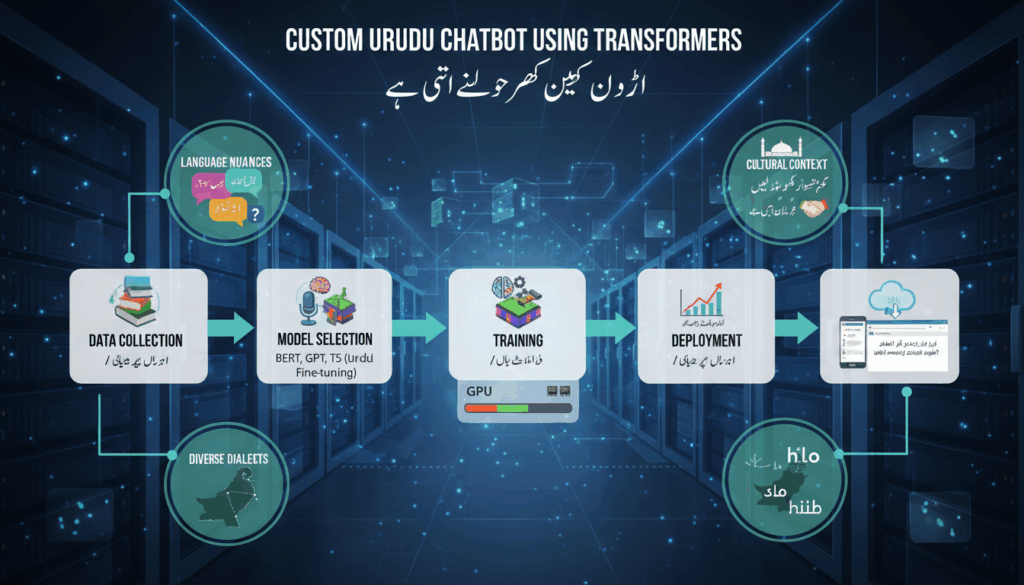
Introduction to Transformers and Their Role in Chatbot Development
The landscape of artificial intelligence and natural language processing has been significantly transformed by the advent of transformer-based models. Transformers, introduced by Vaswani et al. in their revolutionary paper “Attention is All You Need,” have become the backbone of numerous applications, particularly in the development of sophisticated chatbots.
Transformers consist of an encoder and decoder mechanism, relying primarily on self-attention mechanisms rather than recurrent neural networks (RNNs) or long short-term memory networks (LSTMs), which dominated before their emergence. The key innovation lies in the design of the self-attention mechanism, which enables transformers to weigh the importance of different words in a sentence, irrespective of their position. This capability allows transformers to better understand context and capture the nuances of language, even over long sequences.
In the realm of chatbot development, transformers bring a level of robustness and versatility previously unattained. Traditional chatbots often relied on rule-based systems or simpler machine learning algorithms, limiting their ability to understand and respond to user inputs dynamically. With transformers, chatbots can contextually generate responses that are not only coherent but also context-aware, providing users with a more engaging and intuitive interaction.
Large-scale transformer models, such as BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer), have set new benchmarks in various NLP tasks, including language translation, sentiment analysis, and question-answering systems. For instance, GPT-3, with its extensive training data and powerful architecture, can generate human-like text, allowing chatbots to perform complex conversational tasks and engage in more natural dialogues.
Moreover, transformers excel in handling multilingual data, which is particularly beneficial for developing chatbots in diverse linguistic environments like Urdu. Unlike traditional models where hand-crafted features might need to be language-specific, transformers can leverage their attention mechanisms to process differing linguistic structures inherently, granting them the flexibility to adapt across languages.
Implementing a transformer model in a chatbot involves fine-tuning a pre-trained model on domain-specific data. This process allows the model to tailor its responses according to the specific context or industry, enhancing user interaction’s relevance and quality. Developers often employ transfer learning, where they start with a model pre-trained on extensive datasets and then specialize it to understand and generate responses pertinent to their target user group.
The scalability and efficiency of transformers also make them ideal for real-time chatbot deployment. Their parallelization capability allows them to process text faster than traditional methods, ensuring that chatbots can handle numerous user interactions simultaneously without degradation in response quality.
