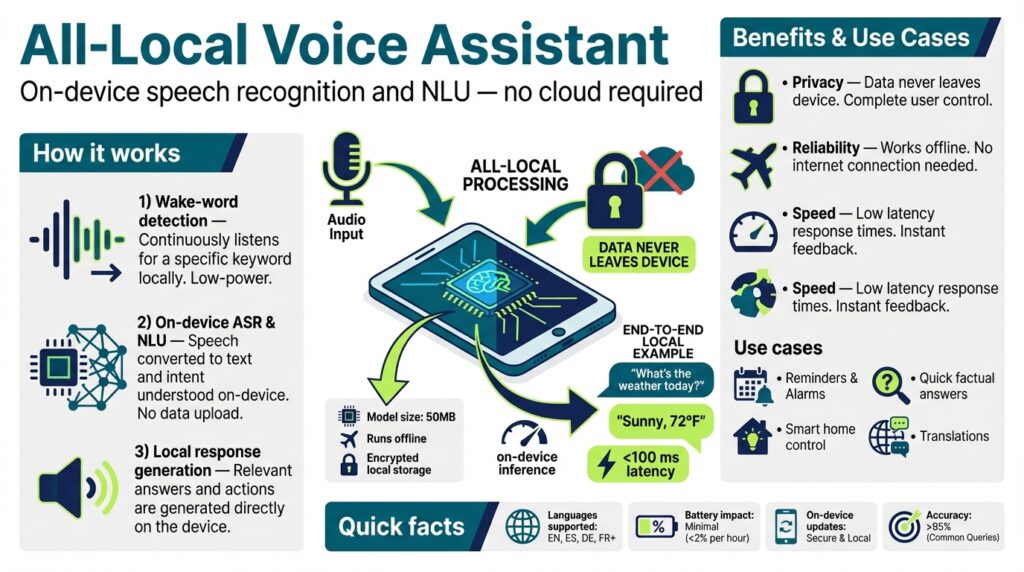
Privacy-first goals and use cases
Building on this foundation, our design starts from a simple premise: keep user speech and derived data on the device unless the user explicitly consents to sharing. Privacy-first and on-device should be front-loaded into every architectural decision because these constraints change trade-offs for latency, model size, and telemetry. By treating audio, transcripts, and interaction history as first-class local resources, we reduce external attack surface and give you deterministic control over data retention and sharing. This approach also improves responsiveness for everyday questions where cloud round-trips add perceptible delay.
A concrete privacy goal is strict data minimization: process only what’s necessary for the user’s request and discard intermediate artifacts unless the user opts in to keep them. Implementing voice activity detection, intent classification, and transient context windows locally means you never write raw audio or full transcripts to persistent storage by default. For example, you can design a pipeline where wake-word-triggered audio is buffered, ASR (automatic speech recognition) runs in-memory, and only the resolved intent or a redacted, user-approved summary is written to local logs. That pattern prevents accidental leakage and makes auditing retention policies straightforward.
Another goal is explicit, discoverable user control over data flows and model behavior. We prioritize affordances that let you toggle local personalization, export or delete on-device profiles, and review past interactions with clear labels like “keeps only for 7 days.” When cloud fallback is necessary—say for complex knowledge retrieval—prompt the user with a one-tap consent flow and show exactly what will be sent. This transparency reduces friction and avoids implicit consent models that create long-term privacy debt for both users and organizations.
What are the practical use cases that justify these goals? Think of a meeting assistant that transcribes sensitive client calls without ever leaving the laptop, a medical dictation tool used in exam rooms where PHI must remain local, or a family device that answers questions for children without profiling across services. Each of these examples benefits from on-device inference for latency and uninterrupted service in no-coverage environments, while preserving confidentiality by default. In enterprise deployments, an all-local voice assistant can comply with internal data residency rules and regulatory constraints without complex VPN routing or specialized networking.
From an engineering perspective, achieving these goals means trade-offs: you’ll optimize models for size and quantization, leverage hardware acceleration where available, and adopt selective cloud options only for non-sensitive tasks. We often apply techniques like model distillation to build compact intent classifiers and use on-device caches for frequent knowledge snippets. For telemetry and improvement, aggregate-only telemetry using differential privacy or local-only evaluation helps you iterate without exposing user-level traces. Secure enclaves and filesystem encryption further harden stored personalization artifacts when they are permitted.
