Genie overview and capabilities
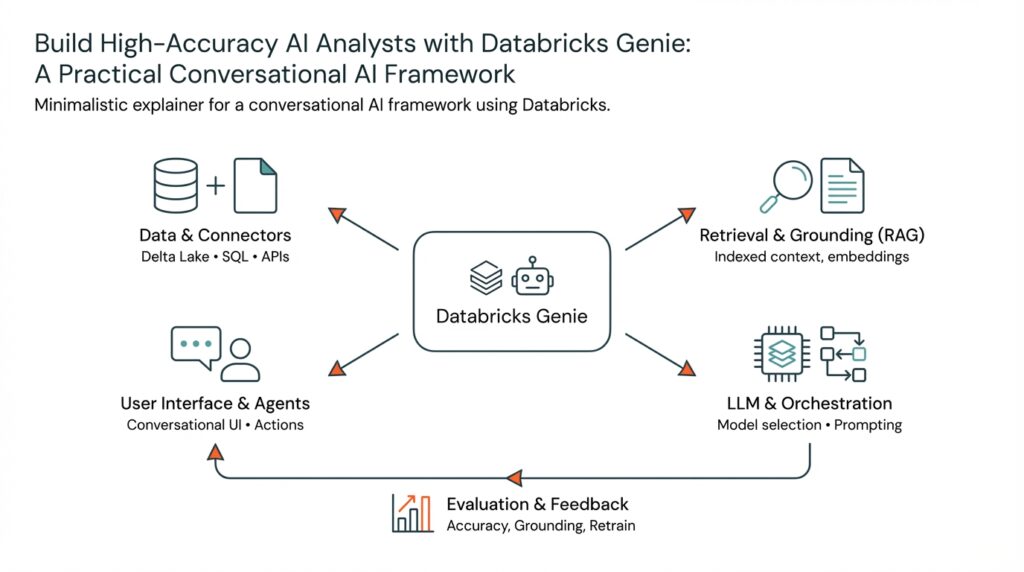
When you need an AI that can interrogate your lakehouse, execute SQL, and return defensible, traceable answers, Databricks Genie gives you a pragmatic conversational AI framework to build production-grade AI analysts. Building on this foundation, we’ll examine how Genie combines retrieval, orchestration, and tool use to deliver high-accuracy responses for analyst workflows. You’ll see why Databricks Genie matters for real-world data teams and how its capabilities map to typical analyst tasks like exploration, ad-hoc querying, and report generation.
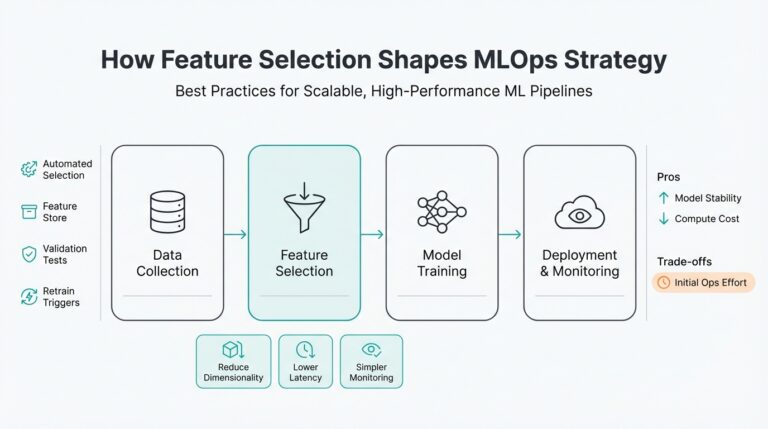
Genie’s core strength is orchestration: it composes retrieval, models, and tools into a single conversational pipeline so you don’t treat an LLM as a monolithic oracle. This pipeline-first design means you can attach a vector retriever against your embeddings, run a precise SQL executor against a governed lakehouse, and invoke custom tools for complex transformations. For example, in an interactive diagnostics session we might retrieve recent anomaly examples, synthesize a short explanation with an LLM, then execute a parametrized SQL snippet to validate the hypothesis — all within the same conversation context.
