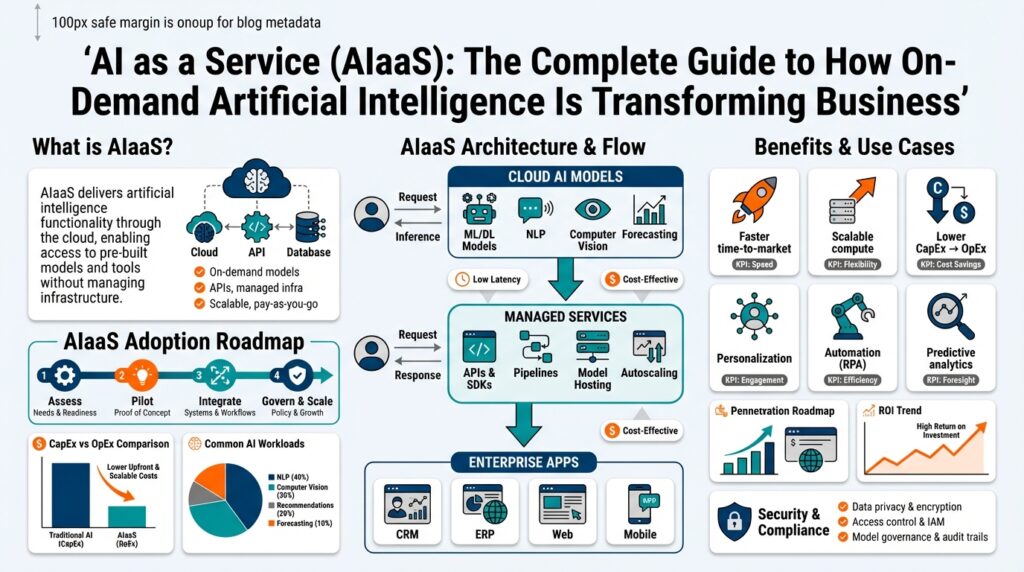
What Is AI as a Service
Building on this foundation, think of AI as a Service (AIaaS) as on-demand artificial intelligence delivered like any other cloud capability: APIs, managed runtimes, and pre-packaged models you call from your application stack. This framing matters because it separates the cognitive capabilities (vision, language, recommendations) from the operational burden (infrastructure, scaling, monitoring). You get functionality without owning every layer of the stack, which accelerates experimentation and shortens time-to-value for teams that need production-grade AI quickly.
At its core, AIaaS provides three technical layers you interact with: model endpoints for inference, managed training and fine-tuning pipelines, and platform services for observability and governance. Model endpoints are hosted inference APIs you call over REST/gRPC; inference here means executing a trained model to produce predictions. Managed training handles data ingestion, distributed compute, and hyperparameter tuning; fine-tuning is the targeted retraining of a base model on your domain data to improve accuracy or change behavior. Platform services—often labeled MLOps (machine learning operations)—cover CI/CD for models, versioning, drift detection, and deployment policies.
You’ll encounter several deployment patterns when integrating these services. The simplest uses pre-built inference APIs for text, speech, or vision where you send payloads and receive structured results; for example, a single HTTP POST to an image-classification endpoint can return labels and confidences. For domain-specific needs you use a customization path: upload training data, run fine-tuning jobs, and expose a dedicated endpoint that mirrors your app’s SLA. Hybrid approaches also exist: run inference in a VPC or edge container for low-latency use cases while keeping heavy training in the cloud, which gives you the flexibility to optimize cost and latency where it matters.
How do you choose between a black-box API and a customizable model? Evaluate on three axes: control, speed, and risk. If you need rapid prototyping and non-sensitive inputs, pre-built APIs deliver the fastest path. If model explainability, regulatory compliance, or domain nuance matters—think medical imaging or financial models—you’ll likely require fine-tuning, local hosting, or a hybrid topology. Real-world examples include using text-generation APIs for customer-facing chatbots to accelerate launch, while reserving in-house or private endpoints for fraud detection systems that must meet strict audit trails.
There are trade-offs that you must architect around: vendor lock-in, data residency, latency, and cost predictability. Vendor lock-in shows up as proprietary SDKs, model formats, or feature differences—mitigate this by standardizing on open model formats where possible and encapsulating provider-specific calls behind service adapters. Data residency and privacy push some teams to choose on-prem or VPC-backed inference; encryption in transit and at rest, plus tenant isolation, are practical controls. Finally, monitor for cost drift by tracking per-inference and per-training spend and setting budgets for model experiments.
