Objectives and Scope
Building on this foundation, we start by aligning measurable objectives that guide every architectural decision for scalable chat-based AI applications and the accompanying reference architecture. The primary objective is predictable user experience: low, consistent latency and graceful degradation under load. Secondary objectives include cost-efficiency at scale, strong security and privacy controls, observability for model and system behaviour, and developer productivity so teams can iterate on prompts, tools, and integrations rapidly. How do you balance real-time latency with cost and privacy when user expectations and regulatory constraints conflict?
Scope clarification matters because it prevents scope creep during design and implementation. This architecture covers end-to-end runtime concerns: message ingress and routing, session and state management, model hosting and inference orchestration, prompt/response pipelines, retrieval-augmented generation (RAG) and vector search, streaming responses, and production telemetry and alerting. It also includes deployment and operations patterns—container orchestration, autoscaling rules, model versioning, and CI/CD for model and service updates. It does not prescribe a single model vendor, specific UI/UX designs, or the research-phase training pipelines for custom models; those are intentionally out of scope.
We prioritize objectives differently depending on the use case, and that prioritization should shape the architecture choices you make. For a consumer chat app you typically prioritize horizontal scalability and low-latency streaming to handle thousands of concurrent WebSocket connections, which drives choices like stateless front-end routing, horizontally sharded inference pools, and aggressive caching of common responses. For an enterprise assistant you prioritize data residency, access control, and auditability, which leads to on-prem or VPC-isolated model hosts, fine-grained access logs, and stricter retention policies. These trade-offs inform whether you optimize for GPU-backed model servers, or for cheaper CPU inference with aggressive quantization and batching.
Specify measurable non-functional requirements early so the architecture enforces them rather than retrofitting controls later. Define SLOs for end-to-end response time (for example, p50/p95 targets), uptime SLAs for critical flows, and maximum acceptable cost per thousand messages. Tie observability requirements to these SLOs: instrument request traces across the messaging layer, the orchestration/queueing layer, and the model inference layer; capture token-level latency where streaming is used; and surface drift metrics for model quality. For regulated domains, include data lineage and encryption-at-rest/in-transit requirements and describe retention policies in the architecture so engineers implement them consistently.
Design for extensibility and integration so the reference architecture remains useful as models and infra evolve. Use clear API contracts and an adapter pattern between your orchestration layer and model providers so you can swap or hybridize providers without rippling changes across the platform. Favor event-driven components for pipelines that need to chain retrieval, prompt enrichment, safety checks, and response filtering; implement a lightweight policy engine for runtime safety decisions. For deployments, leverage container orchestration and node pools with mixed GPU/CPU capacity, and separate autoscaling rules for stateless routing, stateful session stores, and inference backends to optimize cost and performance independently.
Finally, set explicit boundaries: this architecture assumes production-grade inference and integration, not research model development, bespoke on-device model compilation, or deep UX design work. With objectives and scope clearly defined we can map each objective to concrete components, patterns, and example configurations so you can implement a proven, repeatable architecture rather than re-solving the same trade-offs in every project.
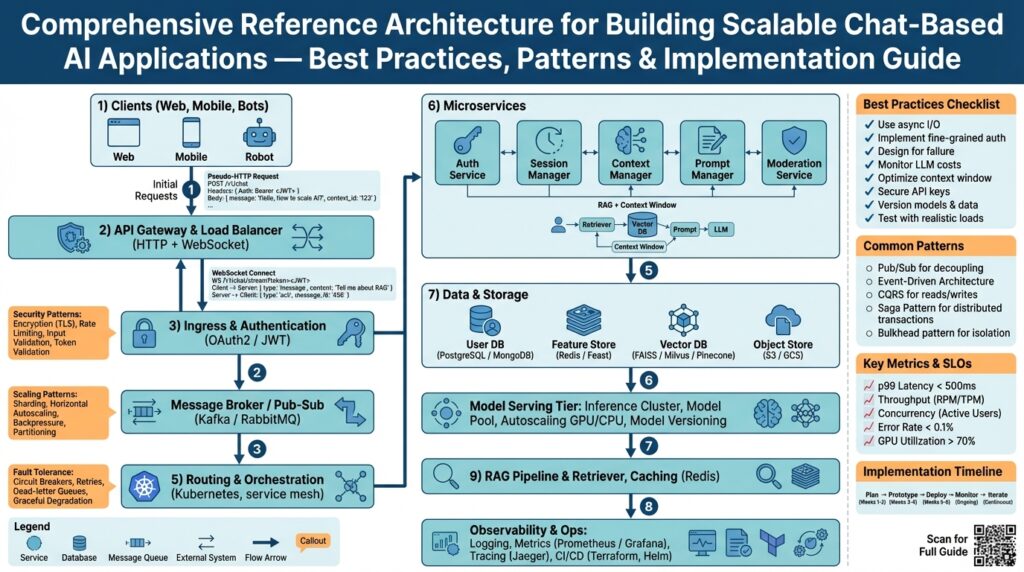
Core Architecture Overview
Building on this foundation, we map measurable objectives directly to a compact set of runtime components so you can reason about trade-offs for scalable chat-based AI systems from day one. Start by treating model hosting and inference orchestration as first-class services that sit behind a stateless routing layer; this front-loads latency, cost, and privacy decisions into the architecture rather than leaving them to implementation details. By emphasizing container orchestration and explicit node pools early, you give teams concrete knobs—GPU vs CPU, pre-warm policies, and autoscaling windows—to meet p50/p95 latency and cost SLOs.
