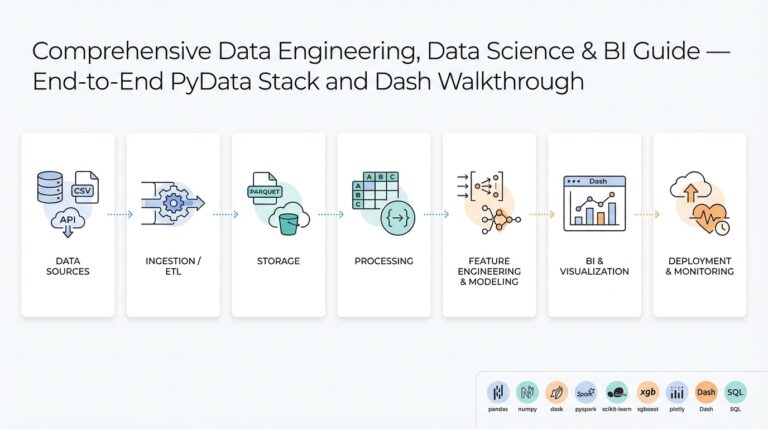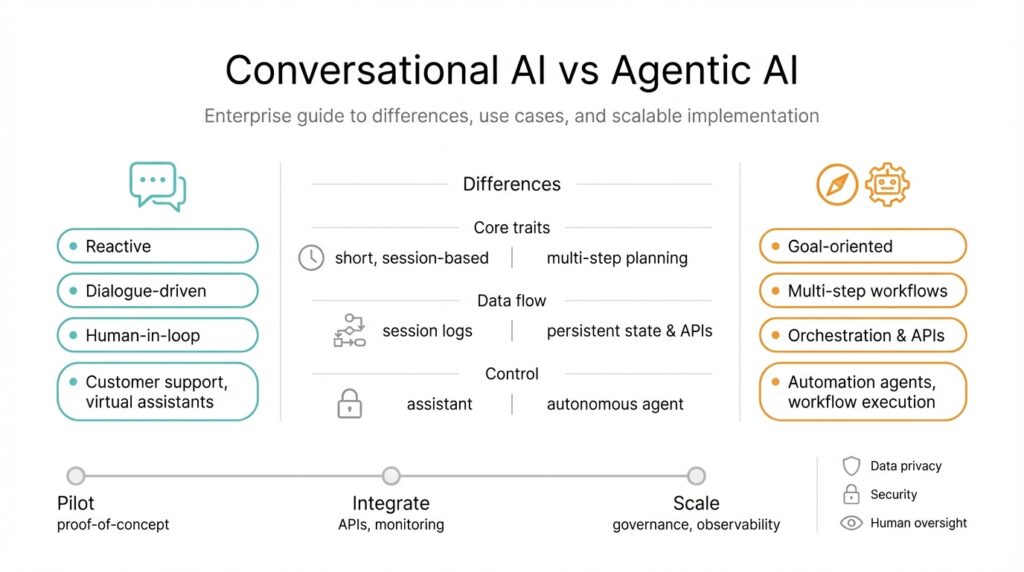
Definitions: Conversational vs Agentic AI
Building on this foundation, we need to be precise about two often-confused categories: Conversational AI and Agentic AI. Conversational AI refers to systems optimized for dialogue—understanding intent, maintaining context, and producing responses that keep a human engaged. Agentic AI refers to systems that take autonomous, goal-directed actions on your behalf—planning, calling APIs, and executing multi-step workflows. Defining these clearly up front prevents architectural drift when you move from prototypes to production.
Conversational AI focuses on language understanding and user experience. In practice this means intent classification, slot filling, dialogue state tracking, and safe response generation; you often augment it with retrieval-augmented generation (RAG) to surface facts from a knowledge base. For example, a support bot that answers billing questions will keep context across turns, fetch policy text from a vector search index, and fall back to escalation when confidence is low. Architecturally, you’ll see a stateless or lightly stateful LLM layer, a retrieval layer, a session store, and human-in-the-loop endpoints for handoff.
Agentic AI adds autonomy and planning on top of language capabilities. An agent constructs a plan, breaks tasks into steps, calls external tools (APIs, databases, CI systems), and reasons about outcomes until it achieves a goal or hits a safety boundary. For instance, an incident-resolution agent might triage alerts, run diagnostic queries, open tickets, and trigger a rollback if a health check fails. Technically this requires a planner, a tool interface layer, retry and idempotency patterns, and strong observability so every action is auditable and reversible.
