Identify data sources and collection
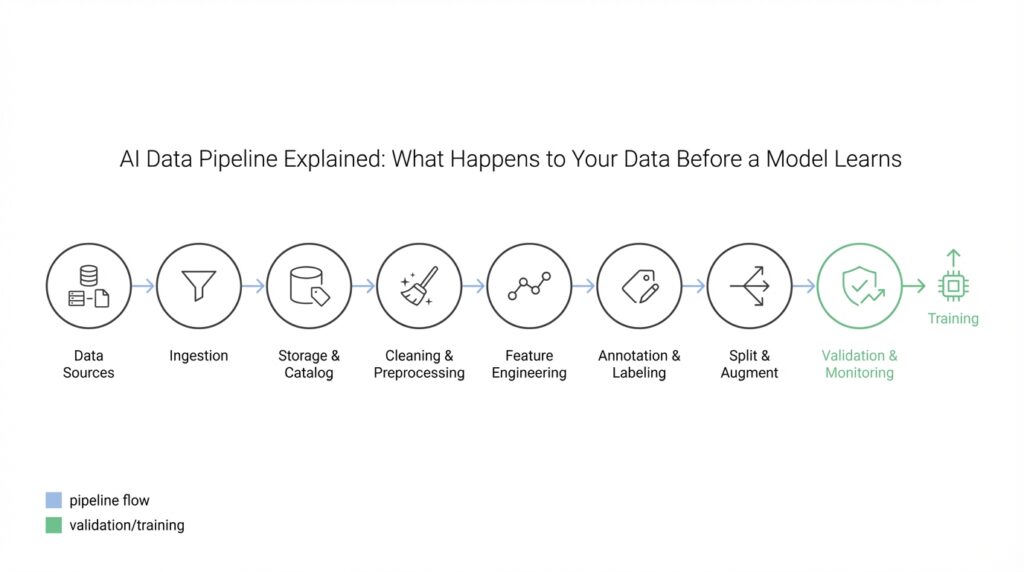
Building on this foundation, imagine you’re at the start of a new project and the first question on your mind is: where will the data come from? Data sources are simply the places or systems that produce information we’ll use — things like databases, user interactions, sensors, or public datasets — and data collection is the process of gathering that information into our data pipeline (the series of steps that move raw inputs into a form a model can learn from). Think of it like assembling ingredients before cooking: what you choose shapes the whole recipe.
The first practical step is to recognize the different flavors of sources. Structured data (rows and columns, like a spreadsheet or relational database) behaves differently from unstructured data (free text, images, audio), and semi-structured data (JSON, XML) sits between them. Common sources include transactional databases, application logs, third-party APIs, CSV exports, web scraping, IoT sensors, and labeled datasets from research or vendors. Each type brings its own format, volume, and quirks, so treat them as distinct characters in the story rather than assuming they’ll all behave the same.
Next we choose how to bring data into the system: batch or streaming ingestion. Batch collection gathers chunks of data at intervals (for example, nightly CSV dumps), which is like grocery shopping once a week; streaming ingest captures events continuously (like a live feed of button clicks or sensor readings) and is better for real-time needs. Streaming requires different tooling and reliability guarantees, while batch is often simpler and cheaper; your choice depends on timeliness requirements, complexity, and cost tolerance.
As we pick sources, we must pay attention to safety and ethics. Personally identifiable information (PII) — any data that can identify an individual, like names or email addresses — needs special handling and, in many cases, explicit consent or legal basis. Licenses and terms of service matter for third-party APIs and public datasets, and collecting more data without considering bias can bake unfairness into your model. Treat privacy and compliance as design constraints rather than afterthoughts; they shape which sources are viable.
How do you decide which sources to prioritize? Start by creating an inventory and scoring each source on signal (how useful the data is), noise (how messy or irrelevant it is), cost (storage, access fees, engineering effort), and latency (how quickly data is available). Then pilot the most promising candidates: pull a small sample, run exploratory checks, and see whether the data actually answers your downstream questions. Sampling early saves time and helps avoid expensive engineering for low-value feeds.
