What is Conversational AI?
When you picture a customer chatting with a brand on your website or an engineer querying logs via a Slack bot, that’s the everyday surface of conversational AI: systems that let people interact with software using natural language instead of menus or API calls. At its core, conversational AI combines speech or text input processing, intent and entity recognition, dialog management, and response generation so that the system can understand, decide, and act. We use the term conversational AI early and often because it captures both the user-facing behavior (chatbots, virtual assistants) and the backend AI stack that makes that behavior coherent.
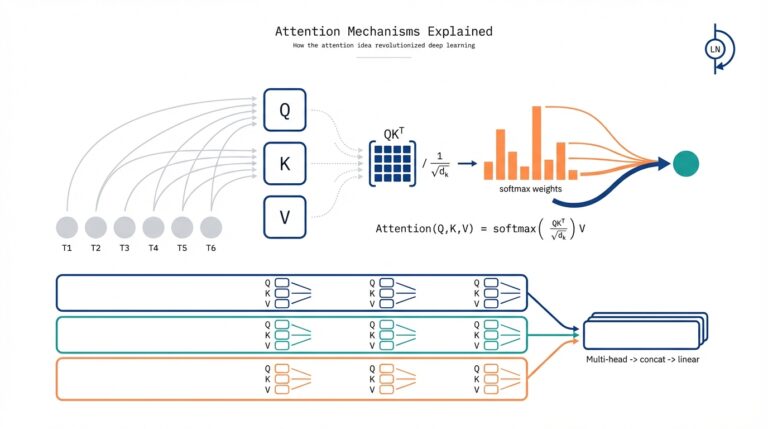
A practical way to break the problem down is by component. Natural language understanding (NLU) is where the system converts utterances into structured signals—intents, entities, and sentiment—and you should think of NLU as the semantic parser. Natural language generation (NLG) composes responses, ranging from templated replies to neural text generation. Dialog management coordinates state, business logic, and fallbacks; it decides whether to call an API, ask a clarifying question, or hand off to a human. For example, an intent JSON might look like {“intent”:”order_status”,”slots”:{“order_id”:”1234”}} and the dialog manager uses that to route to the fulfillment service.
Architecturally, conversational AI projects follow a few common patterns depending on scale and risk. A rule-heavy pipeline (pattern matching + finite-state dialog) works well for predictable, high-compliance flows like payments or authentication. A learning-first pipeline (intent classification + NLG or an LLM) gives flexible, open-ended conversations and benefits from retrieval-augmented generation when pulling facts from a knowledge base. You’ll also see hybrid designs that run an intent classifier first, then an LLM for fallback generation. How do you decide between a rules-first bot and a large-language-model powered assistant? Measure your tolerance for hallucination, latency, and the frequency of unpredictable queries.
The “why” and the “when” drive technology choices. Use conversational AI to reduce ticket volume, speed up common workflows (password resets, order tracking), or enable hands-free interactions in voice channels. For internal developer tools, chat interfaces can increase productivity by exposing queries to logs and metrics in natural language. However, trading off precision for flexibility has costs: regulatory contexts and financial flows often require deterministic behavior and auditable decision paths, whereas marketing or FAQ assistants can accept probabilistic responses. We choose patterns based on required accuracy, regulatory constraints, expected conversational breadth, and integration complexity.
Implementation details matter more than the marketing. Start with representative training data and realistic user utterances; synthetic utterances can supplement but not replace real examples. Plan for state persistence (session stores or vector embeddings for long-context recall), and use a vector database plus RAG to surface authoritative knowledge for responses. Instrument metrics—intent accuracy, containment rate (percentage of sessions resolved without human handoff), latency, and downstream conversion—to guide iteration. Finally, design safety nets: confidence thresholds that trigger clarifying prompts, explicit fallbacks to human agents, and redaction/PII policies for logs and model inputs.
