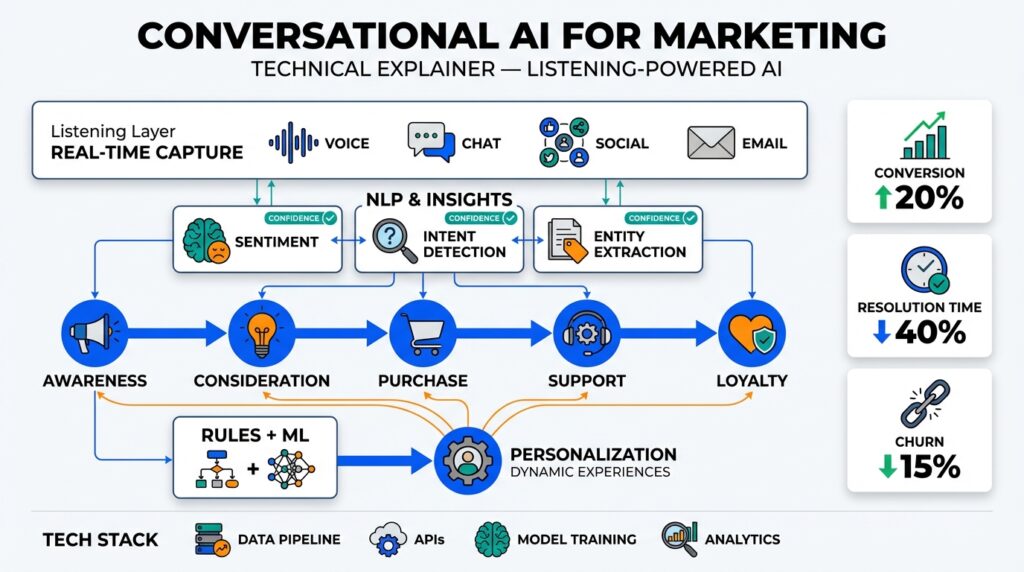
What is listening-powered AI?
Think of a system that hears every customer whisper across chat, call, social, and product telemetry, then turns those whispers into timely, actionable conversation—this is listening-powered AI in practice. At its core, listening-powered AI combines conversational AI capabilities with continuous, multi-channel signal ingestion so you can detect intent, sentiment, and emergent topics as they happen. By front-loading listening into the feedback loop, you move from scheduled surveys and batch analysis to real-time adaptation across the customer journey, which improves relevance and reduces latency in personalization.
Building on this foundation, the technical stack for listening-powered AI is purposefully different from a traditional chatbot pipeline. The first layer is high-throughput ingestion: streaming connectors that normalize messages from chat transcripts, voice transcripts, social APIs, and product event streams. Next comes a real-time processing layer—usually a stream processor or event router—that runs lightweight NLP for intent classification and sentiment scoring, then augments events with embeddings or contextual metadata. Finally, a decision layer maps those enriched events to actions: open a support ticket, trigger a targeted message, adjust a recommendation model, or escalate to a human agent.
Architecturally, you’ll see a hybrid of streaming and model-serving patterns rather than a single monolithic conversational model. Use a message broker (Kafka, Pulsar) to decouple producers from consumers, a stream processor (Flink, ksqlDB, or managed streaming) for event-time semantics, and a low-latency model store for classification and embedding lookups. For example, an event handler might look like stream.map(transcript -> enrich(transcript)).filter(enriched -> enriched.intentConfidence > .7).routeTo(actionTopic), where enrich calls an intent model and a vectorizer whose vectors are indexed in a vector store for fast similarity. Maintain a stateful session store to preserve conversation context across channels and a feature store for user-level signals so downstream personalization models have reliable inputs.
How do you apply this to marketing and customer journeys? Imagine a product launch: social monitoring surfaces increasing confusion about a new feature, support transcripts show a spike in a specific error, and in-app telemetry reveals users abandoning the onboarding flow. A listening-powered system correlates those signals in real time, routes high-priority incidents to support, updates in-app guidance dynamically, and feeds labeled examples back to training pipelines. That loop shortens time-to-response from hours or days to minutes, improves conversion where customers would otherwise churn, and creates a continuous training stream that refines your conversational AI’s accuracy.
