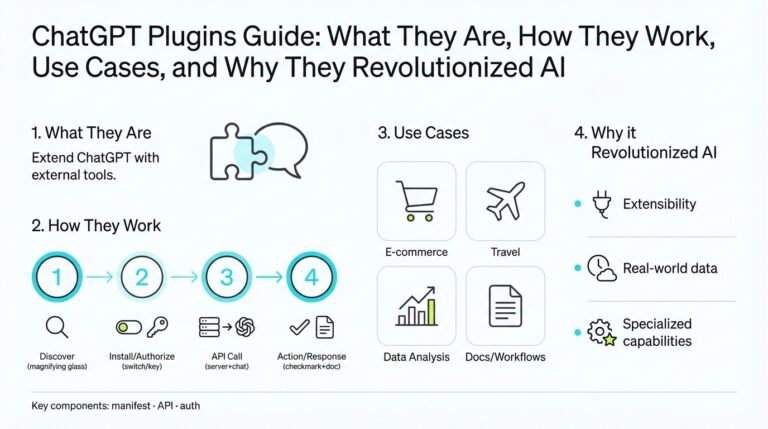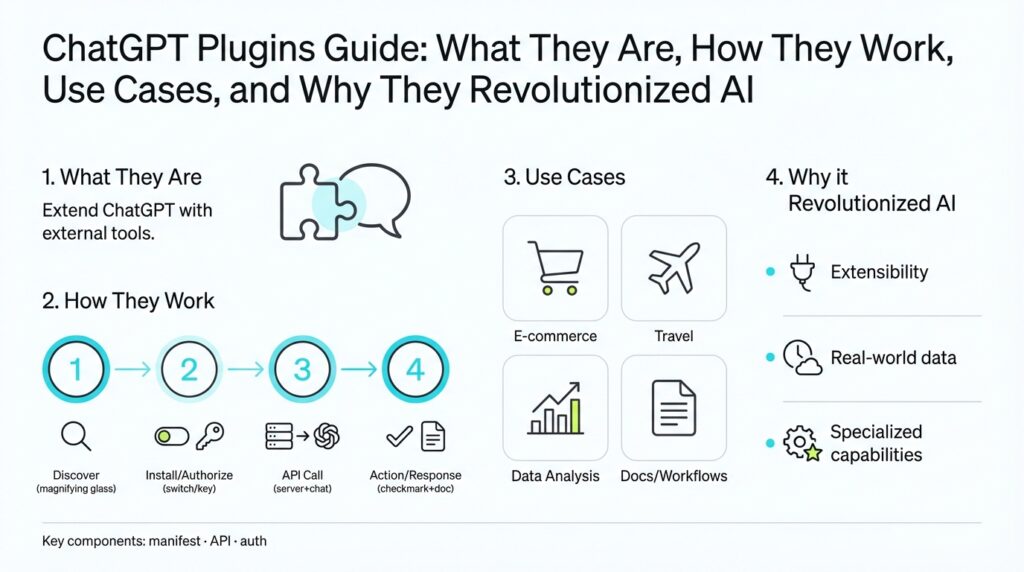
What Are ChatGPT Plugins
ChatGPT plugins put external functionality and live data directly into a chat session so the model can perform real-world tasks you actually need. We’re building on the idea that a language model’s output is only useful if it can access current information and take constrained actions; plugins are the bridge that gives the model secure, documented hooks into web APIs, search, or private data sources. This integration changes the model from a passive generator into an actionable assistant that can look up flights, query your company docs, run computations, or trigger workflows on your behalf. (openai.com)
The core architectural idea is simple: treat each plugin as a backend API described to the model via machine-readable metadata so the model knows what calls it can make and how to use them. In practice that means a manifest file plus an OpenAPI (formerly Swagger) specification that documents endpoints, parameters, and schemas; the chat system injects this documentation into the model’s context so it can plan API calls when appropriate. This approach separates concerns—you keep classic API design and authentication patterns while exposing a curated surface specifically designed for language-model consumption. (openai.com)
To build a plugin you’ll typically implement a standard REST API, produce an OpenAPI spec, and publish a small manifest that points to that spec and declares auth requirements and human-facing descriptions. For example, a minimal manifest might include a schema version, a machine-friendly name, an OpenAPI URL, and an auth block indicating OAuth or service tokens. Here’s a compact illustrative manifest we might register with a chat service:
{
"schema_version": "v1",
"name_for_model": "todo_api",
"api": { "url": "https://api.example.com/openapi.json" },
"auth": { "type": "service_http" }
}
Keep in mind that the platform will surface the plugin description to the model and require user consent before any action that affects external systems. (openai.com)
You’ll see three practical plugin patterns in real-world deployments: retrieval-style plugins that search private document stores and return relevant snippets (useful for internal knowledge bases), browsing or search plugins that fetch current web results, and action plugins that create resources or trigger workflows (book a reservation, send an email, start a CI job). Retrieval plugins normally index documents into a vector database (examples include Pinecone, Milvus, Qdrant) and expose a single query endpoint the model can call to fetch context. These patterns let you combine private data, live web facts, and programmatic actions, yielding use cases like auto-generated reports, contextual code fixes, or multi-step orchestration across services. (github.com)
Connecting models to external services adds power but also risk; you should evaluate when to enable a plugin and what data it may expose. When should you enable a plugin? Enable it when the benefit (accurate, current data or an imperative action) outweighs the risk and when you’ve vetted auth, logging, and data minimization controls. Threats include prompt-injection and permission escalation, so enforce least privilege, prefer tokened server-to-server auth where possible, validate and sanitize plugin outputs, and require explicit user confirmation for impactful operations. Security and transparency are active concerns in the ecosystem and should drive your access and deployment policies. (wired.com)
Taking this concept further, we’ll next examine how the chat model decides when to call a plugin, how it formats requests, and how to design contract-first APIs that are resilient to ambiguous prompts. That operational layer is where you turn plugin capability into reliable, auditable features in production chat workflows.
