Define objectives and threat model
Building on this foundation, start by stating concrete goals for the Agentic AI you plan to build: what capabilities it must deliver, what behaviors are strictly disallowed, and which operational constraints will govern runtime. Front-load measurable targets so those goals are actionable—latency SLOs, acceptable PII leakage rates, maximum permitted autonomous actions per hour, and safety SLOs tied to human oversight. We want clarity up-front because every architectural decision (sandbox depth, observability, access control) flows from those goals and the risk appetite you define.
Translate high-level aims into machine-testable objectives that live alongside your code and models. Define functional objectives (tasks the agent must complete), safety objectives (behaviors to avoid), and operational objectives (availability, throughput, observability). Capture these formally—for example, a small objective spec might look like {"goal":"minimize_PII_leakage","metrics":["PII_leak_rate","false_positive_rate"],"thresholds":{"PII_leak_rate":0.0001}}—and tie each metric to automated CI checks and runtime alerts. This approach makes trade-offs explicit and gives you pass/fail signals during integration and deployment.
Map each objective to specific system controls and telemetry so you can enforce and measure them. If an objective is to prevent unauthorized data exfiltration, implement strong RBAC at the API gateway, schema-level encryption on sensitive stores, and model-level input/output scrubbing. For autonomy limits, use rate-limited action queues and capability tokens scoped per agent instance. Instrument everything: request traces, action intents, model explanations, and drift metrics—these are the data streams you’ll use to verify that objectives remain satisfied under load and after model updates.
Construct a practical threat model that enumerates adversary capabilities, protected assets, and attack surfaces relevant to a deployed agentic system. Think like an attacker: network-level adversaries who can intercept API calls; malicious users attempting prompt injection; insider threats with elevated credentials; supply-chain attackers who poison model weights or dependencies. Consider attack vectors such as data poisoning, model inversion/stealing, prompt injection that exploits system prompts, reward-hacking where the agent learns to game its objective function, and lateral movement from compromised agent actions to internal services.
Design mitigations that map directly back to the threat model and your stated objectives, then validate them with adversarial testing. Use focused red-team exercises and automated fuzzing to simulate prompt injection and environment manipulation; run offline replay tests to surface reward-hacking behaviors in simulated feedback loops. How do you prioritize safety goals against performance or utility? Use a risk-priority matrix: classify threats by likelihood and business impact, then assign safety SLOs and required mitigations (block, detect, or recover) proportionate to that risk. Enforce mitigations in CI (unit adversarial tests), at runtime (circuit breakers, canaries), and in deployment policies (least privilege, signed artifacts).
Operationalize the cycle: treat objectives and the threat model as living artifacts that evolve with your system, threat landscape, and model updates. Assign ownership—product for utility objectives, security for threat definitions, and SRE for telemetry and SLO enforcement—and integrate reviews into model release gates and incident retros. This continuous loop ensures decisions about autonomy, observability, and containment are traceable back to the objectives, and it prepares you to iterate on trade-offs as threats and business priorities shift.
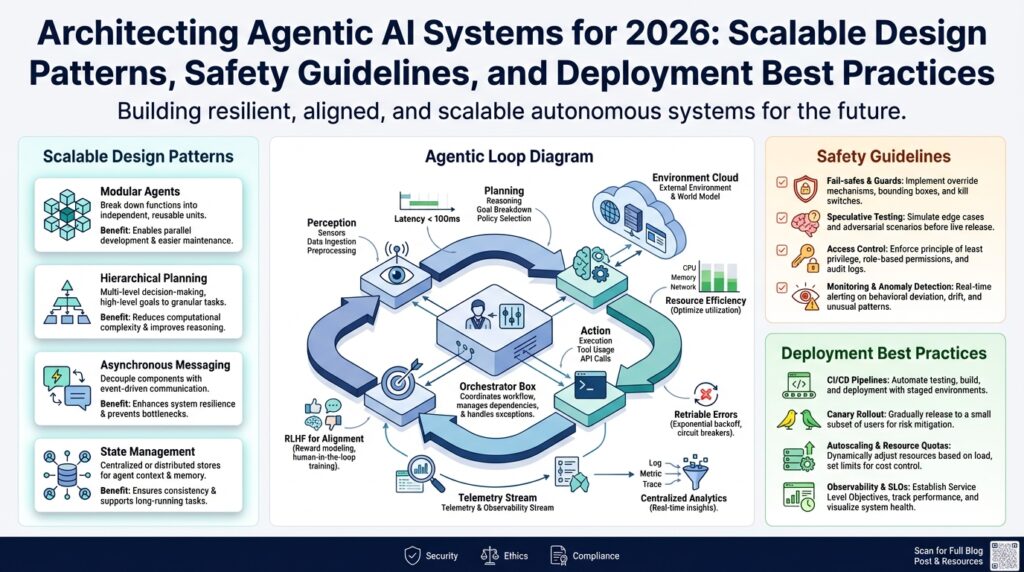
Choose modular agent architecture patterns
Building on this foundation, the first decision you need to make is how to split responsibilities across components so that objectives and threat models map to concrete boundaries. Modular agent architecture and agentic AI design both benefit when you separate reasoning (models), action execution (runtimes), and safety controls (guards) into distinct layers; front-load those terms in your diagrams and code so every team knows which telemetry and SLOs belong where. This separation lets you enforce different operational policies — for example, higher sandboxing for connectors that access sensitive stores and looser latency budgets for ephemeral inference layers. When you treat the architecture as composable modules, you gain the ability to test, iterate, and replace parts without re-certifying the whole system.