At the core, the system decomposes into five interacting planes: ingress and routing, session and state management, model hosting and inference orchestration, retrieval/RAG, and observability/safety policy. Each plane has clear responsibilities and API contracts so we can swap implementations without rippling changes. For instance, the orchestration plane exposes a provider adapter that normalizes calls to hosted models, on-prem inference, or managed APIs, letting you hybridize vendors while keeping the routing and session code stable.
Message ingress and routing should be designed for connection scale and predictable routing latency. Implement a lightweight edge proxy that accepts WebSocket and HTTP/2 streaming, authenticates requests, and routes to stateless frontends; keep these frontends ephemeral and horizontally scalable so they can be killed and restarted without losing throughput. Use consistent hashing or session tokens to direct a session to a suitable inference pool when affinity matters, and fall back to an asynchronous queue for non-interactive workloads so you avoid head-of-line blocking.
Session state must be explicit and sharded, not embedded in process memory. Choose a fast distributed store (for example, a Redis or Dynamo-style service) for short-lived session context and a durable store for transcripts that require audit trails. Separate conversational context (recent turns and slot-values) from long-term knowledge pointers; store only what you need for quality and compliance, and encrypt both at rest and in transit. Shard by customer or tenant to simplify data residency and retention policies.
Model hosting and inference orchestration are where cost, performance, and developer velocity collide. Run model servers in dedicated GPU and CPU node pools, and use an orchestration layer that can route requests based on model version, cost policy, or latency budget. Implement canary traffic for new model versions, automatic fallback to quantized CPU models when GPU pools are saturated, and an adapter pattern so you can substitute a managed provider without changing upstream logic. Instrument token-level latency in the orchestrator so you can diagnose slow layers quickly.
Retrieval-augmented generation requires its own service boundary: a retrieval service that handles embedding generation, index queries, freshness, and caching. Keep vector indexes isolated from inference hosts and synchronize metadata through an event bus to preserve consistency. Cache embedding results for recent or popular queries to reduce cost; use hybrid search (BM25 + vector) for precise retrieval when exactness matters. For regulated deployments, ensure the retrieval layer complies with data residency and redaction requirements before content reaches any model host.
Streaming responses improve perceived latency but introduce complexity: you must manage token-level backpressure, incremental safety checks, and partial-result caching. How do you ensure end-to-end latency stays within SLOs? Prioritize prompt enrichment and retrieval before sending the first token, perform lightweight safety heuristics synchronously, and defer heavier policy checks to an out-of-band filter that can redact or recall content if necessary. Provide the client with deterministic fallbacks—clear error frames or truncated summaries—so the UX degrades gracefully when load spikes.
Observability ties the whole architecture to measurable goals. Trace each user request across the routing layer, the retrieval pipeline, and the inference hosts; emit token-level timing, model version, and cost-per-inference metrics. Surface drift signals (semantic drift in embeddings, latency increases, and quality regressions) and wire them into automated alerts and canary rollbacks. Run synthetic traffic that mimics peak conversational patterns so the SLO dashboard reflects realistic behavior rather than idealized tests.
For deployment and operations, marry container orchestration with policy-driven autoscaling and safe degradation strategies. Use separate autoscalers for stateless routing, the session store, and inference pools so you can optimize each for different scaling characteristics; pre-warm GPU instances or keep warm pools for bursty conversational workloads. Implement CI/CD that treats models as versioned artifacts alongside service manifests, and bake circuit breakers that route heavy workloads to cheaper, lower-fidelity models when cost or capacity thresholds are reached. With these boundaries and patterns in place, we can move from architecture to concrete implementation patterns that satisfy the objectives you defined earlier.
