AI Voice Assistants Overview
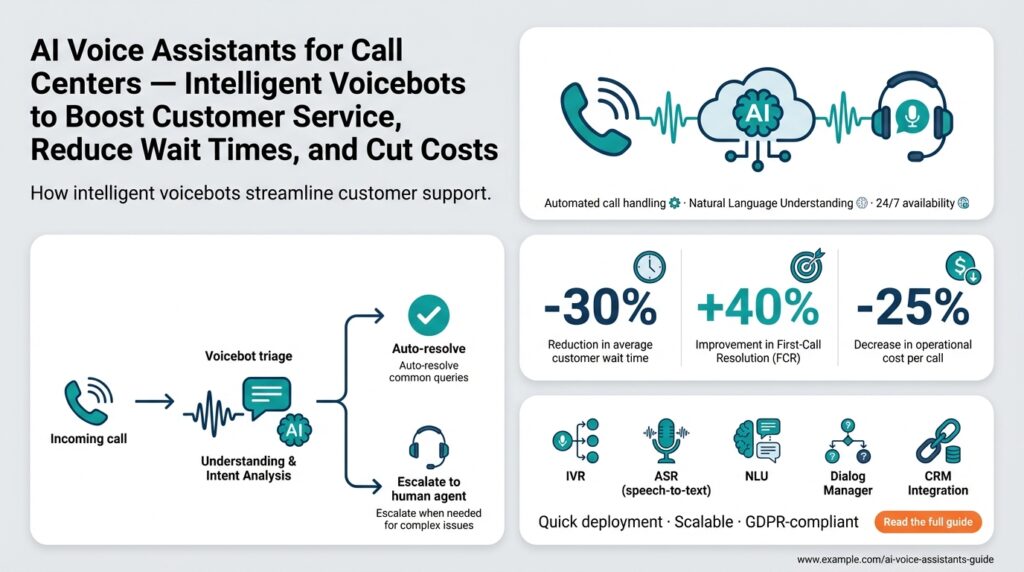
AI voice assistants and voicebots are the first line of interaction in modern call centers, absorbing routine volume, shortening wait times, and routing complex issues to human agents. In the next bite of the architecture we’ll unpack, these systems must reliably recognize speech, infer user intent, maintain context across turns, and produce natural responses — all while integrating with legacy telephony and CRM stacks. If your goal is to reduce cost per contact without degrading experience, understanding the engineering trade-offs behind each module is essential.
At the core of an assistant are four technical components: automatic speech recognition (ASR), natural language understanding (NLU), a dialogue manager (policy), and text-to-speech (TTS). ASR converts audio to text and must be robust to accents, background noise, and codec artifacts; NLU performs intent classification and slot filling (extracting structured data from utterances); the dialogue manager decides the next action using either rule-based flows or learned policies; and TTS renders responses with prosody that sounds human. We often combine deterministic fallbacks (DTMF input, menu prompts) with statistical models to get predictable behavior for high-risk tasks like payments.
Integration patterns make or break production deployments. Connectors usually sit between SIP/WebRTC media streams and cloud services: a media gateway or SIP proxy forwards audio to a streaming ASR (gRPC or WebSocket) while control events move through REST webhooks or a message bus. You’ll integrate with CTI (Computer Telephony Integration) to manage call context, with CRM (Customer Relationship Management) to fetch customer records, and with WFM (Workforce Management) to trigger agent callbacks. For low-latency interactions, prefer streaming pipelines with voice activity detection (VAD), jitter buffers, and partial transcripts so the dialogue manager can start responding before the user finishes speaking.
Conversation design and error handling determine whether your voicebot feels helpful or frustrating. Start by defining intents that map to clear business outcomes (balance inquiry, payment, technical reset) and set confidence thresholds that trigger confirmation or escalation. For example, a billing flow should authenticate (masked account number via DTMF or voice biometric), collect the billing period slot, attempt the resolution, and, if confidence is low or customer sentiment deteriorates, attach the full transcript plus NLU context to an agent transfer. How do you ensure accurate intent detection in noisy calls? Combine domain-adapted ASR models, data augmentation with noise profiles, and continual fine-tuning using post-call transcripts and confusion analysis.
Operational resilience, compliance, and measurement are non-negotiable for enterprise deployments. Track containment rate (percentage resolved by the assistant), average handling time (AHT) for assisted calls, escalation rate, and CSAT for transferred interactions to prove ROI. Instrument observability at multiple layers: audio quality metrics, ASR word-error-rate estimates, NLU confidence distributions, policy decision logs, and end-to-end call traces so you can debug regressions quickly. On compliance, design tokenization and redaction for PCI-sensitive data, maintain retention policies for recordings, and ensure your architecture supports regional data residency and encryption-in-transit and at-rest.
