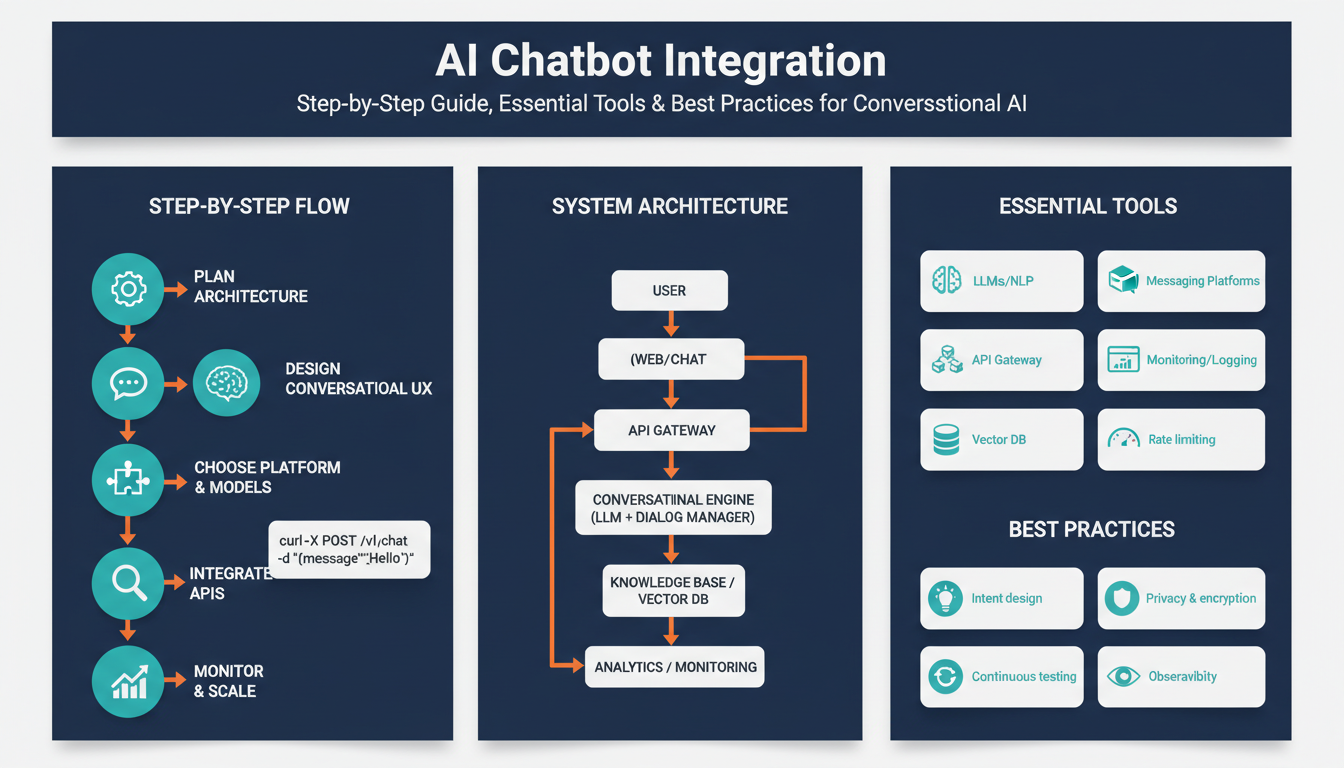
Define chatbot goals and scope
Building on this foundation, the first step is to convert vague product ambitions into measurable outcomes you can engineer toward. Define clear chatbot goals that map to business metrics — for example, reduce average handle time by 30%, increase self-service resolution rate to 60%, or capture qualified leads at a 15% conversion rate. Stating goals as measurable KPIs makes trade-offs explicit when you choose architectures, models, or integration patterns. When we treat objectives as engineering requirements, you can prioritize intents, data collection, and monitoring from day one.