There are trade-offs to evaluate before adopting listening-powered AI. Low-latency inference and continuous processing increase compute and engineering complexity compared to scheduled batch pipelines, and you must enforce strict privacy, consent, and data-retention policies when ingesting cross-channel customer data. Data quality matters: noisy transcripts and poorly labeled intents will amplify errors across real-time actions, so invest in annotation, confidence thresholds, and human-in-the-loop review. Choose where to push intelligence—edge vs. centralized model serving—based on latency requirements and compliance constraints.
Practically, start by instrumenting one high-value channel and building a minimal feedback loop: ingest, classify, action, and feed results back to training. Measure business KPIs—time-to-resolution, conversion lift, and churn reduction—alongside model metrics like precision at operation thresholds. Taking this approach lets you incrementally expand to more channels and richer personalization without overwhelming your stack. In the next section we’ll look at implementation patterns and sample pipelines that turn these concepts into deployable systems for transforming customer journeys.
Marketing benefits and use cases
If you can hear customers across chat, voice, social, and product telemetry in near real time, you can act before engagement turns into churn. Listening-powered AI and conversational AI give marketing teams a continuous signal stream that surfaces intent, sentiment, and emergent topics—so you can convert a confusing product launch into an opportunity for conversion instead of a support spike. By front-loading listening into the marketing feedback loop we get faster insights, tighter personalization, and reduced time-to-action across customer journeys and channels.
One clear marketing benefit is faster and more precise segmentation. When our stream processor tags an event with intent and sentiment, you can move beyond batch segments built on demographic heuristics to behaviorally defined cohorts that update every minute. Building on this foundation, you can target users who expressed purchase intent but show negative sentiment with recovery flows, or exclude recently satisfied customers from retention offers—both of which reduce wasted spend and improve campaign ROI. These dynamic segments power real-time personalization and make your campaigns more contextually relevant.
Another high-impact benefit is automated orchestration of cross-channel responses. Instead of waiting for analysts to correlate social noise and product telemetry, a listening-powered pipeline triggers immediate actions: update an in-app banner, enqueue a high-touch support task, or adjust a recommendation model. For example, a rule might look like stream.filter(e -> e.intent==”pricing” && e.sentiment<0.2).emit(“highPriorityMarketing”)—which routes contacts into a sales outreach flow and surfaces labeled transcripts to retrain ranking models. This reduces mean time to resolution and closes the loop between detection and remediation.
How do you measure uplift from these capabilities? Tie model outputs to business KPIs and instrument attribution at the event level. Use randomized holdouts or feature-flagged rollout windows to compare conversion lift, time-to-resolution, and churn rates between listening-enabled flows and control groups. Track precision at operational thresholds for your intent classifiers and measure downstream impact—conversion delta per 1,000 classified interactions is a tangible metric that links conversational AI performance to marketing ROI. We recommend tracking both model metrics and business metrics in parallel so you can iterate on thresholds and rules with measurable impact.
Use cases extend from launch management to lifecycle marketing and product-led growth. For product launches, correlate social confusion with in-app abandonment and deploy contextual walkthroughs within minutes. For lifecycle campaigns, detect buying intent from support transcripts and convert it into personalized offers or account-based outreach. For content optimization, surface frequently asked questions from voice transcripts to inform landing page copy and ad creative, shortening creative cycles. These use cases all rely on real-time personalization and multi-channel signal fusion to make marketing both proactive and adaptive.
Operational trade-offs determine whether the marketing gains are sustainable. You must balance latency, compute cost, and governance: low-latency inference improves responsiveness but increases cloud and engineering overhead, and ingesting cross-channel data requires strict consent checks and retention policies. Invest in confidence thresholds, human-in-the-loop workflows for edge cases, and tooling for labeling and dataset drift detection so your conversational AI remains reliable. Choosing whether to serve inference at the edge or centralize models should depend on your latency SLAs and compliance constraints.
Taking these ideas into production changes how marketing teams work: we move from monthly reporting to minute-by-minute adaptation, from static segments to event-driven cohorts, and from manual escalation to automated, auditable actions. As we discussed earlier, the architecture that supports this—streaming ingestion, real-time enrichment, and a decision layer—turns listening into measurable marketing value. In the next section we’ll examine concrete implementation patterns and sample pipelines that let you operationalize these marketing benefits across customer journeys.