Taking this concept further, treat AIaaS as another composable service in your systems architecture and design clear contracts around it. We recommend defining SLAs for latency and availability, creating a model catalog with lineage metadata, and automating rollback paths for model releases. In the next section we’ll map these operational requirements into concrete integration patterns and deployment templates so you can decide when to call an external API, when to fine-tune, and when to run inference in your own environment. AI as a Service can transform delivery velocity, but only when you pair it with disciplined engineering practices and measurable governance.
AIaaS Core Components and Models
Building on this foundation, the practical value of AIaaS shows up in a small set of reusable components you’ll interact with day-to-day: hosted model endpoints for inference, managed training and fine-tuning pipelines, and platform services that operationalize models. These terms matter because they define where control, cost, and risk live—model endpoints are the runtime contract your app calls; inference is the synchronous or asynchronous computation that returns predictions; managed training is the heavy-lift pipeline that turns data into a deployable artifact. Early in a project you’ll choose which of these components you outsource and which you keep close to the business.
The first core component is the model endpoint layer, which exposes inference over HTTP/gRPC and enforces SLAs, auth, and rate limits. Model endpoints hide the serving topology—autoscaling groups, GPU-backed instances, batching strategies—but you still need to specify latency budgets and throughput patterns so the provider can fit the right resources. For latency-sensitive features, we prefer dedicated endpoints or VPC-backed hosting to avoid noisy-neighbor interference; for low-volume batch jobs, multi-tenant endpoints reduce cost. Treat endpoints as contracts in your architecture diagrams and codify their SLAs in integration tests and runbooks.
A second pillar is managed training and customization: data ingestion, distributed training, hyperparameter tuning, and fine-tuning workflows that adapt base models to your domain. Not all customization requires full retraining; parameter-efficient methods like adapters or LoRA keep costs and turnaround times reasonable while delivering measurable accuracy gains. Fine-tuning becomes necessary when your domain vocabulary, regulatory constraints, or label distribution meaningfully diverge from the model’s pretraining corpus. When you do fine-tune, keep a reproducible dataset snapshot, automated validation suites, and cost limits so experiments remain tractable.
How do you decide between prompt engineering, embeddings, and fine-tuning? Ask whether the problem is transient, local to a few examples, or fundamental to task semantics. Prompt engineering and retrieval-augmented generation (RAG) are powerful when you need rapid iteration and up-to-date context without changing model weights; they’re ideal for chatbots and document search. Fine-tuning is the right option when you require consistent behavior across edge cases, higher accuracy on niche labels, or auditability for regulated workloads. Designing an evaluation matrix—precision/recall targets, latency allowance, and explainability requirements—helps you choose the right path.
The third component is platform-level MLOps: deployment pipelines, model cataloging, lineage tracking, monitoring for drift, and automated rollback. These services turn models from experiments into repeatable infrastructure: the model catalog records artifact versions, training datasets, evaluation metrics, and responsible owners so you can trace decisions during an incident. Observability for models includes both system metrics (CPU/GPU utilization, queue length) and model signals (confidence distributions, input feature shifts, label drift). Automate alerts for drift thresholds and cost anomalies, and integrate model releases into your CI/CD so deployments are atomic and reversible.
Security, governance, and compliance are cross-cutting components that shape architecture decisions for AIaaS. Data residency, encryption at rest and in transit, fine-grained IAM, and audit logs protect sensitive inputs during training and inference. For example, fraud detection or medical-imaging workloads typically require private endpoints, encrypted artifact stores, and immutable audit trails to satisfy regulators and internal auditors. Complement technical controls with model cards and risk assessments that document intended use, limitations, and mitigation steps.
Taken together, these components form a composable stack you can map against business requirements: use hosted endpoints and prompt-based patterns for rapid product iterations, adopt managed training and fine-tuning when domain fidelity is critical, and layer MLOps and governance to scale safely. In the next section we’ll translate these components into concrete integration patterns and deployment templates so you can decide when to call an external API, when to customize a model, and when to run inference in your own environment.
