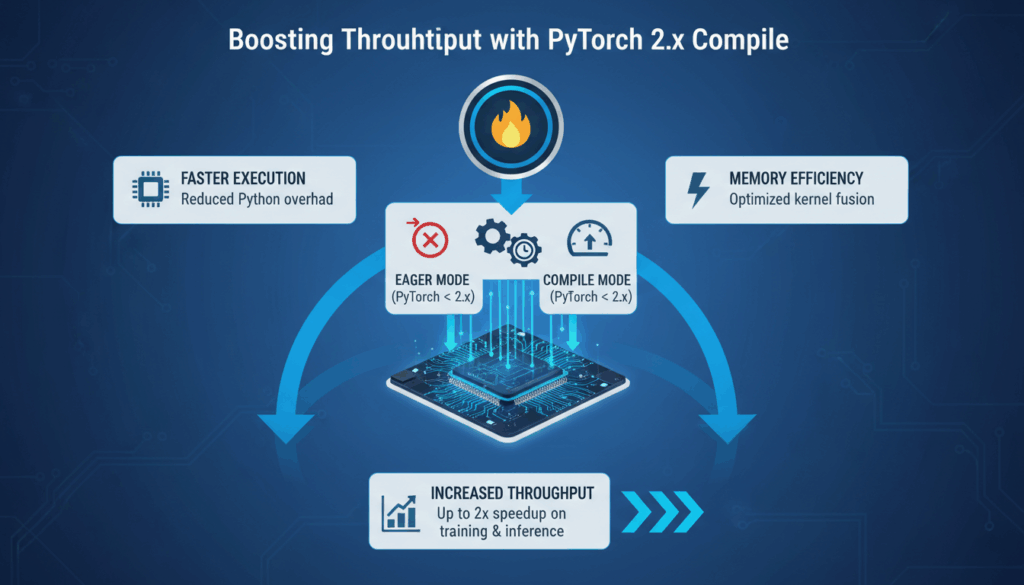
Introduction to PyTorch 2.x and torch.compile
PyTorch, an open-source machine learning library, has undergone significant enhancements with the release of version 2.x, particularly with the introduction of the torch.compile feature. This tool offers transformative benefits for model optimization, enabling developers to achieve better performance with reduced manual intervention. In essence, torch.compile aims to simplify the process of optimizing Tensor computations, making high-performance model deployment more accessible.
At its core, torch.compile converts the PyTorch models into a more optimized form. It automates the transformation and fusion of operations, thus enhancing runtime efficiency without the need for extensive code modification. This is achieved through just-in-time (JIT) compilation techniques, where the code is optimized during execution, leveraging the power of dynamic compilation to improve throughput.
The feature is designed to be used seamlessly within existing PyTorch workflows. As a developer, you can simply wrap your existing PyTorch models with torch.compile to achieve substantial performance improvements. Here’s a brief look at how you might go about doing this:
import torch
import torchvision.models as models
# Load a pretrained model, e.g., ResNet
model = models.resnet50(pretrained=True)
# Wrap the model with torch.compile for optimization
optimized_model = torch.compile(model)
This simple wrapping process instantly optimizes your model by applying numerous under-the-hood optimizations, like kernel fusion, graph-level transformations, and operator engrafting, which all contribute to reduced computation time. The ultimate goal is to provide these benefits without requiring developers to deep dive into compiler design and optimization techniques.
One of the standout features of torch.compile is that it retains the PyTorch dynamic computation graph’s flexibility. Unlike traditional static graph compilers, PyTorch allows for dynamic execution paths, which are crucial for tasks involving variable-length inputs or sequences that change shape over iterations. The torch.compile utility maintains this adaptability while providing significant performance boosts by optimizing frequently executed paths dynamically.
Moreover, torch.compile includes advanced debugging features, enabling developers to monitor and tweak performance through different compilation options such as speculatively applying optimizations or experimenting with different backend configurations.
For engineers concerned with performance metrics, initial benchmarks have shown considerable improvements in throughput and execution time, especially for models with extensive input-output operations. This factor makes it particularly appealing for large-scale AI deployments where computational efficiency directly impacts operational costs.