Taking this concept further, prioritize a predictable, testable privacy contract as part of your API and UX. Define clear defaults, instrument consent flows, and provide developer hooks that make it easy to route only whitelisted fields off-device when integrations demand it. Doing so keeps your product aligned with privacy-first goals while preserving the productivity gains users expect from a local voice assistant. In the next section we’ll examine concrete architecture patterns and code-level strategies to implement these controls across platforms.
Hardware and software prerequisites
Building on this foundation, the first practical step is verifying that the target device can meet real-time constraints for an on-device, privacy-first voice assistant. You should treat latency, model size, and data residency as primary constraints when choosing hardware and software, not afterthoughts. How do you pick the right baseline? Start by mapping your common workloads (wake-word, ASR, intent classification, small-context retrieval) to CPU/GPU/accelerator requirements and budget resources accordingly.
For hardware, assume a multitier deployment: constrained edge (Raspberry Pi/ARM SoC), general consumer (laptop/phone), and performance edge (desktop/server with GPU). At minimum for reliable ASR and intent inference plan for a modern multi‑core CPU with AVX2 or NEON support, 8–16 GB RAM, and an NVMe or fast eMMC for swap/cache to avoid blocking I/O. Microphone hardware matters: use 16-bit PCM at 16 kHz (or 16 kHz+ for wideband models) and prefer MEMS arrays for beamforming on noisy devices. For devices that must run larger models locally, target hardware acceleration: CUDA or ROCm GPUs, Apple Neural Engine / MPS on macOS/iOS, or NPU/TPU on Android hardware to reduce inference latency and power draw.
On the software side, choose runtimes and inference engines that match your acceleration targets and privacy constraints. Use an LTS OS image (Linux distribution, recent macOS, or Android/iOS with the appropriate SDK) and a reproducible runtime like Python 3.10+ or a compiled runtime (Rust/Go) if you need deterministic resource usage. Prefer inference backends with quantized model support—ONNX Runtime, TensorFlow Lite, or platform-specific MPS/NNAPI runners—and compatible model conversion pipelines. For wake-word and streaming ASR, open-source engines such as lightweight trigger detectors and small-footprint ASR (or optimized ports like whisper.cpp) let you run everything locally without cloud fallbacks. Example: record and resample audio to a consistent pipeline input using ffmpeg:
ffmpeg -f alsa -i hw:0 -ar 16000 -ac 1 -f wav - | ./streaming_asr
When selecting models, balance model size and precision against latency and accuracy trade-offs. Distill large language or intent models into compact classifiers for routine queries and reserve larger local retrieval models only when hardware allows; otherwise implement explicit cloud fallback with visible consent. Quantize models to int8 or float16 and validate accuracy loss with a representative test suite. Cache frequent responses and embeddings locally to reduce repeated compute, and implement a small in-memory context window for transient personalization so you avoid writing raw audio or full transcripts to disk by default.
Integration and validation are essential: instrument latency and memory usage end-to-end and test under realistic conditions (concurrent processes, power-saving modes, and noisy audio). Add a small timing harness in CI to catch performance regressions, for example a Python micro-benchmark that measures wake-word-to-intent latency and alerts when thresholds are exceeded. Implement graceful degradation strategies: if hardware acceleration is unavailable, fall back to a lower-capacity model or reduced feature set rather than silently sending data off-device.
Finally, harden the platform for privacy-first operation: enforce per-app microphone permissions, keep raw audio in RAM-only buffers, encrypt any persisted personalization blobs, and use platform attestation (TPM, Secure Enclave) for keys where available. Make retention policies configurable and discoverable in the UX so users can disable local personalization or wipe data. For enterprise use, ensure firmware update channels and signed model bundles so devices can receive audited model improvements without compromising on-device guarantees.
Taking these prerequisites seriously gives you a predictable foundation for the next stage: designing pipelines and code-level patterns that guarantee local inference, minimal persistence, and clear consent flows. In the following section we’ll translate these requirements into concrete architecture patterns and implementation snippets that you can apply across constrained and high-performance devices.
System architecture and data flow
Building on this foundation, start by mapping your system into clear functional layers so you can reason about latency, trust boundaries, and where data is allowed to live. We separate capture, preprocessing, inference, retrieval, and output into distinct stages so failures and retention policies are easy to audit. This layered approach makes it explicit which stages run on-device and which (if any) require consented cloud fallback, and it helps you instrument per-stage SLAs and metrics without leaking user-level traces. How do we ensure data never leaves the device without consent?