Data sources and listening channels
Listening-powered AI and conversational AI depend on the right mix of data sources and listening channels to be effective in marketing operations. Start by thinking of channels as signal producers: chat transcripts, voice calls converted to ASR (automatic speech recognition), social APIs, product telemetry, email, CRM notes, and server-side logs all feed different signal types and latencies. Front-loading these data sources into your streaming ingestion layer gives you the real-time visibility you need to detect intent, sentiment, and emergent topics—so mention of “real-time” and “streaming ingestion” early in the pipeline is intentional and necessary for downstream personalization and orchestration.
The first practical decision is which channels to ingest synchronously versus asynchronously. Chat and in-app messaging usually demand sub-second or single-second latency because actions (like contextual nudges or offer windows) must appear while the user is active, whereas social monitoring or periodic CRM syncs tolerate higher latency but require richer metadata and rate-limit handling. You should design connectors that normalize payloads into a common event schema (user_id, channel, timestamp, raw_text, metadata) so downstream processors can apply consistent NLP and enrichment steps regardless of origin. Building robust adapters for APIs and webhooks reduces bespoke parsing logic and makes scaling to new channels far easier.
Building on this foundation, enrichment and normalization are where quality and utility are made. Convert audio to transcripts with timestamps, attach confidence scores from ASR, run lightweight intent and sentiment models, and emit vector embeddings for similarity lookups; a canonical transformation might look like enrich(transcript) -> {intent, sentiment, embedding, entities, confidence}. Route those enriched events into a vector store and feature store so ranking models and personalization systems can query low-latency signals. Implement backpressure and batching for noisy channels (social streams during product launches) and ensure event-time semantics so late-arriving telemetry doesn’t corrupt session windows or fraud detection rules.
Channel-specific trade-offs determine engineering priorities and governance controls. Voice introduces transcription errors and PII risks that demand redaction and human review workflows; social APIs introduce rate limits and sampling bias that require strategic filtering; product telemetry is high-cardinality and needs careful feature engineering to avoid explosion of sparse signals. How do you prioritize channels when engineering for scale? We prioritize based on business impact (conversion lift or churn risk), latency needs, and data quality—instrument one high-impact channel first, validate model precision at your operational threshold, then expand incrementally with monitored holdouts.
From a marketing orchestration perspective, multi-channel correlation and identity resolution matter as much as individual channel accuracy. You need deterministic and probabilistic identity graphs to dedupe signals and stitch sessions so that an abandoned onboarding flow seen in telemetry maps to a frustrated chat session and a spike in social mentions. That fused view lets you update dynamic segments in real time—moving users into recovery offers or excluding them from irrelevant campaigns—and supports event-level attribution so you can measure uplift from listening-powered interventions. Instrument your decision layer to emit explainable tags (why the user was routed) so analysts can verify and label edge cases for retraining.
Operationalizing these data sources means investing in monitoring, data contracts, and governance before scale reveals problems. Define SLAs for ingestion latency and event completeness, build synthetic traffic tests for channel regressions, and maintain annotation pipelines that feed high-quality labels back into training sets. Enforce consent and retention policies programmatically at the connector level and instrument feedback loops that surface confidence drift, label scarcity, and noisy channels to human-in-the-loop review. Taking these steps lets you expand listening channels confidently while preserving accuracy, privacy, and measurable marketing value as you move from one-channel proofs to a full-fledged listening-powered system.
Designing conversational touchpoints
When your customer interactions feel like interruptions rather than helpful nudges, you’ve lost the signal that should guide conversation design. Conversational AI and listening-powered AI give us the raw capability to respond, but design decides whether those responses land or frustrate. In the first moments of a session you must prioritize context, latency, and relevance so real-time personalization feels earned rather than intrusive. If your messages aren’t aligned with recent behavior or channel expectations, you’ll increase churn even while improving model metrics.
Start by mapping the moments you can meaningfully intervene and tie each to a measurable outcome. Identify high-value triggers—abandonment in onboarding, repeated billing questions, or a spike in negative sentiment on social—and decide whether each trigger warrants an in-channel nudge, an email, or human escalation across your multi-channel stack. For each trigger define the intent classification threshold, allowable latency, and the minimum contextual state required to act (session history, last 3 events, and user opt-in). This mapping turns abstract capability into concrete routing rules and prevents low-confidence automation from creating noisy user experiences.