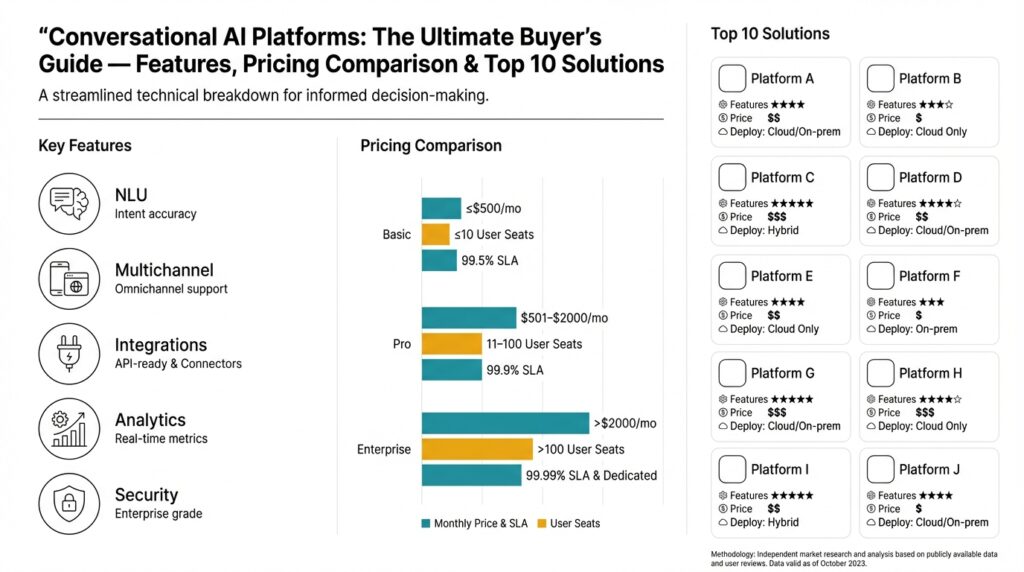
As you evaluate platforms, keep these architectural realities in mind because they map directly to feature and pricing decisions: hosted model inference vs bring-your-own-model, per-message pricing versus seat-based subscriptions, built-in connectors to CRMs and knowledge bases, and SLAs for uptime and latency. In the next section we’ll compare those platform capabilities side-by-side so you can match the technical requirements—latency, manageability, and security—to your business goals and implementation constraints.
Business Use Cases and ROI
Most executives ask the same blunt question first: what will conversational AI deliver in measurable business value and ROI? Building on the foundation we established earlier about NLU, dialog management, and containment rate, we should front-load key metrics when you propose a bot or virtual assistant: ticket volume reduction, average handle time (AHT), containment rate, and conversion lift. Framing the project around these outcomes forces technical trade-offs to align with commercial goals, so when you describe architecture choices to stakeholders, you tie model type, latency, and integration complexity to dollars saved or revenue generated.
Start by mapping concrete business use cases to expected operational outcomes rather than technology features. For customer support, a chatbot that handles tier-1 questions can reduce ticket volume and cut AHT by routing only escalations to humans; for sales, a conversational assistant that qualifies leads in the product can increase demo bookings and lift conversion rates. Internally, developer-facing assistants reduce time-to-diagnose by exposing logs and runbooks via natural language queries; HR chatbots speed up onboarding and benefits administration. Each use case has a different risk profile, so prioritize deterministic, rules-first flows for payments and authentication and reserve LLM-driven interactions for exploratory tasks where flexibility yields measurable uplift.
Estimating ROI requires baselining current costs and modelling incremental improvements. A conservative analytical approach is to calculate total cost of ownership for support (agent FTE cost × hours × shrinkage) and then model containment improvements: moving containment from 60% to 80% reduces human-handled sessions by one-third, which can translate to either headcount reduction or capacity redeployment. For revenue-focused bots, quantify conversion lift per assisted interaction and multiply by average order value and expected traffic. Use scenario modeling: best case / expected / conservative; this both manages stakeholder expectations and highlights sensitivity to traffic volume, accuracy, and latency.
Implementation choices materially affect realized ROI, so we must connect engineering decisions to economics. Integrating a knowledge base with retrieval-augmented generation typically increases correct-answer rates but raises compute cost; a hybrid intent-classifier-plus-LLM fallback reduces hallucination risk but complicates pipelines. Pricing models—per-message inference costs versus seat- or instance-based fees—change the marginal cost curve and therefore the break-even point for automation. Plan for instrumentation and versioned deployments so that you can A/B test knowledge sources, confidence thresholds, and escalation policies while isolating cost drivers.
How do you prove value to finance stakeholders and justify ongoing spend? Run controlled pilots with clear hypotheses and KPIs: containment rate uplift, reduction in mean time to resolution (MTTR), conversion delta, and changes in CSAT or NPS. Instrument every path end-to-end: attribute downstream revenue or retention to assisted sessions, track fallbacks and false positives, and tie bot confidence to deflection versus handoff rates. Present normalized metrics (cost per resolved session, revenue per assisted session) and a 12–24 month cash-flow model that includes implementation, training, and ops costs so the CFO can see payback timing and sensitivity to usage growth.