The operational differences matter: conversational systems optimize for conversational quality, low latency, and safe fallbacks; agentic systems optimize for correct action sequencing, transactional integrity, and error recovery. Conversational AI treats the LLM primarily as a communicator; agentic AI treats the LLM as a planner and decision engine. Consequently, agentic designs demand stronger safeguards—rate limiting, circuit breakers, sandboxed tool execution, permissioned credentials, and rigorous logs—because an agent’s API calls can change state across systems.
How do you decide which to use? Choose conversational AI when the core value is interaction fidelity—customer support, sales assistants, or knowledge discovery where human judgment remains primary. Choose agentic AI when tasks are well-defined, repeatable, and can be safely automated—batch data curation, automated provisioning, or routine incident remediation. In many enterprise scenarios you’ll combine both: a conversational front end that interprets intent and an agentic backend that executes verified, auditable actions after explicit user approval (for example: “Yes, deploy to staging”). Design criteria to weigh include error cost, regulatory constraints, latency requirements, and the need for human oversight.
Taking this concept further, the implementation choices you make next will determine whether your system scales reliably. We’ll examine concrete patterns for safely composing conversational layers with agentic workflows, instrumenting audit trails, and designing human-in-the-loop gates so automation increases velocity without increasing risk.
Core Architectural and Behavioral Differences
Building on this foundation, the architectural split between conversational AI and agentic AI shapes everything from service boundaries to incident response. Conversational AI focuses on fast, context-rich exchanges: lightweight session stores, retrieval-augmented generation (RAG) pipelines, and a primarily stateless LLM layer tuned for turn-taking and safe generation. Agentic AI, by contrast, centers on goal-oriented planning, tool integration, and stateful execution where the model’s outputs drive side effects across systems. Front-loading those differences early prevents architectural drift as you move from prototypes to production.
At the component level the contrast is concrete and prescriptive. Conversational systems typically compose an intent/slot extractor, a session or dialogue state store, a retriever (search or vector index), and a response-generation layer; latency and coherent context management are the dominant concerns. Agentic systems invert that emphasis: they require a planner or orchestrator, a tool interface layer that implements idempotency and permission checks, a transaction manager for multi-step flows, and durable logs for auditability. These distinct component needs change your deployment topology, monitoring stack, and even how you version prompts and policies.
Behavioral differences follow from those architectural choices and shape runtime expectations. Conversational AI aims for coherent, safe, and fast replies; failures map to awkward or incorrect text that can be remediated with clarification or escalation. Agentic AI aims to produce correct sequences of actions; failures can cause persistent state changes, so you must design for retries, rollbacks, and compensating transactions. Consequently, agentic systems demand stricter observability, determinism controls, and safety guards because an action is often irreversible or costly.
Operational patterns diverge accordingly: implement a session store and RAG cache warming strategy for conversational workloads, but implement circuit breakers, rate limiting, and sandboxed tool execution for agentic workloads. For example, a customer-support conversational bot will fetch policy text from a vector index and keep a short conversation history to avoid hallucination, while an incident-resolution agent will run diagnostics, open tickets, and, if required, trigger a rollback using idempotent APIs. In the latter case we instrument every action with an auditable event, attach request-scoped credentials, and build reversible workflows to contain blast radius.
How do you combine both without multiplying risk? Use a conversational front end as the canonical intent and consent layer, and gate agentic actions behind explicit user approval, feature flags, and stepwise authorization. In practice that pattern looks like: parse intent in the chat path, generate a proposed plan with the agentic engine, present the plan back to the user for confirmation, then execute the plan in a controlled environment with strong logging and retry semantics. When should you choose conversational-first versus agentic-first? Choose conversational-first when human judgment and interaction fidelity are the product; choose agentic-first when tasks are well-defined, repeatable, and the cost of automation-induced error is acceptably low.
These architectural and behavioral distinctions have direct consequences for scalability, security, and compliance. Conversational AI optimizes for throughput and context fidelity; agentic AI optimizes for transactional integrity and observability. As we design enterprise systems, we should explicitly document which components own state, what actions are reversible, and where human-in-the-loop gates sit so we can scale velocity without increasing risk. Taking those decisions now makes the rest of implementation—auditing, orchestration, and governance—far more tractable.
Enterprise Use Cases and Applications
Building on this foundation, enterprises need concrete examples that show where Conversational AI and Agentic AI deliver distinct business value and where they must be combined for safe automation. In many production deployments you’ll see Conversational AI used as the intent and consent layer while Agentic AI performs the actual work—this pattern preserves human-in-the-loop control, enables retrieval-augmented generation (RAG) for fact grounding, and enforces auditability for regulated workflows. If you’re deciding between the two, prioritize the cost of an incorrect action: use conversation when accuracy matters for engagement and agentic automation when repeatable tasks create measurable ROI.
