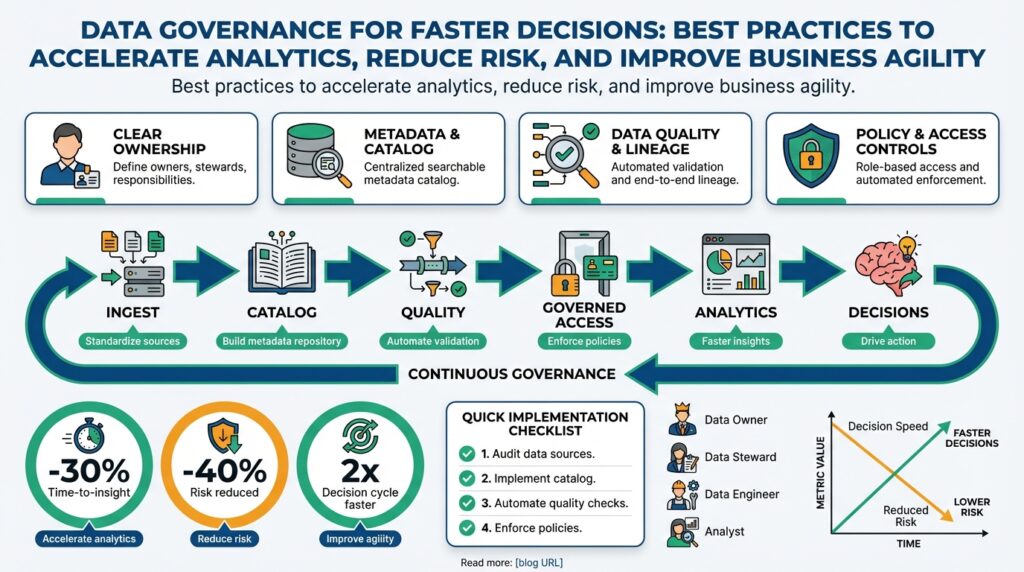
Align governance with business goals
Building on this foundation, start by tying every governance decision directly to the metrics your stakeholders care about: time-to-insight, conversion lift, regulatory compliance, or cost-per-query. Data governance and business goals must be two sides of the same coin; when they’re disconnected you get either excessive bureaucracy that slows analytics or sloppy controls that increase risk. Ask a concrete question early: how do you ensure that policy decisions accelerate rather than block analytics? Framing governance in terms of measurable business outcomes makes trade-offs explicit and gives engineers an operational target to optimize toward.
Translate strategy into technical contracts and measurables so your teams can implement governance pragmatically. Define data contracts—explicit, versioned agreements that specify schema, semantics, and SLAs between producers and consumers—and map them to KPIs or OKRs owned by product teams. A service-level objective (SLO) is one practical mapping: an SLO for data freshness (for example, 99% of records available within 15 minutes) ties a governance rule to an engineering test and a business requirement. When governance policies emit observability signals that feed the same dashboards product managers use, compliance becomes a byproduct of meeting business targets.
Adopt policy-as-code and automated validation so rules don’t live only in slide decks. Policy-as-code means you express access controls, retention, anonymization, and quality checks in versioned artifacts that run in CI/CD pipelines and data jobs. For instance, implement a pipeline stage that validates a data contract, runs schema drift detectors, and enforces encryption-at-rest flags before promoting a dataset to production. This pattern shifts governance left: engineers get fast feedback, security gets auditable artifacts, and analytics teams spend less time manually requesting exceptions.
Use concrete examples that reflect real workloads to set prioritization. If your revenue analytics depend on a small set of denormalized fact tables, treat those as high-value assets with stricter SLOs and change controls, while allowing more experimentation on exploratory sandboxes. Conversely, regulatory data subjects (like Personally Identifiable Information) require retention and anonymization policies encoded into ingestion jobs and enforced by automated tests. Specifying these rules in the same repository as ETL code—together with unit tests that simulate schema drift or sample-count regressions—reduces unexpected incidents and speeds recovery.