Common Enterprise AIaaS Use Cases
What drives most AI projects from PoC to production isn’t novelty—it’s repeatable business value you can call from your stack. In practice, organizations adopt AI as a Service to solve a handful of high-impact problems repeatedly: accelerating customer interactions, automating knowledge work, delivering personalized recommendations, detecting risk, and improving developer productivity. These categories map directly to the AIaaS components we discussed earlier—hosted model endpoints for inference, managed training/fine-tuning pipelines, and platform MLOps—and understanding the mapping helps you pick the right integration pattern.
Customer experience improvements are the fastest path to visible ROI. You’ll implement conversational agents, automated triage, and dynamic FAQs by wiring chat UI events to a hosted text-generation endpoint and augmenting answers with retrieval-augmented generation (RAG) against your document corpus. For example, a minimal production call looks like a POST to a model endpoint that includes a user message and a retrieval step that returns context:
curl -X POST https://inference.example/v1/chat \
-H "Authorization: Bearer $TOKEN" \
-d '{"messages":[{"role":"user","content":"How do I reset my bill pay?"}], "context": ["kb://billing/reset-procedure.md"] }'
This pattern reduces average handle time for contact centers and gives you measurable SLA improvements while keeping sensitive documents in a private vector store.
Automation of knowledge work is another high-yield area: contract analysis, claims processing, and compliance review. We commonly combine OCR + entity extraction endpoints with embeddings for semantic search to automate downstream workflows. For instance, extract parties, dates, and monetary values from a contract with a vision/text pipeline, then materialize structured outputs into your ERP or case-management system so case handlers only review exceptions rather than every document.
Recommendation and personalization systems benefit from hybrid inference strategies. Use offline training jobs to build candidate models and expose real-time model endpoints for scoring personalized feeds or offers; use embeddings for similarity-based recommendations where freshness matters. When should you fine-tune versus rely on prompt engineering and RAG? Choose fine-tuning when you need consistent behavior across edge cases and quantifiable accuracy gains; choose RAG or prompt-based approaches when domain context changes frequently or latency and cost are constraints.
Security, fraud detection, and regulated analytics are use cases that force architectural discipline. For fraud, we implement a two-tier topology: a low-latency local decisioning model runs inside a VPC for instant blocking decisions while heavy retraining and anomaly discovery occur on managed training pipelines in the cloud. That split preserves auditability and allows you to keep high-sensitivity inputs off public endpoints, while still leveraging the scalability of AIaaS for model updates and drift detection.
Developer productivity and internal tooling are quieter but compounding wins. Integrate code-completion and test-generation endpoints into IDEs and CI so engineers scaffold and validate code faster; integrate regression checks against model endpoints into pipelines so every PR triggers a smoke test of confidence distributions. For example, add a CI job that queries a staging model endpoint with a canonical test set and fails the build if average confidence drops below a threshold—this turns models into testable artifacts rather than black-box services.
Latency-sensitive inference at the edge closes gaps where cloud-only approaches fail. Deploy containerized inference in kiosks, manufacturing vision appliances, or retail PoS systems and keep heavy training in the cloud; orchestrate updates through a managed deployment pipeline so you can push model revisions without manual intervention. Taken together, these use cases show how AIaaS becomes a composable capability in your architecture: call hosted model endpoints for fast features, use managed training and fine-tuning when domain fidelity matters, and layer governance and observability to scale safely. In the next section we’ll translate these use cases into concrete integration patterns and deployment templates so you can decide which pattern fits your latency, cost, and compliance constraints.
Choosing the Right AIaaS Provider
Choosing the right AIaaS provider is one of the highest-impact platform decisions you’ll make because it changes how teams build, secure, and operate intelligent features. Building on this foundation, we need to evaluate providers not just on raw model quality but on how their offerings map to your latency budgets, compliance constraints, and operational workflows. How do you balance speed, control, and risk when a single provider decision can create long-term coupling? We’ll walk through the practical signals you should test and the trade-offs that matter in production.
Start by defining the concrete outcomes you need from AI as a Service: target latency percentiles, inference throughput, retraining cadence, and allowed data residency. These requirements become your acceptance criteria when comparing vendors and prevent vendor selection from becoming a feature checklist exercise. For example, if you require 50ms p95 inference inside a VPC for a fraud decisioning path, you should prioritize providers that advertise dedicated endpoints or edge/containerized deployment rather than general-purpose multi-tenant APIs. Stating measurable SLAs up front lets you convert marketing claims into testable integration requirements.