Scope definition must follow goals and constrain the problem so you can deliver value iteratively. Decide which user journeys the agent will own end-to-end and which it will only assist with—authentication flows and billing inquiries are common candidates for end-to-end automation, while legal advice and complex troubleshooting are often better surfaced to human agents. Explicitly list supported channels (webchat, mobile app, voice) and data domains (order history, shipment tracking, account management) so your integration and privacy designs align with real needs. We recommend scoping by vertical slice: pick one high-value journey, automate it fully, then expand.
Translate objectives into technical acceptance criteria that guide implementation and testing. For each KPI create target-levels, success metrics, and observability hooks: a target intent accuracy, a fallback rate threshold, session abandonment rate, and required latency for real-time responses. For example, require intent classification F1 > 0.85 on production traffic and fallback < 5% for the primary journey. These criteria drive dataset collection, model selection, and how you instrument tracing and logs.
Design intent and entity coverage deliberately rather than exhaustively. Begin with a prioritized intent catalog that includes core business intents, high-frequency support queries, and safety-critical ones like “report fraud.” Use a small matrix to map intents to required integrations (CRM read, payments write), sample utterance count, and whether the flow needs stateful context. For instance:
{
"intent": "check_order_status",
"utterances_required": 200,
"integrations": ["orders_api"],
"stateful": true
}
This pattern helps you estimate annotation effort and choose between a retrieval-based or generative approach for each flow.
Consider non-functional scope early: security, privacy, and compliance constrain design choices as much as feature requirements. If the chatbot will access PII or payment data, plan for tokenization, least-privilege API keys, and auditable logs. If responses must be explainable, favor hybrid architectures that combine deterministic business logic (for policy enforcement) with models for natural language understanding. These constraints determine whether you need on-prem model hosting, encrypted data stores, or third-party vendor review processes.
Plan for escalation and ownership so the scope covers operational reality. Define clear handoff criteria — when confidence falls below a threshold, or when an entity extraction fails — and build lightweight transfer-to-agent channels that include session context and transcripts. Assign runbook owners for model drift, semantic errors, and integration failures so you can iterate quickly without firefighting. We find teams that codify escalation paths maintain higher uptime and user satisfaction.
Finally, translate scope into a roadmap that delivers value in vertical slices and enables measurement. Start with a single, instrumented journey that proves both the technical integration and the business impact, then expand coverage, channels, and model complexity based on observed metrics. How do you know when to expand? Use the acceptance criteria and KPIs you defined earlier: if intent accuracy, resolution rate, and user satisfaction meet targets, move to the next slice; if not, iterate on data, prompts, or integration points first.
Choose AI provider and platform
Building on this foundation, the provider and runtime you pick determine whether your acceptance criteria (latency, intent F1, fallback rate) are achievable in production. How do you pick an AI provider and platform that aligns with your KPIs and operational constraints? Start by mapping each KPI to measurable provider attributes: model family and size, average inference latency, SLA and uptime, throughput pricing, and data residency. Front-load these checks into vendor evaluations so you avoid late-stage architecture rework when you validate the first vertical slice.
Evaluate model capability and operational characteristics together rather than separately. For example, a large LLM might improve conversational fluency but increase tail latency and cost; conversely, a smaller retrieval-augmented model could hit your 200ms realtime target while preserving factual grounding. We recommend benchmarking with representative traffic patterns and production-like prompts: measure 95th-percentile latency, token costs per session, and downstream effects on fallback rate. These metrics directly map back to the acceptance criteria you defined earlier and make trade-offs explicit.
Decide early whether managed APIs or self-hosted model hosting fits your risk profile. Managed providers give polished SDKs, scale-to-zero, and frequent model upgrades, reducing ops burden when you need rapid iteration. Self-hosting on Kubernetes or a VM fleet gives control over data residency, custom model fine-tuning, and potentially lower per-inference cost at scale, but increases responsibility for autoscaling, model lifecycle, and security patches. Choose the platform that balances time-to-market against compliance and cost predictability for your specific journey.