Building on this foundation, we can now evaluate design patterns and vendor trade-offs that fit your operational constraints and business priorities. Next, we’ll examine concrete implementation choices — hybrid versus fully managed models, where to run inference (edge vs cloud), and how to instrument continuous improvement loops so the voice assistant learns from every interaction and measurably reduces cost while improving customer experience.
Key Benefits for Call Centers
AI voice assistants are rapidly shifting the economics and experience of modern call centers by taking on the predictable, high-volume work that used to clog agent queues. When you deploy voicebots that combine streaming ASR, robust NLU, a dialogue manager, and natural TTS, you reduce initial friction: customers get immediate responses and your humans focus on exceptions. This upfront reduction in latency and cognitive load changes daily operations — shorter queues, fewer abandoned calls, and a smoother caller journey — and it’s why many contact center teams prioritize intelligent voice automation in their transformation roadmaps.
One of the most visible benefits is dramatic wait-time reduction and higher containment rates. By using partial transcripts and early intent signals from ASR and NLU, a voice assistant can start resolution mid-utterance and complete routine tasks without agent intervention. How do you measure those gains? Track containment rate, average handling time (AHT) for assisted interactions, escalation rate, and CSAT for transfers; these metrics directly map to cost-per-contact and service quality. Moreover, improving recognition accuracy with domain-adapted ASR models and confidence-driven confirmations reduces repeated prompts and raises first-contact resolution.
AI voice assistants also deliver tangible cost savings through automation and more efficient routing. When a voicebot handles billing inquiries, password resets, or appointment scheduling end-to-end, you reduce the number of full-attention agent minutes and the overhead of manual data entry. Integrate the assistant with your CRM and CTI to perform lookups and writebacks so the bot completes work items without creating follow-ups. In practice, a 20–40% containment lift on high-volume intents often translates into measurable reductions in agent headcount needs or enables reallocation of agents to higher-value, revenue-generating tasks.
Beyond raw automation, voicebots improve agent productivity by surfacing context-rich handoffs when escalation is necessary. Instead of transferring a raw audio stream, a well-instrumented system sends the transcript, detected intents, slot values, confidence scores, and recent policy decisions to the agent interface. This pre-filled context shortens wrap time, reduces customer repetition, and raises resolution velocity. For example, in a payment flow we authenticate via DTMF or voice biometrics, collect the billing-period slot, and only escalate with redacted sensitive fields and a clear summary when confidence or sentiment falls below thresholds.
Resilience, compliance, and scalability are additional benefits you realize when the architecture is engineered for enterprise needs. Proper tokenization and selective redaction protect PCI-sensitive data while event logs and policy traces support auditability. Choosing where to run inference — edge for low-latency private deployments or cloud for rapid model updates — gives you operational flexibility and cost control. We also see improved incident response when teams instrument audio quality metrics, ASR WER estimates, and decision logs end-to-end; those signals let you detect regressions and tune models before customers notice.
Building on this foundation, the business case for voice assistants becomes clearer: faster service, lower per-contact cost, better agent experience, and stronger compliance posture. As we move to implementation choices, we’ll evaluate hybrid versus fully managed vendors, the trade-offs of edge versus cloud inference, and how to set up continuous improvement loops so the assistant learns from every interaction. This next step determines whether your voice automation delivers sustained ROI and a genuinely better experience for both customers and agents.
Common Use Cases and Tasks
AI voice assistants and voicebots shine when they take repetitive, predictable work off agent queues and resolve it end-to-end. In practice, that means routing high-volume intents—billing inquiries, appointment scheduling, order status checks—into deterministic flows that combine streaming ASR, NLU, a concise dialogue manager, and natural TTS so customers get an immediate resolution without escalation. Front-loading these tasks reduces wait times and improves containment rate, and it also gives you a controlled surface for model tuning and A/B testing of prompts and confirmations.
Common high-throughput tasks are where you’ll see ROI first: balance inquiries, one-time payments, password resets, appointment management, and simple order changes. These interactions map cleanly to slot-filling patterns in NLU and often require only a handful of confirmations and a single CRM lookup, which keeps policy complexity low and latency predictable. For example, a balance-check flow typically needs customer verification, account lookup via CTI/CRM, and a short spoken summary—each step designed so partial transcripts allow early pipeline actions.