Inspect the integration surface closely—model endpoints, authentication, SDKs, and networking must fit your architecture. Test a provider’s model endpoints with representative payloads and measure round-trip latency, throughput under concurrency, and error behavior under backpressure; a simple curl load test often surfaces subtle issues in JSON schemas or rate-limit errors. Evaluate SDK ergonomics for your stack but avoid blind reliance on proprietary client libraries: prefer providers that expose clean REST/gRPC contracts and support open model formats when you plan to host models elsewhere. Also verify VPC peering, private endpoints, or edge runtimes if your application cannot route sensitive requests over public endpoints.
Operational capabilities separate neat demos from production-grade platforms—look past the model and into MLOps. Confirm the provider’s model cataloging, versioning, and artifact immutability so you can trace which dataset produced which model and who approved it. Ask to see built-in observability: confidence distributions, input feature shift metrics, and automated drift alerts that can trigger retraining jobs or rollbacks. Equally important is billing observability: per-inference and per-training breakdowns, and programmatic controls to cap experimental spend so cost doesn’t spiral during hyperparameter sweeps.
Security and governance must be contractual as well as technical. Insist on encryption in transit and at rest, fine-grained IAM, and immutable audit logs; validate whether the provider offers data processing agreements, SOC 2 or ISO attestations, and HIPAA options if you’re in healthcare. For regulated workloads—medical imaging or payment fraud—require private endpoints, encryption key control (BYOK), and a clear policy on data retention and model derivative rights. These controls are non-negotiable when audits demand lineage and when model outputs can affect legal or safety outcomes.
Commercial terms and exit strategy are frequently overlooked but critical. Understand pricing drivers—per-token or per-inference charges, GPU-hour training costs, storage and egress fees—and simulate expected monthly spend with realistic traffic. Negotiate contractual SLAs for availability and performance, and require data export in an open format as a condition of procurement. Mitigate lock-in by standardizing on model formats like ONNX or containerized inference images and by encapsulating provider calls behind thin service adapters so you can swap providers or bring inference in-house if needed.
Finally, treat provider selection as an engineering experiment: run a short pilot with representative workloads, define KPIs (latency p95, cost per 1k inferences, model accuracy on edge cases, and time-to-fine-tune), and validate governance flows end-to-end. Measure behavior on adversarial inputs and monitor for unexpected confidence shifts during the pilot—these tests often reveal operational gaps that docs don’t cover. Taking this disciplined approach turns vendor choice from a checkbox into a repeatable decision process that aligns with your SLAs, compliance needs, and rollout plans, and prepares you to map those choices into concrete integration patterns and deployment templates next.
Integration, Deployment, and Scaling Steps
Building on this foundation, the single biggest risk when you move AI as a Service into production is treating model integration as an afterthought rather than a core architectural concern. Early decisions about authentication, data contracts, and network topology determine whether your AIaaS feature becomes a stable product or an operational liability. Start by defining the runtime contract for model endpoints: payload schema, latency SLOs, error semantics, and required metadata for auditing. Front-loading these requirements reduces rework later and gives you clear acceptance criteria for integration tests and security reviews.
Begin integration by encapsulating provider-specific calls behind a thin service adapter so you can swap vendors or run inference in-house without a large refactor. Declare a schema-first API between your application and the inference layer and enforce it with contract tests; this prevents subtle breaking changes when a model endpoint evolves. For sensitive workloads, integrate VPC/private endpoints and key-management before you send any production traffic, and instrument request/response logging with redaction to preserve auditability. We recommend codifying these patterns in reusable templates so teams instantiate compliant integrations rather than reinventing them.
When you deploy models, treat the model artifact like any other deployable: package, version, and promote through staging to production via CI/CD. Automate packaging so that a trained artifact includes model weights, a reproducible dataset snapshot, evaluation metrics, and a manifest that records hyperparameters and lineage. Implement an automated deployment pipeline that runs smoke tests against a staging model endpoint (including p95 latency and accuracy checks) and then performs a controlled push using canary or blue/green techniques. If you use managed fine-tuning, capture the fine-tune job id and trained weights in the same catalog entry to preserve traceability between experiments and production releases.