Customer support is the low-friction starting point for most enterprise projects because user intent is easy to observe and the conversational surface improves UX instantly. Implement a conversational front end that uses RAG to surface policy and SLA text, then generate a proposed action plan—refund, ticket escalation, or account hold—and present that plan back to the user for approval. When approved, hand the plan to an agentic backend that executes idempotent API calls, records each step to an immutable audit log, and attaches request-scoped credentials so every change is attributable. This split reduces hallucination risk, speeds resolution, and keeps human reviewers in the loop for the highest-risk cases.
For IT operations and DevOps, Agentic AI is where you capture real operational leverage by automating triage and remediation workflows. Build an incident-resolution agent that first runs read-only diagnostics (metrics queries, logs search), synthesizes a prioritized action plan, and then requests a permission token before executing mutating commands like scaling, configuration changes, or rollbacks. Design tool interfaces with idempotency guarantees and compensating transactions so retries don’t amplify harm, and ensure detailed event streams for post-mortem analysis and compliance. These patterns let you reduce mean time to resolution (MTTR) while keeping blast radius controlled.
Finance, billing, and compliance workflows expose another strong enterprise use case for agentic flows combined with conversational approvals. Use Conversational AI to shepherd users through exception handling—explaining why a reconciliation failed, requesting missing artifacts, and collecting explicit approval for adjustments—then invoke Agentic AI to post journal entries, issue refunds, or update ledgers under strict authorization policies. Preserve full provenance and retain change records for audits, and implement role-based constraints so automated actions never exceed pre-approved boundaries. This approach balances automation velocity with regulatory constraints and auditability.
Data engineering and knowledge-management teams benefit when you separate discovery from execution: let Conversational AI help analysts locate datasets, summarize recent schema changes, or surface relevant notebooks, and let Agentic AI run safe ETL jobs, cherry-pick commits, or materialize views after human sign-off. For example, an analyst can ask a chat interface for “the latest cleansed sales feed,” review a proposed pipeline run, and then trigger a scheduled agentic job that writes into downstream tables using transactional APIs. That separation reduces exploratory friction while preventing accidental data corruption.
How do you keep risk low while automating high-value actions? Apply layered governance: sandbox tool execution, require stepwise authorization for privileged actions, implement circuit breakers and rate limits, and instrument every action with observability hooks so you can trace intent → plan → execution. Track both functional KPIs (time saved, error reduction) and safety KPIs (unexpected side effects, rollback frequency) and iterate on thresholds and escalation flows. These controls let you push automation into production without sacrificing control.
When you roll agentic capabilities into an enterprise landscape, start conversational-first and instrument decision points aggressively. Prototype with read-only agents, expose proposed plans to users, and add execution only after you’ve collected real-world telemetry and refined idempotency and rollback strategies. Then gate the rollout with feature flags, permission scopes, and human-in-the-loop approvals so you scale automation predictably; next we’ll examine concrete composition patterns and observability practices that make that scale both safe and auditable.
Design Patterns for Scalable Implementation
Building on this foundation, the practical challenge is turning architectural intent into repeatable design patterns that support both conversational AI and agentic AI at scale. Enterprises need patterns that preserve human consent, maintain transactional integrity, and keep observability tractable as throughput grows. If we treat conversational AI as the intent-and-consent layer and agentic AI as the planner-and-executor, the patterns below help you scale without multiplying risk. These design patterns for scalable implementation center on clear interfaces, idempotent tooling, and auditable decision points.
Separate responsibilities with a strict orchestrator-adapter pattern so each component has a single accountability. The orchestrator (planner) composes high-level goals into ordered steps and emits plans; adapters implement tool-specific actions with idempotency and permission checks. This separation keeps conversational AI focused on dialogue, context, and confirmation while the agentic engine focuses on sequencing, retries, and side-effect management. When you separate these concerns, you can independently scale the RAG/retriever layer for conversational throughput and the execution worker pool for agentic tasks.
Make the conversation-to-action handoff explicit: always present a machine-readable plan and require confirmation before execution. In practice, parse intent in the chat path, surface a proposed plan (actions, preconditions, estimated risk), then record a user-approved token before the agentic engine runs any mutating API. For example, generate a JSON plan like {"steps":[{"id":"scale","target":"service-a","replicas":3}]} and require a signed approval token approval_id attached to subsequent calls. This pattern reduces hallucination risk and gives you a clear audit boundary between conversational AI outputs and agentic AI side effects.
