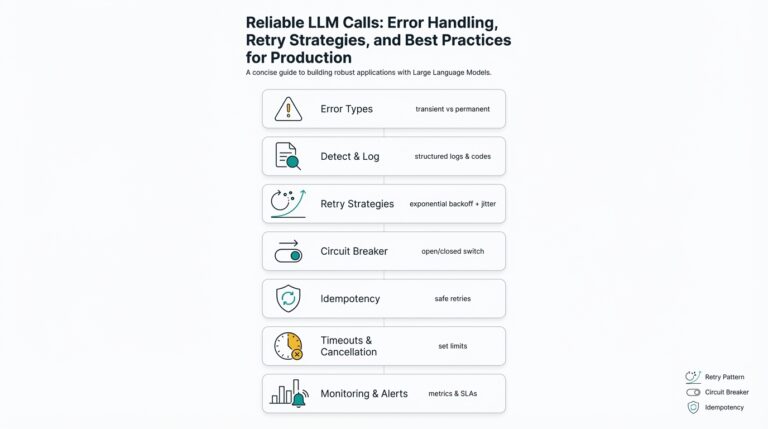
Define churn and business goals
Building on this foundation, we need a concrete, actionable definition of customer churn before we design models or interventions. Customer churn refers to the loss of a banking relationship that materially reduces future revenue or engagement—this includes account closures, dormancy beyond a business-defined window, and product downgrades that lower fee or interest margins. Placing “customer churn”, “predictive analytics”, and “churn prediction” front and center here guides the metrics you optimize for; how do you measure success if the target itself is fuzzy?
Start by operationalizing what counts as churn for each product line. A mortgage customer who repays early but remains with deposit accounts is different from a checking account holder who stops logging in for six months; each requires separate definitions and time windows. Define churn rate as closed customers over an observation cohort, but also build cohort-level retention and recovery metrics (e.g., 30/90/180-day survival). Concrete definitions avoid label leakage in churn prediction and make model evaluation comparable across teams.
Differentiate voluntary from involuntary churn because the remediation strategies diverge. Voluntary churn arises from poor experience, pricing, or better competitor offers and shows signals like declining login frequency, reduced inbound support interactions, or repeated product downgrades. Involuntary churn stems from payment failures, fraud blocks, or regulatory account closures and will show different feature patterns and timestamps. Distinguishing these in your data pipeline prevents noisy labels and informs whether to use churn prediction or uplift/causal models for targeted offers.
Translate business goals into measurable KPIs that drive model design and deployment. If the goal is to maximize retained revenue, optimize models and thresholds for expected retained lifetime value (LTV) rather than raw accuracy; if the goal is to reduce contact costs, optimize precision at top-K to avoid over-contacting low-value accounts. Specify targets like “reduce monthly attrition by 15% among customers with portfolio value > $50k” or “increase 90-day retention lift by 8 percentage points for recipients of targeted offers.” These goals turn abstract churn prevention into prioritizable engineering work.
Map those KPIs to evaluation metrics and model choices in predictive analytics pipelines. For high-value targeting, use propensity scores with calibration and measure business lift via A/B tests; for one-to-many campaigns, measure precision@k and expected net retained revenue. Consider uplift modeling when the question is “who responds positively to an intervention” rather than merely “who will churn.” Also include operational constraints like latency for real-time intervention, allowable false-positive rates, and the need for interpretable features when front-line teams require justification for outreach.
Account for constraints that shape feasible goals: regulatory and privacy requirements, channel capacity for outbound contact, and the cost-to-serve versus cost-to-retain tradeoff. For example, prioritize interventions for customers whose predicted prevented-churn value exceeds the cost of the retention offer and legal review. Implement control groups and holdouts to measure true incremental impact; a labeled uplift estimate without a randomized or quasi-experimental design risks over-estimating the effect of your churn prevention program.