Data Ingestion and Processing
Building on this foundation, the first place we fight latency and noise is at the pipeline entry point: data ingestion. When you ingest chat messages, user uploads, or external documents you decide what gets admitted, validated, and enriched before it ever reaches a model host. Explicitly treating ingestion as a policy-and-transform layer lets us enforce rate limits, schema contracts, tenant sharding, and early redaction—each of which directly reduces downstream cost and compliance risk. By front-loading these decisions we keep end-to-end latency predictable and make downstream processing repeatable and auditable.
A robust processing design separates synchronous, low-latency transforms from asynchronous enrichment tasks. Define synchronous transforms as small, deterministic operations you run in-line (for example: authentication, JSON schema validation, profanity redaction, and short-window context stitching). Define asynchronous processing as event-driven work that can tolerate delay (for example: full-text indexing, heavy NLP enrichment, or long-running document conversions). This split lets you meet p50/p95 SLOs for interactive flows while still supporting complex offline workflows; the pattern resembles an ETL (extract-transform-load) pipeline but optimized for conversational workloads and streaming responses.
How do you keep the ingestion surface reliable at scale? Use an ingestion gateway that writes canonical events to a durable, ordered queue (for example a partitioned message broker) and exposes a lightweight synchronous path for interactive requests. The gateway should attach provenance metadata (request id, tenant id, model version hint) and run quick safety heuristics before acknowledging the client. For tenant isolation, shard queue partitions by customer to make retention and residency policies straightforward, and implement idempotency keys so retries don’t duplicate expensive processing. These practical choices reduce head-of-line blocking and make bursty traffic easier to absorb.
Consider a typical request flow to illustrate the pattern: the client posts a message to POST /v1/messages and the gateway performs auth and schema checks; if the message is interactive we write a compact context record to the session store and publish an ingest event to the broker; a short-path enrichment service fetches recent context, performs lightweight retrieval or prompt templating, and forwards a normalized request to the orchestrator; meanwhile, heavier enrichment (OCR, full-document embeddings) is handled by separate consumers that annotate the transcript asynchronously. This sequence ensures you can stream the first tokens back to the user quickly while downstream processors add value without blocking the interaction.
For retrieval-augmented generation workflows, treat embedding generation and index queries as distinct services behind clear SLAs. Generate embeddings either synchronously for small documents or asynchronously for large corpora, and keep vector indexes (vector search systems) isolated from inference hosts to avoid compute contention. Employ hybrid search—BM25 or exact-match filters combined with vector search—for precision-sensitive queries, and cache recent embedding results to cut costs on hot queries. In regulated deployments, run the retrieval pipeline inside the required data residency boundary and apply redaction before any content reaches shared indexers or external model providers.
Operationally, instrument ingestion and processing end-to-end: emit queue lag, per-shard throughput, validation error rates, and token-level latency for synchronous enrichments. Build circuit breakers that route traffic to cheaper quantized models or simplified flows when the ingestion pipeline is overwhelmed, and design replayable event logs so you can reconstruct transcripts for audits and debugging. Taking these steps makes processing deterministic and observable, and it naturally hands off to the orchestration and inference layers we discuss next so you can scale model hosting without reworking upstream plumbing.
Vector Store and Retrieval
Building on this foundation, retrieval quality and runtime predictability hinge on how you design and operate the vector store and vector search pipeline. If retrieval-augmented generation is the amplifier for your models, the vector store is the signal chain that determines what gets amplified; we must therefore treat embeddings, index topology, and metadata filtering as first-class components. Early in the request path you should generate or fetch embeddings and apply tenant-aware filters so the index query returns precise, lawful candidates within your latency SLOs. By front-loading these decisions you reduce noisy hits that cause downstream token-cost and hallucination risks.
Start by separating embedding generation, index management, and query serving into distinct services with clear SLAs and adapter contracts. Generate embeddings synchronously for short documents or interactive queries when p95 latency matters, and fall back to asynchronous embedding pipelines for bulk ingestion or large files; keep an idempotent task queue for re-embeds. Store embeddings alongside compact, queryable metadata (tenant id, document version, content hash, redact flags) so you can apply deterministic filters before retrieval. Treat the embedding vector and its metadata as a single atomic record in your ingestion event stream to avoid consistency gaps between index state and transcript storage.
Choose your index topology explicitly based on recall, write-patterns, and hardware cost. Exact indexes (flat L2/cosine) are simple but expensive at scale; approximate nearest neighbor (ANN) methods like HNSW or IVF+PQ give orders-of-magnitude improvement in query throughput at a modest recall cost. Normalize vectors for cosine similarity or use dot-product if your model outputs unnormalized vectors; quantization and product quantization reduce memory but raise recall trade-offs, so benchmark recall@k and MRR against production queries. When low-latency retrieval is essential, prefer an HNSW index tuned for low efSearch; when ingestion rate is high and incremental updates matter, an IVF approach with periodic compaction often works better.