Real-world ROI rarely appears overnight; it compounds as you improve training data, expand domain coverage, and reduce fallbacks through analytics-driven iteration. We recommend treating conversational AI as a product: prioritize high-frequency, low-risk flows first, instrument thoroughly, and redeploy savings into more complex automation areas. That approach aligns technical work—model selection, knowledge engineering, latency tuning—with measurable business outcomes and prepares you to choose the platform and pricing model that maximizes ROI as usage scales.
Core Features to Compare
Building on this foundation, the first thing to insist on when evaluating platforms is robust NLU and clear dialog management primitives. NLU accuracy determines whether user intents and entities are extracted reliably, and dialog management determines how state, context, and business logic are orchestrated across turns. Evaluate intent classification and slot-filling separately from response generation because you may combine a deterministic intent pipeline with an LLM for fallback. Early in the lifecycle you want reproducible intent metrics and a dialog model that exposes versioning, hooks for middleware, and deterministic transitions.
Next, measure integration breadth and model hosting options because they shape operational cost and implementation velocity. Does the platform provide native connectors to your CRM, knowledge base, and event bus, or will you have to implement adapters? How do you prioritize among NLU accuracy, latency, and safety when those goals conflict? Prefer platforms that support both hosted model inference and bring-your-own-model (BYOM) so you can start with vendor-managed models and later migrate to fine-tuned or private LLMs without rewriting pipelines.
Consider knowledge management and retrieval-augmented generation (RAG) as a feature set, not a checkbox. A production assistant rarely succeeds on model capability alone; it needs a search layer, vector database, and controllable retrieval policies that surface authoritative documents from a knowledge base. For a customer-support scenario—order lookups, refunds, and payment confirmations—RAG improves answer accuracy but also raises audit and latency concerns, so evaluate whether the platform lets you pin sources, tune retrieval recall/precision, and instrument provenance metadata for every generated claim.
Examine safety, observability, and operational controls because they directly affect compliance and maintainability. Look for configurable confidence thresholds that route low-confidence sessions to clarification prompts or human agents, immutable audit logs with redaction, role-based access control, and encryption at rest and in transit. Also verify what telemetry is available: intent accuracy over time, containment rate, average response latency, throughput, and fallback frequency. These metrics let you tune confidence thresholds and dialog policies to reduce hallucinations while maximizing containment.
Pay attention to lifecycle features: model/version management, testing sandboxes, and CI/CD for conversational flows. A mature platform will let you run unit tests against intents, smoke tests for integrations, and staged rollouts for dialog changes; it will also let you A/B test knowledge sources or confidence thresholds. From a cost-control perspective, compare per-message inference pricing against seat or instance fees and factor in vector-search costs—those line items will determine when scaling becomes expensive and whether a hybrid intent-classifier-plus-LLM fallback makes economic sense.
Finally, weight features against your use case and risk profile so you can rank platforms objectively. For high-compliance flows prioritize deterministic dialog engines, auditability, and on-prem or private-model hosting; for exploratory, customer-engagement use cases prioritize flexible NLG, RAG, and rapid iteration. As we discussed earlier, map features to business metrics—containment rate, AHT, and conversion lift—and use those KPIs to score vendors during trials. In the next section we’ll translate these prioritized capabilities into a side-by-side comparison so you can match technical requirements and pricing to the outcomes you care about.
Deployment and Integration Options
When you decide how the assistant will live in your ecosystem, deployment and integration choices determine speed, cost, and compliance more than model selection. Building on the architecture we covered earlier, start by asking a concrete question: how do you choose between hosted model inference, bring-your-own-model (BYOM), or an on‑prem/hybrid deployment for your workload? Your answer should map to latency targets, data residency rules, and whether you need direct control over model weights or prefer vendor-managed updates. We’ll walk through trade-offs and concrete patterns so you can pick an approach that matches the use case—support, sales, or internal developer tooling—without guessing about operational constraints.
A common deployment topology is vendor-hosted model inference: the platform runs the model, manages scaling, and exposes inference via API. This option minimizes ops work and accelerates time-to-value, but it increases network round-trips and may raise data residency or audit concerns for regulated flows. BYOM gives you the middle ground: you bring fine-tuned or private models to the vendor’s runtime or a managed execution environment so you control the model artifacts while still benefiting from platform connectors and orchestration. On‑prem or fully air‑gapped deployment is the choice when auditability, PII safeguards, and deterministic behavior are mandatory; it shifts operational burden to your team but eliminates many compliance headaches. We recommend explicitly documenting which user paths require on‑prem handling (payments, identity verification) and which can use hosted model inference to balance risk and velocity.
