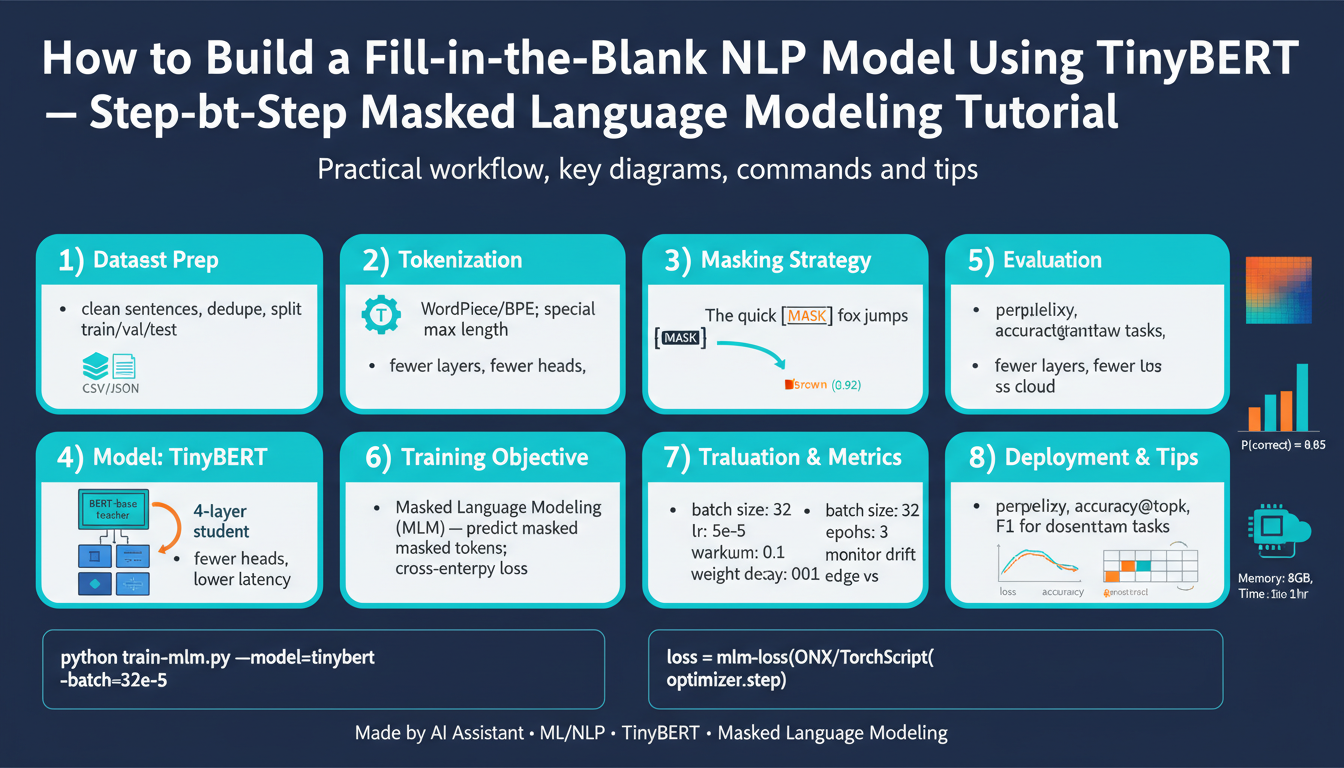
How to Build a Fill-in-the-Blank NLP Model Using TinyBERT — Step-by-Step Masked Language Modeling Tutorial
Prerequisites and environment Building on the concepts we introduced earlier, you should arrive here with the goal of training a […]
Prerequisites and environment Building on the concepts we introduced earlier, you should arrive here with the goal of training a […]