Retrieval-augmented generation (RAG) is central to getting accurate, grounded answers, and Genie makes RAG practical at scale. You can index tables, query logs, and documentation into vector stores and then surface only the most relevant context to the model at runtime, reducing hallucination and improving factuality. In practice we embed time-series summaries, ETL lineage notes, and business glossaries so the assistant uses source-backed facts when answering: this is how you move from creative language modeling to reliable analyst outputs.
Genie also emphasizes tool integration and actionability: it’s not just answering questions but performing work you’d otherwise do manually. That means authenticated connectors to your data warehouse or lakehouse, safe execution sandboxes for SQL or Python, and result-formatting utilities for charts and downloadable CSVs. When you design flows, define explicit verification points (example: run SQL and return row counts before exporting) so you can audit actions and maintain compliance in regulated environments.
Operational features matter for production use, and Genie delivers capabilities you expect from an enterprise conversational AI framework. Expect multi-turn state management so context persists across sessions, model routing to pick the right LLM for a task, and observability hooks for logging prompts, retrieved contexts, and execution traces. How do you validate accuracy? Implement test suites that run canonical queries against golden datasets and compare the assistant’s outputs; log discrepancies and feed them back into retriever tuning or prompt engineering.
Putting this into a simple pattern, we typically assemble a conversational flow like: build retriever → fetch top-k evidence → run concise prompt template → optionally execute SQL/tool → present answer + provenance. A minimal pseudocode sketch looks like:
retriever = VectorRetriever(index)
evidence = retriever.get(query, k=5)
prompt = PromptTemplate(evidence, query)
answer = LLM.generate(prompt)
if answer.requires_sql:
result = SQLExecutor.run(answer.sql)
return format(result, provenance=evidence)
else:
return answer.text_with_provenance
This pattern scales: swap embeddings, change models, or add new tools without rewriting the whole flow. Taking this concept further, you can automate model evaluation, orchestrate fallback strategies when confidence is low, and continuously retrain retriever indexes from user feedback. In the next section we’ll drill into concrete implementation choices and code examples that make these capabilities repeatable across teams.
Prerequisites and required permissions
Building on this foundation, getting Genie production-ready starts with a clear checklist of infrastructure, identities, and data access so your conversational AI can act reliably and audibly in governed environments. You’ll need a Databricks workspace with workspace-admin coverage to provision clusters, SQL warehouses, and Unity Catalog assets; a service principal or managed identity for automated calls; and network connectivity (VPC/VNet peering or private endpoints) that allows the assistant to reach the lakehouse, external vector stores, and any tooling endpoints. Front-load these prerequisites early: without a workspace admin and a scoped service principal you can’t wire the SQL executor, vector retriever, or observability hooks used by Databricks Genie.
Define the identity and permission model explicitly so you can apply least-privilege controls across retrieval, execution, and tool use. Create a dedicated service principal (or cloud managed identity) for the assistant and restrict it to only the catalogs, schemas, and tables it needs in Unity Catalog; grant read-only to documentation and embeddings storage but granular read/write where the assistant must materialize temporary artifacts. For interactive SQL execution, give the SQL execution principal SELECT privileges and separate a different principal for exports or writes; this separation prevents a single compromised token from both reading sensitive PII and exfiltrating data.
How do you ensure the Genie assistant can run parametrized SQL without overprivilege? Use role-based access control and scoped tokens with short TTLs. For example, configure a SQL endpoint role that allows EXECUTE on parametrized stored procedures but denies ALTER/DROP on schemas; generate ephemeral tokens for user sessions so long-running credentials aren’t embedded in application code. We recommend enforcing credential passthrough or token exchange patterns so the assistant operates with the caller’s limited privileges when accessing sensitive tables, and configuring row- and column-level security where available to protect sensitive attributes.