With definitions and goals aligned, we can select modeling strategies, sampling schemes, and real-time intervention patterns that directly support business objectives. Next, we’ll convert these targets into feature engineering, training pipelines, and deployment constraints so that churn prediction models feed automated decision engines for timely, measurable churn prevention and real-time intervention.
Data collection and sources
Building on this foundation, high-quality data is the single most important enabler of reliable customer churn models, churn prediction, and actionable predictive analytics. If your labels and features don’t reflect real business events, the model will optimize noise instead of retained revenue. Early investment in a catalog of proven data sources prevents rework later when you need to justify why a segment was targeted or why an intervention failed.
Start by enumerating the primary data domains that feed churn models: transactional data (deposits, withdrawals, payments), behavioral telemetries (login frequency, mobile feature usage), product holdings (balances, overdraft flags), and customer touchpoints (support tickets, NPS surveys). Enrich these with operational signals like fraud flags, payment failures, and collection events that often precede voluntary or involuntary churn. Include lawful third-party enrichment such as credit bureau scores and marketing consent records to capture propensity and outreach eligibility—label which external sources are permissible for contact under your compliance rules.
As we discussed earlier about operational definitions, aligning timestamps and label windows is essential for preventing leakage and for reproducible churn prediction. Define the observation window, label window, and exclusion periods explicitly for each product: for example, compute features using a 90-day lookback and declare churn when no logged activity occurs in the following 180 days, or when an account closure event is recorded. Handle censoring (incomplete observation periods) by keeping cohort start/end metadata so survival-analysis techniques and time-to-event models can be applied without bias. Distinguish voluntary indicators (declining engagement, repeated downgrades) from involuntary causes (failed KYC, regulatory account closures) in your label schema to guide appropriate remediation strategies.
Design ingestion so it supports both batch re-training and low-latency scoring. Use Change Data Capture (CDC) to stream transactional updates into a landing zone and publish materialized feature views for real-time scoring; CDC captures row-level changes instead of full table snapshots, minimizing latency and duplication. Centralize derived features in a feature store—a system that version-controls, documents, and serves feature vectors consistently to training and serving pipelines—so the same transformation logic is used during offline experiments and online inference. Instrument traceable data lineage from source tables through transformation jobs to model input so auditors and frontline teams can inspect why a customer received an offer.
Privacy and governance must shape which fields you collect and retain. Treat Personally Identifiable Information (PII) with the strictest controls: tokenize or hash identifiers, store minimal contact fields in a secure vault, and log access for auditability. Apply data minimization and purpose-limitation: if a third-party enrichment doesn’t measurably improve uplift in A/B tests, remove it to reduce compliance risk. Ensure consent flags and suppression lists are available as first-class attributes in your pipeline so outreach decisions honor opt-outs in real time.
In feature engineering, prefer interpretable, business-friendly signals that product teams and compliance reviewers can validate. Create rolling-window aggregates (e.g., last_30_days_txn_count) and rate features (e.g., month-over-month balance change) and persist them as immutable feature snapshots for each cohort cut. For example, a SQL-style rolling aggregate might look like: SELECT customer_id, COUNT(*) AS last_30_txns FROM transactions WHERE txn_time >= current_date - interval '30' day GROUP BY customer_id; Use these snapshots to compare feature drift between training and production and to compute expected retained value per action.
Finally, instrument robust data quality monitoring and drift detection so the pipeline degrades loudly rather than silently. Monitor schema changes, null-rate spikes, and distribution shifts for top predictive features, and gate model rollouts behind data-contract checks. Establish data contracts with source owners that specify SLA, freshness, and cardinality; when a contract breaks, trigger a rollback or fall-back policy that uses a conservative scoring model. Taking these steps preserves model validity and makes the transition to feature engineering, model training, and real-time intervention predictable and auditable.
Feature engineering and labeling
Building on this foundation, the most important engineering work you do for churn prediction happens before model training: precise labeling and pragmatic feature construction. How do you convert raw events into signals that capture intent and risk while avoiding leakage? We start by turning the business churn definitions and observation windows you’ve already set into reproducible label-generation logic, then design features that reflect recency, trend, and causal proxies for churn so predictive analytics models learn durable patterns rather than dataset artifacts.