By bringing compiler-level optimizations to an accessible interface, PyTorch 2.x positions itself as a powerful tool for both research and production environments, integrating high-performance capabilities without losing the simplicity that PyTorch is known for.
Setting Up Your Environment for torch.compile
To effectively utilize PyTorch 2.x’s torch.compile feature, a suitable environment setup is essential. This setup ensures compatibility and maximizes performance benefits. Follow these steps to prepare your environment for leveraging torch.compile:
Install the Latest Version of PyTorch
First, ensure you have the latest version of PyTorch installed, as torch.compile is a feature introduced in PyTorch 2.x. You can verify your current PyTorch version by running:
python -c "import torch; print(torch.__version__)"
To install or upgrade PyTorch, use pip or conda:
Using pip:
pip install torch torchvision torchaudio
Using conda:
conda install pytorch torchvision torchaudio -c pytorch
This installation will provide you with the core libraries needed to work with torch.compile and other PyTorch features.
Set Up a Compatible Python Environment
PyTorch 2.x is compatible with Python versions 3.7, 3.8, 3.9, and 3.10. It is recommended to use a virtual environment to avoid conflicts with other packages. You can create a virtual environment using venv or conda:
Using venv:
python3 -m venv torch-env
source torch-env/bin/activate # On Windows use: torch-env\Scripts\activate
Using conda:
conda create --name torch-env python=3.9
conda activate torch-env
Install Backend Dependencies
To fully exploit the benefits of torch.compile, make sure that LLVM’s llvmlite and other JIT compilation dependencies are installed if required by your specific use case. In many installations, these will be pulled as dependencies automatically. However, manually verify and install if necessary:
pip install llvmlite
Enable GPU Support
For maximum performance, especially with complex models, enabling GPU support is crucial. Make sure you have CUDA installed if you plan to use an NVIDIA GPU. Check your CUDA version and ensure compatibility with the installed PyTorch version. You can often find installation guides or compatibility matrices on the official PyTorch website.
To install PyTorch with CUDA support, you can select the appropriate CUDA version when running your pip or conda installation command:
For a specific CUDA version:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
Replace cu116 with the correct CUDA version supported by your GPU (e.g., cu113 for CUDA 11.3).
Configure Environment Variables
Optimizing torch.compile might require setting specific environment variables to tweak backend compilation settings. These are advanced settings usually used during deep optimization. Refer to PyTorch’s official documentation for guidance on environment variables that might be relevant for your setup.
Testing the Setup
Finally, test your setup by running a simple compilation to ensure everything is functioning correctly:
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
compiled_model = torch.compile(model)
print("Setup successful: Model compiled.")
If no errors occur, your environment is ready to use the torch.compile feature efficiently. Regularly update your environment to keep up with new features and optimizations introduced by the PyTorch team.
Implementing torch.compile in Your PyTorch Workflow
Integrating torch.compile into your PyTorch workflow can significantly enhance model performance via automatic optimization. Here’s how you can implement torch.compile for efficient execution of your models:
Start by ensuring your PyTorch model is trained and validated. Using a model already set up for inference allows you to focus solely on optimizing performance. PyTorch models often involve multiple layers and operations, making them prime candidates for the optimizations that torch.compile provides.
import torch
import torchvision.models as models
import torch.nn as nn
# Load a pretrained model such as ResNet50
model = models.resnet50(pretrained=True)
After loading your model, the next step is to use torch.compile. This function is designed to wrap the model, enhancing it through various optimizations such as operation fusion and graph transformations. This helps reduce the computational overhead during inference.
# Optimize the model using torch.compile
compiled_model = torch.compile(model)
Parameters for torch.compile
torch.compile offers several optional parameters that allow for fine-tuning the optimization process. Here are some key parameters and how you can leverage them:
- backend: Specifies the backend used for compilation. Currently, common backends include
"inductor","eager", and others provided by PyTorch. - mode: Can be set to
"max"for maximum optimization or"min"for minimal changes focused on compatibility.