You must also provision and secure the retrieval layer: embeddings storage, vector retriever, and index management all need permissions and lifecycle controls. If you host vectors in cloud object storage, create a dedicated bucket with versioning and lifecycle policies and give the retriever service read-only access; for managed vector stores, use scoped API keys stored in a secrets manager. Configure automated reindexing jobs with a separate orchestration principal, and enforce encryption-at-rest and in-transit for embedding data because retrieval context becomes the provenance the model cites during answers.
Operational prerequisites matter as much as access control. Enable audit logging for workspace actions, SQL run history, and anything that invokes external tools so you can trace model prompts to executed queries and returned artifacts. Wire logs to your SIEM and implement observability hooks that capture retrieved evidence, prompt templates, and execution traces—this makes RAG defensible and simplifies post-incident analysis. Also prepare monitoring alerts for unexpected query patterns, large exports, and abnormal retriever usage so your security and SRE teams can intervene automatically.
Finally, bake governance and developer workflows into the onboarding process so teams using Databricks Genie move fast without creating risk. Define templates and example policies for service principals, provide a “developer sandbox” catalog with synthetic data for experimentation, and require code reviews for any tool integration that performs writes or external calls. When you combine least-privilege roles, ephemeral credentials, auditability, and clear separation between retriever, executor, and exporter principals, you create a secure, auditable conversational AI pipeline that scales across analyst teams and preserves the integrity of your lakehouse and business data.
Modeling data with Unity Catalog
Building on this foundation, one of the first decisions we make is how to model your lakehouse assets so Genie can retrieve, reason about, and execute against authoritative data. Unity Catalog gives you a single control plane for catalogs, schemas, and tables; model those primitives to reflect business domains and analytical trust levels so retrievers and SQL executors pull provable evidence instead of ad-hoc files. How do you design tables and schemas to make RAG reliable and auditable? Start by mapping product, sales, and finance domains to separate catalogs or schemas and reserve a predictable naming convention that your retriever can rely on when it constructs evidence sets.
The next key idea is layering data by trust and intent rather than technology. Create bronze (ingest), silver (cleaned/standardized), and gold (aggregated/business-ready) tables inside Unity Catalog so each layer carries clear SLAs, owners, and transformations. This separation makes it straightforward for Genie to source recent raw signals from bronze for diagnostics, use silver for reproducible joins and lineage checks, and reference gold for final numeric answers returned to users. When you implement these layers as Delta tables registered in Unity Catalog, you preserve schema, time-travel history, and a consistent object identity that the assistant can cite as provenance.
Implementing those layers requires concrete metadata and access patterns. Define table properties or tags for owner, sensitivity, and refresh cadence so retrievers can score evidence by recency and trust; add a canonical column list to make programmatic masking easier. For example, create tables with explicit LOCATION and TBLPROPERTIES metadata and grant a narrow SELECT privilege to the assistant service principal rather than exposing raw object storage. A short SQL example illustrates intent: CREATE TABLE prod.sales_silver USING DELTA LOCATION ‘/mnt/bronze/sales’ TBLPROPERTIES (‘owner’=’data_eng’, ‘sensitivity’=’low’); GRANT SELECT ON TABLE prod.sales_silver TO genie_service.
Performance and query patterns drive physical design choices that affect both latency and the quality of evidence. Partition by date or logical event bucket for high-cardinality time-series, and use Delta OPTIMIZE plus Z-ORDER for common filter columns so parametrized SQL runs that Genie generates remain responsive. Maintain compact statistics and schedule compaction for high-ingest tables so row-count checks and sampling queries used for verification return quickly. We prioritize physical design that balances ingest throughput with the query shapes your assistant will execute during multi-turn sessions.
Security and governance are integral to modeling—not an afterthought. Use Unity Catalog’s row-level filtering and column-masking policies to keep PII out of the assistant’s immediate context while still enabling aggregate analysis; enforce least-privilege by separating a read-only retriever principal from an execution principal that can run parametrized SELECTs. Configure short-lived tokens or credential passthrough so any SQL executed by Genie inherits the caller’s scope when required, and audit every query run and artifact created so you can trace model prompts back to specific table versions and properties.