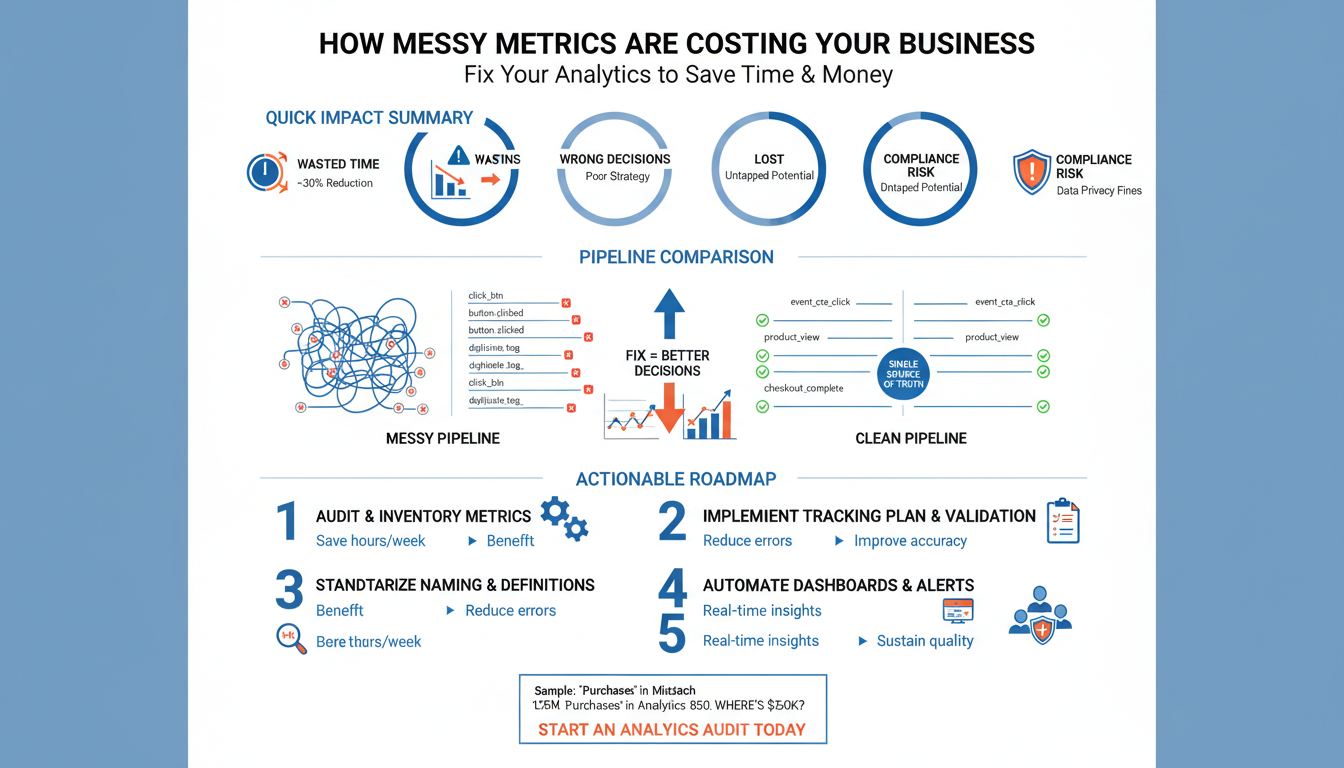
Recognize Messy Metrics Symptoms Messy metrics are rarely obvious until they cost you time, credibility, and budget—and by then remediation
How Messy Metrics Are Costing Your Business – Fix Your Analytics to Save Time & Money Read More »
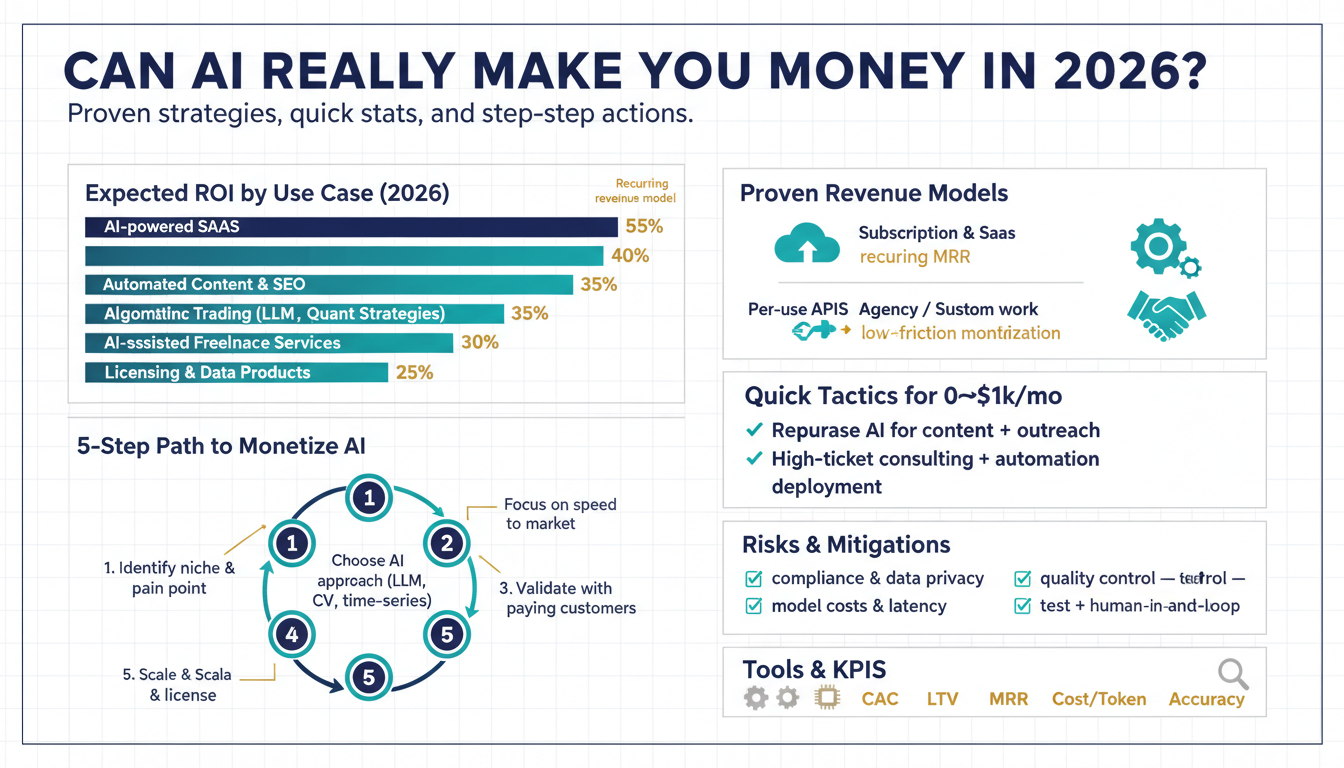
Why AI profits in 2026 Building on this foundation, the business case for AI profits is now concrete rather than
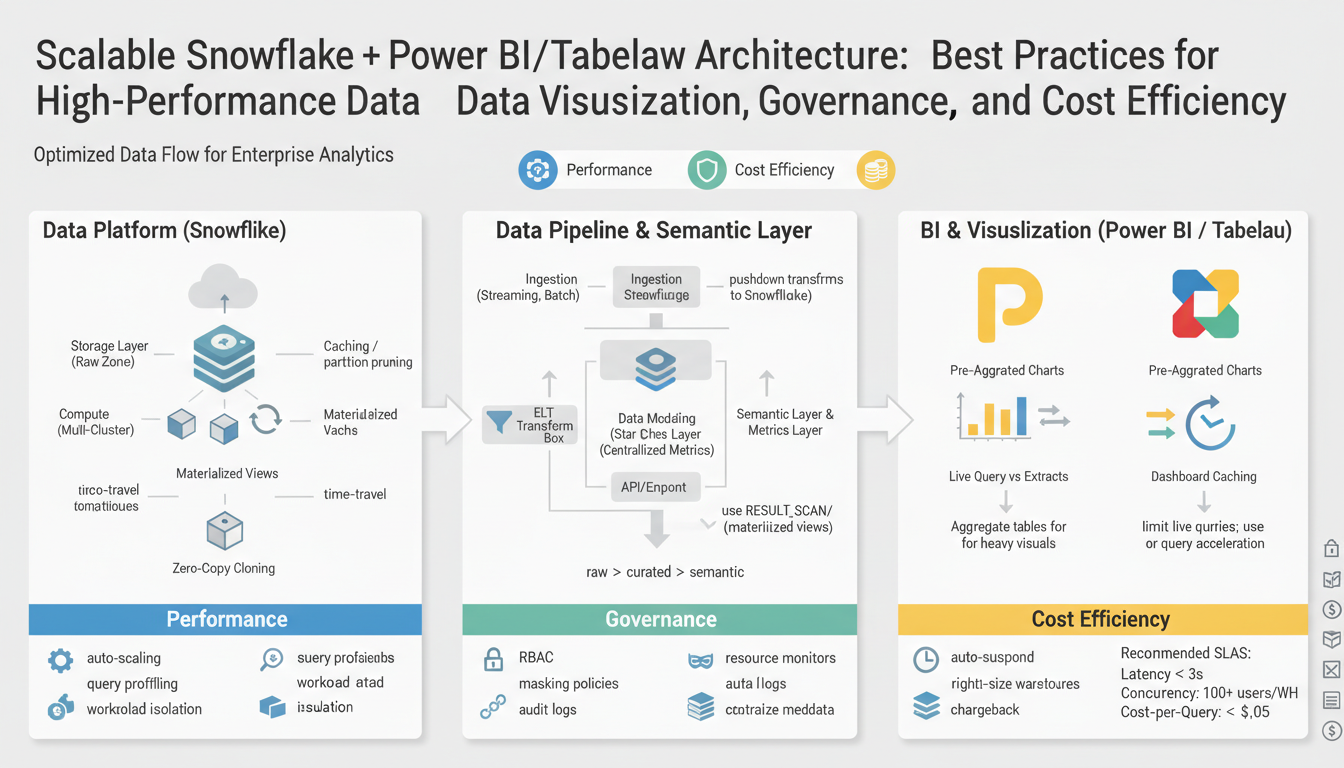