Integration patterns matter as much as where the model runs. Use first-class connectors when available—CRM, ticketing systems, knowledge bases, and telephony providers reduce engineering work and simplify provenance for RAG (retrieval-augmented generation). When a native connector doesn’t exist, build thin adapters that translate platform webhooks into your domain events and call your fulfillment APIs; treat adapters as versioned, testable services rather than ad‑hoc scripts. For example, route an intent payload to a microservice that validates order_id, queries your SQL store, and then inserts a vector lookup against your vector database for RAG. This keeps the conversational layer stateless and auditable while the heavy lifting occurs in controlled services.
Operationalizing integrations requires attention to latency, throughput, and failure modes. We suggest colocating latency‑sensitive services (auth, order lookups) in the same cloud region as your hosted model inference or running them on the same private network for on‑prem deployments to meet strict SLOs. Implement caching for high-frequency read patterns—session state, static FAQs, and lookup tables—to reduce vector-search and model calls. Use circuit breakers and graceful degradation so the assistant falls back to templated responses or a human‑handoff when a downstream system is slow or unreachable. A small Express webhook that verifies a signature and enqueues a fulfillment job demonstrates this pattern in practice: you accept the request, validate, push to a queue, and respond quickly to avoid blocking the chat turn.
Security, observability, and lifecycle controls should be baked into your integration strategy from day one. Enforce encryption in transit and at rest, role‑based access control for connector credentials, and automatic redaction for PII before any external model call when using hosted model inference or third‑party vector stores. Instrument intent accuracy, containment rate, average response latency, and fallback frequency end‑to‑end; feed these metrics into CI/CD gates so dialog changes don’t regress containment. Finally, install a deployment pipeline that supports canary rollouts, test sandboxes for end‑to‑end RAG scenarios, and feature flags for toggling BYOM versus vendor models in production without full redeploys.
Choosing the right mix of deployment and integration options is a mapping exercise: align each conversational path to required latency, auditability, and cost profile rather than applying a single pattern everywhere. When we score vendors or design our architecture, we prioritize deterministic on‑prem flows for high‑risk transactions, BYOM for controlled model ownership and iterative tuning, and hosted model inference for experimental, low‑risk experiences. In the next section we’ll compare platform capabilities side‑by‑side so you can translate these deployment and integration trade‑offs into vendor selection criteria and concrete procurement requirements.
Pricing Models and Cost Drivers
Building on this foundation, the economics of conversational AI platforms determine whether your pilot becomes a sustained product or a line-item that drains budget. You should treat pricing models as an engineering constraint: they change marginal decisions from “can we call the model” to “should we call the model.” Conversational AI platforms often package functionality into a mix of fixed subscription fees and variable usage charges, so understanding those distinctions up front prevents surprises when traffic or model complexity grows.
Start by mapping the common pricing models to the technical levers you control. How do you decide between per-message pricing, seat-based subscriptions, or instance/hour bills for hosted inference? Per-message pricing typically charges for each API call or chat turn and tightly couples cost to traffic and turn length, while seat-based subscriptions price per named user or admin and are useful when human operators dominate costs. Instance-based or node pricing can make sense when you need reserved capacity or predictable latency; it trades variable inference cost for operational overhead and provisioning responsibility.
Next, identify the primary cost drivers that will drive your monthly bill. Inference cost is usually the single largest driver when you use large models: model size, token count, and frequency of calls increase compute and therefore cost. Retrieval costs from vector search and the underlying storage also add up—high-recall RAG patterns generate many vector queries per turn, and those queries have both compute and egress impact. Integration costs (connectors, webhooks), audit/log storage, and human‑handoff seats are steady secondary drivers that scale with feature breadth rather than raw traffic.
Make trade-offs concrete with a simple breakpoint calculation so you can pick a pricing model objectively. Calculate cost per resolved session = (inference cost per turn × average turns) + (vector search cost per query × avg queries) + fixed ops amortization. Compare that to your effective cost of a handled session (agent hourly cost × average handling time / sessions per hour). If per-message pricing yields a lower cost per resolved session at your expected traffic, it beats seat-based subscriptions; otherwise a seat or instance model may be cheaper at high containment rates. This math forces you to measure containment rate, average turns, and token usage early in pilots.
Deployment choices materially change both baseline and marginal costs, so align architecture with procurement. Using BYOM or private-hosted models shifts inference cost from vendor usage fees to your cloud compute and storage bills; it gives you control over model sizing and quantization optimizations but requires capacity planning. Vendor-hosted inference makes start-up cheaper operationally but increases per‑call fees and can add data egress. On‑prem or air‑gapped deployments minimize external billable events but increase fixed ops and maintenance headcount—choose the mix based on latency targets, compliance constraints, and predictable traffic patterns.