Authentication and sensitive transactions are a specialized but frequent use case in call centers; these require tightly coupled DTMF, voice biometric checks, and tokenization for PCI compliance. Start every payment-capable flow by routing DTMF or a masked entry and applying redaction before storing any transcript. Use explicit confidence thresholds in the dialogue manager: if (nlu.confidence > 0.9 && asr.quality > 0.85) commit the transaction; otherwise confirm or escalate. That simple rule reduces false authorizations while keeping customer friction minimal.
Guided troubleshooting and technical support are ideal for hybrid voicebots that mix deterministic scripts with model-driven intent detection. Begin with a narrow intent set (reset, diagnose, schedule technician), then prompt for device identifiers and reproduce steps while running out-of-band diagnostics via API. If the bot detects repeated low confidence, rising negative sentiment, or an unresolved diagnostic code, transfer with a context package that includes the last 30 seconds of transcript, slot values, and recommended next steps for the agent. This pattern preserves customer trust and shortens agent wrap time.
Transactional automation that integrates with your CRM and backend systems unlocks appointment bookings, refunds, and order modifications without human intervention. Implement connectors that perform idempotent operations and return structured webhook payloads like {“intent”:”refund”,”orderId”:”12345”,”amount”:45.00,”confidence”:0.92} so you can audit and replay actions. Use optimistic writes for low-risk changes and conservative two-step commits for anything that requires manual reconciliation, and instrument every action for observability and rollback.
Beyond direct automation, voicebots support analytics and agent assist use cases that improve long-term performance: real-time whispering of intent and slots to agents, automated call summaries, and post-call surveys triggered by the dialogue manager. These assistive features reduce handle time and surface root causes faster; for instance, automated summaries that include detected intent, confidence scores, and failed prompts let QA teams prioritize model retraining. How do you measure success? Track containment rate, escalation rate, and CSAT for escalations, and tie those metrics back to specific flows to identify improvement opportunities.
Not every task should be automated; high-risk financial changes, complex disputes, or multilingual conversations with heavy noise often need human judgment or specialized models. Building on this foundation, we choose implementation patterns—hybrid versus fully managed, edge vs cloud inference, and continuous improvement loops—based on the risk profile, required latency, and compliance needs of each use case. These design decisions determine whether the voice assistant reduces cost while preserving or improving customer experience, and they set the stage for the concrete implementation choices we’ll examine next.
Technical Architecture and Components
Building on this foundation, the architecture we choose determines whether an AI voice assistant becomes a reliable first line of contact or a frustrating bottleneck. The most common failure mode is latency and context loss created by chopped-up media pipelines, so start by designing end-to-end streaming paths that preserve partial transcripts, timing metadata, and confidence signals. For search and discoverability, emphasize terms like streaming ASR and dialogue manager early in your implementation so telemetry and alerting map cleanly to the components that matter. If you can detect intent before a user finishes speaking, you reduce perceived wait times and increase containment.
Media ingestion and real-time transport are the plumbing that make low-latency voicebots possible. Route SIP or WebRTC into a media gateway that performs codec transcoding, jitter buffering, and voice activity detection so your streaming ASR receives stable audio frames. For scale, separate the media plane (audio streams) from the control plane (webhooks or a message bus) so you can horizontally scale transcoders independently of policy engines. Instrument per-call audio metrics—packet loss, round-trip time, VAD ratio—so you can correlate perceived failures with downstream ASR quality and policy decisions.
ASR and NLU are distinct engineering problems that you must co-optimize for latency, accuracy, and domain coverage. Choose streaming ASR models tuned with domain-specific data and noise augmentation when accuracy on account numbers or product SKUs matters, and consider lightweight on-device or edge models for ultra-low-latency authentication flows. How do you decide where to run inference: edge, private cloud, or public cloud? Base that decision on required latency, data residency, and update cadence—edge for sub-200ms round-trips, cloud for rapid model improvements and centralized telemetry. Continual learning pipelines that re-train on post-call transcripts keep your NLU aligned with changing language and new product names.
The dialogue manager is the brain that turns signals into actions, and choosing a policy architecture affects safety and observability. Blend deterministic flows for high-risk transactions (authentication, payments) with learned or statistical policies for discovery dialogs; keep an explicit context store to persist slots, previous confidences, and recent policy choices. Implement policy decisions as auditable events (for example, {“event”:”policy_decision”,”action”:”escalate”,”reason”:”low_confidence_or_negative_sentiment”}) so you can replay and debug complex handoffs. Use short, testable policy functions that return both an action and a justification string—this makes A/B testing and human-in-the-loop corrections actionable.
