
Database Normalization Explained: Practical Guide to 1NF–5NF for Efficient, Scalable Schema Design
Why Normalize Your Schema Data redundancy is a silent productivity tax: it makes writes brittle, increases storage and backup time, […]
Why Normalize Your Schema Data redundancy is a silent productivity tax: it makes writes brittle, increases storage and backup time, […]
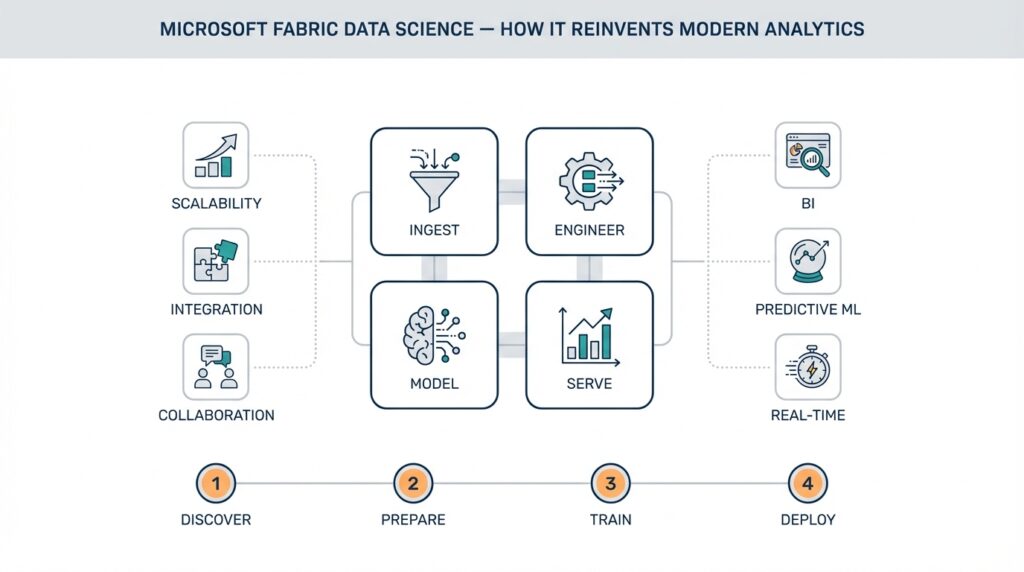
Microsoft Fabric Data Science: Quick Overview Microsoft Fabric Data Science puts an end-to-end data science environment where you can move
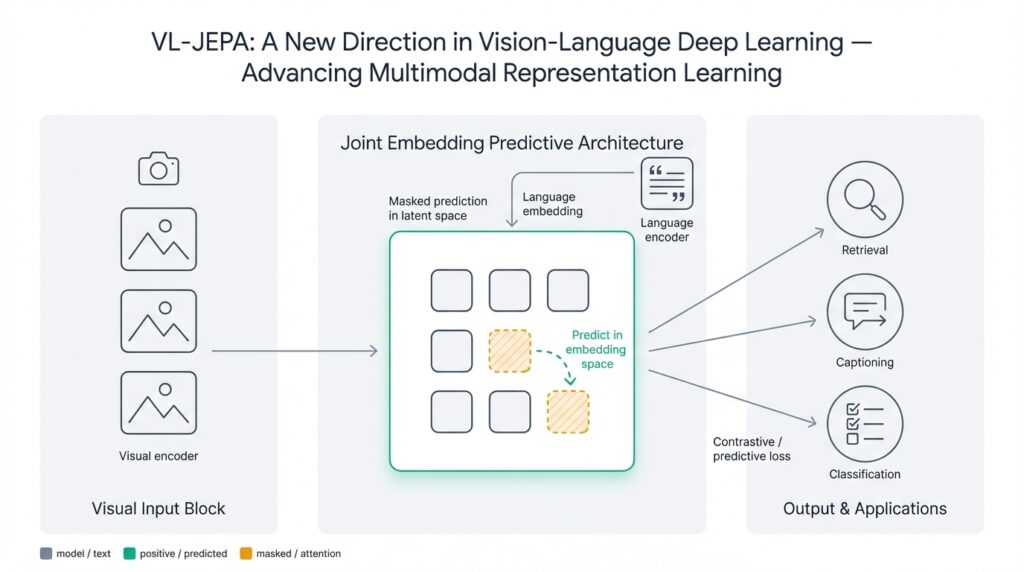