Overall, transformers have redefined the chatbot development process, transforming them from simple query-response agents to sophisticated conversationalists capable of naturally interacting across diverse contexts and languages. Through their innovative architecture and ability to learn from vast amounts of text data, they continue to push the boundaries of what is possible in conversational AI.
Challenges in Processing Urdu Language with Transformers
Processing the Urdu language with transformer models presents a set of unique challenges due to its linguistic complexity and the particularities of training data. Understanding these issues is crucial for developers aiming to create effective Urdu-language chatbots using transformer-based models like BERT, GPT, or their derivatives.
One of the primary challenges in processing Urdu with transformers stems from the script in which Urdu is written—the Perso-Arabic script, a right-to-left script that includes a complex set of characters and diacritics. This adds a layer of difficulty because most pre-trained transformer models are initially optimized for Latin-script languages such as English. Thus, there’s a need to adapt these models to handle Urdu script effectively, which can involve augmenting datasets to include more examples of the script or even retraining parts of the model to better recognize these character encodings.
Moreover, Urdu morphology and syntax present additional hurdles. Like many other Indo-Aryan languages, Urdu is rich in inflection and agglutination. Words in Urdu often comprise a root with various prefixes and suffixes, changing tense, mood, or plurality, which can result in a single word conveying a complex meaning. Transformers need to be specifically trained to understand and generate this morphological richness. This often requires additional preprocessing steps, such as tokenization strategies tailored to account for this agglutination or deploying byte-pair encoding (BPE) to better segment and understand word forms within the language.
Another significant challenge is the scarcity of high-quality and extensive datasets specifically for Urdu. While languages like English benefit from a vast array of accessible corpora, the availability of comprehensive annotated datasets for Urdu is limited. Developers often have to rely on smaller datasets or engage in significant efforts to compile data from various sources to achieve a decent amount of training material. This can include scraping publicly available Urdu-language websites, news articles, and even social media content, followed by a comprehensive cleaning and formatting process to ensure its suitability for model training.
Transfer learning can partially mitigate these dataset limitations, where a model pre-trained in a resource-rich language is fine-tuned on the available Urdu data. However, this approach might still struggle with the idiomatic and cultural nuances specific to Urdu, affecting the chatbot’s ability to generate contextually appropriate and culturally sensitive responses. Incorporating multilingual pre-trained models like XLM-RoBERTa, which is pre-trained on data from numerous languages including some Indo-Aryan languages, provides a more tailored starting point. Nonetheless, developers often need to finetune these models with additional domain-specific Urdu data to achieve optimal performance.
To handle these challenges effectively, creating specialized pre-training tasks aimed at capturing Urdu-specific linguistic features is beneficial. Leveraging language-specific corpora and augmenting them with manually annotated data can help models better learn the unique aspects of Urdu. Further, employing human-in-the-loop frameworks can significantly enhance model training and evaluation processes, where linguists and native speakers provide feedback and fine-tune model parameters to achieve desired understanding and response capabilities.
Given these challenges, developing an Urdu-language chatbot using transformer-based models demands consideration of various linguistic and technical factors, as well as creative solutions for data acquisition and model adaptation. Each step—from customized tokenization to the selection of an effective transfer learning strategy—plays a critical role in overcoming obstacles and leveraging transformer technology to its full potential in the context of the Urdu language.
Data Collection and Preprocessing for Urdu Chatbots
The process of crafting an effective Urdu chatbot begins with the meticulous collection and preprocessing of relevant data. This stage is integral to the performance of the transformer models that drive modern chatbots, particularly in languages like Urdu, which present unique challenges due to their script and linguistic characteristics.
Urdu’s diversity and depth require a comprehensive corpus that captures various dialects, styles, and contexts. A practical approach to assembling this dataset involves sourcing data from a variety of digital platforms where Urdu is predominantly used. These include news websites, social media forums, and online literature. In particular, newspapers and blogs written in Urdu provide rich, well-structured content that can be pivotal for initial model training.
Once the data sources are identified, the data extraction process can begin. This step can be automated using web scraping tools that are customized to handle right-to-left scripts and collect text data effectively. Python libraries such as BeautifulSoup or Scrapy can be employed, but care must be taken to ensure that the text is encoded in UTF-8 to handle Urdu script properly.