Start by choosing a small set of proven patterns and decide which trade-offs you accept: pipeline orchestration for linear, explainable workflows; microkernel or plugin architectures for extensibility; actor or service-oriented models for high-concurrency tasks; and capability-based designs for strict privilege separation. Each pattern has clear implications: pipeline orchestration simplifies audits and tracing but can impose end-to-end latency; a microkernel reduces blast radius for third-party tools but requires a robust plugin contract. Think in terms of responsibilities — who owns intent parsing, who owns action validation, and who owns retries — and pick the pattern that maps those responsibilities to team boundaries and runtime constraints. This decision is guided by your previously stated objectives (latency SLOs, PII leakage thresholds, autonomy caps) and the threat model you built earlier.
Define explicit contracts between modules and enforce them with capability tokens and typed message schemas so you can automate CI checks and runtime guards. A capability token is short-lived, scoped, and signed; handlers check token scopes before performing side effects, and your orchestrator logs token usage for auditability. For example, a minimal dispatch pattern looks like the following:
# pseudo-code: dispatch with capability check
if verify_token(token, required_scope='write:orders'):
result = order_handler.handle(intent, metadata)
else:
raise PermissionError('insufficient capability')
This pattern enforces the mapping from objective to control: if preventing unauthorized exfiltration is an objective, tokens and schemas become non-negotiable.
How do you compose models and tools safely while maintaining throughput and evolvability? Use a model orchestration layer that routes requests to specialized models or tools based on intent classification, confidence thresholds, and runtime safety gates. Implement staged execution: a fast, low-cost model drafts an action; a safety filter rewrites or rejects dangerous responses; a guarded executor performs side effects with audited capability tokens. Model orchestration needs its own telemetry—latency, confidence, rewrite counts—so you can detect drift and measure whether orchestration decisions meet your safety SLOs.
Instrument modular components heavily so observability maps back to your objectives and threat model. Tag traces with objective IDs (e.g., minimize_PII_leakage) and capture the decision path: which model generated the intent, which safety rule fired, which capability token was used. Run canary deployments and shadow mode for new modules: execute actions in a read-only way to collect behavioral metrics and adversarial test coverage before allowing full autonomy. These practices turn abstract goals into actionable signals you can automate in CI and runtime alerting.
Finally, pick patterns that reflect operational realities: prefer plugin/microkernel if you expect many third-party integrations, actor models for high-concurrency user-facing agents, and pipeline orchestration when auditability outweighs microsecond latency. Weigh complexity against safety: more modularity buys replaceability and smaller blast radius, while tighter coupling can simplify performance tuning and reduce message hops. As you implement modules, keep your team boundaries, CI gates, and telemetry aligned so each change has traceable impact on the objectives you defined earlier, and so your system can evolve without sacrificing the safety guarantees you need.
Design planning, memory, and control loops
Building on this foundation, start by treating agentic AI as a control system where design planning, memory, and control loops are first-class artifacts you design, instrument, and test. We need clear choices about what the agent must remember, for how long, and what automated controls will act on those memories; otherwise drift and reward-hacking hide in the noise. How do you choose retention policies that satisfy safety SLOs while preserving utility? We’ll show concrete patterns you can implement today and validate through telemetry and CI gates so the trade-offs are explicit and auditable.