Metadata, lineage, and data contracts make RAG defensible in production. Attach glossary IDs and change-log fields to tables, publish lineage for ETL jobs that populate silver and gold, and surface those artifacts in your retriever index so the assistant cites the exact transformation that produced an answer. We find it practical to embed small provenance snippets (owner, job_id, commit_timestamp) alongside vector embeddings so users see not only the claim but where it came from.
For a concrete example, model a sales pipeline by keeping an immutable sales_bronze Delta table for raw events, a sales_silver table with PII-masked customer identifiers and standardized SKU mappings, and a sales_gold table with daily aggregates keyed by region. Configure the assistant’s retriever to prefer gold for KPIs, silver for investigative joins, and bronze for anomaly hunting; this mapping ensures Genie runs the minimal, auditable SQL and returns answers with clear provenance.
Taking this approach lets you treat Unity Catalog not just as a permissions layer but as the canonical modeling surface for Genie. In the next section we’ll convert these modeling principles into deployable code and CI checks that keep models, permissions, and retriever indexes synchronized across environments.
Create and configure a Genie space
Databricks Genie needs a well-scoped runtime environment before it can act as a reliable analyst; creating that environment correctly is the difference between an experimental chatbot and a production-grade assistant. Start by treating the Genie space as an organizational unit that binds identities, retrievers, execution principals, and observability together so you can reason about provenance, permissions, and performance in one place. How do you design that boundary so retrievers return high-trust evidence and the assistant can run parametrized SQL safely? We’ll walk through practical configuration choices you’ll want to standardize across teams.
Building on this foundation, define the Genie space as a lightweight deployment unit inside your Databricks workspace that contains: a service principal for automation, secrets and scoped API keys, a configured vector retriever endpoint, a SQL executor role and endpoint, and an artifacts folder for index and model metadata. Name and tag the space so your CI/CD pipelines and governance tooling can discover it automatically. Treat the space as both a runtime and a policy container: apply Unity Catalog access policies, network controls, and audit settings at the same logical scope so retriever evidence and executed queries share the same governance rules.
First-order setup: create and register the identities and compute resources the assistant needs. Provision a dedicated service principal (genie_service) and store its credentials in a secrets manager; create a short-lived SQL execution principal for runtime queries and grant it narrowly scoped privileges such as GRANT SELECT ON TABLE prod.sales_silver TO genie_service. Configure a SQL warehouse or endpoint with token passthrough where possible so sessions inherit user-scoped permissions. These concrete grants and ephemeral tokens prevent broad privileges while enabling the assistant to run the parametrized SELECTs required for interactive analysis.
Next, wire the retrieval layer: index the artifacts you want the assistant to cite and host them in a managed vector store or object storage bucket with versioning. Create a VectorRetriever instance tied to that index and tune its parameters (for example: retriever = VectorRetriever(index, top_k=5, score_threshold=0.2)) so you return compact, high-relevance evidence for prompts. Give the retriever read-only access to the embeddings bucket or a scoped API key stored in the space secrets. Schedule automated reindexing jobs in the same space to capture schema changes, refresh cadence metadata, and update provenance snippets alongside embeddings.
Configure the SQL executor and tool sandboxes inside the Genie space so any executed code runs with explicit guards. Use parametrized stored procedures or prepared statements to prevent injection, restrict the executor principal to SELECT and EXECUTE on approved objects, and implement preflight checks that validate row counts, runtime limits, and result sizes before returning data. For exports, require a separate export principal with distinct credentials and enforce approval flows for large downloads. These execution controls keep the assistant actionable while preserving auditability and least privilege.
Operationalize observability and testing within the same space: log retrieved evidence, prompt templates, and every SQL run to your workspace audit logs and to your SIEM. Create a test suite that runs canonical queries against golden datasets and compares assistant outputs to expected results so you detect regressions in retriever quality or prompt templates. Add monitors that alert on anomalous query shapes, sudden increases in top_k retrievals, or unexpected export volumes so SRE and security teams can intervene automatically.