Record-keeping is surprisingly powerful, so capture provenance and metadata from the start. Data provenance is the history of where a piece of data came from and the transformations it underwent; metadata is the extra context (column types, units, timestamps, source system). Tag each dataset with a source ID, collection time, and quality flags so we can trace and reproduce any observation later. This is the equivalent of labeling jars in your pantry so you never mistake salt for sugar.
Before you scale, prototype an ingestion pipeline and apply basic data quality checks. By data quality we mean completeness (are expected fields present?), accuracy (do values make sense?), and timeliness (is the data fresh enough for the problem?). Run automated scripts on a small batch to detect missing values, out-of-range entries, or schema drift, then iterate. These checks catch problems early and prevent bad inputs from poisoning the model training stage.
With a clear map of who produces what, how we’ll collect it, and basic safeguards in place, we’ve laid the groundwork for the next phase of the pipeline: cleaning and transforming the raw feeds into reliable training data. That next step will turn this messy, diverse collection of sources into the consistent, high-quality inputs a model can actually learn from.
Ingest data and store reliably
Imagine you’ve just agreed to build a model and the pile of raw feeds is waiting at the doorstep — clickstreams, CSV exports, API responses — and your immediate worry is not the fancy math but simply getting that data into your system safely. This section focuses on data ingestion and reliable storage as the backbone of any healthy data pipeline, because if the inputs are shaky the model never stands a chance. Think of data ingestion as the mailbox that collects every letter, and reliable storage as the locked filing cabinet where we keep the originals; both must be designed so nothing is lost, tampered with, or misunderstood later. We’ll walk through simple patterns and practical checks you can implement today to make that mailbox and cabinet trustworthy.
Building on this foundation from earlier, start by creating a deliberate landing zone — a specific place where raw inputs first arrive and remain immutable. A landing zone is an append-only area (append-only means we only add new records, never overwrite the originals) where raw files, event logs, or API dumps are stored exactly as received; keeping these originals makes debugging and provenance easy. Make the landing zone cheap but durable (object storage is a common choice) and tag every file with metadata: source ID, collection timestamp, ingestion job ID, and a checksum to verify integrity. By separating the raw landing zone from transformed copies, we keep a reliable audit trail and avoid losing the original context during downstream cleaning.
Next, think about delivery guarantees and failure modes: how do you make sure nothing is lost during transfer? Delivery guarantees like at-least-once and exactly-once describe how often a message may be delivered; idempotency — the property that repeating an operation has the same result as doing it once — is how we tolerate retries safely. Practically, implement acknowledgements, retries with backoff, and idempotent write operations on the consumer side so repeated deliveries don’t corrupt your dataset. Use buffers or queues to absorb spikes and provide backpressure (backpressure is the signal that slows producers when consumers are overloaded), so temporary outages don’t translate into permanent data loss.
Schemas and lightweight validation act like a table of contents that keeps the incoming story coherent. A schema (a definition of expected fields and types) and a schema registry (a central place to store those definitions) let producers and consumers agree on what structure looks like, and they help detect schema drift (schema drift is when the shape of incoming data changes unexpectedly). Validate records on arrival for basic completeness and types, tag or quarantine bad entries for review, and automate contract tests between producers and consumers to catch breaking changes early. When you encounter drift, prefer versioned schemas and graceful migration paths rather than ad hoc fixes that introduce silent data corruption.
Durability, replication, and security complete the reliability picture: durability means the storage system protects data against hardware failure and bit rot over time, replication means copies exist in multiple places, and encryption and access control keep the data safe from unauthorized eyes. Choose storage classes that match your access patterns — hot storage for recent, frequently used data; cold/archival storage for older, rarely accessed originals — and set clear retention policies that balance compliance, cost, and reproducibility. Backups and an automated restore drill give you confidence that recovery is possible and that your provenance metadata will bring things back to a reproducible state.
Finally, treat ingestion and storage as an operational service with metrics, alerts, and SLAs; this is how reliability becomes sustainable. Monitor ingestion lag, error rates, storage costs, and the freshness of the landing zone; log and surface provenance for every dataset so troubleshooting feels less like guesswork and more like following breadcrumbs. With a robust ingestion layer and reliable storage in place, transforming and cleaning those raw feeds becomes a repeatable, auditable step — and we can move on to shaping that trustworthy raw material into high-quality training data.