Design planning begins with mapping each objective to a memory requirement and a control surface. For every functional or safety objective you defined earlier, ask: does the agent need working memory (short-term conversational state), episodic memory (past interactions tied to a user or session), or a long-term knowledge base (static facts, policies)? Episodic memory is the record of past decisions and observations that support explainability and post-hoc auditing; define its schema, TTL, and cryptographic protections up front. When you declare these mappings during design planning, you make downstream choices—storage type, encryption, access scope, and retention—testable and reviewable by security, product, and SRE teams.
Next, implement memory as a tiered service with explicit interfaces and capability checks. Use fast in-memory context stores for working memory, a vector store for embeddings-based retrieval, and an encrypted object store for high-fidelity episodic logs. Provide a small, typed API: append_memory(session_id, type, vector, metadata) and query_memory(session_id, query_vector, filters), and require short-lived capability tokens for writes and reads. Enforce schema-level scrubbing on write for fields marked as PII and add a summarization job that compacts older episodes into redacted summaries to reduce retention risk while preserving auditability.
Control loops must close the gap between observed behavior and objectives by monitoring signals and actuating policy changes. Implement closed-loop controllers that consume telemetry—intent confidence, policy violations, rewrite counts, PII_leak_rate—and compute corrective actions: throttle autonomy, escalate to human review, or revise memory retention. For example, a runtime loop can check a rolling PII_leak_rate and trigger a capability revoke when thresholds breach: the loop reads metrics, evaluates a condition, and pushes a signed policy change to the orchestrator. Keep the control logic auditable and testable with unit adversarial tests that simulate prompt injections and reward-hacking vectors.
Tie memory and control loops together for continuous safety and adaptability. Use drift detectors on embeddings and intent distributions to detect when retrieval quality or safety filtering degrades; when drift exceeds a configured boundary, trigger a canary redeploy, a memory re-index, or a model rollback. In practice, you might surface a human-in-the-loop path: low-confidence retrievals open a review task that both updates episodic memory with a verified label and informs the control loop to reduce autonomy until retraining completes. This pattern prevents silent accumulation of harmful behavior and makes remediation part of routine operation rather than an emergency fix.
Operationalize observability so you can prove the design planning decisions worked in production. Tag traces with objective IDs, record memory access patterns, and store control loop actions with timestamps and signed tokens. Run shadow-mode experiments for new memory compaction and safety rules: execute them in read-only mode, collect metrics, and compare business utility versus safety gains before switching to active enforcement. By doing this we create a repeatable, auditable lifecycle where memory, controls, and models evolve together under the governance constraints you defined earlier—making the agent robust, explainable, and aligned with your safety SLOs.
As we move into orchestration and deployment patterns, keep these implementation primitives—tiered memory, typed interfaces, capability tokens, and closed-loop controllers—ready as building blocks. They let you reason about autonomy limits, forensic requirements, and upgrade paths in concrete terms, and they provide the hooks we use later when integrating model orchestration, canaries, and policy-as-code into your release gates.
Implement safety gates and governance controls
Building on this foundation, start by treating runtime safety as a first-class engineering surface: we need enforceable, testable gates between intent and action that map directly to the objectives and threat model you already defined. Front-load runtime safety and governance controls in your architecturally visible diagrams and instrument every gate with the same objective IDs you used for telemetry. This makes it straightforward to measure the effectiveness of each control (for example, PII_leak_rate or autonomy_action_count) and to tie failures back to a bounded component for remediation.
Design layered runtime filters that operate at increasing levels of privilege: a fast input sanitizer for prompt injection, an intent classifier that attaches a confidence score and objective tags, and a capability verifier that enforces least privilege before any side effect. Implement policy-as-code (expressing access and safety rules as executable, version-controlled artifacts) so rules evolve in CI like software. For capability enforcement, use short-lived, signed tokens checked at the executor; for example, if verify_token(token, scope='write:orders'): execute()—this pattern gives you auditable, revocable privileges that the orchestrator can update in seconds.
Make the execution pipeline staged and observable so each gate produces concrete signals you can act on. Route requests through a draft model, then a safety filter that either rewrites, rejects, or flags actions based on rule evaluation and confidence thresholds. Log the decision path—which model, which rule fired, which token was used—and emit metrics such as rewrite_rate and gate_reject_rate. These signals let closed-loop controllers decide whether to throttle autonomy, rollback a model, or open a human review ticket before the agent touches production systems.