How Plugins Actually Work
Building on this foundation, we now look at what actually happens when the model moves from a natural-language plan to a concrete API call using ChatGPT plugins. The runtime treats each plugin as a typed tool described by a manifest and an OpenAPI specification, so the model can map intents to the exact HTTP method, path, and parameters it needs. This mapping is critical because it prevents ad-hoc, free-form web requests and gives you predictable, auditable interactions between the language model and external systems. For searchability and integration, mention of OpenAPI and manifest files up front helps you reason about the contract the model will rely on.
The first step is intent detection and tool selection inside the model’s reasoning process. How does the model decide when to call a plugin? The model evaluates whether the user’s request requires external data or an external action and then selects the smallest set of candidate plugins whose documented endpoints satisfy that intent. We call this a planner stage: the model generates a short plan that names the plugin, the endpoint, and the expected shape of parameters before producing a formal call. This planner approach reduces pointless calls and focuses on operations that change state or fetch live facts.
Once the model commits to an action, it formats a structured call using the OpenAPI metadata the platform injected into its context. The request includes path parameters, query strings, a typed JSON body, and auth hints the platform enforces; the platform then executes the HTTP request on the model’s behalf. Below is a compact example of what the model’s structured call looks like when invoking a TODO creation endpoint:
{
"tool": "todo_api",
"operationId": "createTask",
"method": "POST",
"path": "/tasks",
"body": { "title": "Draft plugin docs", "due_date": "2026-03-05" }
}
Designing your API contract to match that consumption pattern matters. We recommend a contract-first approach: define small, focused endpoints with explicit parameter names, stable JSON schemas, enumerated types where possible, and idempotency keys for write operations. Clear error shapes and consistent HTTP status codes let the model interpret failures programmatically instead of guessing; for example, an error body with {“code”:”INSUFFICIENT_PERMISSIONS”,”message”:”…”} is far easier to recover from than free-text errors. This makes plugins robust to ambiguous prompts and enables automated retry, fallback, or user confirmation flows.
At runtime you also need validation, sanitization, and graceful degradation. The chat platform should validate plugin responses against the declared schema and run lightweight sanity checks—length limits, content-classification, and type checks—before returning data to the model or the user. For long-running operations, streaming responses and progress events let the model deliver interim summaries and ask follow-up questions while the action completes. When an endpoint returns partial data or transient errors, the platform can surface a structured retry token so the model reattempts safely rather than hallucinating missing fields.
Security and user consent are enforced as part of the call lifecycle, not after the fact. The manifest declares auth patterns so you can require OAuth scopes, per-user tokens, or server-to-server credentials; the chat platform handles token exchange and prevents the model from embedding secrets in outputs. We also recommend logging and audit trails for every plugin invocation and requiring explicit, contextual user confirmation for any action that mutates external systems. These controls help you balance automation and safety while keeping least-privilege principles in place.