Finally, manage lifecycle and environment parity across dev, staging, and prod copies of the Genie space by templatizing infrastructure as code, model-selection policies, and secret scopes. Use feature flags for model routing and a clear promotion path for retriever indexes so we can iterate on embeddings without destabilizing production assistants. With those pieces in place, the space becomes a repeatable unit you can version, audit, and scale—setting the stage for implementing prompt templates, evaluation pipelines, and richer tool integrations in the next section.
Curate knowledge store and prompts
If your conversational assistant is only as good as the evidence it cites, the highest-leverage work you can do is curate the underlying knowledge store and design prompt templates that shape how that evidence is used. Building on the Genie orchestration model we discussed earlier, prioritize a compact, high-trust index in your vector store and a small set of robust prompt templates that inject provenance, not noise. Early in the pipeline you should treat the retriever as a precision gate — return fewer, higher-quality snippets rather than many loosely related hits.
Start by deciding what artifacts belong in your knowledge store and how to represent provenance. In practice we embed not only documentation and notebooks but also table summaries, ETL lineage notes, and snippet-level SQL examples; each embedding should include metadata fields like source_table, commit_timestamp, owner, and sensitivity. This metadata makes it possible to filter or re-rank evidence by recency and trust: prefer gold-aggregates for KPIs, silver for reproducible joins, and bronze for raw anomaly examples. By storing short provenance snippets (owner and job_id) alongside vectors you let downstream prompts include traceable citations without exposing full PII.
How you chunk and embed text matters as much as which artifacts you index. Chunk by logical unit — a function’s docstring, a table’s schema+sample rows, or a curated summary paragraph — sized for your model’s context window so evidence stays coherent when concatenated into prompts. Use semantic-preserving splits (sentence or paragraph boundaries) rather than arbitrary byte limits, and attach a compact summary for long documents so the retriever can surface the summary first with a link to the full material. For structured data, embed short flattened records (column:value pairs) and include a column-level sensitivity flag so prompts can mask fields dynamically.
Tune the retriever to favor relevance and recency rather than raw similarity scores. Configure top_k and score_threshold so you retrieve a tight evidence set (for example, top_k=4 and score_threshold=0.25 as a starting point) and implement a recency multiplier for time-sensitive artifacts. Consider hybrid retrieval that uses structured filters (catalog, schema, tags) before vector re-ranking; this reduces hallucination by constraining candidate pools. How do you ensure the retriever returns trustworthy evidence? Run automated tests that query canonical questions and assert that returned snippets contain expected table_ids and commit_timestamps.
Design prompt templates that make the model an evidence-aware analyst rather than a free-form responder. Use a short system instruction that sets the role, then inject retrieved snippets as labeled evidence blocks with provenance markers. For example, a compact prompt template might look like:
SYSTEM: You are a data analyst. Use only the evidence below unless asked to run SQL.
EVIDENCE 1: [sales_gold.daily_agg | ts=2026-02-28] summary: ...
QUESTION: {user_query}
INSTRUCTION: Provide an answer and list the evidence references used.
Require the model to either return a concise conclusion with referenced evidence or emit a flagged action like “RUN_SQL:” plus a parametrized SQL template. This explicit separation helps the orchestration layer decide when to call the SQL executor or to present a purely textual answer. Use temperature=0.0 for factual extraction prompts and a slightly higher temperature (0.2–0.4) for exploratory synthesis where you want phrasing variety but still need fidelity.
Guard the pipeline with verification steps and minimal execution privileges. If a prompt produces a SQL snippet, run a preflight that checks for only allowed keywords and then execute row-count and sample queries in a sandbox with a read-only principal; return both results and the evidence IDs that justified the query. Log the prompt, retrieved evidence IDs, and execution trace to your observability store so you can audit recommendations and tune both retriever and prompt templates from real sessions.