Labeling and annotation workflows explained
Imagine you’ve just collected a rich batch of raw examples and you can see the shape of a model emerging in your head — but before any learning can happen, someone (or something) must tell the model what each example means. In this stage we talk about labeling and annotation workflows inside the data pipeline and why they are the bridge between raw inputs and useful training data. Labels are the simple tags or categories we attach to an example; annotations are richer markings or notes (like bounding boxes on images or spans in text) that describe structure or meaning in more detail. This is where examples stop being mysterious signals and start becoming teachable lessons for the model.
You might be wondering: what’s the practical difference between a label and an annotation? A label is a short, categorical value — for instance “spam” vs “not spam” — while an annotation is a piece of structured information attached to the example, such as a highlighted sentence, a polygon around a road sign, or a timestamped transcription of speech. Think of a label as the title on a book and an annotation as marginalia that explains why a passage matters. Defining these terms clearly at the start of the workflow saves hours of rework later, because the team will know whether they need quick binary tags or detailed, human-readable structure.
Who actually does the work matters a lot, and this is where process design earns its keep. Human annotators are people trained to follow an annotation guideline — a written document that explains each label, edge case, and example — and it’s crucial we write these guidelines like a recipe, with inputs, expected outputs, and a few “if this happens, do that” rules. Automated pre-labeling uses a weak model to propose labels that humans then correct, which speeds throughput but requires vigilance against model bias. How do you ensure consistency? We train annotators on examples, run blind quality checks, and measure agreement so you can spot ambiguous instructions or confusing data.
A typical workflow reads like a small conveyor belt: sample selection from the landing zone, assignment to annotators, annotation in an interface, quality review, and then storage with metadata that preserves provenance. For example, image classification needs a clean set of images and a short list of classes, while named entity recognition in text requires span-level annotations and a tokenizer-aware interface. We keep the original raw files immutable (as we discussed in ingestion and storage) and attach annotations as versioned artifacts, so every training snapshot can be traced back to what the annotators saw and when.
Quality control is not optional; it’s the mechanism that turns human judgment into reliable training labels. We measure inter-annotator agreement — a simple way to quantify how often different people pick the same label — and use adjudication, where a senior reviewer resolves disagreements, to create gold-standard examples. If agreement scores are low, that’s a signal to refine the guideline or provide more examples, not to blame annotators. Treat these scores like a health check: they tell you whether the annotations are stable enough to teach a model.
Tooling and orchestration determine how smoothly labeling workflows scale. Annotation tools are interfaces for marking examples; common output formats might be JSONL (newline-delimited JSON, which is easy for pipelines to read) or other structured files that your training process expects. Model-in-the-loop approaches and active learning (active learning is when the model chooses which examples would be most informative to label next) can reduce labeling volume by prioritizing uncertain or diverse examples. Whatever tools you choose, integrate versioning, metadata capture, and simple APIs so labels flow back into your dataset catalog without losing provenance or context.
By the time examples are annotated and quality-checked, we’ve turned raw signals into documented, traceable training data — but the work isn’t finished. Keep metadata with each annotation (who labeled it, when, and under which guideline version), track costs and throughput, and maintain a feedback loop so annotators and engineers can iterate on edge cases together. With that mapped out, the next step is to clean and transform these labeled artifacts into the consistent, normalized training sets your model will actually consume.
Clean, normalize, and validate data
Imagine you’ve just pulled the annotated batch from the landing zone and opened a folder that feels like a messy kitchen after a dinner party: files from different sources, inconsistent labels, timestamps that don’t match, and a handful of obvious mistakes. This is the moment where data cleaning, normalization, and validation step in — they are the kitchen routine that turns disorder into a reliable mise en place for your model. We’ll walk through each step as if we’re tidying, organizing, and checking quality together, so your preprocessing prepares data the model can actually learn from.
First, let’s meet data cleaning — the process of finding and fixing errors so the dataset reflects reality more closely. Cleaning means handling missing values (places where data is absent), correcting obvious typos or parsing errors, removing duplicate records, and flagging outliers that probably stem from sensor glitches or import bugs. When we clean, we don’t throw away everything that looks odd; we investigate why it’s odd, because some outliers are real signals rather than mistakes. Think of cleaning like peeling and trimming ingredients: you remove what will spoil the recipe, but you keep anything that adds important flavor.