Align organizational roles and incentives with the technical mappings you’ve made. Create product-aligned data stewards who own the contract and SLO lifecycle, and a central governance core that provides tooling, policy templates, and compliance audit capabilities. This federation model keeps decision-making close to the teams that own business outcomes while preserving consistent guardrails. Reward teams for delivering measurable improvements in data quality and time-to-insight rather than simply for ticking compliance checkboxes; incentives drive behavior faster than mandates.
Finally, instrument for continuous learning: convert governance artifacts into signals that populate dashboards and trigger remediation workflows. Treat quality metrics, access logs, and contract validation failures as first-class observability data so you can correlate governance health with business metrics like churn or revenue per user. Run periodic governance retrospectives that examine incidents through the lens of business impact and update contracts and policies accordingly. By operationalizing governance against concrete business goals, we make controls actionable, measurable, and adaptive—preparing the organization to scale analytics velocity without increasing risk.
Assess data maturity and gaps
Building on our earlier point that governance must map to business outcomes, the first step is an evidence-based assessment of data maturity so you can stop guessing where controls add value and where they add friction. Start by inventorying critical data products and their owners, then score capabilities against a consistent data governance rubric that measures metadata coverage, lineage visibility, access controls, policy automation, and operational SLAs. This diagnostic uncovers hard gaps—missing owners, no lineage, undocumented schemas—and soft gaps like unclear SLOs or misaligned incentives. When you treat assessment as a deliverable with measurable outputs, you create a defensible roadmap rather than a list of anecdotes.
Choose a practical maturity model and keep it lightweight: a four- or five-level capability map works well for engineering teams because it’s actionable and auditable. Define what “level 1” vs “level 4” means for each capability (for example, level 1 schema drift is manually detected; level 4 is automated drift detection with CI gates and alerts), then apply that taxonomy across dataset classes—regulatory, revenue-critical, and exploratory. Use your data catalog to centralize these artifacts so the maturity assessment isn’t siloed in spreadsheets. Doing this links the abstract notion of data maturity to concrete tooling and people, which accelerates remediation.
Operationalize scoring with dataset scorecards that capture measurable signals instead of vague judgments. Include metrics such as freshness SLAs met (%), completeness (null or missing-rate thresholds), schema drift incidents per month, lineage coverage (% of fields with lineage), unit-test pass rate for contracts, and the presence of an assigned steward. Weight each metric by business impact—revenue tables get higher weights than ad-hoc sandboxes—then compute a composite maturity score. This lets you sort datasets by risk and value so you can answer questions like “Which tables block our top three dashboards?” quickly and objectively.
Automate the evidence collection so assessments remain current and reproducible. Implement profiling jobs that feed the scorecard, run schema comparisons as part of CI/CD, and capture access and audit logs into the governance telemetry stream. Policy-as-code hooks should publish pass/fail to the same data governance dashboard that product managers use, closing the loop between engineering controls and business KPIs. That automation reduces the manual toil of audits, improves the fidelity of your data quality signals, and surfaces regressions before consumers are affected.
Once you have scored assets, perform a gap analysis that prioritizes remediation by impact, cost, and compliance risk. How do you turn an assessment into prioritized work? Map each gap to a business metric—time-to-insight, revenue-at-risk, or regulatory exposure—and estimate engineering effort to fix it. Create a two-track backlog: short tickets for high-impact, low-effort fixes (e.g., assign owners, add simple lineage tags) and longer initiatives for systemic improvements (e.g., standardized ingestion templates, end-to-end lineage). Use SLOs and targeting in product OKRs to fund and measure delivery, so improvements are not abstract obligations but tracked outcomes.