Label generation must be explicit, auditable, and segmented by product and churn type. Define cohort start, observation window, label window, and exclusion rules in code so every downstream pipeline uses the same semantics; for example, create a label table keyed by customer_id and cohort_date and materialize it daily. Avoid label leakage by excluding features computed after the label cut; if you use a 90-day lookback with a 180-day churn window, ensure all features derive only from data older than cohort_date + 0 days and not from events inside the churn window. If you need an example SQL pattern for label creation, implement a deterministic query such as:
INSERT INTO labels (customer_id, cohort_date, churn_label)
SELECT c.customer_id, c.cohort_date,
CASE WHEN MAX(account_closed_at) BETWEEN c.cohort_date + interval '1' day AND c.cohort_date + interval '180' day THEN 1 ELSE 0 END
FROM cohorts c LEFT JOIN accounts a ON a.customer_id = c.customer_id
GROUP BY c.customer_id, c.cohort_date;
Design features that capture behavioral cadence, financial health, and relationship breadth, then persist them as named, versioned feature columns. Use rolling-window aggregates (last_30_txns, last_90_avg_balance), rate-of-change measures (MoM_balance_pct_change = (bal_t – bal_t-30)/NULLIF(bal_t-30,0)), and interaction terms (support_tickets_last_30 * overdraft_flag) to expose non-linear risk signals to tree models or neural nets. Include product-holding features (num_products, max_product_tenure), digital engagement telemetry (mobile_session_days_last_30), and loss-of-trust proxies (failed_payments_count). These engineered signals are where domain intuition converts into predictive power for churn prediction.
Apply robust transformations and encoding strategies so models generalize across segments and time. For skewed monetary features apply log or quantile transforms; for high-cardinality categorical fields use regularized target encoding with Bayesian smoothing or K-fold schemes to limit leakage. When using target-aware encodings, always compute encodings inside cross-validation folds or use time-split encoding to preserve temporal integrity. For time-to-event or censored cohorts, consider survival features and discretized hazard bins rather than a single binary label to retain timing information for downstream intervention prioritization.
Operationalize feature lineage and serving to eliminate the “works-in-notebook” gap between experiments and production. Persist feature definitions in a feature store with clear version tags and online store support for low-latency scoring; materialize daily snapshots for batch scoring and maintain stream-backed incremental aggregations for real-time scoring. We recommend CDC-driven micro-batches or stream-aggregations for metrics that must reflect last-minute activity (failed payments, fraud flags), and scheduled recompute for heavier aggregates. Consistent feature serving ensures your predictive analytics results in repeatable campaign actions.
Detect and mitigate label noise and feature drift so production decisions remain reliable. Monitor null-rate spikes, distribution shifts for top predictive features, and sudden changes in churn-label prevalence; set automatic alerts and fallback scoring when data contracts break. Handle noisy labels by reweighting examples by account value or time-to-churn, using robust loss functions, or fitting uplift models where treatment effect matters more than raw churn propensity. Always evaluate candidate features with temporal cross-validation and sanity-check feature importance against domain expectations to avoid optimizing on ephemeral signals.
Taking these steps turns raw bank events into stable, interpretable signals that feed interventions with measurable ROI. When features are versioned, labels are auditable, and freshness guarantees are explicit, we can confidently map model outputs to business actions—from low-latency retention offers to cohort-level policy changes. Next, we use these engineered and labeled inputs to select model families and deployment patterns that satisfy your latency, interpretability, and uplift measurement requirements.