Integrations with CTI, CRM, and backend APIs are where automation becomes measurable business value, but they also introduce failure surfaces you must harden. Design idempotent connector endpoints and return standardized webhook payloads such as {“event”:”intent_detected”,”intent”:”balance_inquiry”,”confidence”:0.92,”customerId”:”abc123”} so downstream systems can replay or reconcile actions. Prefer transactional two-phase commits only when you need strict consistency; for many customer-facing writes, optimistic idempotent writes plus compensating actions are safer and faster. Also, ensure your handoff package to agents includes transcripts, slot values, confidence scores, and recent policy traces to minimize customer repetition and shorten wrap time.
Operational resilience, security, and observability close the loop between engineering and ROI measurement. Instrument WER estimates, partial-transcript latency, policy decision latency, containment rate, and escalation metrics at the service level and expose them through dashboards and alerting; couple this with CI/CD for both code and models so deployments are reproducible. Apply tokenization and field-level redaction for PCI/PII, enforce encryption in transit and at rest, and bake regional data residency into your deployment templates. Taking this concept further, embed experiment flags and rollout gates in the architecture so we can iteratively deploy hybrid or fully managed strategies and measure their impact on containment and CSAT before committing to a single vendor approach.
Integrating with CRM and IVR
Building on this foundation, the most fragile part of production voice automation is how your voicebot exchanges context with legacy systems like CRM and menu-driven telephony. When a caller expects the bot to read an account balance or update an appointment, you must complete lookups and writes with sub-second latency and guaranteed correctness; otherwise customers hear delays or repeated prompts. We recommend treating CRM and IVR interactions as first-class, observable services in your call flow so policy decisions can rely on concrete signals rather than best-effort guesses. This reduces escalation friction and preserves containment rate and AHT improvements we’ve already targeted.
Design your integration patterns around two modes: synchronous reads for decision inputs and asynchronous writes for background tasks. Synchronous CRM lookups should return denormalized, cache-friendly payloads (for example, account status, last payment, and preferred language) in a tight JSON contract so the dialogue manager can make deterministic confirmations. For writes that change state—rescheduling an appointment or initiating a refund—emit idempotent webhook actions with an operation ID and use optimistic commit plus compensating actions when strict two-phase commits are too slow. How do you keep these messages auditable? Include a standard envelope like {"event":"intent_detected","operationId":"op-123","customerId":"c-456","payload":{...}} so downstream systems can reconcile and replay safely.
Low-latency media integration with the IVR/telephony layer matters as much as your API contracts. Route SIP or WebRTC through a media gateway that provides both the audio stream to streaming ASR and control hooks into the IVR for DTMF collection or menu fallbacks. When confidence is low or legal flows require touch-tone entry (for PINs, last four digits), switch to DTMF or a deterministic IVR prompt rather than relying solely on speech. Keep the media plane separate from control events so you can transcode and buffer audio independently while the control plane issues CRM queries and policy decisions.
A robust handoff package to human agents is non-negotiable for quality and speed. When escalating, include the last 30–60 seconds of transcribed audio, detected intents and slots, per-slot confidence scores, recent policy decisions, and the CRM snapshot used in the session; present sensitive fields as tokens or redacted values. This package should be serializable and replayable—an example payload could be {"transcript":"...","intent":"billing_inquiry","slots":{"account": "<token>"},"confidence":0.92}—so agent desktops can pre-fill forms and resume without asking the caller to repeat information. Pre-populating context reduces average wrap time and improves CSAT on transfers.
Plan for failures proactively: network blips, CRM timeouts, and inconsistent data models are inevitable. Implement retries with exponential backoff for transient errors, circuit breakers to prevent cascading failures, and deterministic fallbacks that surface minimum viable information to the caller. Instrument correlation IDs across SIP, media gateway, NLU events, and CRM calls so you can trace a single call end-to-end in logs and APM dashboards. Real-time alerts for elevated CRM latency or high write-failure rates let you triage before containment metrics regress.
Security and compliance must be embedded in every integration decision rather than tacked on afterwards. Tokenize and redact PCI/PII at ingestion, encrypt audio in transit and at rest, and ensure CRM writes never store unmasked sensitive entries; maintain audit logs that record both the bot decision and the explicit consent step for transactions. For regulated regions, design the connector to respect data residency: route CRM reads/writes through a regional gateway or a filtered replication endpoint so you meet locality requirements without compromising latency for your primary flows.