Assess the integration surface the platform offers—SDKs, REST or gRPC inference APIs, stream/response-chunking, webhooks, and cloud-native connectors for CRMs and ticketing systems. Practical integrations use a small, secure backend service to mediate calls: your chat UI posts to /session -> your backend attaches context, calls the model API (POST /v1/predict {model, session_id, prompt}), applies policy filters, and writes traces to observability. This pattern centralizes auth, enforces least-privilege for downstream APIs, and gives you a single place to implement prompt templating, caching, and rate limiting.
Treat data handling capabilities as first-class selection criteria. If the chatbot accesses PII or billing information, you need encryption-at-rest, field-level redaction options, audit logs, and explicit retention controls from the provider or your platform. Also consider whether you will fine-tune models, use retrieval-augmented generation, or rely solely on prompt engineering; each approach has different requirements for secure vector stores, embedding pipelines, and approval workflows. These controls directly affect compliance and the safety guardrails you must implement during chatbot integration.
Avoid vendor lock-in by designing a thin abstraction between your business logic and the model layer. Implement a ModelProvider interface with methods like generate(prompt, sessionOptions) and embed/loadVector(documents) so you can swap providers or hybridize (managed API for low-effort flows, self-host for sensitive workloads). Monitor cost-per-conversation and model-performance delta continuously; if cost or drift exceed thresholds, your adapter lets you pivot without refactoring conversation state or orchestration logic.
Finally, validate decisions with a focused POC that runs real queries, measures the KPIs you defined earlier, and stresses billing and scaling behavior under expected traffic. Use the results to pick the provider and platform for the first vertical slice, instrument billing alerts and model-drift detectors, and plan a migration path for other journeys. With that operational validation in hand, we can move to designing the integration layer and runbooks that make chatbot integration robust and measurable.
Select WordPress integration method
Building on this foundation, the first practical choice you make is the integration pattern between your chatbot backend and WordPress—this decision determines security boundaries, latency, and how much of the integration you can iterate on quickly. You should evaluate plugin-embedded widgets, headless/decoupled frontends, and server-side connectors against the KPIs we defined earlier (latency, intent F1, fallback rate). Which WordPress integration pattern will meet your SLA and data-sensitivity requirements while still allowing retrieval-augmented generation (RAG) and observability?
A common fast path is a client-side widget delivered by a lightweight plugin or theme hook that loads a JS client and talks to your backend via REST or websockets. Use this when you need rapid time-to-market and the chatbot only requires read-only context (page metadata, non‑PII). Implementation follows a predictable pattern: enqueue the script in PHP, pass a nonce and REST endpoint via wp_localize_script, and have the client open a websocket or POST to /wp-json/my-chat/v1/session, where your backend mediates calls to the model provider. This pattern minimizes PHP surface area while keeping authentication and policy enforcement on the server.
When your flows require RAG, access to orders or PII, or you need low tail latency and observability, prefer a decoupled backend that owns session state and vector lookups. In this approach WordPress either serves the frontend that calls your backend or acts purely as a CMS for content consumed by a separate app (Next.js, Nuxt, or a mobile app). The backend should implement a ModelProvider adapter, a secure token-exchange for WP-authenticated users, and server-side caching for embeddings and retrieval results. That keeps sensitive data off the browser and lets you enforce least-privilege API keys, field-level redaction, and auditable logs.
There are important trade-offs to weigh. Plugin-embedded widgets reduce initial integration work but increase maintenance burden across WordPress upgrades, themes, and plugin conflicts; they also expose more surface area to XSS and CSRF unless you use nonces and Content Security Policy. Headless or server-side connectors increase operational complexity—deploying containerized services, managing Redis session stores, and a vector store (FAISS, Milvus, or managed alternatives)—but give you control over latency profiles and fine-grained access controls. Choose based on your acceptance criteria: for a 200ms 95th-percentile target, server-side batching and pinned model instances will usually be necessary; for softer latency targets, a managed API with a client-side widget may suffice.