In practice, a single user request often becomes a small choreography: the model calls a retrieval plugin to gather context, synthesizes that context into a decision, requests user confirmation, and then calls an action plugin to execute. For example, you might fetch the latest SLA document, summarize the relevant clause, ask the user whether to notify the on-call engineer, and then call the notification plugin with a prepopulated payload. That orchestration pattern—search, summarize, confirm, act—is where plugins deliver real productivity gains while remaining auditable and reversible.
Taking this operational view further, the next step is to examine how the model plans multi-step flows and resolves ambiguous prompts into deterministic sequences of plugin calls. That layer—planning, disambiguation, and fallback strategy—is what turns plugin capability into reliable production behavior you can test, monitor, and iterate on.
Plugin Architecture and Components
Building on this foundation, the practical anatomy of ChatGPT plugins centers on a small set of cooperating components that turn a language model’s intent into safe, auditable actions. In the first hundred words we want you to anchor on the core terms: plugin architecture, ChatGPT plugins, OpenAPI, and manifest—these are not labels, they’re the contract and the runtime rails that let a model call an external system predictably. When you design or review a plugin, always start by asking which component owns each responsibility: discovery, authorization, validation, execution, and observability.
The discovery and contract layer is where the manifest and OpenAPI spec do their work. The manifest advertises the plugin’s name, human-facing description, and the URL for the OpenAPI document so the platform can inject typed endpoint metadata into the model’s planning context. The OpenAPI file defines paths, operationIds, parameter types, enums, and response schemas; because the model uses that schema to form structured calls, you should keep schemas narrow and explicit so the planner can reliably map intents to parameters instead of guessing free-form text. This contract-first approach reduces ambiguity and makes integrations testable.
At runtime the platform implements a request pipeline that enforces auth, sanitization, and execution. The model emits a tool call (operationId, path, typed JSON body) and the platform transforms that into an HTTP request, handling OAuth flows, short-lived tokens, or server-to-server service credentials on your behalf. Put the auth and proxy logic in the platform layer whenever possible so plugins don’t expose long-lived secrets; this also lets you centrally enforce least-privilege scopes and per-user consent without modifying each backend API.
Validation and deterministic error shapes are essential for resilient behavior. The platform should validate responses against the declared response schema and normalize errors into machine-readable codes so the model can decide next steps programmatically. For example, return structured errors like {“code”:”QUOTA_EXCEEDED”,”message”:”…”} instead of plain text; include an idempotency_key for writes and a retry-after header for transient failures. These conventions let you implement automated retry, graceful degradation, or user prompts instead of forcing the model to guess what went wrong.
Security and data-minimization controls sit at the intersection of architecture and policy. Enforce input sanitization and output content classification before returning plugin responses to the model, and design endpoints to avoid returning sensitive fields unless explicitly requested. Sandbox execution of plugin code where possible, log every call with redaction rules, and require explicit consent for any operation that mutates external systems. These measures reduce prompt-injection and permission escalation risk while keeping audit trails clear for compliance reviewers.
Observability and testing close the loop on reliability. Treat plugins like production services: create contract tests that assert OpenAPI conformance, run end-to-end canaries that exercise frequent flows, and emit structured metrics (latency, error codes, auth failures) so you can alert on regressions. Instrument traces that correlate a model request to downstream API calls and include context IDs in payloads to speed incident investigation. This makes it feasible to roll forward or rollback a plugin with confidence when you see abnormal behavior in live usage.
Orchestration is where these components produce real value: the model often composes retrieval calls, user confirmation, and action calls into a single choreography. How do you ensure reliability when plugins perform multi-step actions? Use explicit planner outputs, confirmation checkpoints, and idempotency tokens for each mutating step; for long-running tasks, surface progress tokens or webhooks the model can poll so you don’t block the chat session. In practice, a robust flow looks like: query retrieval plugin, synthesize summary, ask for permission, call action plugin with idempotency_key, and record the audit entry.
These architectural building blocks—contract-first OpenAPI manifests, a secure runtime proxy, schema validation, clear error semantics, and observability—are what make ChatGPT plugins practical at scale. As we move into planning and disambiguation, we’ll examine how the model uses these components to produce deterministic multi-step plans you can test and monitor.
Build Your First Plugin
Building on this foundation, start small and make your first ChatGPT plugins project deliberately narrow: pick one clear capability—create tasks, fetch account balances, or query a knowledge base—and treat the work as an API contract exercise rather than a feature sprint. Define the surface area you need in concrete terms (endpoints, parameters, and exact error shapes) and keep the initial scope to a single read or write action so you can iterate quickly. Front-loading an explicit OpenAPI contract and a compact manifest will pay dividends during development because the chat platform uses those artifacts to plan calls and enforce auth. By focusing on a minimal, well-documented surface you reduce ambiguity and accelerate testing and review cycles.