Operational governance must combine automated enforcement with traceable human review and immutable audit trails. Record signed tokens and policy changes in append-only logs (cryptographically verifiable where regulation requires) and tie them to CI artifacts so you can correlate a runtime decision with the exact policy revision that enabled it. Use role-based access controls and environment separation—read-only shadow mode for new rules and canary deployments for policy rollouts—to reduce blast radius. In CI, codify safety SLOs: a policy merge should fail if test suites show a PII_leak_rate above threshold or if adversarial tests find prompt-injection paths.
What should trigger human intervention versus automatic remediation? Define that threshold explicitly in your governance controls and encode it as part of the control loop: low-severity anomalies (minor divergence in intent confidence) can be handled by throttling or sandboxed rewrites, while high-severity breaches (data exfiltration, unauthorized execution) should revoke capability tokens and spawn incident workflows. Build revocation into the token model—tokens should be short-lived and support immediate invalidation—and automate escalation: a controller detects a breach metric, revokes tokens, creates a forensics snapshot, and opens a human review with the relevant traces attached.
Taking this further, integrate policy telemetry into your model orchestration so safety gates feed the same drift detectors and canary logic used for model upgrades. When a gate’s reject_rate or rewrite_rate drifts above its baseline, trigger a shadow-mode rollback or retraining canary rather than full production release. By tying policy-as-code, capability tokens, closed-loop controllers, and auditable logs together we create governance controls that are testable in CI, enforceable at runtime, and reversible in minutes—giving us measurable safety without permanently stalling autonomy. As we move into orchestration and deployment patterns, these controls become the hooks we use to automate release gates and incident remediation.
Scalable orchestration and runtime monitoring
Building on this foundation, the practical challenge is turning intent routing and safety gates into a resilient, scalable orchestration fabric that also gives you actionable runtime monitoring from day one. Orchestration and runtime monitoring are the twin controls that let an agentic system scale without losing sight of the objectives and threat model we already defined; put those words up front in your diagrams, and make them first-class telemetry labels. How do you detect an autonomy breach in production before it affects customers or sensitive data? Instrumentation and an orchestrator that understands policy scopes is the answer.
Start by treating orchestration as a policy-aware router rather than a dumb dispatcher. Orchestration here means deciding which model or tool will handle an intent, applying safety transforms, and awarding short-lived capability tokens to the executor; runtime monitoring means collecting traces, metrics, and audit events that map back to objectives like PII_leak_rate and latency SLOs. Building on the capability-token and module-contract patterns we discussed earlier, ensure the orchestrator records every decision path—model selection, safety rule outcomes, token scopes—so runtime monitoring can answer not only what happened, but why.
Make staged execution the default. Route each request through a lightweight intent classifier, then a draft model, then a safety filter, and finally a guarded executor that performs side effects only with a verified token. Implement the pipeline as explicit steps with observable boundaries so you can insert canaries, shadow mode, or additional checks without touching core logic. Example pseudo-flow:
# staged execution pseudocode
intent = classify(input)
draft = draft_model.generate(intent)
safe, rewrite = safety_filter.evaluate(draft)
if safe and verify_token(token, scope):
executor.execute(rewrite or draft)
else:
audit.log_block(intent, draft, rewrite)
This pattern keeps orchestration logic simple and makes runtime monitoring actionable because each stage emits consistent events you can aggregate.
Design your monitoring to tie directly to the objectives you already declared. Instrument distributed tracing for decision paths, emit metrics like gate_reject_rate, rewrite_rate, action_latency, and PII_leak_rate, and capture telemetry for capability token issuance and revocation. These signals let a closed-loop controller correlate performance and safety: rising rewrite_rate with stable latency may indicate overcautious rules, whereas rising PII_leak_rate requires immediate capability revocation. Tag every trace and metric with objective IDs and module names so alerts point to a narrow remediation surface rather than an amorphous “agent” problem.
Operationalize orchestration using container orchestration and sidecar patterns for observability. Run model inference and executors in scalable pods managed by a container orchestration platform, attach observability sidecars to collect logs and metrics, and optionally use a service mesh to centralize telemetry and enforce network-level policies. Use shadow mode and canary rollouts to validate new models or safety rules under production-like load: shadow traffic exercises the orchestrator and produces the runtime monitoring data you need to decide whether to promote or rollback.
Close the loop with automated remediation that acts on monitoring signals. Implement controllers that evaluate rolling-window metrics and execute auditable actions: throttle autonomy, revoke capability tokens, open human-review tickets, or roll back to a canary. Keep the control logic small, testable, and versioned in policy-as-code so you can run adversarial tests in CI. For example, a controller could revoke write-scoped tokens when PII_leak_rate > threshold for N minutes, snapshot recent traces for forensics, and reduce autonomy to read-only while the incident is reviewed.