Next comes normalization, which makes different feeds speak the same language and scale — a crucial part of preprocessing when sources vary. Normalization is about converting units (inches to centimeters), standardizing categorical values (“NY” vs “New York”), and scaling numeric ranges so one feature doesn’t drown out another during training. Normalizing text can mean lowercasing, removing punctuation, or applying consistent tokenization; for images it can mean resizing and normalizing pixel ranges. These transformations let examples from different sources be compared fairly, much like aligning recipe measurements so everyone follows the same cup and teaspoon sizes.
Validation is the reality check that follows cleaning and normalization: it verifies the data actually conforms to expectations before it reaches the model. Validation covers schema checks (does each record have the expected fields and types?), range checks (are numeric values within plausible bounds?), and business rules (does the event timestamp fall within the experiment window?). We also run statistical validation: compare distributions between training slices and recent production data to spot drift. How do you tell if a column is clean enough? Use a mix of rule-based checks and lightweight tests that fail loudly when assumptions break.
Putting these steps together, a practical flow feels like a gentle assembly line: ingested files land in the immutable raw zone, we run automated cleaning passes that tag or fix obvious issues, then normalization transforms formats and scales, and finally validation gates the dataset with clear pass/fail signals and metadata. Keep provenance (source ID, ingestion time, job ID) attached at every step so when a downstream metric spikes you can trace which transformation changed the signal. For example, a text dataset might go from raw logs to cleaned rows (strip nulls, fix encoding), to normalized tokens (lowercase, consistent tokenization), to validated artifacts (no empty labels, label distribution within expected ranges) that are ready for training.
This process improves data quality in the pipeline and reduces surprises during model training, but it’s also an iterative practice: celebrate small wins when a validation check goes green and treat failures as clues to refine cleaning rules or update annotation guidelines. As we move from labeled, cleaned, and normalized artifacts toward feature engineering and dataset versioning, keep in mind that good preprocessing is repeatable, auditable, and conservative — preserve originals, log every change, and make checks explicit so future you (and your team) can trust what the model learns next.
Feature engineering and data transformation
Building on this foundation of cleaned, normalized artifacts, the next creative step is where raw columns turn into meaningful signals for a model: feature engineering and data transformation. Feature engineering is the process of creating or selecting features — individual measurable properties or characteristics pulled from your data — while data transformation describes the operations that convert raw values into formats a model can learn from. Think of this as taking your ingredients and chopping, marinating, and arranging them so the recipe actually comes together; the way you prepare features determines whether the model tastes good or falls flat.
A feature is not the same as a raw column: a timestamp column is raw data, whereas a feature might be “hour of day” or “days since last purchase.” We introduce features gradually, like characters in a story: some are direct (numeric values you scale), some are categorical (labels you encode), and some are derived (aggregations or interactions you compute from multiple columns). Defining each feature clearly — its type, units, and provenance — keeps the pipeline honest and makes later debugging much easier.
In practice, common data transformations include encoding categorical variables (turning text labels into numbers), scaling numeric ranges (so one wide-range feature doesn’t dominate), extracting time-based features from timestamps, and aggregating events into rolling statistics (like 7-day average clicks). For example, in an e-commerce scenario you might derive a user’s rolling 30-day spend, count of returns, and a binary indicator for a recent promo click; these transformed features often carry more predictive power than raw logs. We treat these transformations like testable recipes: write the code, run it on a sample, and inspect distributions to see whether the result makes sense.
The model you plan to use influences which transformations matter. Linear models and distance-based methods usually require careful scaling and one-hot encoding for categories, while tree-based models tolerate raw categories and skewed distributions better. Neural networks often benefit from continuous embeddings for high-cardinality features (an embedding converts categories into dense numeric vectors learned by the model). Match your feature choices to the model’s assumptions, and document why a transformation is applied so the reasoning survives handoffs between teammates.
Operationally, treat transformations as code in a pipeline, not as one-off scripts. Package preprocessing into reusable components that run identically at training and inference, store transformation metadata (versions, parameters, and seed values), and include unit tests that check schemas and statistical properties. Consider a feature registry or feature store when features are shared across teams; this reduces duplication and enforces consistency so the same “days since last purchase” you used in training feeds the production service unchanged.