Begin the runtime flow at the edge with a tiny, always-on front end: a wake-word detector and a short circular audio buffer that keep raw audio in RAM-only. The topic sentence here is that transient buffering prevents accidental persistence; implement wake-word-triggered copies of the in-memory buffer rather than committing streams to disk. Immediately apply voice-activity detection (VAD) and a short in-memory resampling/normalization stage so downstream models receive consistent frames. This minimizes the attack surface, reduces I/O stalls, and ensures that full transcripts are never written to persistent storage unless explicitly approved.
After preprocessing, route audio frames into a streaming ASR and a compact intent classifier that run locally using quantized models and hardware acceleration where available. The main idea is to perform local inference for common queries to satisfy privacy-first and latency goals: use int8 or float16 quantized models in ONNX Runtime, TensorFlow Lite, or platform-specific runners (MPS/NNAPI) to keep latency sub-300ms for short utterances. For more complex language understanding, cascade a distilled on-device language model that emits structured slots and confidence scores; only high-confidence, non-sensitive outputs should be eligible for caching. This staged inference pattern gives you deterministic behavior while containing the size and compute budget of the voice assistant.
When knowledge retrieval or heavy LLM generation is necessary, implement an explicit consent gate and a privacy-aware marshalling layer. The design principle is that any off-device request must be human-approved and scoped: redact sensitive fields, show a one-tap confirmation with exact payload snippets, and log consent events locally. For conditional cloud fallbacks, serialize only whitelisted attributes (intent, query embedding, or redacted text) and tag them with a short-lived request token so that you can revoke or audit transmissions. We recommend an opt-in-only telemetry channel that transmits aggregate metrics with differential privacy rather than raw utterances.
Persisted state should be minimized, versioned, and encrypted with platform attestation to enforce the privacy-first contract. The key point is to treat personalization blobs—voice profiles, short-term context windows, cached embeddings—as first-class encrypted artifacts with configurable retention. Use hardware-backed keys (TPM, Secure Enclave) for encryption and sign model bundles so updates are auditable; provide programmatic hooks to wipe or export data and expose user-facing labels like “keeps only for 7 days.” For offline-first scenarios, maintain a small in-memory context and a capped local cache so that repeated queries hit a local retrieval index rather than a network service.
Finally, design observability and failure modes so you can test privacy guarantees as part of CI and production validation. The concluding point is that predictable data flow demands automated checks: add unit tests that assert no disk writes of raw audio, micro-benchmarks measuring wake-word-to-intent latency, and fuzz tests for consent flows. We instrument aggregate-only telemetry and runtime attestations to validate local inference and signing of model artifacts. Together, these patterns create an on-device, privacy-first voice assistant architecture that balances responsiveness, resource constraints, and transparent user control while making it practical to extend into consented cloud capabilities in a provable way.
On-device speech recognition setup
Building on this foundation, the first practical step is getting a deterministic, low-latency audio pipeline in place so your on-device speech recognition system consistently meets privacy and responsiveness goals. Start with a circular RAM buffer that holds only the last few seconds of raw 16 kHz PCM audio and wire a tiny wake-word detector to copy a short window into a transient inference buffer when triggered. Immediately run voice activity detection (VAD) and normalization on that in-memory copy so downstream models always see consistent frames; this avoids accidental disk writes of raw audio and keeps retention policies enforceable.
Next, architect the streaming path so acoustic features and short-term context never escape volatile memory unless the user explicitly consents. Convert buffered audio into frames and compute the frontend features you plan to use (log-mel spectrograms or filterbanks) in-place, then feed those frames into a streaming ASR and a lightweight intent classifier that produce timestamped tokens and slot values. For many deployments you’ll want a cascaded approach: a compact, quantized ASR handles routine queries and a larger local model is reserved only for edge cases; if cloud fallback is required, gate it behind an explicit consent UI that shows the exact payload being sent.