If you adopt the WordPress plugin route, implement clear separation of concerns in the plugin: UI asset loader, secure REST routes, and minimal server-side logic. Register a REST route using register_rest_route(‘my-chat/v1’, ‘/session’, [‘methods’ => ‘POST’, ‘callback’ => ‘handle_session’]), validate nonces with wp_verify_nonce, and forward the request to your backend over mTLS or a private network. Store only ephemeral session ids in WP and push long-lived telemetry and transcripts to your observability pipeline—this keeps the CMS lightweight and ensures you can rotate model-provider credentials without a hot plugin update.
For headless integrations, instrument the backend workflow explicitly: authenticate the user with a signed JWT from WordPress (or use OAuth2 client credentials for server-to-server), hydrate the session context from WP REST endpoints, run retrieval against a vector database, then call your chosen model provider with prompt templating and safety filters. Persist conversation state in Redis or a durable store so you can transfer to human agents with full context. This architecture makes it straightforward to A/B different models, measure cost-per-conversation, and fall back to deterministic business-logic layers for high-risk intents.
To decide quickly, run a vertical slice: implement a single high-value journey end-to-end using the cheapest viable pattern that meets your acceptance criteria, then measure latency, security compliance, and operability. Assess maintainability, SEO impact (server-side render vs client widget), and incident response complexity before you scale the pattern to other journeys. Next, we will map the chosen pattern into orchestration, monitoring, and runbooks so you can operate the integration reliably in production.
Set up backend and APIs
Building on this foundation, start by treating the backend and APIs as the single trusted integration layer that enforces policy, routes context, and mediates every call to the model provider. Front-load this design decision: your backend should own authentication, prompt templating, rate limiting, and telemetry so clients never call the model provider directly. This reduces attack surface and gives you a single place to implement caching, vector lookups, and deterministic business logic that complements the model.
Design a small, well-documented API surface that maps to conversation primitives rather than low-level model calls. Expose endpoints like POST /session, POST /session/{id}/message, and GET /session/{id}/state so clients handle UI concerns while the backend composes prompts, enforces safety filters, and records transcripts. Implement a ModelProvider adapter layer (generate, embed, healthCheck) so you can swap managed and self-hosted providers without changing orchestration logic. This abstraction also makes A/B testing and cost-based routing straightforward.
Manage session state explicitly and keep sensitive data out of the browser. Store ephemeral session tokens in a short-lived cache (Redis or an in-memory store with persistence fallback) and persist long-term transcripts and audit logs to an append-only store for compliance. Use JWTs or signed cookies for user identity and implement a token-exchange for server-to-server flows—this lets your backend exchange a WP-signed JWT (or OAuth token) for scoped API credentials that expire quickly. Stateful flows benefit from a compact session snapshot (recent messages, retrieval keys, last-action) that you serialize when transferring to human agents.
When you add retrieval-augmented generation, make the retrieval pipeline part of the backend API rather than the client. Embed documents during ingestion, keep vectors in a managed store (FAISS, Milvus, or a cloud vector DB), and query the vector store inside POST /session/{id}/message before you call generate. Cache embeddings and retrieval results aggressively and use a relevance threshold to avoid noisy context. Example request flow inside the backend (pseudo-code):
// simplified handler
const message = req.body.text;
const topDocs = await vectorStore.query(embed(message), {k: 5});
const prompt = template({context: topDocs, history: session.recent});
const response = await modelProvider.generate({model, prompt, maxTokens});
await telemetry.log(sessionId, message, response);
res.json({text: response});
Security and data governance must be first-class engineering requirements. Enforce least-privilege API keys for the model provider, use mTLS or private networking for backend-to-provider traffic, and implement field-level redaction for PII before persisting or sending data to external vendors. How do you design APIs to protect PII while keeping responses fast? Use selective hashing or tokenization for sensitive fields, redact in-transit payloads to the provider when not needed for inference, and keep auditable logs that separate redacted transcript indices from raw data accessible only to compliance roles.