VL-JEPA overview VL-JEPA rethinks how we learn joint image-text representations by predicting high-level targets in embedding space rather than forcing
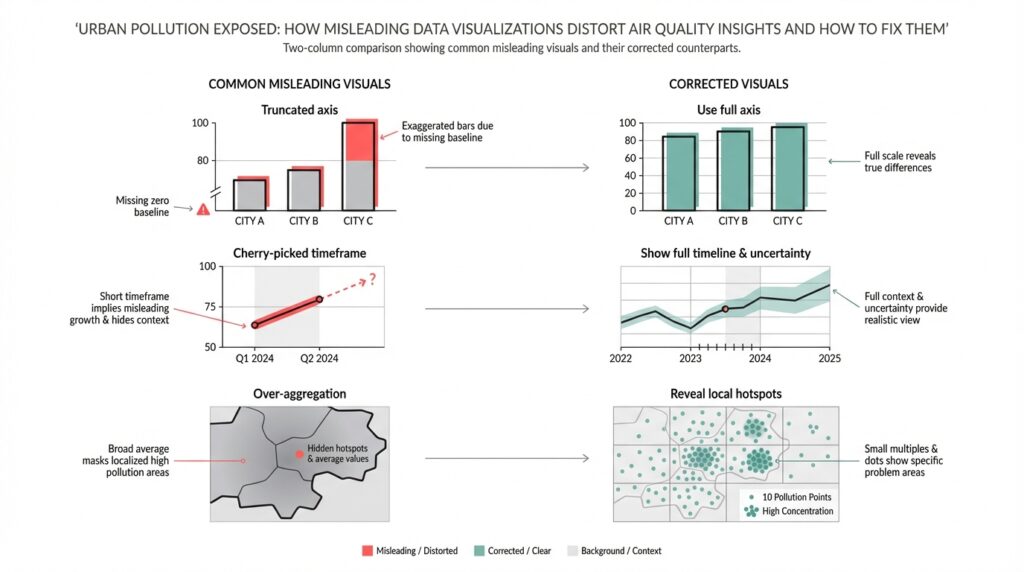
Why air-quality visuals often mislead Building on this foundation, think of most public dashboards as persuasive summaries rather than raw
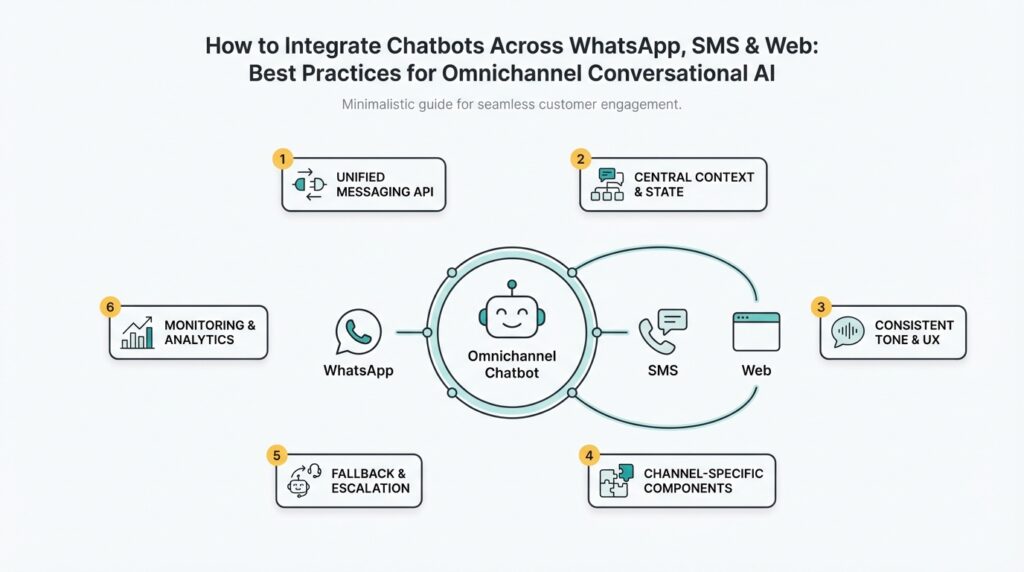
Define Omnichannel Goals and KPIs Building on this foundation, the first priority is translating business outcomes into a small set

Use virtual environments Keeping your project’s runtime predictable is one of the fastest wins for delivery velocity—virtual environments give you
