Why Conversational AI Matters
Conversational AI shifts interfaces from rigid menus to natural language, letting users complete tasks faster and with less friction. It enables 24/7 self-service for support, personalized experiences by maintaining context across interactions, and accessible entry points for users who prefer speech or simple phrasing. Real-world incarnations include ticket-triaging chatbots that reduce time-to-resolution, in-app assistants that run queries or automate multi-step workflows, and developer-facing copilots that accelerate coding and debugging.
For engineering teams, conversational systems unlock measurable ROI: lower support costs, higher engagement, and new product surface areas driven by user dialogue data. Building for success means modeling intents and context, designing clear handoffs and graceful failure modes, instrumenting conversations for analytics (task success, latency, escalation rate), and treating privacy and consent as core requirements. Start small with transactional skills, iterate using live feedback loops, and prioritize observability and test suites so the agent improves reliably as usage grows.
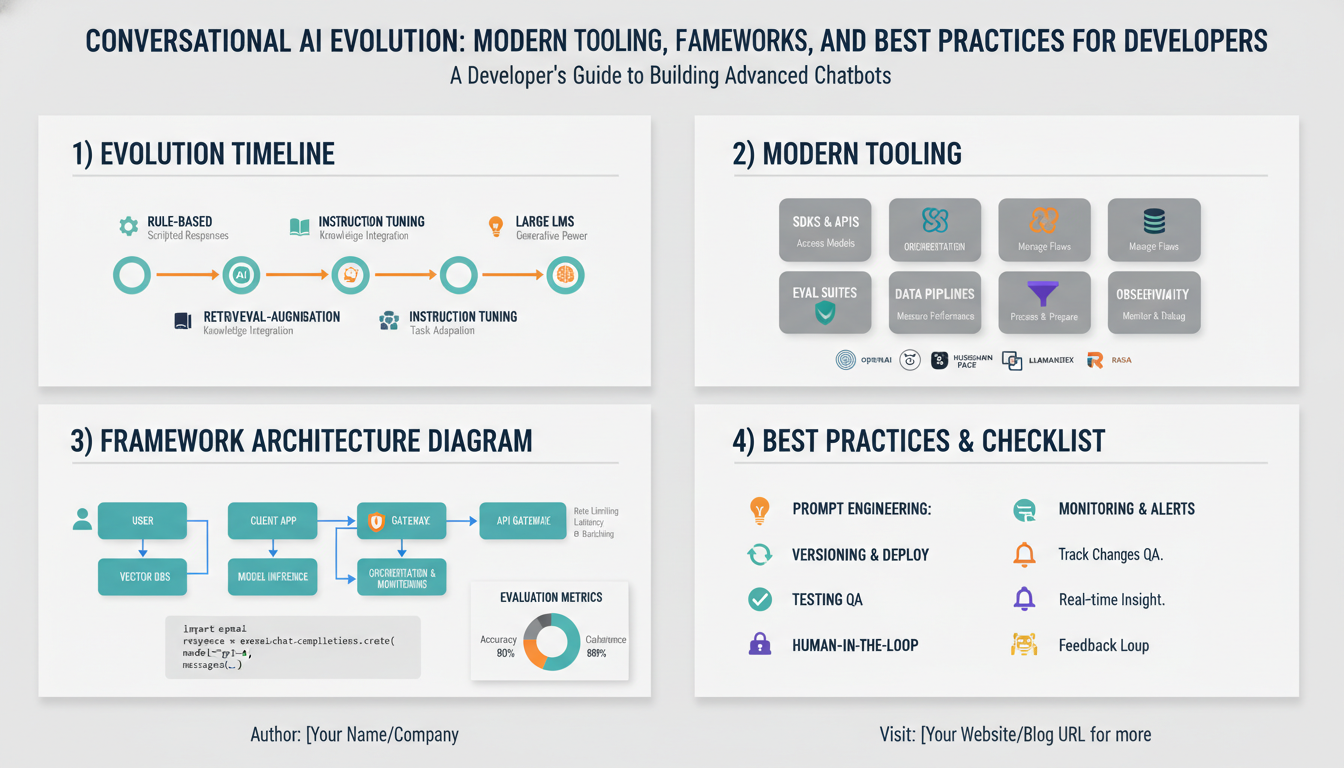
Evolution of Conversational AI
Early systems used hand-crafted rules and decision trees: deterministic flows that mapped keywords to scripted responses and required heavy maintenance. Statistical models then introduced intent classification and slot-filling, letting systems generalize from examples and handle simple variations. Sequence-to-sequence neural networks enabled end-to-end response generation, but struggled with factual consistency and multi-turn coherence. The transformer breakthrough shifted the field: large pretrained language models provided fluent, context-aware generation and simplified NLU pipelines by absorbing many linguistic patterns during pretraining.