Design tool interfaces for idempotency, permission scoping, and safe retries so agentic actions are reversible or compensatable. Implement idempotency keys on every mutating call (for example: POST /deploy?idem_key=<uuid>) and return a canonical status object that the orchestrator can rehydrate on retry. Use short-lived, request-scoped credentials and role-based permission checks in the adapter layer so the agent cannot exceed its authorized blast radius. How do you ensure idempotent tool calls across retries? Use deterministic operation identifiers, versioned APIs that support upserts, and compensating transactions where direct rollback isn’t possible.
Instrument an auditable event model and correlation IDs to make intent → plan → execution traceable across systems. Emit structured events for each phase: intent_detected, plan_generated, user_approved, action_executed, and action_compensated. Store these events in an immutable audit log and surface them through your observability stack for live tracing and post-incident analysis. Capture both functional KPIs (success rate, MTTR reduction) and safety KPIs (rollback frequency, unexpected side effects) so you can iterate policies and thresholds with data.
Gate dangerous operations with layered human-in-the-loop checks, feature flags, and sandboxed rollouts. For high-risk operations require stepwise authorization: conversational confirmation, manager approval, and execution in a staging sandbox prior to production rollout behind a feature flag. Use canary runs and circuit breakers to limit scope, and apply throttling and rate limits to control velocity. These governance patterns let you push automation into production while retaining control over sensitive state changes.
Scale execution with proven infrastructure patterns: worker queues, autoscaling pools, backoff strategies, and bounded concurrency for external tools. Decompose long-running plans into resumable tasks, persist execution state in a durable store, and use exponential backoff with jitter for transient failures. Treat tool integration points as backpressure boundaries — implement queue length and latency-based autoscaling so agentic workloads don’t overwhelm downstream services. Container orchestration, queueing systems, and orchestration workers let you scale agentic AI independently of conversational throughput.
Taken together, these patterns let you combine conversational AI and agentic AI without sacrificing governance or scalability. We prioritize explicit handoffs, idempotent adapters, structured auditing, and layered approvals so automation increases velocity while containing risk. Next we’ll examine concrete composition patterns and observability practices that make these design choices verifiable in production and ready for incremental rollout.
Operationalizing AI: Deployment Monitoring Governance
Building on this foundation, the real work of production begins when you move from prototypes to disciplined deployment, monitoring, and governance that span both conversational AI and agentic AI. The first sentence here is the hook: without an operational plan you trade velocity for chaos. We need observability that ties intent to action, deployment controls that limit blast radius, and governance that enforces who can escalate or execute state-changing steps. Treat these as a single control plane rather than three disconnected efforts so you can reason about risk end-to-end.
Different runtime behaviors demand different monitoring signals. For conversational AI you’ll prioritize per-turn latency, context-window truncation events, RAG retrieval hit/miss rates, and a hallucination or confidence metric derived from grounding checks. For agentic AI you’ll emphasize plan success rates, action idempotency violations, external tool error rates, and transactional latency across multi-step flows. Instrument both stacks with unified correlation IDs so a single trace can show the user utterance, the generated plan, the approval token, and each adapter call that followed.
Make auditable events the canonical source of truth for intent → plan → execution. Emit structured JSON events such as {“phase”:”intent_detected”,”intent”:”reset_password”,”corr_id”:”abc-123”,”ts”:”2026-02-23T12:34:56Z”} and persist them to an append-only store. This lets you replay flows for post-incident analysis, rehydrate execution state for resumable tasks, and produce tamper-evident audit trails for compliance. When you attach approval tokens and idempotency keys to those events, the logs become both evidence and control points for governance.
Design your observability stack around metrics, traces, and structured logs that map to operational questions. Create Prometheus-style metrics like conversation_turn_latency_seconds, retrieval_miss_ratio, agentic_actions_executed_total, and agentic_action_failure_rate so you can SLO on both UX and safety. Use distributed tracing to follow a conversation from frontend request through planner orchestration into adapters, and surface span attributes such as approval_id and idem_key so engineers can quickly locate the root cause. Correlate metric alerts with recent model or prompt rollouts to reduce false positives.
How do you detect behavioral drift or emergent risk? Implement continuous model and data monitoring: track input feature distributions, embedding drift for retrieval quality, changes in top-k retriever sources, and degradation in downstream task accuracy. Tie those signals to automated alerts and to an error budget that gates automated execution. When drift breaches thresholds, automatically demote agentic execution to read-only mode and escalate to human review so you preserve safety while you diagnose.
