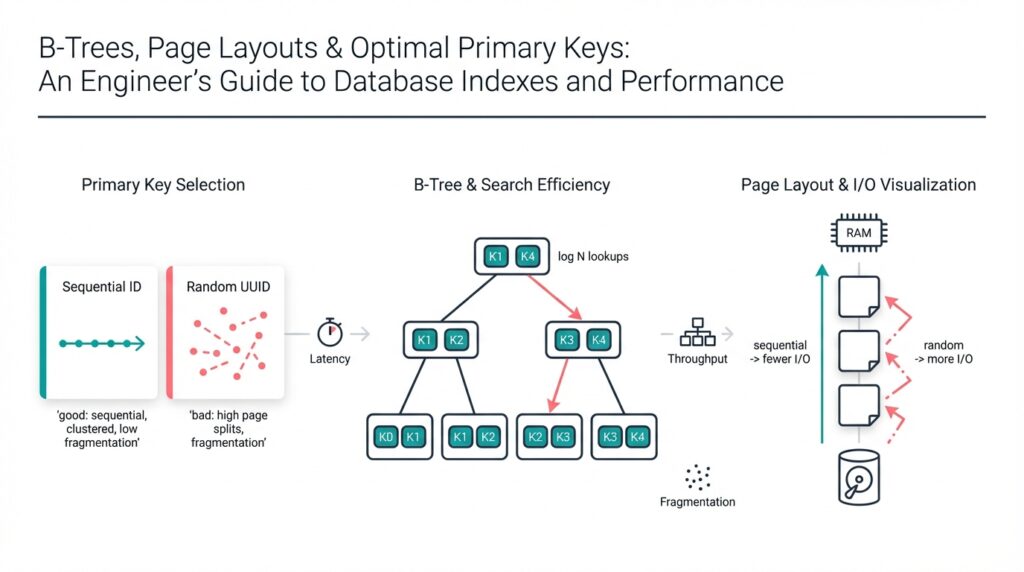
B-Tree Structure
Building on the foundation we set earlier about indexes and page layouts, we’ll examine how a B-tree organizes keys and pointers to optimize disk-based lookup and range scans. A B-tree (balanced tree) stores many keys per node so that tree height stays small even for very large data sets; this low height minimizes random I/O, which is the dominant cost for OLTP and analytic workloads. In practical database engines the term index appears often here: the B-tree is the canonical on-disk index structure because it packs multiple index entries into a single page and exploits locality.
A node is the primary unit of storage and should map to your database page size. Internal nodes hold key separators and child pointers; leaf nodes hold the actual (key, row-pointer) entries or dense key-value tuples depending on the implementation. We define order (m) as the maximum number of children an internal node can have; in practice you calculate m from page_size, key_size, pointer_size, and a modest header. For example, given a 4096-byte page, 8-byte pointers, and 16-byte average keys, the rough fanout is:
fanout ≈ (page_size - header) / (key_size + pointer_size)
fanout ≈ (4096 - 64) / (16 + 8) ≈ 250
This high fanout keeps tree height very low—often 2–4 levels for billions of rows—so your index lookups touch only a few pages.
Nodes remain balanced by design: splits and merges keep occupancy within bounds so we avoid pathological tall trees. When a leaf overflows, the engine splits it and promotes a separator into the parent; when underflow occurs after deletes, the engine borrows from siblings or merges nodes. These invariants mean that worst-case search, insert, and delete complexity is O(log n) in node-operations, but more importantly for real systems, the number of I/O operations stays bounded. We should also consider write amplification: inserts that trigger splits propagate up and may cause page writes; compacting and free-space choices affect throughput, so choose node fill thresholds to balance read vs write performance.
Leaf layout decisions matter for common access patterns. If you store (key, rowid) tuples in leaves you get compact indexes and efficient point lookups; if you store the whole row in leaf entries (clustered index) you optimize primary-key scans at the cost of index size. Range queries benefit from linked leaf pages or sibling pointers because the engine can follow sequential pages with prefetch-friendly access. How do you pick between a clustered and non-clustered layout? Measure expected read patterns: frequent full-row scans with ordered predicates favor clustering, while write-heavy workloads and small point lookups often prefer a narrow non-clustered index.