Model selection and quantization policies determine whether you can hit sub-300ms response times on target hardware. Use post-training quantization (int8 or float16) to shrink model size and improve CPU throughput, and validate accuracy with representative calibration data; TensorFlow Lite and its Model Optimization Toolkit document both dynamic and full-integer quantization approaches for this exact use case. Converting your ASR and intent models to TFLite or ONNX lets you run optimized engines on-device and gives you the option to use hardware delegates for acceleration. (tensorflow.org)
Choose an inference backend tuned to your platform and verify delegate availability at runtime so the assistant gracefully degrades. On Android, the NNAPI delegate can route work to GPU/DSP/NPU when available; on x86/ARM CPUs, ONNX Runtime provides quantization-aware kernels that leverage SIMD and VNNI where present; and community ports like whisper.cpp demonstrate practical on-device ASR performance and Apple Silicon optimizations for local transcription. Detect available providers during startup, prefer hardware-backed delegates for int8/float16 execution, and fall back to a smaller float32 model if no accelerator is present. (android.googlesource.com)
How do you validate this in CI and on real hardware? Add micro-benchmarks that measure wake-word-to-intent latency and memory high-water marks under realistic workloads (concurrent apps, power saving modes, noisy input). Create a small test harness that runs representative utterances through the full pipeline—VAD, resampling, feature extraction, ASR, intent classifier—and asserts there are no writes to disk and that confidence scores exceed application thresholds. Automate calibration runs for quantized models so you catch accuracy regressions early and include a fallback policy that reduces features (e.g., fewer context frames) rather than silently sending audio off-device.
Finally, make the setup auditable and controllable by users and integrators. Expose toggles for local personalization and a one-tap consent flow for cloud fallback, persist only encrypted, versioned personalization blobs under hardware-backed keys, and instrument consent events locally so you can prove whether data left the device. These implementation practices keep your on-device speech recognition predictable, testable, and aligned with the privacy-first requirements we discussed earlier while leaving you room to iterate on models and delegates in future sections.
Local NLU and knowledge retrieval
Building on this foundation, local NLU and knowledge retrieval are the pieces that turn raw transcription into useful, private answers on-device. Local NLU — the compact intent and entity pipelines we run inside the device boundary — must emit structured queries and short embeddings that feed a local retrieval index without ever writing full transcripts to disk. If you care about latency and privacy, you should front-load intent classification, slot filling, and a short-term embedding cache into the first 100–150ms of the pipeline so the assistant can answer routine questions instantly while keeping sensitive data local. How do you design that safely and efficiently for real workloads?
Start by splitting responsibilities between lightweight on-device NLU and heavier retrieval tasks. The NLU components produce three artifacts: a normalized intent label, a set of extracted slots (entities) with confidence scores, and a compact semantic embedding for the user query. These artifacts let you decide whether a purely local retrieval suffices or whether a consented cloud fallback is required. We recommend scoring each artifact with a small policy engine that checks sensitivity, confidence, and freshness before any data leaves the device.
Choose model families and representations that match the device class and privacy constraints. For many consumer devices, distilled transformer encoders or tiny convolutional classifiers are good for slot extraction and intent detection; for semantic similarity use a lightweight embedding model quantized to int8 or float16. Store embeddings in an in-memory or encrypted on-disk vector store and index them with a compact ANN graph (for example, HNSW-like topology) to keep queries sub-50ms on typical laptops and phones. Quantization and pruning let you keep the retrieval model small without sacrificing the semantic signal you need for accurate local matches.
Indexing and document representation matter more than raw model size for useful knowledge retrieval. Chunk documents into semantically coherent passages (200–400 tokens) and attach minimal metadata: source id, timestamp, and a sensitivity tag. When you compute embeddings, also compute a cheap lexical fingerprint for fast filtering so you can avoid ANN lookups for trivial keyword matches. Implement an eviction policy that prioritizes recent, high-confidence snippets and enforces the device’s retention rules—this keeps your local index bounded and auditable under the privacy contract we described earlier.
Privacy-aware retrieval requires explicit consent and redaction gates at the marshalling layer. Before initiating any cloud fallback, present the user a short consent card that shows the exact redacted snippet or the embedding token to be transmitted and the purpose of the request. We prefer transmitting intent/embedding hashes or whitelisted attributes rather than full text; tag each outbound request with a short-lived token that can be revoked or audited. For sensitive domains (health, legal, meetings) default to “local-only” and surface a clear override flow so users understand the trade-off between accuracy and data exposure.
Performance testing and validation should be part of your CI and device qualification suite. Add micro-benchmarks that measure end-to-end time from wake-word to retrieval hit, and synthetic workloads that simulate large local indices and concurrent apps. Validate retrieval accuracy with representative queries and compute false-negative/false-positive rates for both ANN thresholds and lexical filters; when accuracy drops, prefer weakening pagination or reducing context windows rather than silently sending raw audio off-device. Instrument telemetry at the aggregate level only, and use differential privacy for any usage metrics sent back for model improvement.