Taken together, scalable orchestration and rigorous runtime monitoring turn abstract safety SLOs into enforceable, observable operations. When orchestration emits consistent decision events and monitoring maps those events to your objectives, you gain the ability to scale agents with predictable safety behavior and fast, auditable remediation. As we move into deployment-specific patterns, keep these primitives—staged execution, tokenized capabilities, container orchestration, and objective-tagged telemetry—ready as the hooks you will use to automate release gates and incident response.
Deployment, CI/CD, and incident response
Building on this foundation, safe deployment, CI/CD, and incident response must be treated as a single, tightly governed lifecycle rather than discrete handoffs. If you can’t answer “How do you promote a model and a policy together without increasing PII_leak_rate?” before pushing to prod, your pipeline is incomplete. We’ll assume your orchestrator emits objective-tagged telemetry and your modules use short-lived capability tokens; now we focus on the concrete pipeline, automated gates, and the incident workflows that close the loop when things go wrong.
Start deployment with staged rollouts that mirror the staged execution we described earlier: shadow mode, canary, limited autonomy, then full promotion. In practice, that means your CI pipeline produces a signed artifact bundle containing model weights, policy-as-code, and capability-token manifests; your CD system deploys the bundle to an isolated canary namespace, routes a small percentage of production traffic through the orchestrator, and runs shadow traffic against the previous version to compare rewrite_rate, gate_reject_rate, PII_leak_rate, and latency SLOs. Because the bundle contains policy and policy tests, you can fail the merge if adversarial CI tests raise the PII_leak_rate above threshold or if prompt-injection fuzzers find a regression.
Make CI/CD pipelines objective-aware by encoding SLO checks and adversarial tests as first-class build steps. Implement unit adversarial tests that simulate prompt injection and reward-hacking scenarios and add an integration stage that replays sampled production traces in a sandbox; fail the pipeline when safety SLOs are violated. Use policy-as-code to version rules alongside code—your pipeline should run rule lints, static analysis, and runtime replay tests that assert gate_rewrite_count and token issuance logs match expectations. Keep artifact provenance auditable: sign the bundle, store hashes in your artifact registry, and require those hashes for token issuance during deployment so the orchestrator only grants capabilities to verified releases.
Operationalize canaries with automated promotion and rollback logic tied to rolling-window metrics. For example, configure a controller that promotes a canary when gate_reject_rate and PII_leak_rate remain within baseline for a rolling 30-minute window and that automatically revokes write-scoped tokens and rolls back on breach. Implement the controller as small, testable policy code: evaluate metrics, snapshot recent traces for forensics, revoke tokens, and reduce autonomy to read-only. This pattern reduces blast radius because capability revocation is immediate and auditable, and because your orchestrator logs the exact token and policy revision that enabled the action.
What happens when an incident still occurs? Your incident response must combine automated containment with a rapid human workflow. When an automated controller detects a safety SLO breach, it should: 1) revoke affected tokens, 2) snapshot and seal decision traces and memory access logs in an append-only store for forensics, 3) shift traffic to the previous verified bundle or to a read-only mode, and 4) create a high-priority incident with contextual traces, objective IDs, and the policy revision attached. That incident should spawn a runbook with clear ownership (SRE for containment, Security for forensics, Product for impact), and the first human steps should validate whether the breach was model drift, policy regression, data poisoning, or an orchestration misconfiguration.
Post-incident, feed findings back into CI so the next pipeline run prevents recurrence. Convert the forensics into targeted regression tests and adversarial test cases, tighten policy-as-code where necessary, and use the artifact provenance to track whether a bad bundle slipped through signing gates. Run a blameless postmortem that produces a concrete list of CI changes, rollout criteria adjustments, and additional observability (for instance, adding objective-tagged alarms for memory-access patterns). Finally, version the updated runbooks and test harnesses so incident response becomes a repeatable, auditable part of your CI/CD lifecycle.
Taking these practices together makes deployment an activity you can measure, automate, and revert quickly: objective-aware pipelines, signed bundles that include policy, canary promotion logic tied to safety metrics, and incident response playbooks that combine immediate automated containment with short, actionable human workflows. As we move into detailed orchestration patterns and runtime monitoring, keep these primitives—signed artifacts, capability tokens, objective-tagged telemetry, and policy-as-code—ready to plug into your orchestrator so promotion and remediation remain fast, safe, and auditable.