Concurrency and crash-recovery interact with structure decisions. Modern engines use latch-free or fine-grained latching and logical logging to allow concurrent modifications without holding global locks on the tree; atomic updates to a node and durable WAL (write-ahead log) ensure consistency across crashes. For example, latch-coupling (hand-over-hand locking) can be replaced with optimistic concurrency and versioned reads to reduce contention on root and upper-level nodes during heavy inserts. We therefore choose page sizes and fanout to reduce the rate at which many transactions touch the same high-level node.
Finally, think about tuning: increase page size or reduce key width to raise fanout and lower height, but watch cache efficiency—bigger pages mean fewer pages fit in memory. We should profile using representative data distributions rather than synthetic uniform keys, because skewed keys trigger hot splits and uneven node occupancy. Taking this concept further, the next section will show how page layout choices and primary-key selection change the arithmetic we just used and what that means for index maintenance and query latency.
Leaf vs Internal Pages
Building on this foundation, think about internal pages as the compact, high-level roadmap and leaf pages as the dense, I/O-facing storage surface in the B-tree. If you care about lookup latency and cache efficiency, these two page types behave very differently and require different tuning. How do you tune page layout and primary keys so that internal pages stay small and hot in memory while leaf pages serve sequential scans efficiently? Framing that tradeoff up front helps you make choices that directly reduce I/O, contention, and write amplification.
Internal pages are hot on almost every lookup because they form the path from root to leaf; keep them cache-resident and you chop latency for millions of point reads. By contrast, leaf pages absorb bulk of range scans and writes, so they should be optimized for sequential throughput and compact packing. Because internal pages contain separators and child pointers rather than full row payloads, compression strategies like prefix compression yield large wins there; this increases fanout and lowers tree height, reducing how many internal pages you need to keep pinned. We therefore prioritize narrow keys and effective compression for internal pages, while optimizing leaf pages for density and prefetch-friendly layout.
Leaf pages and internal pages differ in how they grow and fragment under writes. Leaf pages split frequently during high write rates because they hold dense tuples or row pointers; these splits create sibling chains and change the I/O pattern for subsequent scans. Internal page splits happen less often but are more expensive: a split promotes a separator, updates the parent, and can ripple upward if the parent is full. Because internal-page changes affect many future lookups, they amplify write costs differently than leaf-page churn; reducing the width of keys stored in internal pages decreases the chance and impact of those ripples.
Concurrency and contention also map to page roles in practical systems. Internal pages—especially the root and the upper levels—are natural contention points under concurrent inserts, so we bias memory allocation and latching strategies to protect them: allocate more of the buffer pool to upper-level caches, use optimistic/lock-free reads, and consider hierarchical latches to avoid serializing transactions on a single node. Leaf pages experience localized contention (hot ranges) when keys are monotonic or clustered; if your workload inserts mostly at the tail, pre-splitting, using append-friendly keys, or employing buffer-backed insert staging can reduce hot-leaf contention and the frequency of costly splits.
What actionable rules should you apply when choosing a primary key or designing page layout? Prefer narrower, locality-preserving keys when you need low-latency point lookups because they shrink internal pages and increase cache hit rate for the B-tree path. For write-heavy workloads, avoid global randomness in primary keys that spreads inserts across many leaves and causes scattered I/O; instead, use locality or application-level sharding to control write hotness. Tune leaf fill-factor and consider prefix compression only where it improves overall density without harming the runtime cost of comparisons; pre-splitting and appropriate free-space thresholds let you trade some storage efficiency for far fewer split-driven writes.
Taking these ideas further, the interaction between page layout and primary-key choice is a core lever for predictable performance: narrow keys and compressed internal pages reduce tree height and the number of internal pages you must cache, while leaf layout choices control scan bandwidth and write amplification. As we move into the arithmetic of page-size tradeoffs and primary-key formats, we’ll quantify how those decisions change fanout, cache residency, and the expected I/O per operation so you can make evidence-based tuning choices.
Page Layout Fundamentals
Building on this foundation, the layout of on-disk pages is the low-level lever that turns B-tree theory into predictable latency and throughput. Page layout, page size, and the way we place keys and row pointers on a page directly determine fanout, cache residency, and write amplification; these are the knobs you must understand before tuning a primary key or index. How do you decide which parts of your tuple belong on internal pages versus leaf pages? Answering that question drives decisions that affect every read and write in your system.