Operationalize prompt and index lifecycle with CI and evaluation. Version prompt templates alongside retriever indexes in your Genie space, run A/B evaluations against golden queries, and automatically reindex embeddings after schema changes or weekly for high-velocity sources. Capture user feedback signals (accept, correct, request-run) and feed them into supervised re-ranking and prompt improvements so we close the loop between production use and index quality.
Taking these steps—curating compact, provenance-rich vectors, tuning the retriever for precision, and designing constrained prompt templates—makes the assistant both actionable and defensible. In the next section we’ll convert these curation and prompt practices into concrete deployment code and CI checks that keep retriever indexes and prompt versions synchronized across dev, staging, and prod.
Integrate, test, and optimize API
Integrating the assistant’s runtime APIs into your Genie pipeline is where design meets reality: this is how retrieval, model prompts, and the SQL executor become a reliable, auditable analytic service. You should front-load API integration and Databricks Genie concerns — authentication, contract validation, and observability — into your CI/CD pipeline so runtime failures surface as build breaks rather than production incidents. Treat the API as a first-class component that must satisfy the same SLAs and governance rules as your data endpoints, because the assistant will call it at scale during multi-turn sessions.
Define a strict contract and enforce it programmatically before any runtime call. Start by publishing a machine-readable schema (JSON Schema or OpenAPI) that specifies allowed parameters, types, and provenance fields such as evidence_ids and commit_timestamp; require an idempotency_key header for state-changing endpoints and short-lived tokens or credential passthrough for authenticated SQL execution. How do you validate that an API call won’t leak sensitive data or cause a large export? Implement preflight checks that run against the request (size, allowed tables, row-limit thresholds) and reject requests that violate policy before executing them in the lakehouse.
Implement resilient client patterns in your orchestration layer to make API calls predictable under load. Use connection timeouts, request-level deadlines, and exponential backoff with jitter to avoid thundering herds when models generate rapid follow-ups. For example, a simple Python client pattern looks like:
import requests
from backoff import expo
@expo(max_tries=5)
def call_api(payload, headers):
resp = requests.post(API_URL, json=payload, headers=headers, timeout=5)
resp.raise_for_status()
return resp.json()
response = call_api({"query": q, "evidence_ids": ids}, headers={"Authorization": token, "Idempotency-Key": uuid})
In addition to retries, validate responses against your schema and reject any response that omits provenance or returns disallowed fields; failing fast keeps downstream LLM prompts from consuming malformed evidence. Use idempotency keys for export or write operations and separate the execution principal for exports so that a transient retry cannot trigger duplicate side-effects.
Testing must cover unit, contract, and integration layers so you find regressions in retrieval, prompt templates, and API behavior early. Unit tests should mock the SQL executor and retriever to assert orchestration logic (e.g., when evidence implies RUN_SQL the orchestrator calls the executor with the expected parametrized SQL). Contract tests should verify any API with a consumer-driven approach (asserting required fields, rate-limit responses, and error codes). Integration tests run against a staging Genie space with synthetic but realistic golden datasets, comparing assistant outputs and provenance to expected results; include automated checks that compare returned row counts, sample rows, and evidence IDs.
Optimize for latency and cost once correctness is proven. Cache idempotent API responses at the gateway for repeat queries, batch small fetches into a single multi-evidence call to the retriever, and prefer streaming result patterns for large query results so the UI can render progressive insights. Tune retriever parameters (top_k, score_threshold) together with API payload size limits to balance context quality against model input cost. When you encounter hotspots, profile end-to-end latency (retriever, model, executor) and apply targeted optimizations such as pre-warming common embeddings, Z-ordered tables for faster sampling, or moving inexpensive verification checks to the API edge.
Make observability and SLOs non-optional: instrument every API call with distributed tracing, attach request ids to evidence and prompt templates, and capture metrics for request latency, error rates, and exported row volumes. Configure alerts for sudden changes in top_k retrievals or large export patterns so SRE and security teams can act. Finally, bake these tests and monitoring into your CI so that any retriever index update, prompt template change, or API contract revision runs through the same verification suite and rollout gates — this is how we keep Databricks Genie-driven workflows accurate, auditable, and performant as usage scales.