Design message content and control logic for clarity and recoverability rather than novelty. Lead with the most actionable information: why you’re interrupting, what you can do, and a simple next step (accept, get help, dismiss). Use confidence scores from your intent models to choose phrasing: at high confidence, offer a prescriptive CTA; at medium confidence, ask a clarifying question; at low confidence, surface options for escalation to a human. Implement a circuit-breaker pattern—if a user dismisses or ignores two automated prompts within a window, escalate to human review or lower the automation cadence to avoid fatigue.
Preserve and surface conversational state across channels so context doesn’t vanish between touchpoints. Keep a stateful session store that records recent intents, sentiment trend, and vector embeddings for semantic retrieval, and make that state available to any channel-specific agent. For example, if telemetry shows a user repeatedly dropping off on step three of onboarding and a chat transcript tags “pricing” intent, your next in-app banner should reference the onboarding step and offer a pricing clarification link—not an unrelated upsell. How do you avoid mistaken identity? Use deterministic identifiers when available and probabilistic stitching with confidence scores to avoid false merges.
Governance, privacy, and explainability must be part of message design, not an afterthought. Programmatically enforce consent and redaction at the connector layer so messages never expose PII, and include explainable tags with each automated action (“routed because: intent=pricing, confidence=0.86”). Build human-in-the-loop flows for low-confidence or high-risk actions—escalation queues that include short transcripts and the model rationale speed up review and retraining. Rate-limit proactive outreach to respect attention budgets and to avoid creating feedback noise that will degrade your intent classification and sentiment signals.
Measure everything you design against both model and business KPIs so iteration is evidence-driven. Use randomized holdouts and feature-flagged rollouts to compare conversion lift, time-to-resolution, and retention for automated versus human-assisted flows; instrument event-level attribution so you can trace which classifier outputs drove each business outcome. Monitor precision at operational thresholds and track false-positive user interactions as a safety metric; tune thresholds if automated outreach increases support load or creates negative sentiment. Real-time personalization is only valuable when it moves business metrics predictably and sustainably.
Taking a production view, design these touchpoints as composable building blocks: a detection rule, an enrichment pipeline that supplies context, a channel-specific template, and an escalation policy. When we treat messages as orchestrated artifacts rather than ad-hoc content, we can reuse components across campaigns, standardize explainability, and scale automated interventions without eroding customer trust. In the next section we’ll translate these design patterns into deployment patterns and sample pipelines that connect your streaming ingestion, model serving, and decisioning layers.
Implementation and system integration
Building on this foundation, the hardest part of making listening-powered AI work in production is not the model—it’s integrating streams, models, and business systems so actions are reliable and auditable. You should treat integration as a product: define clear contracts for ingestion, enrichment, decisioning, and downstream actors (CRM, campaign engine, support queue). Early decisions about event schemas, identity stitching, and consent flags determine whether a spike in social noise becomes a coherent recovery flow or an expensive false alarm. This orientation reduces long-term rework and keeps the focus on measurable marketing outcomes.
Start small but design for composition. How do you roll out a listening loop without disrupting existing pipelines? Begin with one high-impact channel, implement streaming ingestion that normalizes events into a canonical schema, and wire a simple rule-based decision layer behind a feature flag. This lets you validate intent/sentiment thresholds and measure lift against control groups before adding latency-sensitive channels. We recommend using message brokers for decoupling, a stream processor for enrichment, and feature-flagged decision endpoints so you can progressively increase automation risk.
Model serving and latency choices shape system topology. You’ll need a hybrid approach: low-latency model serving for in-channel personalization and batched retraining pipelines for ranking or recommendation models. Centralized model serving with autoscaled REST/gRPC endpoints works for most classification tasks, while vector lookups for semantic matching belong in a low-latency vector store (ANN index) co-located with your inference layer. Configure your pipeline so enrichment looks like: stream.map(e -> enrich(e)).filter(e -> e.confidence >= threshold).route(actionTopic)—this keeps enrichment idempotent and traceable, and simplifies retries for transient failures.
Governance and privacy must be enforced programmatically at integration points. Implement per-connector consent checks, PII redaction, and retention rules before any event reaches your feature store or model training bucket. Emit explainability metadata with every routed action—intent, confidence, contributing signals—so human reviewers and auditors can reconstruct why an outreach occurred. Additionally, maintain data contracts and schema versioning for each connector so downstream consumers can rely on stable fields; contract tests and synthetic traffic exercises catch regressions long before they affect production campaigns.