Example:
compiled_model = torch.compile(model, backend='inductor', mode='max')
Mode of Execution
Running your model with torch.compile inferences means your model will automatically benefit from the optimizer’s capacity to engage dynamic just-in-time (JIT) compilation. JIT compilation operates by capturing traces during model execution and identifying opportunities for accelerating commonly executed paths.
Example of Model Inference:
def infer(image):
# Ensure model is in evaluation mode
compiled_model.eval()
with torch.no_grad():
return compiled_model(image)
Debugging and Optimization Controls
Debugging compiled models might seem daunting, but torch.compile offers several tools to facilitate this:
- Logging: Increase verbosity using the
verbose=Trueparameter, which helps diagnose issues by providing detailed logs of the compilation process. - Guard Requirements: Control check runs by setting
fullgraph=Truein the compile call, ensuring the model meets specific static requirements.
Debugging Example:
compiled_model = torch.compile(model, verbose=True, fullgraph=True)
Performance Monitoring
After implementing torch.compile, it is crucial to monitor performance gains. Use PyTorch’s built-in utilities to compare execution time between standard and compiled models:
import time
input_tensor = torch.randn(1, 3, 224, 224)
# Measure the standard model’s inference time
start_time = time.time()
model(input_tensor)
print("Standard model inference time:", time.time() - start_time)
# Measure the compiled model’s inference time
start_time = time.time()
compiled_model(input_tensor)
print("Compiled model inference time:", time.time() - start_time)
Considerations
Remember that while torch.compile can offer remarkable efficiency gains, not all models will see the same level of improvement. It’s beneficial to experiment with different backend configurations, especially if your model has unique computational patterns or extensively uses custom layers.
By integrating torch.compile into your workflow with these methods, you’re leveraging the power of JIT and compiler optimizations in PyTorch 2.x, which can lead to significant throughput and performance enhancements in both research and production settings.
Optimizing Performance with torch.compile Modes
The torch.compile modes provide tailored optimization strategies that can significantly enhance performance depending on the specific needs and constraints of your model. By understanding and selecting the appropriate mode, developers can optimize model execution to acquire maximum throughput and efficiency gains.
PyTorch’s torch.compile feature includes several modes characterized by differing levels of optimization aggressiveness and target objectives. Here’s a closer look at how you can leverage these modes to enhance performance:
Understanding the Available Modes
The design of these modes is to balance between maximal performance and achievable generality. Each mode has specific focuses:
- “default” Mode: This is the standard setting and aims for balanced general optimizations. It will generally apply the necessary transforms and autonomously decide when to opt for more aggressive strategies if it detects stable execution patterns.
- “reduce-overhead” Mode: This mode minimizes the overhead of compilation itself. It’s targeted for scenarios where startup costs are pivotal, like deploying in environments with short-lived processes. Although it sacrifices some runtime optimizations, it can be beneficial where rapid response times are critical.
- “high-speed” Mode: As the name suggests, this mode aims to maximize speed by applying aggressive optimizations such as aggressive operation fusion, ahead-of-time compilation, and prioritized elimination of redundant computations.
- “keypoint” Mode: Tailored for hot spots or critical sections of the execution graph that are frequently re-executed. This mode intensively optimizes and caches computations to minimize re-evaluation time during extensive runs.
Applying Modes in Practice
To optimally use these modes, you need to evaluate your model’s runtime characteristics and choose a mode aligning with your performance objectives.
Selecting a Mode:
Quality benchmarks and profiling should precede the selection of a compilation mode.
import torch
import torchvision.models as models
# Load a model, e.g., ResNet50
model = models.resnet50(pretrained=True)
# Compile the model targeting high-speed optimization
compiled_model = torch.compile(model, mode='high-speed')
Dynamic Mode Tuning
In some scenarios, you may strategically switch modes depending on stage requirements of your AI application, such as pipeline initialization versus full-scale execution. Employing checkpointing with different modes can lead to overall performance stabilization.
def optimized_execution(input_data):
# Alternate modes when necessary
if initialization_phase:
compiled_model = torch.compile(model, mode='reduce-overhead')
else:
compiled_model = torch.compile(model, mode='default')
# Execute the model
with torch.no_grad():
result = compiled_model(input_data)
return result
Mode-Specific Considerations
Every mode involves trade-offs:
- Memory Footprint: High-speed modes might increase memory usage due to additional caching and duplicated kernel strategies.