A page is more than a blob of bytes; it has structure and semantics that shape performance. At minimum you’ll see a fixed header, a slot directory (or offset table), and a payload area for tuples; alignment and padding matter because they affect the number of items that fit in a page. For example, with a 4KB page even a few bytes of per-tuple header or alignment waste will reduce fanout and raise tree height. We therefore prefer narrow tuple formats for internal pages—store only separator keys and child pointers there—while using denser encodings on leaf pages where sequential throughput matters most.
Tuple placement policy influences both point and range performance. If you append tuples in insertion order you get fast tail writes but risk hot-leaf contention for monotonic primary keys; if you keep tuples sorted inside the page you optimize range scans at the cost of higher insert work and page splits. Free-space management—fill-factor, page compaction, or in-place reuse—changes the split/merge behavior of leaf pages and therefore write amplification. In practice, choose a fill-factor that reflects your write-read mix: lower fill-factor reduces split-driven writes, higher fill-factor maximizes throughput for cold read-heavy ranges.
Compression and key-storage strategies are the next set of tradeoffs. Internal pages benefit the most from prefix compression and separator-only storage because reducing key width increases fanout and decreases tree height; that lowers the number of internal pages you must keep hot in the buffer pool. Leaf pages can tolerate heavier compression for scan-heavy workloads, but compression increases CPU cost for comparisons and can complicate in-place updates. A common hybrid is to store only compressed separators in internal pages and keep leaf pages either fully compressed or storing variable-length suffixes externally to balance CPU and I/O.
Concurrency and buffer management interact directly with layout choices. Internal pages are hot and short—pin them more aggressively in your buffer pool and use optimistic or versioned reads to avoid latching contention on root and upper levels. Leaf pages are large and hot for range scans; reduce contention there by tuning split thresholds, pre-splitting hot ranges, or using append-friendly encodings for high-velocity inserts. We recommend reserving a proportion of the buffer pool for upper-level pages and monitoring latch wait metrics to detect layout-driven hotspots early.
Measurement informs any change you make to page layout or primary key design. Instrument average fanout, tree height, cache hit ratio for internal pages, and I/O per lookup under representative workload shapes—not synthetic uniform keys. Run A/B tests where you vary page_size or key_width and capture end-to-end latency percentiles and write-amplification metrics. If you need a practical next step, profile a tail-heavy workload with a fill-factor reduction and observe split rates, then iterate: tune compression, then adjust how much payload the leaf stores versus keeping rows in the base table. Taking that iterative, measurement-driven approach lets us convert page-layout theory into predictable production behavior and sets you up to quantify the arithmetic of page-size tradeoffs in the next section.
I/O and Range Scans
Building on this foundation, I/O and range scans determine whether an ordered query reads a few cached pages or floods the storage subsystem with sequential reads. We care about I/O patterns first because disk and SSD latency—random versus sequential—dominates end-to-end latency for large scans. Range scans exploit the B-tree’s leaf layout and sibling links to convert many random lookups into a few sequential page reads, so optimizing page packing and prefetch behavior directly reduces time spent on I/O. In other words, the difference between a few dozen and a few thousand physical reads is what separates interactive queries from batch jobs.
Understanding the fundamental cost model clarifies tradeoffs: a point lookup touches O(tree height) pages (mostly internal), while a range scan costs the number of leaf pages touched plus the internal-path overhead. Internal pages are compact and frequently cached; leaf pages hold density and therefore dominate I/O for scans. Because fanout controls height, narrower keys and compressed separators reduce internal I/O but do not eliminate leaf I/O for wide ranges. Consequently, think of I/O as two parts—high-frequency, small internal reads that benefit from cache, and bulk leaf reads that benefit from sequential throughput and prefetch.
How do you reduce I/O during wide range scans? Make the leaf-access pattern sequential and the pages dense yet prefetch-friendly. Sibling pointers or linked leaf chains let the engine issue read-ahead for the next N pages, turning many small reads into larger sequential transfers that storage and OS readahead handle efficiently. Use page layouts that avoid expensive in-place shuffling—append-ordered or stable-packed tuples let the engine scan contiguous extents. Compression helps, but only if CPU cost for decompression is lower than saved I/O; test with representative payload sizes to decide whether to compress leaves aggressively.