Operationalize observability and autoscaling for real traffic patterns. Instrument request traces (distributed tracing), record intent-level metrics (fallback rate, resolution rate), and measure model costs per conversation. Implement backpressure and batching—batch similar short prompts at the proxy layer for throughput-sensitive models and support streaming/chunked responses for long replies to reduce perceived latency. Configure SLOs around 95th-percentile latency and surface alerts when cost-per-conversation or fallback rate drifts above thresholds so you can pivot providers or tweak prompts quickly.
Taking this approach gives you a maintainable, testable integration layer that balances security, latency, and developer ergonomics. With the backend and APIs hardened, we can now map orchestration, runbooks, and monitoring so the system scales reliably and your chosen vertical slice meets the KPIs you defined earlier.
Design conversation flows and UX
Building on this foundation, your conversation flows and chatbot UX determine whether users complete tasks or abandon the session. Conversation flows should map directly to the KPIs and scope you defined earlier, because UX decisions—turn length, confirmation prompts, fallback behavior—drive resolution rate and average handle time. How do you design flows that feel natural, remain secure, and hit engineering SLOs? We start by treating the chat interaction as a stateful micro-application with explicit acceptance criteria and measurable checkpoints.
Start each flow by declaring its contract: the goal, success condition, allowed integrations, and confidence thresholds. This contract becomes the runtime guardrail—if intent confidence < 0.6 or entity extraction completeness < 0.8, the flow moves to a recovery or escalation branch. Define minimal required slots for each intent (e.g., order_id, auth_token) and enforce them before executing side-effecting operations. By codifying these rules you keep UX predictable and ensure the backend only executes operations when preconditions are met.
Design patterns matter: choose between linear, branching, and mixed flows depending on task complexity. Use linear flows for short transactional journeys (password resets, simple lookups) where you can validate each step deterministically. Use branching or state machines for troubleshooting or multi-step processes where user answers open new branches; model these as explicit states in your session store so you can serialize and resume conversations across channels. For complex knowledge tasks, combine deterministic slot-filling with retrieval-augmented generation to keep answers grounded while allowing natural follow-ups.
Microcopy, pacing, and persona shape perceived latency and trust—treat response craft as part of UX engineering. Write concise system prompts and agent persona declarations on the server, then stitch user history and retrieved context into a templated prompt. For example:
{
"system": "You are a helpful support assistant for AcmeCorp. Keep answers under 120 words and confirm next steps.",
"context": "{{top_documents}}",
"history": "{{recent_messages}}",
"user_input": "{{user_text}}"
}
This pattern centralizes style, enforces safety filters, and lets you A/B different tones without changing orchestration logic. Use typing indicators and streaming responses to reduce perceived latency for longer replies.
Plan for graceful failure and efficient escalation as first-class UX. When fallback occurs, surface concise recovery options: rephrase question, offer menu-based clarifications, or transfer to a human with a single click. Include a context bundle in handoffs: last N messages, extracted entities, attempted actions, and the confidence scores that triggered the escalation. We recommend attaching a short summary sentence that explains why the transfer is happening so the human agent can triage faster.
Validate flows with real and synthetic traffic before you ship. Run staged experiments that simulate common failure modes—noisy input, partial entity matches, rate-limited integrations—and measure fallback rate, mean turns-to-resolution, and satisfaction (CSAT) via short inline surveys. Use session replay and intent-level metrics to find conversational dead-ends; iterate by tightening prompts, improving templates, or adding targeted retrieval documents. A/B tests on prompt variants or microcopy often yield larger UX gains than model-size swaps for the same cost.