- Compatibility: Some operations may exhibit reduced performance improvements in
reduce-overheadmode due to fewer optimizations. - Startup Latency: Using non-default modes can introduce additional startup latency, especially if transitions between modes involve extensive JIT compilation phases.
Profiling and Performance Evaluation
Assess the impact of each mode using detailed profiling. PyTorch’s built-in tools like torch.utils.bottleneck can help reveal the best-fit modes:
import torch.utils.bottleneck as bottleneck
def profile_model(compiled_model):
bottleneck.run(f"compiled_model({input_tensor})")
Evaluating these aspects allows developers to fine-tune their models, balancing between runtime efficiency and operation latency.
By thoughtfully integrating the torch.compile modes into your pipeline, you walk the path towards optimized model deployment, benefiting from PyTorch’s advanced compiler strategies to achieve high-performance standards in diverse environments.
Handling Dynamic Shapes and Graph Breaks
Handling dynamic shapes and graph breaks in PyTorch models becomes particularly challenging yet increasingly important as the complexity and variability of input data grow. The torch.compile function in PyTorch 2.x is designed to maintain the framework’s inherent flexibility while optimizing runtime performance, even in the face of these challenges.
Dynamic shapes occur frequently in real-world applications where input data might vary in dimensions, such as varying sequence lengths in natural language processing tasks or differing image sizes in computer vision deployments. This variability demands a flexible execution path that adapts dynamically, a feature inherent to PyTorch’s eager execution.
However, dynamic shapes can introduce inefficiencies during computation, as static optimizations become less straightforward when input dimensions aren’t fixed. torch.compile mitigates these inefficiencies by employing dynamic Just-In-Time (JIT) compilation strategies, which compile performance-critical paths while retaining flexible handling of input variations.
Graph breaks occur when PyTorch operations deviate from the typical linear or static computation graph due to control flow constructs like loops or conditional statements. These breaks can potentially hinder the ability of compilers to optimize, as the path of execution is not determined until runtime.
The torch.compile utility addresses these breaks using speculative and partial graph compilation. Instead of attempting to compile the entire computation graph upfront (which is impossible when the path is not known in advance), torch.compile selectively optimizes frequently traversed paths, applying dynamic compilation techniques.
Example of Handling Dynamic Shapes
Consider a scenario with a model that processes sentence embeddings. The sentence lengths may vary considerably:
import torch
import torch.nn as nn
def create_model():
return nn.LSTM(input_size=128, hidden_size=256, num_layers=2)
model = create_model()
compiled_model = torch.compile(model)
In this LSTM model, each input sequence can have a different length. PyTorch’s ability to handle such variability means torch.compile needs to dynamically adjust optimizations. By dynamically compiling only those segments of the graph that are critical to performance, it manages to maintain efficiency without sacrificing flexibility.
Mitigating Graph Breaks
Graph breaks often result from varying input-dependent computations, like different branches in an algorithm. By utilizing advanced tracer mechanisms in torch.compile, PyTorch identifies stable computation paths reflected in recurring inputs.
import torch
import torch.nn.functional as F
def conditional_execution(input):
# Dynamic control flow resulting in a graph break
if input.sum() > 0:
return F.relu(input)
else:
return -F.relu(-input)
compiled_execution = torch.compile(conditional_execution)
Here, conditional execution introduces a graph break because the exact path depends on the input data. torch.compile effectively handles this by focusing on optimizing the relay paths (e.g., outcomes of the ReLU function), which dominate the execution.
Best Practices for Utilizing torch.compile
Managing dynamic shapes and graph breaks can still pose challenges. Here are key practices:
- Batch Inputs: Where possible, batching inputs of varying shapes can reduce graph compilation times since similar shapes can share computed optimizations.
- Profiler Usage: Use PyTorch profilers to identify segments of your models that are time-intensive and may benefit from specific optimizations.