Consider a concrete example: a meeting assistant that answers “What were the action items from today’s standup?” The local NLU extracts intent=action_items, context=meeting_id, and produces an embedding of the question; the retrieval engine filters the local meeting store by meeting_id, runs a fast ANN lookup across the chunked transcript embeddings, and composes a short structured summary with timestamps and owner slots. If the ANN confidence is low, we surface the partial result and ask the user for permission to enrich the answer with a consented cloud retrieval, showing exactly what will be sent.
Taking this concept further, we’ll translate these patterns into code‑level patterns and platform-specific optimizations so you can implement a deterministic, auditable local NLU and knowledge retrieval pipeline that aligns with the privacy-first goals outlined earlier.
Privacy controls, testing, and deployment
Building on this foundation, delivering a true privacy-first, on-device assistant requires that controls, validation, and rollout be treated as first-class engineering concerns rather than afterthoughts. We start with a clear policy: nothing leaves the device without explicit consent, and every code path that could serialize audio, transcripts, or user profiles is testable and auditable. That policy must be visible in the UI, enforced in the runtime, and codified in CI so you can prove privacy guarantees to customers or auditors. Treat local inference behavior, consent flows, and retention rules as deployable artifacts with versioning and signatures.
Design runtime privacy controls so users can make precise choices and you can automate validation. Building on this foundation, expose toggles for local personalization, a one-tap consent flow for cloud fallback, and fine-grained retention labels like “keeps only for 7 days.” Implement a redaction pipeline that can programmatically redact or hash sensitive slots before any outbound marshalling; store the redaction rules alongside model bundles so tests exercise the same logic production will run. Make consent events immutable audit records on-device so you can answer questions like “what was sent and when?” without ever transporting raw transcripts off-device.
Testing must explicitly assert privacy properties, not only functional behavior. How do you prove no accidental leakage? Add unit tests that assert no_raw_audio_writes() and integration tests that simulate wake-word, VAD, and ASR pipelines under crash and power-loss scenarios to ensure transient buffers never become persistent. Include fuzz tests for consent dialogs—synthesize borderline inputs that trigger cloud fallback and assert the UI shows the exact redacted payload and requires an explicit user action. Automate these checks in CI so every pull request that touches audio, NLU, or marshalling fails if any path can escape the device boundary.
Performance tests should be part of the same harness that validates privacy. We measure wake-word-to-intent latency, memory high-water marks, and delegate availability in reproducible micro-benchmarks so regressions are caught before release; for example, run representative utterances through streaming ASR and the intent classifier and assert sub-300ms median latency on targeted hardware. Include feature-flagged stress runs that disable hardware accelerators to validate graceful degradation: fall back to smaller models locally rather than silently switching to cloud inference. Track confidence thresholds and policy checks alongside timing metrics so policy failures are as visible as performance regressions.
Packaging and rollout must preserve the privacy contract across updates. Sign model bundles and personalization blobs with hardware-backed keys and version them so devices can verify authenticity before loading a new model or policy. For production rollouts, use staged canaries and phased rollouts with revocation tokens embedded in signed manifests so you can quickly recall a faulty model without exposing user data. Maintain reproducible build artifacts for both binaries and quantized model files so security reviews can replay exactly what shipped to a device.
Operational deployment requires secure distribution channels and auditable update flows. Host update manifests on a hardened server, require TLS and signature verification on the client, and include an attestation handshake that proves the device is running an approved runtime before accepting sensitive model blobs. For enterprise devices, support air-gapped update packages and allow admins to opt for out-of-band model approval. Instrument OTA processes so updates report only aggregated health metrics (no utterances) and expose a local admin view that lists installed models, their hashes, and retention policies.
Monitoring and incident response must avoid collecting raw user data while still being actionable. Design observability around aggregate telemetry, deterministic test vectors, and remote attestation checks: collect histograms of latencies, confidence score distributions, and consent-flow acceptance rates with differential privacy, and correlate those with signed model hashes. If you need to debug a specific device, implement a developer-controlled dump that redacts personal content and requires a user or admin signature before it can be exported. How do you prove compliance? Use signed audit logs and attested runtime evidence to show exactly which model and policy were active when a decision occurred.
Finally, treat the lifecycle from testing to rollout as a single pipeline that encodes privacy goals: local inference models, consent policies, redaction logic, test harnesses, signed artifacts, and staged rollouts. We’ll translate these operational patterns into concrete code-level examples and platform-specific deployment recipes next so you can implement verifiable, user-centric controls on-device without compromising responsiveness or developer velocity.