Objectives and Success Criteria Building on this foundation, our immediate priorities center on Snowflake-driven data pipelines feeding fast, governed visualizations
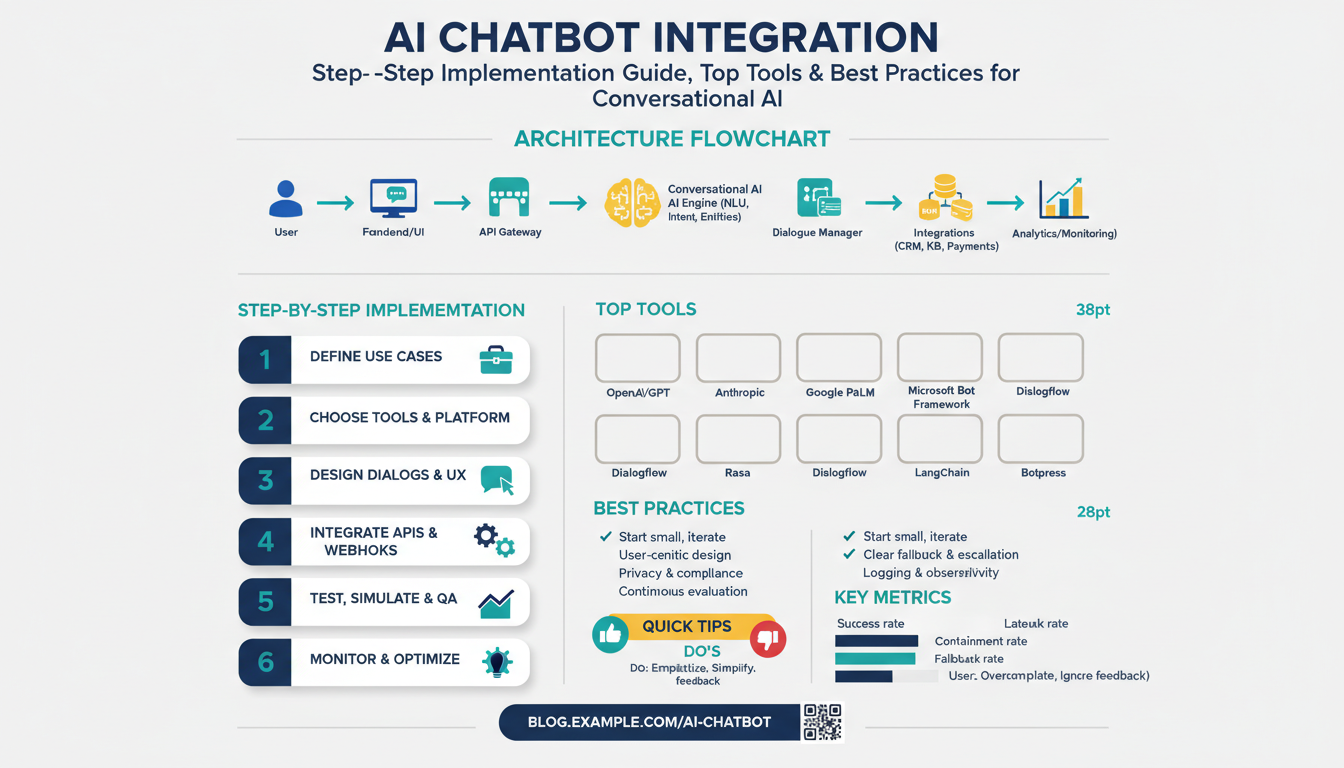
Define goals and target users If your AI chatbot integration doesn’t start with clear, measurable goals and well-defined users, you

Why Database Schema Design Matters When your app slows to a crawl under real traffic, the problem often isn’t the

2025 Breakthrough Timeline Building on this foundation, 2025 was the year ChatGPT moved from a viral chatbot into a platform

Framing the Stochastic Parrot Critique Building on this foundation, we need to frame the debate that reduced large language models

Why Look Beyond Scikit-Learn Building on this foundation, you need to be deliberate about tool choice because Scikit-Learn was designed