- Iterative Over RTT: Instead of relying on static model adjustments for dynamic properties, allow runtime tuning by running multiple test executions to identify optimal paths.
These methods help ensure that your model gains the performance benefits of torch.compile without compromising on the adaptability crucial for dynamic data scenarios.
In summary, while dynamic shapes and graph breaks present complexities, PyTorch 2.x’s torch.compile robustly addresses them by maintaining a balance between performance and flexibility through dynamic JIT compilation and selective graph path optimization.
Integrating External Kernels with torch.compile
Incorporating external kernels into your PyTorch workflows via torch.compile can unlock significant performance optimizations, especially when dealing with custom operations not natively supported by PyTorch. External kernels refer to specialized computational routines often written in lower-level languages like CUDA or C++, and integrating these with PyTorch requires careful setup and execution strategy.
Overview of External Kernels
External kernels are typically used to perform highly specialized tasks or to optimize certain operations that are computationally demanding. These kernels can be written to take full advantage of specific hardware capabilities, such as GPU parallelism, and often result in performance gains that are not possible with high-level PyTorch operations.
By integrating these kernels with torch.compile, you enable PyTorch to optimize them alongside native operations, creating a cohesive execution plan that maximizes efficiency across the board.
Steps to Integrate External Kernels with torch.compile
1. Developing the Kernel
Begin by developing your external kernel. Depending on the hardware, this might be a CUDA kernel for NVIDIA GPUs, a ROCm kernel for AMD GPUs, or even a CPU-based routine. Assume a simple CUDA kernel for illustration:
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
2. Building the Kernel
Compile your kernel using a suitable compiler, such as nvcc for CUDA kernels. Ensure that the compiled binaries are optimized for your target hardware.
nvcc -o my_kernel.o my_kernel.cu
3. Wrapping the Kernel in PyTorch
Incorporate your compiled kernel into PyTorch using torch.utils.cpp_extension. This utility allows you to define custom operations and integrate them seamlessly with PyTorch.
from torch.utils.cpp_extension import load
# Assuming your compiled kernel is "my_kernel.so"
custom_ops = load(name="my_kernel", sources=["my_kernel.cu"])
# Define a PyTorch function to use this operation
import torch
class CustomAdd(torch.autograd.Function):
@staticmethod
def forward(ctx, a, b):
c = torch.empty_like(a)
custom_ops.addKernel(c, a, b)
return c
4. Testing the Kernel Function
Before integrating with torch.compile, verify the kernel’s functionality and correctness:
import torch
a = torch.tensor([1, 2, 3], device='cuda')
b = torch.tensor([4, 5, 6], device='cuda')
result = CustomAdd.apply(a, b)
print(result) # Should print [5, 7, 9]
5. Integrating with torch.compile
Finally, compile your PyTorch model incorporating the custom operation for optimized execution. Ensure that torch.compile recognizes the custom operation by registering it correctly.
# Define a simple model that uses the custom add operation
class CustomModel(torch.nn.Module):
def forward(self, x, y):
return CustomAdd.apply(x, y)
model = CustomModel().to('cuda')
compiled_model = torch.compile(model)
# Test the compiled model
input1 = torch.tensor([1, 2, 3], device='cuda')
input2 = torch.tensor([4, 5, 6], device='cuda')
output = compiled_model(input1, input2)
print("Compiled Output:", output)
Considerations
-
Performance Tuning: Continuous monitoring is essential. Use PyTorch profilers to ensure the kernel operation is enhancing performance as expected. The effect of integrating external kernels will heavily depend on the alignment with hardware capabilities.
-
Compatibility: Ensure the operation cooperates well with other parts of the PyTorch execution pipeline. Some optimizations might collide with dynamic graph paths if not managed carefully.
-
Resource Management: Be attentive to memory management, especially for GPU-based kernels, as incorrect allocation can cause runtime errors or crashes.
By meticulously incorporating external kernels into your PyTorch models via torch.compile, you harness the full potential of hardware acceleration, achieving superior performance and efficiency even for complex operations.