Operational concerns make or break production behavior: sharding, replication, incremental upserts, and re-embedding strategies must be planned up front. How do you ensure freshness when documents change or policies require redaction? Implement versioned embeddings and a compact tombstone mechanism so updates and deletes propagate without full index rebuilds, and schedule regular background re-embeds for model upgrades with canary testing. Shard by tenant or by hash to keep per-shard latency predictable, and replicate hot shards across zones for availability. Enforce data residency and redaction at the retrieval layer before any vector leaves the required boundary.
The query pipeline should layer fast filtering, hybrid search, and deterministic reranking so the candidate set is both relevant and safe. Use a hybrid approach—BM25 or exact-match filters followed by ANN vector search—to ensure precision for structured queries; then apply a lightweight reranker (semantic or lexical) before passing context to the model. For example, a simple call might look like: candidates = index.search(query_emb, k=20, filters=tenant_filter); reranked = reranker.score(candidates, query_text)[:k]. Cache embeddings for recent queries and cache top-k results for popular prompts to cut cost and shave milliseconds off p95 latency, but expire caches on document updates.
Instrument retrieval end-to-end and treat quality metrics as runtime signals. Emit query latency, shard load, recall@k, rerank lift, and cache hit rate; run synthetic queries that mirror peak conversational patterns so SLOs reflect realistic behavior. Tie index configuration changes to AB tests that measure downstream model cost and user satisfaction rather than relying on raw vector metrics alone. With robust monitoring, replayable ingestion events, and a policy-driven refresh cadence for embeddings, we can keep retrieval aligned with your latency, cost, and compliance objectives while handing off safe, high-quality candidates to the inference layer.
LLM Integration and RAG
Building on this foundation, integrating large language models with a robust retrieval layer is the single most effective way to control hallucinations, reduce token cost, and deliver predictable user-facing answers. Early in the request path we should treat LLM integration and retrieval-augmented generation (RAG) as coordinated subsystems rather than independent features: the orchestrator must know when to call vector search, when to enrich prompts, and when to fall back to cached summaries. Front-load those decisions so the runtime can enforce token budgets, data-residency constraints, and safety checks before any sensitive content reaches a model host. Doing this up-front keeps p95 latency and downstream inference cost within the SLOs you defined earlier while improving answer relevance.
Start by implementing a provider adapter and a lightweight orchestration policy so you can hybridize managed APIs, on-prem servers, and cheaper quantized models without rewriting the routing layer. A good adapter abstracts authentication, rate-limits, batching, and model-specific prompt formats; the orchestration layer then applies routing rules—canary to new model versions, cost-based fallbacks to CPU quantized models, or affinity to GPU pools—based on request metadata. How do you decide routing in practice? Route by an explicit latency budget and tenant policy: if budget < 300ms route to a low-latency distilled model; if data residency requires on-prem, route to the VPC-isolated host; otherwise prefer higher-fidelity managed models. Instrument these paths so we can A/B test model choices against downstream satisfaction and cost metrics.
Prompt engineering becomes a runtime concern when you combine retrieval with LLM inference; enrich the prompt with compact, high-value context rather than full transcripts. Assemble the prompt in three stages: filter and rerank retrieval candidates, extract or summarize the top candidates to fit your token budget, then apply a deterministic template with guardrails for instruction clarity. For example, instead of sending 20 raw documents, run a lightweight reranker and produce a 250-token summary of the top 3 candidates plus a concise system instruction that constrains hallucination. This approach reduces token charges, improves relevance, and makes safety heuristics more effective because the content presented to the model is already curated.
The retrieval pipeline must be a separate service with SLAs: embedding generation, index query, and metadata filtering should each be independently scalable and observable. Generate embeddings synchronously only when interactive latency matters and cache those embeddings for hot queries; for bulk or document updates, use asynchronous re-embed tasks with tombstones and versioned vectors so updates propagate without a full rebuild. Use hybrid search—text filters or BM25 to narrow the candidate set, followed by ANN vector search—to preserve precision while keeping vector search latency predictable. Enforce tenant-aware filters and redact or isolate content at the retrieval layer to meet compliance before any candidate is passed to the LLM.
At runtime, prioritize token-level observability and graceful degradation: measure token-generation latency, cache hit rates for top-k retrievals, and model cost per request so the orchestrator can make real-time decisions. Stream the first tokens only after prompt enrichment and lightweight safety checks, and use an out-of-band policy engine to perform heavier moderation that can redact or retract content if needed. Implement fallbacks that return truncated summaries or explicit error frames when vector search is overloaded or a model pool is saturated; deterministic UX behavior makes degradation tolerable and debuggable for both users and engineers.