The first engineering step is contract-first design: write the OpenAPI paths, request/response schemas, enums, and operationIds before you write server code. Make parameters explicit, prefer JSON bodies with typed fields for writes, and include idempotency_key for mutating endpoints so the model can retry safely. Design predictable error shapes—machine-readable codes like QUOTA_EXCEEDED or INSUFFICIENT_PERMISSIONS—so the model can implement fallback logic instead of guessing from free text. When you restrict choice and make the contract deterministic, the model’s planner maps intents to exact API calls with far fewer failures.
Next, wire a local dev server and an auth/egress proxy so you can iterate without exposing secrets. Run a tiny REST service locally (for example, an Express route that accepts POST /tasks and returns a typed task object) and expose it via a secure tunnel during development; how do you connect local code to the chat platform and iterate safely? Use short-lived service tokens or OAuth flows that the platform mediates, and keep long-lived credentials out of your source tree. This pattern keeps auth centralized in the platform proxy, lets you rotate credentials quickly, and mirrors the production runtime where the platform enforces least privilege.
Publish a machine-readable OpenAPI JSON and a compact manifest the platform consumes; the manifest should point to your hosted openapi.json, declare the auth pattern, and include human-facing descriptions that guide user consent. Include examples in your OpenAPI spec for common calls and document required query parameters explicitly so the model can populate them programmatically. A tiny example operation might look like {“operationId”:”createTask”,”path”:”/tasks”,”method”:”POST”} in your spec—operationIds help the planner pick the exact call. Host these artifacts behind HTTPS and version them so the platform and your contract tests can validate compatibility across deployments.
Invest in automated contract validation and safety checks before you trust production traffic to the plugin. Run schema validation (for example, AJV for JSON Schema) on every response, assert explicit HTTP status codes in integration tests, and create canaries that exercise the most common flows end-to-end. Sanitize returned text (trim large blobs, apply content classification where required), redact sensitive fields, and emit structured logs and correlation IDs so an observed model request can trace downstream API calls. These observability primitives let you detect regressions early and audit every action the model requested.
When you’re ready to publish, stage the rollout: register the plugin with the platform, expose it to a small set of testers, and measure success metrics like call latency, schema errors, and consent denial rates. Use the orchestration pattern we discussed earlier—retrieval, summarize, confirm, act—so complex operations include a human checkpoint where appropriate, and require idempotency for multi-step mutating flows. As you gather telemetry, iterate on the OpenAPI contract, tighten auth scopes, and add explicit error codes to cover edge cases. This incremental, contract-driven approach gets you from a running prototype to a production-ready ChatGPT plugin with predictable behavior and clear audit trails.
Security, Privacy, and Safety
Building on this foundation, the biggest security risk with ChatGPT plugins is not a single vulnerability but a chain of weak controls that lets a model, user, or attacker traverse from intent to data exfiltration or unintended side effects. You should treat the manifest and OpenAPI artifacts as security gates, not just discovery metadata, because they define the surface area the model can observe and call. That means front-loading least-privilege decisions into the contract: narrow scopes, explicit response schemas, and examples that limit free-form text returns. How do you balance utility and risk when a retrieval plugin must surface private documents but should never leak credentials or PII?
Start by enforcing strict authentication and scoped authorization at runtime; OAuth and short-lived service tokens belong in the platform proxy rather than embedded in your backend. Require per-user consent for any scope that could return sensitive customer data, and model permission checks as part of the endpoint contract so the planner can request narrower capabilities when possible. For action plugins, use role-based access control (RBAC) and idempotency keys for writes to prevent privilege escalation and accidental replay; for example, require an idempotency_key and scope that only allows creating draft objects until explicit user confirmation.
Data minimization and content filtering should be first-class behaviors in retrieval flows. Design endpoints to accept explicit field selectors (e.g., ?fields=title,summary) so the model requests only the attributes it needs, and implement output redaction on the server side rather than relying on the model to omit fields. Combine lightweight content-classification and regex-based PII scrubbing before returning text to the model, and enforce maximum token or character limits on payloads to avoid hallucination triggers or accidental large-data leaks from long documents. These patterns reduce exposure and keep responses aligned with the declared OpenAPI schemas.