Finally, treat these integrations as experimentable components in your continuous improvement loop. Build A/B tests that vary when the bot does a synchronous CRM lookup versus when it prompts, and measure containment rate, escalation rate, and AHT per-flow. As we discussed earlier, telemetry from ASR, NLU, and policy bundles should feed retraining and prompt tuning; extend that telemetry to include CRM success rates and IVR fallbacks so we can prioritize engineering fixes that yield the largest customer-impact gains. This operational feedback closes the loop between integration quality and business outcomes, and it sets the stage for the next implementation choices we’ll evaluate.
Deployment, Testing, and Performance Metrics
Deploying AI voice assistants and voicebots into production is where engineering meets operations: we can train great models in a sandbox, but the real test is reliable behavior across thousands of concurrent callers. Building on the streaming ASR and policy primitives we discussed, start by treating the media plane, control plane, and model inference as independently deployable subsystems so you can scale and iterate without coupling releases. How do you deploy reliably at scale and keep latency predictable? The short answer is: automate everything—CI/CD for code and models, infrastructure-as-code for media gateways and SIP/WebRTC proxies, and rollout gates for model changes.
Choose an environment strategy that matches latency, compliance, and update cadence: cloud for rapid model rollouts, edge for sub-200ms authentication flows, or a hybrid topology when data residency matters. Container orchestration (for example, Kubernetes) becomes the default for policy services, NLU microservices, and connectors to CRM/CTI, while the media gateway often lives on a specialized VM or appliance to handle codec translation and jitter buffering. Build deployment pipelines that separate model artifacts from application binaries so you can A/B test a new streaming ASR model without touching the dialogue manager. We recommend canary deployments and feature flags for policy changes that alter customer-facing prompts or escalation thresholds.
Testing must reflect production signal types, not just unit-level correctness. Unit-test policy functions and NLU slot parsers, then run integration tests that exercise CTI and CRM connectors with synthetic but realistic payloads. For end-to-end validation, replay recorded calls and synthetic audio through the full media pipeline to measure partial-transcript latency, ASR degradation under noise, and downstream policy decisions; incorporate DTMF fallbacks in your test flows. Include chaos and load tests on the media plane—simulate packet loss, jitter, and CRM timeouts—so you can verify graceful fallbacks and circuit breakers before a rollout.
Observability is the backbone of safe rollouts and continuous improvement. Instrument streaming ASR quality estimates (WER proxies), NLU confidence distributions, policy decision latencies, and per-call audio metrics; correlate these with business KPIs such as containment rate, AHT, escalation rate, and CSAT. Surface these signals in dashboards and attach automated alerts to deviation windows (for example, a sustained drop in containment rate or rise in average policy latency). Use correlation IDs across SIP, media gateway, NLU events, and CRM calls so you can trace a single call end-to-end and quickly attribute failures to media, model, or backend errors.
Translate observability into operational SLOs and KPIs that map to business outcomes. Define latency SLOs for partial-transcript availability and end-to-end policy response, accuracy targets for ASR/NLU (WER thresholds and intent precision), and containment rate targets that reflect cost-per-contact goals. Create escalation budgets—acceptable thresholds for transfers to human agents per flow—and tie those budgets to product decisions (for example, relax confirmation logic on low-risk flows to improve containment while keeping high-risk flows conservative). Make SLOs actionable: when an SLO breaches, the pipeline should trigger rollbacks or reduced traffic routing automatically.
Close the loop with continuous improvement: treat every call as training data while respecting privacy and compliance. Sample and redact transcripts for retraining NLU and fine-tuning ASR, and use labeled escalation packages to prioritize model fixes. Run A/B experiments on prompts, confirmation strategies, and model variants while measuring containment rate, AHT, and CSAT per cohort so we know which changes drive business impact. Keep human-in-the-loop workflows for high-impact corrections—QA reviewers should be able to annotate failed flows and feed those labels back into the retraining cycle.
Consider a concrete rollout pattern for a billing flow: stage a new streaming ASR model to 1–5% of traffic, run synthetic and live-canary tests, monitor containment rate and CSAT closely, then incrementally increase traffic with automatic rollback if ASR quality or end-to-end latency regresses. Instrument the handoff package so agent transfers include the transcript, intent, slot confidences, and the CRM snapshot; this reduces wrap time when escalation occurs and gives you high-signal examples for retraining. Taking this concept further, bake experiment flags, rollout gates, and SLO-driven automation into your deployment process so every model or policy change is measurable, reversible, and tied to the metrics that prove ROI.