: metrics for high-cardinality SLOs, logs for debugging, and traces for causality. Use selective retention for high-value lineage logs required for auditability and shorter retention for verbose debug logs, and implement rate-limited tail-sampling so error paths are preserved without storing every successful span. Export signed, append-only audit records for decisions that change durable state; this preserves tamper-evidence and supports regulatory queries while keeping hot-path telemetry lean enough for autoscaling decisions.
Taking these practices together, monitoring, testing, and observability become the feedback loop that enforces architecture choices and keeps agent orchestration predictable at scale. By tying tests to capability contracts, propagating trace context end-to-end, and converting telemetry into SLO-driven alerts and deployment gates, we make rollouts measurable and reversible. Building on this foundation, the next step is translating traces and test outcomes into automated canary policies, deployment gates, and capacity adjustments so we can close the loop between detection and remediation.