Modeling techniques and imbalance
Building on this foundation, the practical challenge we face next is modeling reliably when positive churn labels are rare and the business cost of false positives and false negatives is asymmetric. Imbalanced classes distort common objectives—accuracy and AUC can hide catastrophic business outcomes—so we choose models and loss objectives aligned to retained revenue, contact cost, and intervention capacity rather than vanilla classification metrics. From the start, map model outputs to business KPIs like precision@k and expected retained lifetime value so every modeling decision has a measurable downstream impact on campaigns and budgets.
Start model selection by matching problem shape to model family: use regularized logistic regression when you need crisp probability calibration and interpretability for compliance; prefer tree ensembles (LightGBM, XGBoost, CatBoost) when non-linear interactions and fast iterations matter; and adopt time-to-event or survival models when churn timing, not just occurrence, guides interventions. How do you choose between a propensity predictor and an uplift model? If your goal is “who will churn,” a churn prediction model suffices; if you need to know “who will respond positively to an offer,” uplift or causal models that estimate treatment effect heterogeneity are required. In practice, we often train a propensity baseline, then layer uplift experiments for high-cost offers where incremental impact is critical.
Address class imbalance using complementary strategies: careful sampling, cost-sensitive learning, and label-aware losses. For tabular churn problems we prefer reweighting by business value rather than blind oversampling—assign sample_weight = account_value or use class_weight tuned to expected contact costs so the model internalizes economic priorities. Synthetic oversampling (SMOTE) can help when minority-class patterns are sparse, but use it with temporal splits and validate on untouched holdouts to avoid leakage. Modern libraries also support focal loss or custom objective functions to emphasize hard-to-classify positives while avoiding overfitting to noisy labels.
Use concrete training patterns to make these ideas operational. For example, with LightGBM you can pass per-row weights or class_weight, and always validate with time-based cross-validation rather than random folds to preserve temporal integrity:
python
from lightgbm import LGBMClassifier
clf = LGBMClassifier(n_estimators=1000, learning_rate=0.05)
clf.fit(X_train, y_train, sample_weight=acct_value_weights, eval_set=[(X_val,y_val)], early_stopping_rounds=50)This pattern enforces that high-LTV accounts influence the learned boundaries more than low-value noise, and early stopping on a temporally held-out validation set preserves generalization to live cohorts.
Evaluation must reflect operational objectives: prioritize precision@k, PR-AUC, calibrated probability reliability, and expected net retained revenue over global accuracy. Precision@k shows how many of the top-k contacted customers actually churn and directly maps to contact budgets; PR-AUC is more informative than ROC-AUC when positives are rare. Calibrate your model with Platt scaling or isotonic regression so probability thresholds map to predicted lift and expected value; a well-calibrated model lets you threshold by the expected return-on-offer rather than an arbitrary score.
When interventions can change behavior, consider uplift modeling and causal validation alongside churn prediction. Uplift models estimate incremental effect and reduce wasteful outreach to customers who would have stayed; validate uplift models with randomized holdouts or stratified A/B tests to estimate treatment effect heterogeneity. For compliance and explainability, combine uplift scores with local explanations (SHAP) so front-line teams understand why a customer is targeted and auditors can trace the decision rationale.
Operationalize guardrails around thresholds, drift, and interpretability so models remain trustworthy in production. Tie thresholds to cost curves and run periodic re-calibration as base-rate drift occurs; monitor label prevalence, feature distributions, and campaign response lift so degradation triggers retraining or fallbacks. Use monotonic constraints or sparse explainable features where regulators or contact centers require straightforward justification for offers.
Taken together, these modeling techniques let us build churn prediction systems that respect class imbalance, prioritize business value, and integrate causal thinking where it matters. In the next step we’ll translate these model outputs into scoring pipelines, thresholds, and real-time decisioning that feed your automated retention channels.
Prioritize customers using CLV
Building on this foundation, prioritize customers by blending model propensity with customer lifetime value (CLV) so your churn prevention work maximizes retained revenue rather than raw accuracy. Customer lifetime value (CLV) is the economic lens that converts a churn probability into an expected dollar impact, and predictive analytics without that conversion often routes outreach to low-value accounts. We focus on expected prevented-churn value as the primary ranking signal so that every outreach decision is justified by a positive expected return after offer and contact costs.