To operationalize these ideas, treat LLM integration and RAG as composable capabilities in your platform: build adapters for model providers, a retrieval service with versioned indexes, a prompt-enrichment pipeline that enforces token budgets, and an orchestration policy that optimizes for latency, cost, and compliance. Instrument every handoff—ingest, embed, index, rerank, prompt, and inference—so we can iterate on routing rules and rerank thresholds with measurable downstream impact. The next section will walk through concrete implementation patterns for canaries, autoscaling inference pools, and replayable tests that validate end-to-end behavior.
Scaling, Security, Observability
Building on this foundation, predictable scalability, robust security, and comprehensive observability are the operational pillars that determine whether a chat-based AI system performs under real-world stress. We prioritize scalability, security, and observability from the start because they are interdependent: scaling decisions affect exposure surface and telemetry volume, security controls constrain routing and data flow, and observability gives the signals we use to tune autoscaling. How do you architect these concerns so they reinforce—rather than fight—each other under load?
Start with explicit scaling primitives that map directly to your SLOs and cost targets. Treat node pools, pre-warm policies, and autoscaling (automatic horizontal scaling based on metrics) as first-class knobs in your orchestration layer; separate GPU-backed inference pools from CPU quantized pools and apply different scaling rules to each. Implement predictable affinity for long-lived WebSocket sessions via consistent hashing or session tokens to avoid head-of-line blocking, and use a durable queue with partitioning by tenant for asynchronous workloads so we can smooth bursts without dropping interactive latency guarantees. Instrument and act on concrete signals—request concurrency, queue lag, token-generation throughput, and GPU utilization—rather than relying on simple CPU thresholds to scale inference hosts.
Embed security controls into the routing and data plane rather than bolting them on afterward. Enforce tenant isolation at the storage and index level, apply encryption-at-rest and in-transit, and redact or tokenize PII at ingestion so models never see sensitive material unless explicitly permitted. Use a policy engine that evaluates data-residency, retention, and classification rules before any retrieval candidate is forwarded to a model host; where regulations demand it, route requests to VPC-isolated or on-prem inference pools by policy. Make the model-provider adapter responsible for provider-specific privacy knobs (for example, provider-side logging toggles and post-call scrubbing) so you can switch vendors without reworking privacy logic across the stack.
Operational observability must be token-aware and end-to-end to be useful for chat systems. Token-level latency (the time to produce individual generated tokens) is a high-resolution metric that highlights bottlenecks inside the model host and the orchestrator; capture it alongside p50/p95 end-to-end response times, recall@k for retrieval, and cost-per-inference. Propagate a single request id through the ingress, retrieval, prompt-enrichment, and inference lanes and emit distributed traces and lightweight spans so you can reconstruct slow requests. Run synthetic traffic that mirrors realistic conversational patterns and tie those tests to alert rules and runbooks so on-call engineers can react to regressions in quality, latency, or cost.
Design for interplay: let observability inform scaling, and let security constrain scaling decisions where necessary. Use telemetry-driven autoscaling policies that consider cache hit rates, retrieval latency, and inference tail latency; when retrieval or reranking errors spike, trigger fallback routes to cached summaries or lower-fidelity models. Enforce security-driven placement: mark certain tenants or classes of requests as non-evictable from VPC-only node pools and prevent automated scaling from routing those flows to public managed providers. This way, autoscaling responds to meaningful signals while preserving compliance and predictable user experience.
Streaming responses and partial outputs complicate this balance, so treat streaming as a mode that requires extra safety and telemetry. Implement incremental safety heuristics that run synchronously on the first tokens and heavier, out-of-band moderation that can redact or retract after the fact; capture partial-result metrics so you can measure how much of an output was streamed before an active moderation action. Provide deterministic fallbacks on overload—explicit error frames or truncated summaries—so client UX degrades gracefully and engineers can reproduce failure modes from logs.
Operationalize these patterns by treating models as versioned artifacts in CI/CD, running canaries for model versions and index changes, and maintaining replayable event logs for debugging and compliance. Run periodic chaos or load tests to validate autoscaling policies and security placement under failure scenarios, and expose curated dashboards that answer core SLO questions: are we meeting p95 latency, are we within cost-per-thousand messages, and does any tenant violate residency constraints? With these practices in place, you’ll have the telemetry, controls, and elasticity to keep chat applications performant, compliant, and debuggable as they scale.