Operationalizing listening-powered systems requires production-grade telemetry and human-in-the-loop workflows. Instrument SLOs for ingestion latency, model recall at operational thresholds, and end-to-end time-to-action. Build labeling microtasks into escalation flows so edge cases automatically populate your retraining corpora, and run randomized holdouts to measure business impact on conversion and churn. Use feature stores to persist user-level signals and tie model outputs to event-level attribution so you can quantify conversion delta per 1,000 classified interactions—this closes the loop between model performance and marketing ROI.
Finally, treat integrations as reusable, composable artifacts rather than one-off glue. Package detection rules, enrichment transforms, channel-specific templates, and escalation policies as versioned services that can be composed in orchestration workflows. We deploy with runbooks that include rollback criteria, synthetic tests for each channel, and periodic audits of consent and label quality. Taking this incremental, governed approach gets you from a proof-of-concept to scalable conversational AI and listening-powered AI deployments that actually drive measurable improvements in customer journeys, while keeping compliance and reliability intact.
Measurement, analytics, and optimization
If you run a listening-powered AI pipeline for marketing, the business value depends on how tightly you close the loop between model outputs and measurable outcomes. Building on this foundation, we need instrumentation that links every routed action back to an event-level outcome so you can quantify lift in conversion, retention, and time-to-resolution. Start by treating each classified interaction as a first-class experiment: log the intent, confidence, contributing signals, channel, and the downstream action id so analysts can reconstruct causal chains. This upfront discipline turns conversational AI signals into auditable inputs for business analytics rather than opaque model artifacts.
A practical measurement framework separates model-level telemetry from business KPIs so you can optimize both in parallel. At the model layer, track precision at your operational threshold, calibration curves, latency percentiles, and class-wise recall for high-value intents; at the business layer, measure conversion delta per 1,000 classified interactions, mean time-to-resolution, and incremental revenue from targeted cohorts. We recommend emitting a compact explainability payload with every action (intent, confidence, top contributing feature) and storing it alongside attribution keys so downstream analytics can answer which signals actually moved the needle. This dual-track approach keeps us honest: we avoid optimizing accuracy in isolation when it doesn’t improve revenue or retention.
Instrumentation and data quality are the engine of reliable analytics. Use a canonical event schema that includes deterministic identity, channel, session window, raw_text, enrichment outputs, and retention/consent flags so you can slice data safely and consistently. Enrich events idempotently—e.g., enrich(event) -> {intent, sentiment, confidence, embedding}—and persist both enriched outputs and raw inputs for retraining and auditing. Implement automated label capture in escalation queues: when human agents correct an intent or tag a transcript, that correction should flow back to a labeled dataset with provenance metadata. Doing so reduces label drift, improves model calibration, and makes your conversational AI progressively more trustworthy.
How do you know a change actually increased conversion rather than created noise? Rigorously use randomized holdouts, feature-flagged rollouts, and statistically powered A/B tests at the event level. Partition traffic by identity or session and compare business outcomes across control and treatment groups while keeping model behavior, exposure windows, and timing consistent. For high-risk interventions, deploy phased rollouts with early stopping rules tied to negative safety metrics (increased support load, drop in NPS, or spikes in negative sentiment) so you can rollback before harm compounds. This experimental discipline turns optimization from opinion-driven tweaks into measurable product work.
The analytics pipeline must support both near-real-time monitoring and richer retrospective analysis. Stream-based aggregates (Flink, ksqlDB) catch emerging issues—intent spikes, sudden confidence drops, or growing false-positive rates—while an OLAP layer supports cohort analysis and lifetime value attribution. Track SLOs for ingestion latency, model inference latency, and end-to-action time so operational alerts surface before customers feel the impact. Combine these telemetry streams with model-monitoring signals—calibration drift, out-of-distribution detection, and embedding-space shift—so our retraining cadence targets real signal degradation rather than cosmetic changes.
Optimization becomes continuous when you close the loop between labeling, retraining, and rollout. We embed microtasks in escalation workflows to capture high-value labels, schedule retraining windows triggered by drift signals, and tune thresholds based on conversion lift rather than raw accuracy. By automating this feedback loop and keeping explainability metadata attached to every action, you move from reactive fixes to proactive improvements that compound over time. Building on what we’ve instrumented here, the next step is translating these measurements into deployment patterns and runbooks that make real-time personalization safe, auditable, and repeatable.