8 Python Productivity Hacks to Accelerate Data Science Project Delivery Read More »
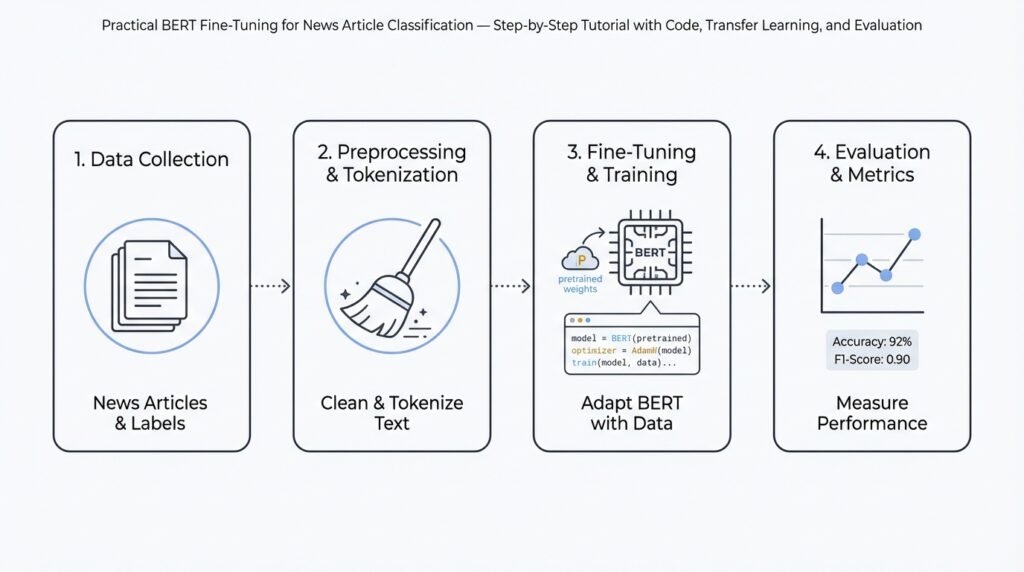
Prerequisites & Environment Setup Building on the high-level motivation for transfer learning in our previous section, we first make the
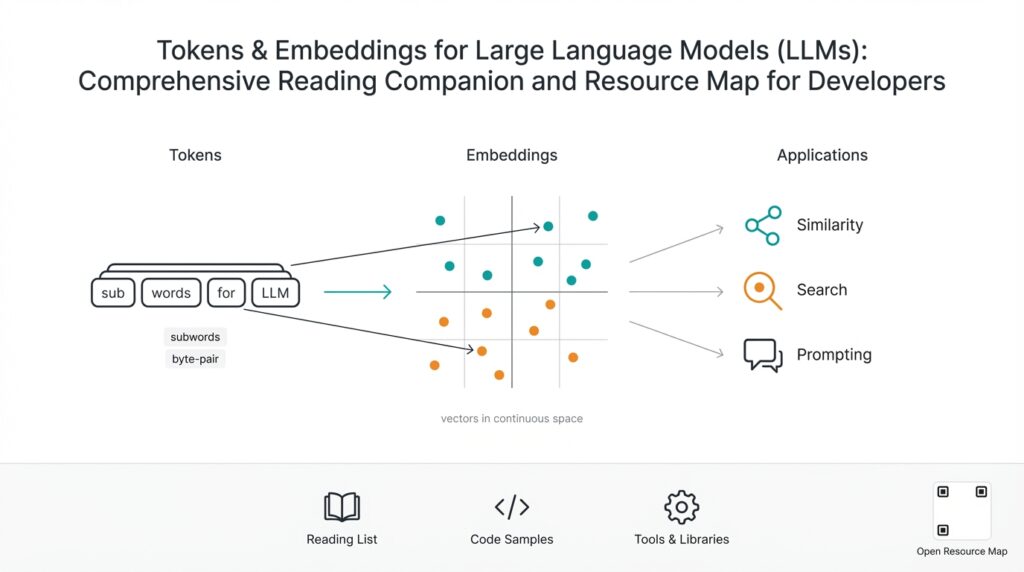
Why Tokens and Embeddings Matter Building on this foundation, understanding tokens and embeddings is the practical difference between a model
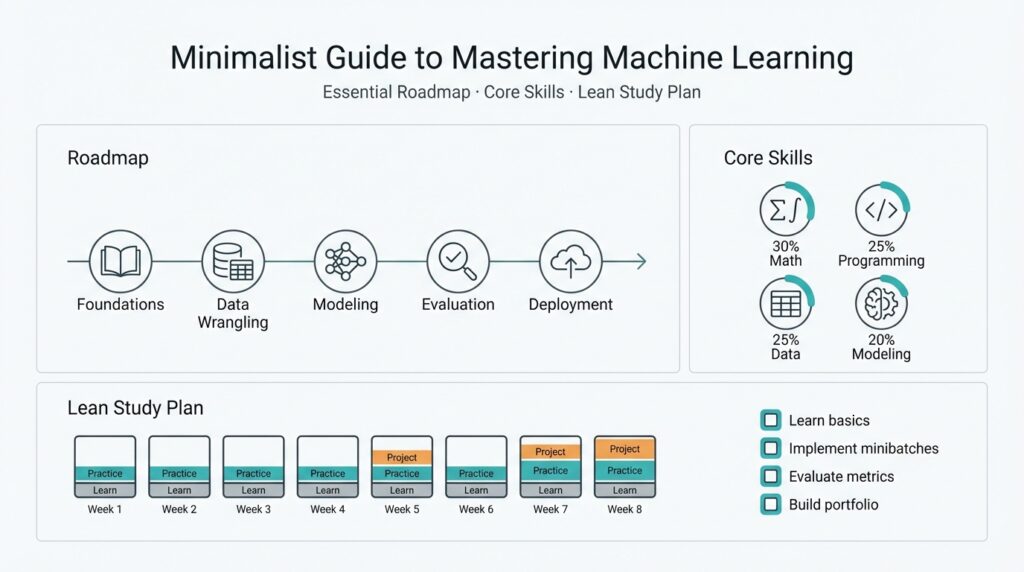
Quick Roadmap Overview Building on this foundation, think of our approach as a compact machine learning roadmap that focuses on