Governance must be layered and enforceable. Enforce RBAC on execution endpoints, require signed approval tokens for mutating actions, and use feature flags and canary windows to limit production scope. Retain immutable audit logs with retention policies appropriate to your regulatory environment and surface role-based views for auditors. Make permission scopes narrow by default and instrument policy violations as high-severity signals in your observability pipeline.
Prepare operational playbooks that make incident response repeatable. Capture how to replay an execution from the audit log in a sandbox, how to revoke stale credentials, how to roll back adapters with compensating transactions, and how to gather the exact prompt/plan pair that triggered a problematic action. Treat agentic failures as safety incidents: run post-mortems that map to intent → plan → adapter behaviors, and feed results back into prompt/version gating and test suites.
When you combine these practices you get a stable path to scale: tie deployment to observability and governance so every rollout has measurable safety checkpoints, every anomalous signal can be traced to a concrete action, and every high-risk operation is gated behind approvals. In the next section we’ll translate these controls into concrete composition patterns and monitoring dashboards you can implement in your CI/CD and orchestration pipelines.
Metrics, ROI, and Performance Indicators
Building on this foundation, the single most important question for product and engineering teams is simple: how will you measure value and quantify ROI when you combine conversational AI with agentic AI? Start with that question because it forces you to separate user-facing quality from automation correctness and to choose performance indicators that map directly to business outcomes. How do you attribute time saved, error reduction, and increased throughput across a conversation-driven intent layer and a planner-driven executor? If you don’t answer that clearly up front, governance and observability will be fragmented and your automation will be hard to justify to finance and compliance stakeholders.
Begin by grouping metrics into three complementary families: user-experience metrics, automation correctness metrics, and safety/performance indicators. For conversational AI, prioritize per-turn latency, conversation completion rate, retrieval hit ratio, and an empirically measured hallucination or grounding-failure rate (the fraction of answers that require correction or escalation). For agentic AI, prioritize plan success rate, action failure rate, idempotency violations, rollback frequency, and end-to-end transactional latency across multi-step flows. Treat these as first-class KPIs so product managers and SREs can reason about trade-offs between responsiveness, autonomy, and risk.
Instrumenting these metrics requires making intent → plan → execution auditable and queryable. Emit structured events for intent_detected, plan_generated, user_approved, action_executed, and action_compensated, and attach a single correlation_id to every span so traces join cleanly in your observability pipeline. Expose Prometheus-style counters and histograms (conversation_turn_latency_seconds, retrieval_miss_ratio, agentic_actions_executed_total, agentic_action_failure_rate) and use distributed tracing to capture approval_id and idem_key as span attributes. Also implement continuous data-monitoring: embedding drift for retrievers, feature-distribution drift for intent classifiers, and rising retrieval miss rates are early signals that conversational quality or automation safety is degrading.
Quantifying ROI means translating those metrics into dollars and risk-adjusted benefits. Start with a baseline measurement period: measure current mean time to resolution (MTTR) or mean time to acknowledge (MTTA), per-case handling cost, and frequency of human escalations. Run read-only agentic trials and A/B tests that compare automated plan proposals with human-only workflows to estimate time saved and reduction in manual steps. Convert time saved into cost savings (hours saved × fully loaded hourly cost), add avoided error costs (reduced refunds, rollback-related downtime), and subtract automation costs (model inference, tool execution, engineering). A practical ROI sanity check is simple: ROI = (Annualized benefits − Annualized costs) / Annualized costs. Use that to justify staged rollouts.
Don’t forget safety KPIs—these are the performance indicators that gate automation. Define actionable thresholds such as minimum acceptable plan success rate (for example, a target above 95% during canary), maximum rollback frequency, acceptable idempotency violation rate, and an embedding-drift threshold that demotes agentic execution to read-only. When any safety KPI breaches its threshold, automatically flip to a restricted mode: require multi-step authorization, throttle execution, or revert to human-in-the-loop only. Layer these gates with feature flags and canary windows so you can measure real-world ROI without exposing production systems to unacceptable blast radius.
Finally, use metrics to close the loop on engineering work and governance. Feed observability signals back into prompt/version gating, adapter test suites, and deployment policies so improvements in retrieval quality or adapter idempotency directly increase automation coverage. As we discussed earlier, tie every mutating action to a signed approval token and immutable audit event so finance, legal, and SREs can reconcile automated changes against business outcomes. With those elements in place—clear UX and safety metrics, traceable events, ROI calculations, and automated safety gates—you can iterate confidently on composition patterns and build dashboards that show both velocity and safety in one view.