Remember channel-specific UX constraints: voice interactions need shorter prompts, explicit confirmations, and clearer turn-taking rules; mobile chat benefits from quick-reply buttons and progressive disclosure to avoid cognitive overload. Preserve session continuity across channels by serializing session snapshots and replaying recent history at handoff. These choices keep your conversational AI coherent, reduce repeated user effort, and improve cross-channel CSAT.
Designing flows and UX is iterative product engineering: combine measurable contracts, templated prompts, and explicit escalation rules so you can tune behavior against the KPIs you set earlier. Next, we’ll translate these UX patterns into orchestration and observability so the system remains resilient as you scale.
Test, deploy, and monitor
Building on this foundation, treat the production rollout of a conversational system as three engineering phases that must be instrumented from day one: testing, deployment, and monitoring. Front-load chatbot integration test hooks and observability into your backend so every session, retrieval result, and model call emits structured telemetry. By doing this you reduce firefighting later and make SLOs, cost-per-conversation, and intent-level metrics first-class engineering constraints rather than afterthoughts. This approach keeps your team accountable to the KPIs and acceptance criteria we defined earlier.
Start with a disciplined testing strategy that covers prompt templates, NLU units, API integrations, and full end-to-end journeys. Unit tests should validate deterministic logic: slot parsing, authorization checks, and prompt rendering; integration tests exercise vector lookups, CRM calls, and rate-limited APIs; end-to-end tests replay representative sessions through your /session and /session/{id}/message endpoints to assert resolution and fallback behavior. Use synthetic traffic and production replay to build test suites that mirror real utterance distributions and include negative cases (noisy input, partial entities). For example, a CI test might POST a recorded conversation and assert fallback_rate < 0.05 and response_latency_95p < 300ms.
Deploy progressively and automate rollback so incidents remain small and reversible. Use a staging environment that mirrors production for throughput and billing validation, then push changes via canary or blue/green deployments and feature flags to control exposure. Configure your CI/CD pipeline to run linting, unit/integration tests, static security scans, and a smoke test that asserts critical SLOs before promoting traffic. Gradual rollouts (for example 1%, 10%, 50%) let you validate model behavior and integration stability under real user contexts and give you a safe window to flip a feature flag or revert the canary if alerts fire.
Monitor both system and semantic signals with unified observability so you detect infrastructure faults and model failures early. Instrument request traces, per-session logs, and structured metrics like fallback rate, intent F1, 95th-percentile latency, sessions-per-second, and cost-per-conversation; correlate these with business KPIs such as resolution rate and CSAT. Implement dashboards and alerts tied to error budgets and SLOs so on-call engineers get actionable context (recent messages, confidence scores, top retrieval docs) in alerts. Remember to redact or hash PII before telemetry ingestion to preserve privacy while keeping logs useful for debugging.
Detecting model drift requires production-aware evaluation, not just offline metrics. Shadow testing and continuous evaluation pipelines should sample real traffic, run it through candidate models, and compute drift signals such as embedding-space distance distributions, rising fallback rate, or a sustained drop in intent F1 relative to baseline (we previously targeted F1 > 0.85). When thresholds are crossed—e.g., fallback rate sustained above the 5% SLA for N hours—trigger a retrain or promotion rollback and start targeted data collection for the failing intents. A/B tests and gradual promotions help you validate retrained models without exposing all users to risk.
Operationalize runbooks and incident playbooks so on-call engineers can act quickly and consistently. Each playbook should include immediate mitigation (disable feature flag, revert canary), triage steps (collect session bundle, confidence scores, recent retrievals), and escalation criteria tied to KPIs. Automate routine recovery where possible: circuit-breaker to backend integrations, auto-rollbacks for latency or cost spikes, and scripted handoffs to human agents with context bundles for complex cases. Taking this concept further, map these observability signals into your orchestration and runbooks so the system can scale safely and your team can iterate on chatbot integration with confidence.