Contemporary stacks combine strengths instead of relying on a single paradigm. Developers pair an LLM with retrieval-augmented generation (RAG) to ground answers in up-to-date documents and reduce hallucination, use embeddings and vector stores for semantic search, and orchestrate modules (NLU, policy, action connectors) to enforce business logic and safe fallbacks. Instruction tuning and reinforcement learning from human feedback (RLHF) refine behavior for usability and alignment. Observability and evaluation moved from simple accuracy metrics to task success, turn-level latency, escalation rates, and real-user A/B experiments, which guide iterative improvements.
Practical trade-offs now dominate engineering decisions: latency versus model size, deterministic routing versus generative flexibility, and privacy versus external retrieval. Tooling that automates testing, simulates conversations, and captures rich telemetry shortens the feedback loop. For teams building production agents, the modern approach is modular: ground language models with curated knowledge, enforce policy with deterministic connectors, and instrument aggressively to keep the agent reliable, measurable, and maintainable.
Core System Architecture
Design a modular, layered system where each concern is separable and testable: a thin client layer (web, mobile, voice) talks to an API gateway that enforces auth, rate limits, and routing. The gateway forwards requests to an orchestration layer that composes NLU, retrieval, generation, and business-action modules according to policy. Keep the large model(s) and vector store behind well-defined interfaces so you can swap providers or run hybrid on-prem/cloud deployments.
Make state explicit: a session/context store manages short-term conversation state and long-term user memory, while embeddings and a vector index provide semantic retrieval for grounding. Design the context window manager to construct prompts deterministically from context, retrieval results, and system instructions to control latency and token costs.
Separate policy and execution: a policy engine evaluates intents, safety checks, and routing rules and either issues a deterministic connector call (datastore update, third-party API) or invokes a generative response. Use verifier modules (fact-check/RAG or tool-augmented grounding) to reduce hallucination before returning user-facing text.
Instrument everything: request/response traces, turn-level latency, task success metrics, and error classification feed the observability pipeline and automated tests. Provide a sandboxed staging environment to run simulated conversations and CI checks for regressions. Enforce data governance at the I/O layer—encryption, consent flags, selective logging, and retention policies—so the system remains auditable and privacy-compliant.
Typical runtime: client → gateway → orchestrator → (context + retrieval) → model → policy/verifier → connector or response, with telemetry and replayable traces captured at each step.