Scaling inference reliably requires you to separate throughput engineering from model behavior engineering. Define capacity planning targets for peak QPS and p95 latency, then map those targets to autoscaling policies, batching strategies, and instance types (CPU vs GPU). Use dynamic batching for high-throughput, non-latency-critical paths and dedicated single-tenant endpoints for sub-100ms decisioning where noisy neighbors are unacceptable. For hybrid topologies, orchestrate edge containers or VPC-hosted inference alongside cloud-hosted training so you get low-latency inference without sacrificing the scalability of managed training.
How do you operate rollouts and failures? In practice we run two-tier releases: start with a small percentage of traffic routed to the new model endpoint under real traffic conditions, monitor system and model signals for a short burn-in period, then increase traffic if metrics are healthy. Instrument both system metrics (CPU/GPU utilization, queue length) and model signals (confidence distribution shifts, input feature drift, number of unknown tokens) and wire automated rollbacks when thresholds are exceeded. This pattern preserves user experience while letting you validate model behavior at scale.
Taking these steps together aligns engineering, security, and business goals: you get predictable deployments, measurable SLAs, and a clear path to scale. Next, we’ll connect these operational patterns to observability playbooks and governance controls so you can automate drift detection, retraining triggers, and compliance reports that keep AIaaS features reliable and auditable as traffic grows.
Security, Governance, Compliance, and Ethics
Building on this foundation, treating AIaaS as a first-class platform requires you to bake security, governance, compliance, and ethics into design decisions from day one. If you treat these concerns as an afterthought, you’ll discover gaps during an incident or audit that cost time and trust. We’ll focus on concrete controls and trade-offs you can implement now—encryption, identity, lineage, and ethical guardrails—so teams can ship features while protecting sensitive data and maintaining accountability. These controls directly influence architecture choices you made earlier around endpoints, VPCs, and fine-tuning.
Start with threat modeling that reflects real operational risks rather than abstract lists. Identify sensitive inputs (PII, PHI, payment tokens), map where they travel across model endpoints and vector stores, and then enforce encryption in transit and at rest plus strong key management (prefer BYOK when regulatory obligations require it). Implement fine-grained IAM and role separation so only designated service identities can invoke training or export model artifacts; integrate SSO and short-lived credentials to limit blast radius. Complement these with schema validation and input redaction at the edge to prevent accidental leakage of secrets into logs or third-party prompts.
Governance is the connective tissue that turns security controls into auditable practices. Maintain a model catalog that records artifact hashes, dataset snapshots, hyperparameters, evaluation metrics, and an immutable audit trail linking production endpoints to the exact training job and dataset used. Automate policy-as-code so deployment gates enforce data residency, retention, and allowed-use constraints before a model moves from staging to production. Schedule periodic access and risk reviews, and codify SLAs and SLOs for model behavior—latency, accuracy on key segments, and acceptable confidence distributions—so governance decisions are measurable, not subjective.
How do you demonstrate compliance during an audit? Produce reproducible evidence: exportable dataset snapshots, signed manifests for model weights, immutable logs showing who approved each release, and retention policies that match contractual obligations. Instrument every inference with metadata (model-version, request-id, data-classification) and forward redacted telemetry to your SIEM for correlation with other security events. Prepare legal and procurement artifacts—data processing agreements, attestations from providers, and export formats—so you can answer auditors’ questions without rebuilding history on the spot.
Ethical risks emerge where model performance, business impact, and user expectations intersect, so treat fairness and explainability as operational requirements. Run bias tests across protected attributes relevant to your domain, quantify disparate impact with concrete metrics, and bake human-in-the-loop checkpoints for high-stakes decisions. Produce model cards and data sheets that document intended use, limitations, training data provenance, and known failure modes so product owners and auditors can make informed trade-offs. Regularly adversarially test models for edge-case behavior and document mitigation plans; transparency is a stronger defense than secrecy when harms are plausible.
Operationalize these controls with automated observability and incident playbooks so security, governance, and ethics scale with traffic. For example, implement a two-tier fraud topology: a low-latency VPC-hosted decision model for blocking, and a managed training pipeline in the cloud for continuous discovery and retraining; tie both to the model catalog and to drift-detection alerts that trigger a rollback pipeline. Define burn-in windows for releases, automate canary analysis against both system and model signals, and require explicit approvals for any model that affects legal or safety outcomes. Taken together, these practices let you move fast with AIaaS while preserving auditability, reducing risk, and preparing teams to respond when things go wrong—next we’ll map these controls into specific observability playbooks and enforcement templates you can apply across projects.