Finally, adopt operational controls to contain spend without sacrificing user experience. Implement caching of static responses and common vector-search results, batch low-priority queries, and use an intent classifier or rule engine as a cheap first pass so the LLM is a fallback. Enforce confidence thresholds and graceful degradation—route low-confidence requests to templated replies or human agents—to avoid unnecessary inference cost. Instrument cost-sensitive metrics (cost per resolved session, tokens per turn, vector queries per session) and gate releases with CI metrics so pricing models and cost drivers inform product decisions rather than surprise them.
Taking this approach lets us focus procurement conversations on measurable breakpoints and operational levers, not vendor marketing. When you evaluate proposals, insist vendors expose cost telemetry and unit pricing for inference, vector search, storage, and human seats so you can model scale. With those inputs you can score platforms objectively and design a hybrid architecture—BYOM where control matters, vendor inference where velocity matters—that minimizes total cost of ownership as usage grows.
Security, Compliance, Privacy Considerations
Building on this foundation, security, privacy, and compliance must be design-first constraints for any conversational AI deployment rather than afterthoughts you bolt on. When you evaluate vendor features or choose between hosted inference, BYOM, or on‑prem hosting, prioritize data residency, encryption, and auditability in the first discovery sprint. Conversational AI exposes new data paths—user utterances, vector embeddings, knowledge retrieval, and model outputs—so we have to treat every chat turn as a potential privacy and security event and instrument accordingly.
Start by categorizing the risks you actually care about: sensitive data exfiltration, model hallucination that makes false claims, unauthorized access to conversation history, and third‑party data sharing. For example, a payments flow requires deterministic handling and often on‑prem processing, whereas a marketing FAQ can tolerate vendor-hosted LLM calls; those are different risk buckets. This risk taxonomy drives concrete controls: which paths need field‑level redaction, which need private model weights, and which are acceptable to run through a vendor-managed RAG (retrieval-augmented generation) layer.
Implement technical controls where they make a measurable difference. Encrypt all traffic with TLS and consider mutual TLS (mTLS) for backend services that handle fulfillment or order lookups; use a cloud KMS for envelope encryption at rest, and rotate keys programmatically. Enforce least-privilege via RBAC and SSO integrations (OIDC/SAML) so connector credentials and access tokens are scoped and audited. Pre-call middleware should scrub or pseudonymize PII—remove card numbers, SSNs, and other direct identifiers—before sending text to any external model or vector store, and log only hashed identifiers for traceability.
When you introduce RAG and vector search into the pipeline, control becomes more than encryption: it’s provenance and retrieval policy. RAG (retrieval-augmented generation) pulls documents to ground LLM outputs, so tag every retrieved document with source metadata, confidence scores, and a signed source identifier to enable downstream audit and dispute handling. How do you balance data privacy with model accuracy? We recommend pinning high‑risk sources to on‑prem indices or restricting fallback retrievals to sanitized summaries; this preserves answer quality while preventing sensitive record leakage. Also enforce role-based access and encryption on the vector DB and limit retention windows for embeddings derived from PII.
Compliance demands operationalized evidence, not promises. Map your conversational paths to applicable frameworks—GDPR for EU users, HIPAA for health data, SOC 2 for vendor security posture—and bake data subject rights into interfaces (export, erase, consent). Maintain immutable audit logs that record intent, fulfillment calls, model version, and redaction events so you can reconstruct decisions. Version your models and dialog flows, and include model hash or artifact IDs in logs so auditors can tie a response to the exact model and knowledge snapshot used at that time.
Operational practice reduces risk more than checkbox controls. Build test harnesses that run adversarial prompts and hallucination red-team scenarios against your LLMs, include privacy-preserving training options like differential privacy or federated learning when you fine-tune on customer data, and gate deployments with canary releases and CI metrics for containment rate and fallback frequency. Implement clear human‑in‑the‑loop policies and confidence thresholds so low‑certainty responses route to agents. Finally, plan incident response playbooks that cover model misbehavior, data breach notifications, and regulator reporting timelines.
Security, privacy, and compliance are not one-off features; they shape architecture, vendor selection, and product KPIs from day one. As you move from pilot to scale, we recommend codifying data flows, automating redaction and key rotation, and insisting on vendor telemetry that surfaces inference lineage, cost, and provenance. Doing that lets you balance agility with control so conversational AI delivers value without creating unacceptable legal or operational risk, and it sets a clear handoff to the next phase of platform evaluation.