In practice we tune several knobs to shape I/O: adjust page size, set a conservative fill-factor to reduce split-driven writes, and choose clustering intentionally. Larger pages increase sequential throughput and reduce per-page meta overhead, but they reduce how many pages fit in the buffer pool, raising cache-miss rates for internal nodes. For tail-heavy inserts, pre-split hot ranges or use append-friendly key formats to avoid repeated leaf splits that scatter data and kill sequential I/O. Also consider read-ahead and I/O scheduler settings at the OS level for SSDs and NVMe; they amplify B-tree-level optimizations when the storage stack cooperates.
Concurrency and long-lived range scans interact with I/O in subtle ways that affect latency and throughput. Long scans can pin many pages and increase latch or buffer pressure, causing point queries to suffer random I/O when their working set is evicted. Use snapshot reads or MVCC to avoid blocking writers, and prefer lock-free or optimistic read paths so scans don’t serialize updates on upper-level nodes. Where possible, create covering indexes narrow enough to satisfy common ordered predicates—serving a range from a compact index can remove leaf-to-table lookups and dramatically reduce I/O.
Taking these operational lessons together, we prioritize keeping internal pages narrow and cache-resident while shaping leaf layout to maximize sequential I/O and minimize split churn. Measure leaf-page scan throughput, read-ahead effectiveness, and split rates under realistic workloads, then iterate: tweak page size, adjust fill-factor, and consider clustering or a covering secondary index. As we move into the arithmetic of page-size tradeoffs, we’ll quantify how these choices change fanout, cache residency, and the expected I/O per operation so you can pick the right defaults for your production workload.
Choosing Optimal Primary Keys
Choosing the right primary key shapes almost every performance property of a B-tree-backed index: fanout, tree height, cache residency, and write amplification all start with that single schema decision. If you treat the primary key as an afterthought, you force the storage layer to compensate through larger pages, heavier compression, or more frequent splits. We want keys that keep internal pages narrow, leaf pages sequential-friendly, and split churn low—because those are the levers that directly reduce I/O and latency for both point lookups and range scans.
Prefer narrow, stable keys as a first principle. Narrow keys shrink separators stored in internal pages, which raises fanout and reduces tree height; that lowers the number of internal pages you must keep pinned in memory. Stable means the key value won’t change for a row—updates that modify a primary key often trigger deletes and inserts, causing unnecessary page churn. For space and comparison efficiency, prefer fixed-width numeric types over long varchars when they model the domain without loss of meaning.
Monotonic versus random ordering is the next tradeoff you must weigh. Monotonic keys (serial integers, time-based ULIDs) aggregate inserts to a small range of leaf pages and avoid scattered I/O, but they create tail-hot leaves under heavy concurrent writes. Random keys (UUIDv4) diffuse write contention across many leaves and reduce per-leaf latch contention, yet they increase write amplification and hurt range scan locality. Consider these SQL patterns as examples:
CREATE TABLE events_seq (id BIGSERIAL PRIMARY KEY, payload JSONB);
CREATE TABLE events_ulid (id CHAR(26) PRIMARY KEY, payload JSONB); -- ULID: ordered + globally unique
CREATE TABLE events_uuid (id UUID PRIMARY KEY DEFAULT gen_random_uuid(), payload JSONB);
Choose serial or ULID for append-heavy OLTP where ordered scans and small tree height matter; choose random UUID only when you need unpredictable identifiers for security or multi-master uniqueness and are prepared to accept higher I/O costs.
Composite keys and clustering influence leaf layout in practical systems. If you build a clustered index (where the table rows are stored in primary-key order), the primary key controls physical row order and therefore range-scan performance directly. Use a leading tenant_id or shard_id in the key to confine hot ranges per tenant, for example (tenant_id, created_at), which preserves both locality and ordering for time-window queries. When clustering is inappropriate, create a narrow clustered surrogate and add covering secondary indexes for common ordered predicates to avoid expensive leaf-to-table lookups.
How do you evaluate candidate primary keys in your workload? Measure fanout, average tree height, leaf split rate, buffer-pool hit ratio for internal pages, and write-amplification (physical page writes per logical insert). Run representative A/B tests: deploy a table with a serial primary key and the same workload against a UUID-based variant, then compare 99th-percentile latency and split frequency. Instrumentation matters—capture latch waits and I/O per transaction so you can connect schema choices to operational pain points rather than guessing.