Modern Tooling and Frameworks
Adopt a modular developer stack that cleanly separates orchestration, retrieval, model runtime, and connectors so you can iterate on parts without a full rewrite. Use orchestration libraries and lightweight agents to route intents to deterministic connectors or to generate responses; pair generation with retrieval-augmented generation (RAG) backed by a vector store for grounding and reduced hallucination. Choose a vector database that fits your scale and latency needs and keep embeddings, chunking, and recall strategies versioned alongside your code. Optimize inference with model-serving layers that support batching, quantization, and hardware-aware runtimes so you can trade off latency and cost predictably. Treat prompts as code: store templates, expose parametrized prompt builders, and run automated prompt regression tests in CI to catch behavioral drift. Instrument every turn with tracing, turn-level latency, task success, escalation rate, and semantic-quality signals; feed those into alerting and a replayable conversation lake for offline analysis and labeling. Embed safety and policy checks as policy modules that can short-circuit responses or trigger handoffs to human agents. Automate testing using simulated user journeys and adversarial utterance suites to validate slot-filling, context carryover, and connectors under load. For deployment, prefer reproducible infra (containerized services, IaC, and staging sandboxes) and a feature-flagged rollout for model or prompt changes. Finally, version everything that affects behavior—prompts, retrieval corpora, embeddings, model checkpoints, and policy rules—so A/B experiments and rollbacks are fast, auditable, and low risk.
Model Selection and Prompting
Match model capability to the job: use compact, quantized models (or distilled variants) for low-latency classification, routing, or short responses; choose larger, instruction-tuned models for multi-step reasoning, synthesis, or creative generation. For knowledge-sensitive outputs, pair a mid-size model with retrieval-augmented generation (RAG) so the model stays grounded while keeping costs predictable. Treat model choice as a tradeoff between latency, cost, context window, and factuality, and validate with A/B tests on real traffic and representative prompts.
Control behavior with layered prompting. Start with a concise system instruction that sets role, format, and safety constraints, then add a context block: relevant user history, retrieved documents, and schema expectations. Use few-shot examples when you need a specific style or structured output; prefer zero-shot plus explicit requirements when examples would bloat the context window. Set sampling parameters to match task needs (low temperature and top-p for factual answers; higher temperature for creative tasks) and cap max tokens to limit cost and prevent runaway responses.
Make prompts reproducible and testable: store templates in code, parameterize variable slots, version prompt changes, and run prompt-regression tests in CI against golden examples. Enforce output structure by asking for machine-parseable formats (JSON schema or delimited fields) and validate model responses with a verifier step that checks schema, citations, or retrieval hits; if validation fails, trigger a deterministic fallback or retry with a stricter prompt.
Instrument and iterate: log prompt + model config + response quality signals (task success, hallucination rate, latency), run small experiments when you swap models or change temperature, and rollback via feature flags if behavior degrades. Finally, bake policy checks into the pipeline rather than relying on prompts alone—use deterministic filters or human handoffs for high-risk actions.
Deployment, Monitoring, and Safety
Treat releases as behavioral changes, not just code updates: package model checkpoints, prompt templates, retrieval corpora, and policy rules together and deploy them with immutable artifacts and infrastructure-as-code. Use containerized services and a staging sandbox to run end-to-end simulated conversations and CI prompt-regression tests before any production rollout. Gate model or prompt changes behind feature flags and phased rollouts (canary or percentage-based traffic splits) so you can measure impact and rollback quickly if metrics degrade.
Instrument every turn: capture request/response traces, context construction, retrieved evidence, model inputs/outputs, latency, and downstream connector outcomes. Surface key SLOs—turn-level latency, task success rate, escalation rate, hallucination alerts, and error-class distributions—in dashboards with automated alerts for regressions. Feed replayable conversation logs into a labeling pipeline to drive A/B experiments, prompt tuning, and automated retraining of classifiers. Run adversarial and load tests in staging to validate slot-filling, context carryover, and connector resilience under stress.
Embed layered safety: enforce deterministic policy checks before and after generation to block or transform unsafe outputs, verify schema and citation requirements with a verifier module, and fall back to deterministic connectors or human escalation for high-risk intents. Apply rate limits, auth, and consent flags at the gateway; use selective logging, encryption at rest/in transit, and retention policies to meet privacy requirements. Maintain auditable change logs for prompts, retrieval indices, embeddings, and model versions so investigations and rollbacks are fast.
Operationalize human-in-the-loop workflows for edge cases, and treat every alert as a data point: triage, label, and fold into your test suites and metrics so the system becomes measurably safer and more reliable over time.