Start by turning churn propensity into an expected-value score so you can answer the core decision rule: contact only when expected prevented-churn value exceeds the cost of intervention. The expected prevented-churn value is simply propensity * CLV * estimated_uplift — cost_of_offer; expressed another way: EV = p(churn) × CLV × uplift − offer_cost. Calibrated probabilities matter here because a miscalibrated propensity will bias EV estimates; we therefore calibrate models (Platt or isotonic) and validate predicted-value buckets against realized lift in holdouts.
How do you decide which customers to contact in practice? Define a business-aware threshold: contact if EV > contact_cost and the contact respects regulatory and consent constraints. For example, if a customer has CLV = $8,000, predicted churn probability = 0.12, and expected uplift from a retention offer = 0.25, then EV = 0.12 × 8,000 × 0.25 − 30 = $210 − 30 = $180; that justifies outreach. Use precision@k and expected net retained revenue as your operational metrics rather than global accuracy so campaign capacity maps directly to financial impact.
Operationalizing CLV means two parallel engineering flows: a production-grade CLV estimate served alongside churn propensity in your feature store, and a real-time merger layer that computes EV for decisioning. For many banks a hybrid approach works best: persist a daily, cohort-based CLV for stability and compute lightweight real-time adjustments (recent balance delta, recent complaints) at inference. In code, your scoring step looks like merging two tables and applying a threshold:“`python
pseudo-code
scores = propensity_store.get_scores(cohort_date)
clv = clv_store.get_latest(customer_ids)
ev = scores[‘prob’] * clv[‘value’] * uplift_model.predict(customer_ids) – offer_costs
targets = ev[ev > contact_cost]
“`This pattern isolates the heavy CLV calculation from low-latency decisioning while keeping the EV computation auditable.
Measurement and experimentation must validate that CLV-based prioritization increases retained revenue and avoids perverse outcomes. Always include randomized control groups that mirror your top-LTV segments so you can estimate incremental revenue by CLV decile; stratify holdouts among high, medium, and low CLV buckets to detect heterogenous treatment effects. Where offers are expensive, prefer uplift models to reduce outreach to customers who would have stayed; also log treatment assignment and outcomes back into the CLV model so the next iteration learns actual incremental returns rather than naive retention.
Finally, embed governance, monitoring, and recalibration into the pipeline so CLV-driven decisions remain reliable over time. Monitor EV distribution, feature drift for CLV inputs, and campaign ROI; trigger recalibration when realized lift diverges from predicted EV beyond tolerance. We should also enforce legal and consent checks as first-class constraints in the decision service so high-CLV customers are never contacted in violation of policy. Next, we’ll use these EV-ranked targets to design channel-specific interventions and real-time playbooks that close the loop between prediction and measurable retention.