Post extraction, the dataset requires diligent cleaning and formatting. This includes removing non-textual data, such as HTML tags or advertisements, and normalizing the text to address inconsistencies in spelling or punctuation. Given the morphological features of Urdu, a customized tokenization strategy is important. Tokenizers like SpaCy or the UrduHack library can be utilized, which are specifically designed to process Urdu language structures by handling word agglutination and identifying root words efficiently.
An essential preprocessing step is managing the diacritics present in the Urdu script. Diacritics indicate short vowels and are sometimes omitted in written texts. When preparing the training data, it may be beneficial to create two versions of the corpus: with and without diacritics, to train models on both forms. This helps the model understand context irrespective of diacritic usage.
To address the challenge of limited annotated datasets for Urdu, data augmentation techniques can be employed to expand the dataset artificially. Techniques such as back-translation, where Urdu text is translated into another language and then back to Urdu, can increase data diversity and richness without sacrificing quality. Additionally, leveraging data from allied languages like Hindi, which share a significant overlap in syntax and vocabulary, can further enhance the dataset.
Finally, to optimize the data for transformer models, it’s crucial to convert the text into a format suitable for input. Tokenization using BPE (Byte Pair Encoding) or SentencePiece can help segment the text efficiently into subword units, reducing vocabulary size while maintaining semantic richness. These subword units are particularly effective in capturing and representing complex word forms characteristic of Urdu.
Throughout this entire process, maintaining a structured and documented approach to data collection and preprocessing ensures repeatability and enhances our ability to refine or expand the dataset as needed. This foundational stage sets the stage for deploying a transformer-based Urdu chatbot capable of delivering nuanced and contextually relevant interactions. By integrating meticulous preprocessing and innovative data augmentation methods, developers can build an effective dataset that truly represents the linguistic richness of Urdu.
Fine-Tuning Transformer Models for Urdu Language Understanding
Fine-tuning transformer models for understanding the Urdu language involves customizing pre-trained models to better interpret and generate responses tailored to Urdu’s linguistic specifics. This customization process is crucial given the complex morphology and script variations inherent in the Urdu language. Let’s explore the steps involved in fine-tuning and the strategies that ensure this process is both effective and efficient.
At the outset, fine-tuning involves selecting a pre-trained transformer model that serves as a base. Many developers leverage models like mBERT (Multilingual BERT) or XLM-RoBERTa, which are already pre-trained on multiple languages, including some with similar characteristics to Urdu. These models provide a good starting point, having been trained on large datasets that encompass a variety of language structures.
The first step in fine-tuning is adapting the tokenizer to handle the specifics of the Urdu language. This involves augmenting the tokenizer’s vocabulary to include Urdu-specific tokens, considering its orthographic norms and common linguistic constructs. Urdu has a rich array of suffixes and prefixes, and therefore, utilizing a tokenizer that segments words into subword units, such as Byte Pair Encoding (BPE) or SentencePiece, allows the model to handle these effectively.
Subsequent to tokenizer optimization, the model must be fine-tuned using Urdu-centric datasets. This step is pivotal, as the quality and variety of the dataset directly influence the model’s performance. Training involves adjusting the model’s weights with Urdu-language text, helping it learn the syntax, semantics, and cultural nuances innate to Urdu. During this process, labeled datasets tailored to specific tasks—be it sentiment analysis, part-of-speech tagging, or named entity recognition—play a crucial role. When such datasets are unavailable, semi-supervised learning approaches, using a combination of labeled and unlabeled data, can be explored.
Fine-tuning further includes regularizing the learning process with techniques such as dropout, which helps in preventing the model from overfitting on smaller datasets. Additionally, leveraging data augmentation methods to synthetically increase the training data size is beneficial. This step might involve translating available resources from Urdu to other languages and back again to diversify sentence structures without losing semantic integrity.
Moreover, researchers often employ transfer learning frameworks to leverage linguistic similarities with allied languages, such as Hindi, during the fine-tuning phase. This approach can streamline the tuning process by borrowing linguistic principles and vocabulary shared between languages, thus enhancing the model’s contextual and cultural understanding.