In practice we follow a short checklist: pick the narrowest stable type that models the domain, preserve locality for common access patterns, avoid global randomness unless required, and use composite keys or clustering to isolate tenant or time-based hotness. Where randomness is necessary, prefer time-ordered GUIDs (ULIDs/UUIDv7) to reclaim some locality without sacrificing uniqueness. Iterate: run microbenchmarks focused on split rates and cache residency, then tune fill-factor, compression, or page size based on the arithmetic of fanout and I/O. Building on the page-layout and B-tree principles we’ve already discussed, these decisions let us trade storage for predictable latency and lower write amplification as we move into quantifying page-size tradeoffs.
Fill Factor and Fragmentation
Building on this foundation, fill factor and fragmentation are the operational levers that determine whether your B-tree stays compact and fast or degrades into a noisy collection of half-empty pages. Fill factor (also written fill-factor) is the target occupancy you leave on pages to absorb future inserts and reduce split frequency; fragmentation describes how space and ordering degrade over time through splits, deletes, and scattered writes. How do you choose a fill-factor to balance split-driven write amplification against read-efficiency and cache residency? We’ll show practical heuristics you can measure and tune in production without blind knobs.
At a mechanical level, fill factor directly controls how many tuples you pack into each leaf page and therefore how often splits occur. If a 4KB page holds roughly 40 average tuples at 100 bytes each, an 80% fill factor leaves room for about eight inserts before a split; a 60% fill factor buys more insert headroom but increases the number of pages—and the tree height—you must cache. Splits force page writes and parent updates, which amplify write I/O and increase latency for concurrent transactions; therefore fill-factor is a tradeoff between split frequency, write amplification, and the number of pages that occupy your buffer pool.
Fragmentation shows up in several ways that matter differently for latency and storage. Internal fragmentation is free space stranded inside pages after deletes or partial splits; external fragmentation is adjacency loss where logically sequential leaf pages are scattered across storage or interleaved with other traffic; and logical fragmentation is when the logical order of keys no longer maps cleanly to contiguous physical extents, harming read-ahead and sequential scan throughput. In real systems you’ll often see a mix—steady-state deletes create many half-empty leaf pages that slow range scans, while hot-split churn scatters new pages and breaks read-ahead windows.
Monitor concrete metrics to detect when fragmentation is hurting you: page-fill histograms, split rate per second, average free bytes per page, and write-amplification (physical page writes per logical insert). Also track end-to-end application latencies—especially 95th and 99th percentiles—because fragmentation often shows as tail spikes during range scans or bursts of concurrent inserts. If split rate or page-fill variance climbs, or if 99th-percentile range-scan latency drifts up, that’s a signal to act: consider changing fill-factor, triggering a targeted compaction, or scheduling an index rebuild during low traffic.
Practical tuning starts with workload characterization. For heavy append-only OLTP (time-series, event logs) we prefer higher per-page free space at the tail—lower fill-factor (60–75%)—or use append-friendly keys like ULIDs so new inserts cluster without forcing high split churn across many leaves. For mostly read-heavy, stable tables choose a high fill-factor (85–95%) to maximize density and sequential throughput. Remember the systemic cost: lowering fill-factor increases total page count and can reduce fanout, so we often offset that by using prefix compression on internal pages to regain fanout and preserve low tree height.
Operational strategies complement fill-factor tuning. Pre-splitting hot ranges or using tenant-aware leading-key components confines hot inserts to isolated extents and reduces global fragmentation. Background compaction and online reorganization (a light-weight, incremental rebuild) reduce internal fragmentation without large maintenance windows; full rebuilds are costly but effective when logical order has become deeply scrambled. In practice we run A/B experiments: change fill-factor for a candidate table, replay representative traffic, and compare split rates, buffer-pool hit ratios for internal pages, and 99th-percentile latencies before rolling changes wide.
Taking this concept further, treat fill-factor and fragmentation control as part of schema design and operational playbooks rather than ad-hoc maintenance. We tune fill-factor based on measured split rates and access patterns, mitigate fragmentation with targeted compaction and pre-splitting, and use compression to regain fanout when density drops. As we move into page-size tradeoffs next, we’ll quantify how changing page size interacts with fill-factor and fragmentation to change fanout, cache residency, and the expected I/O per operation so you can pick defaults that match your workload.