Prompt-injection and malformed responses are real threats; treat every plugin response as untrusted input and validate it against the OpenAPI schema before the model sees it. Implement strict schema validation (for example, JSON Schema with AJV) and normalize errors into machine-readable shapes like {“code”:”INSUFFICIENT_PERMISSIONS”,”message”:”…”} so the planner can decide fallback behavior programmatically. If you return HTML or markdown content, run content-safe rendering and strip active elements; sandbox any executable payloads and never allow the model to execute returned scripts. These checks prevent the model from following attacker-crafted instructions embedded in returned text.
Logging, observability, and audit trails are your forensic backbone—log every plugin invocation with a correlation_id that ties the model prompt to downstream API calls and responses. Record auth context, operationId, sanitized request and response shapes, and the user consent decision; redact sensitive fields at write time and keep immutable audit logs for compliance reviews. Instrument metrics for schema-validation failures, auth denials, and consent rejections so you can surface anomalous patterns quickly and run canaries that exercise the most common paths in production without exposing secrets.
Operationally, require explicit user confirmation before any state-changing operation and design multi-step flows with checkpoints and recoverability in mind. Use idempotency keys, retry-after headers, and progress tokens or webhooks for long-running tasks so the chat session can poll safely rather than blocking or guessing state. Test these controls in a staged rollout with contract tests, end-to-end canaries, and targeted security reviews; taking this concept further, the next topic examines how the model composes planning, disambiguation, and fallback strategies into deterministic, auditable multi-step sequences that maintain safety while delivering real automation.
Use Cases and Industry Impact
Building on this foundation, ChatGPT plugins are already shifting how teams access live data and automate routine work inside conversational interfaces. In the enterprise context, retrieval plugins and action plugins put current facts and constrained operations directly into your chat flow so you don’t have to switch tools or copy-paste context. That immediacy—typed OpenAPI contracts the model can call—front-loads accuracy and reduces the cognitive overhead of manual lookups. Readers who want tangible wins should expect faster decision cycles and fewer context-switching errors when plugins are used judiciously.
A common, high-value pattern appears in knowledge-driven processes: retrieval plugins that query indexed corpora (embeddings + vector DB) and return scoped snippets for summarization. You’ll see this in legal teams who need clause-level answers from contract stores, support engineers who surface relevant KB articles during tickets, and product teams that generate feature-spec drafts from design docs. Implementationally, this looks like a single POST /search endpoint that accepts an embedding or natural-language query and returns typed results that the model can synthesize without hallucinating. Because the model receives structured context, you can automate summarization, citation, and follow-up questioning reliably.
Action plugins transform that context into measurable outcomes by calling downstream systems under explicit consent. In practice we use an orchestration pattern—retrieve, summarize, confirm, act—so the model fetches context, asks a clarifying question, and only then invokes a mutating endpoint with an idempotency_key. That flow powers use cases such as booking travel, creating JIRA issues, kicking off CI pipelines, or sending targeted customer notifications. Design your OpenAPI surfaces with narrow parameter sets, stable operationIds, and predictable error codes so the planner can retry, fallback, or ask for clarification instead of guessing state.
Sector-specific impact is significant because plugins change who can access what and how fast. In healthcare, for example, a retrieval plugin can pre-digest EHR notes into a practitioner-facing brief while enforcing field-level redaction and consent checks; in finance, an action plugin can prepare trade tickets for human approval while logging every intent for audit. Retailers use plugins to orchestrate inventory reconciliation and flash-sale orchestration across order, fulfillment, and pricing systems. Each vertical demands data-minimization, RBAC, and auditable trails—so you should bake compliance and sanitization into API contracts rather than relying on the model to filter outputs.
Beyond verticals, developer productivity and platform velocity change measurably when you automate repetitive developer workflows with plugins. Teams embed code search and contextual fix suggestions into pull-request conversation threads, auto-generate release notes from commit metadata, and trigger test suites or hotfix branches from chat prompts. How do you measure ROI for a plugin? Track signal-level metrics: call latency, schema-validation failures, consent-denial rates, and downstream task completion rates; combine those with qualitative measures like reduced handoffs and fewer context-switches in sprint retrospectives.
These gains come with responsibilities: security, observability, and staged rollout practices make the difference between a helpful assistant and an accidental data leak. Start small with a narrow surface area, build contract-first OpenAPI specs, enforce least-privilege auth, and run end-to-end canaries that validate error shapes and consent flows. Taking this concept further, production-grade deployments pair real-time metrics with immutable audit logs and clear human checkpoints so you can scale plugin-driven automation while maintaining trust, compliance, and operator control.