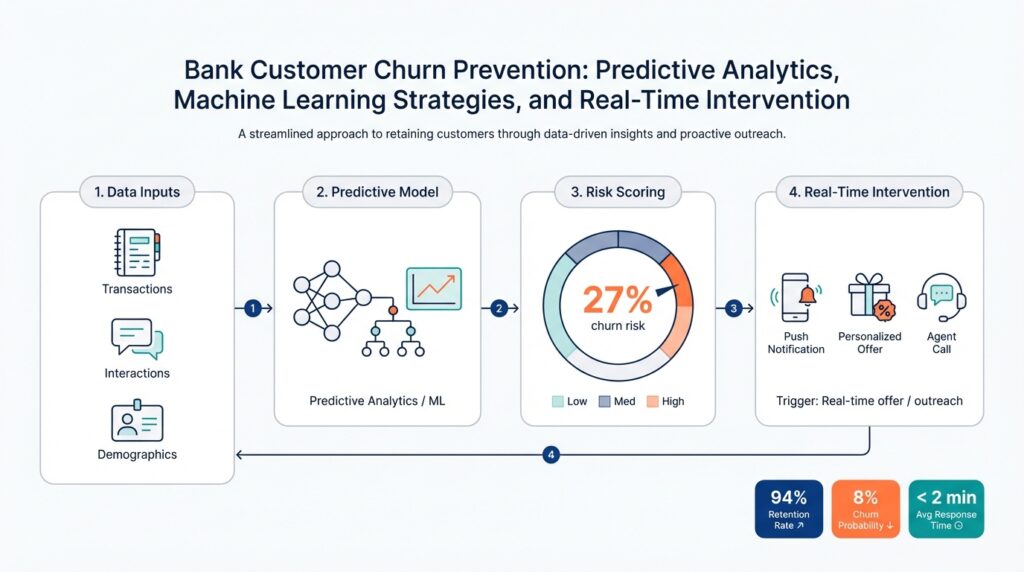
Real-time scoring and interventions
Building on this foundation, the hardest part of turning churn prediction into impact is closing the time gap between a risky signal and an actionable response—latency kills retention. If you wait days to score a customer after a failed payment, you lose the window where an offer or an in-app prompt actually prevents attrition. How do you ensure timely, personalized action before a customer leaves? We solve this by embedding low-latency predictive analytics into the event stream and tying scores directly to decisioning logic that computes expected prevented-churn value on demand.
Start by streaming the right signals into an online feature store so you can perform real-time scoring without sacrificing reproducibility. Capture CDC events (authorizations, failed payments, KYC flags), mobile session pings, and support interactions into Kafka or a similar log, then materialize lightweight aggregates in an online store that your model server can read in milliseconds. This architecture separates heavy offline feature engineering—daily CLV and long-window aggregates—from the small, high-freshness features needed for low-latency inference, letting you run real-time scoring against the same feature definitions used in training.
Design features for both stability and immediacy: persist daily cohort snapshots for durable predictors and maintain incremental stream-aggregates for volatile signals. For example, use a 90-day rolling balance and a last-5-minutes failed-payment flag; compute slow features in batch and fast features in stream processing, then join them at inference. This hybrid approach ensures your propensity output reflects long-term relationship health and last-minute risk indicators, and it keeps the production model robust against transient telemetry gaps.
Decisioning should merge calibrated propensity with economic context so offers target expected value, not just probability. Compute EV at inference with a simple, auditable expression such as EV = prob * CLV * uplift - offer_cost, then compare EV to channel and contact-cost thresholds to decide whether to send a push, place an outbound call, or enqueue a waiver. Because probabilities must be trustworthy, always apply calibration (Platt or isotonic) before computing EV; a miscalibrated model will systematically misallocate spend and over-contact low-value customers.
Implement the real-time intervention pipeline with clear operational guardrails. The model server should expose a low-latency API guarded by consent and suppression checks, frequency caps, and an offer budget service that enforces per-customer and per-channel limits. Include a circuit-breaker that falls back to a conservative rule-based action when feature freshness is uncertain, and run canary experiments to validate live uplift before full rollout so you don’t scale a negative intervention.
Instrument measurement and feedback loops as first-class elements of the flow so you can prove incremental impact. Log every inference, treatment decision, offer delivered, and downstream outcome into a time-series store; this enables near-real-time attribution and allows us to retrain uplift models on true incremental response rather than naive retention. Also track operational metrics—latency percentiles, feature staleness, and score distribution drift—and wire alerts that trigger automatic rollback or re-calibration when tolerances are exceeded.
Finally, balance automation with explainability and compliance so front-line teams can trust and tune interventions. Surface a short rationale with each action (top contributing features and EV bucket), honor opt-out/consent flags at the decision layer, and maintain randomized holdouts to measure real lift. Taking this approach turns predictive analytics into defensible, measurable real-time interventions that prioritize retained revenue and keep your retention playbooks auditable and effective—next we’ll map these decision outputs to channel-specific playbooks and execution patterns.