Monitoring and evaluating the performance of the fine-tuned model is another crucial part of the process. Standard metrics such as accuracy, F1-score, and cross-entropy loss are typically employed to assess performance across various benchmarks. In scenarios where Urdu-specific benchmarks are lacking, customized test cases representing common conversational themes and user intent can be created to validate the chatbot’s accuracy and relevance.
Lastly, integrating feedback loops that incorporate evaluations from native Urdu speakers aids in refining the model further. This human-in-the-loop approach ensures cultural and contextual relevance, providing the model with real-world interaction data that helps it evolve beyond simple text predictions.
In summary, fine-tuning transformer models for Urdu is an iterative process that blends art with science. By crafting a carefully-prepared training regimen tailored to Urdu’s linguistic landscape, complementing technical adjustments with cultural insights, developers can significantly develop the capabilities of Urdu language understanding and thereby craft more effective and engaging chatbots.
Implementing and Evaluating the Custom Urdu Chatbot
The creation of a custom Urdu chatbot involves several crucial stages of implementation and evaluation, ensuring it effectively engages users in a culturally nuanced and contextually appropriate manner.
To begin with, the implementation phase entails designing a robust architecture utilizing transformer models. Models such as multilingual BERT or XLM-RoBERTa can be chosen as foundational frameworks due to their ability to process multiple languages, including Urdu. The architecture must be adapted to handle Urdu’s right-to-left script, complex morphology, and linguistic diversity.
Architecture Design and Implementation
The development process starts with setting up a software environment conducive to running transformer models. This typically involves utilizing platforms that support extensive libraries like TensorFlow or PyTorch. Setting up a virtual environment using tools such as Anaconda can ensure dependency management and ease of model experimentation.
After environment setup, integrating data pipeline systems is essential. This involves loading the pre-processed Urdu datasets into the model. Data is structured using NumPy arrays or Pandas DataFrames, formats that are compatible with tensor processing in transformer networks.
Training Process
Once the environment and data are prepared, the model undergoes the training phase. Here, significant care must be taken to select hyperparameters like learning rate, batch size, and epoch count, which can drastically affect model performance. Hyperparameter tuning can utilize grid search or Bayesian optimization techniques to identify the most performant setup.
During training, it is prudent to incorporate early stopping mechanisms that prevent overfitting, especially when working with relatively smaller Urdu datasets. Logging tools such as TensorBoard can be instrumental in monitoring training performance, providing visualization of metrics like loss and accuracy over time.
Incorporating Domain-Specific Knowledge
To further enhance the chatbot, incorporating domain-specific knowledge through additional fine-tuning is valuable. This involves training the model on specialized datasets tailored to specific industries or user segments, such as commerce, healthcare, or customer service. These domain adaptations empower the chatbot to provide more precise and relevant responses.
User Interaction and Feedback Collection
Implementing user interaction involves deploying the chatbot on a platform where real-time communication is managed. Platforms like Telegram or custom web applications can serve as deployment venues. Integration is achieved by interfacing the chatbot with API gateways using frameworks like Flask or FastAPI, which facilitate seamless communication between the model and end-users.
Crucially, capturing user feedback through surveys or interaction logs is necessary for iterative improvement. This feedback loop should be automated, where data is continuously analyzed to recognize patterns or shortcomings in chat responses.
Evaluation Metrics and Testing
Evaluating a custom Urdu chatbot hinges upon a combination of quantitative and qualitative metrics. Standard NLP metrics—precision, recall, and F1-score—are utilized alongside specialized tests that reflect the chatbot’s ability to handle real-world scenarios in the Urdu language.
Testing should encompass unit tests for individual functions and integration tests ensuring the system functions as a cohesive unit. Additionally, testing should simulate conversational contexts that the chatbot is expected to encounter, examining its performance across varied inputs.
Moreover, user-centric evaluations with native Urdu speakers provide insights into the quality and cultural relevance of chatbot responses. This feedback can fine-tune language nuances that may not be captured purely through automated metrics.
In summation, successfully implementing and evaluating an Urdu-language chatbot requires a meticulous approach that integrates technical, linguistic, and user-experience considerations. By continually refining through quantifiable metrics and user feedback, developers can ensure that the chatbot not only meets but exceeds expectations in delivering engaging, contextually aware interactions.