How do you decide which features will help your model? Use a mix of quick experiments and guarded analysis: run simple baseline models with candidate features, measure uplift with ablation studies (remove one feature group at a time), and examine feature importance or permutation tests to see which signals matter. Beware of data leakage — accidentally using information that won’t be available at prediction time (for example, using a future label or downstream metric as an input) — because leakage creates unrealistically good performance that collapses in production.
Finally, feature engineering is an ongoing practice: monitor feature distributions in production, detect drift when a feature’s statistics shift, and trigger retraining or feature reengineering when performance degrades. Keep lineage and versioning so you can trace which feature changes affected model behavior, and keep lightweight dashboards for key feature health metrics. This keeps the pipeline resilient and makes future iterations faster.
With these patterns in place — thoughtful transformations, reproducible code, careful selection, and operational monitoring — your training data becomes a reliable set of signals rather than a pile of numbers. Next, we’ll carry these engineered features into dataset versioning and model training so the learning phase can start from a stable, auditable snapshot.
Versioning, lineage, privacy, and monitoring
Imagine you’re standing at the threshold between cleaned, engineered features and the moment a model actually learns — and you’re asking how to keep everything honest, traceable, and safe. Right away we need to think about data versioning (saving snapshots of datasets and transformations), data lineage (a map of where each value came from and what happened to it), privacy (protecting people’s information), and monitoring (watching for surprises once the model is live). These four practices are the guardrails that turn one-off experiments into repeatable, trustworthy workflows you can explain to teammates and auditors alike.
First, let’s make sense of versioning in plain terms: versioning means keeping immutable copies of a dataset and the exact code or parameters that produced any transformed version. Think of it like a recipe book where every batch you cook gets its own page describing ingredients, measurements, and the oven settings; dataset versioning gives you the page to reproduce that meal. We’ve already emphasized provenance earlier when we talked about landing zones and metadata; versioning formalizes that provenance so you can rerun experiments, compare previous models, and roll back to a known-good snapshot if something goes wrong.
Next, consider lineage as the provenance map drawn in fine detail: data lineage records the path from the original source file through each cleaning, normalization, and feature transformation to the final training example. Lineage is what lets you answer a question like “Why did precision drop last week?” by following breadcrumbs to a particular ingestion job, schema change, or annotator guideline update. When you capture lineage at a field level, not just at dataset-level, debugging becomes an investigation with a trail instead of a guessing game.
Privacy sits alongside versioning and lineage as a set of constraints that shape how you store and expose those traces. Privacy means treating personally identifiable information (PII) — anything that can identify a person, such as names or emails — with extra controls: minimize collection, encrypt data at rest and in transit, apply access controls and masking, and maintain retention policies that delete or archive old copies according to legal and ethical requirements. For sensitive use cases you may also consider techniques like pseudonymization (replacing identifiers) or differential privacy (adding controlled noise to statistics) so you can share insights without exposing individuals.
Monitoring is the active discipline that turns those artifacts into ongoing safety nets: it’s the practice of tracking metrics about data quality, schema conformity, label distributions, and feature statistics in production so you detect drift early. How do you know when a dataset has drifted? You instrument key signals (missingness rates, token length changes, label imbalance) and set thresholds or anomaly detectors that create alerts and start a playbook — for example, pin a model to an older dataset version and trigger a retraining ticket if drift crosses a risk threshold. Monitoring closes the loop between detection and action.
These elements aren’t independent; they reinforce one another. Versioning gives you the snapshots to roll back or to run controlled A/B experiments, lineage tells you which transformation or source to fix, privacy dictates what you can retain or share when investigating, and monitoring tells you when to use those tools. For instance, a sudden shift in feature distribution discovered by monitoring points to a lineage trace that identifies a new upstream source; with dataset versioning you can compare the current model against a previous snapshot and decide whether to retrain, patch the feature, or roll back.
As we move from engineered features into training and deployment, treat versioning, lineage, privacy, and monitoring as a single, integrated practice rather than separate chores. Capture metadata consistently, enforce access controls early, and wire monitoring to automated playbooks so small issues become manageable fixes instead of model outages. With those patterns in place, your models will learn from data you can explain, reproduce, and trust — and that makes the next phase of modeling far less mysterious.