Treat the assessment cycle as continuous improvement rather than a one-off audit; schedule lightweight reassessments tied to release cadence and major schema changes. Maintain the data catalog as the single source of truth for ownership, contracts, and maturity scores so teams can see progress and blockers at a glance. By linking maturity metrics to operational telemetry and business outcomes, we make remediation decisions transparent, measurable, and defensible—preparing the organization to accelerate analytics without increasing risk and ensuring every investment in governance reduces time-to-insight or controls a quantifiable exposure.
Assign data owners and stewards
Building on this foundation, start by designating clear owners and stewards for each critical dataset so your data governance and business goals actually move in the same direction. In the first 100 words we should be explicit: data governance succeeds when accountability maps to outcomes, and that requires named data owners who answer for SLAs and product-aligned data stewards who operationalize policy. Put those names into the data catalog alongside data contracts and SLOs so discovery, compliance, and operational telemetry point to a responsible human or team. This small step shifts governance from an abstract checklist to a set of executable responsibilities you can measure and enforce.
The roles must be distinct and actionable: an owner is accountable for the dataset’s business correctness, contracts, and SLOs, while a steward focuses on day-to-day quality, metadata, and lifecycle actions. Owners should be product or domain teams that understand business semantics and can prioritize fixes when an SLO slips; stewards should be embedded specialists or platform members who implement policy-as-code, manage lineage metadata, and run remediation playbooks. Define these responsibilities in the catalog and in the repository that houses your data contracts so responsibilities are discoverable and testable. Treat the owner as the decision-maker for schema changes and the steward as the executor who enforces CI gates and data quality tests.
In practice, adopt a federated assignment pattern: align owners with the product teams that rely on the dataset and centralize stewards in a governance core that supplies tooling, templates, and audit capabilities. For example, make the revenue analytics product team the owner of the denormalized revenue fact table and assign a governance steward to ensure the ingestion pipeline publishes freshness metrics, unit-test contracts, and field-level lineage. This preserves business context and accelerates decision-making while keeping guardrails consistent across domains. Where regulatory datasets contain sensitive PII, give ownership to the compliance-aligned team but attach a compliance steward from security to enforce retention and anonymization rules.
Operationalize the arrangement with onboarding, runbooks, and automation so ownership doesn’t become a paper exercise. Require owners to declare SLOs and data contracts in the same repo as ETL code, then enforce those contracts with CI/CD gates that fail builds on schema drift or missing lineage. Have stewards maintain the data catalog entries, run profiling jobs that feed dataset scorecards, and open remediation tickets automatically when threshold breaches occur. Use access-control templates tied to ownership: owners can approve consumer access for their domain, while stewards review access scopes for policy compliance, creating a clear approval workflow and audit trail.
Measure ownership effectiveness with signals that tie back to business KPIs and the maturity assessment we described earlier. Track metrics such as SLO compliance rate, incident-to-owner ratio, mean time to remediate data quality alerts, and the percentage of datasets with complete lineage in the data catalog. How do you handle exploratory sandboxes or ephemeral datasets? Assign temporary owners with expiration policies and default stewards who can either promote the dataset to permanent status or archive it after a TTL, reducing technical debt and uncontrolled data sprawl. Link these measurements to team OKRs so ownership becomes a performance criterion rather than an ignored label.
Make ownership review a lightweight, repeatable process: revalidate ownership after major releases, when maturity scores drop, or quarterly as part of your governance retrospectives. Update data contracts, refresh SLOs, and rotate stewards when organizational priorities change so accountability stays aligned with the metrics stakeholders care about. When you operationalize ownership with the data catalog, policy-as-code, and measurable SLOs, governance becomes an enabler of faster, safer analytics rather than an obstacle—paving the way for the next set of governance controls and automation we’ll implement.
Define policies, standards, and metrics
Building on this foundation, start by making your data governance goals actionable through concrete policies, standards, and metrics that accelerate decision-making instead of blocking it. If policies remain high-level statements, engineers and product teams will interpret them differently and analytics velocity will stall. Front-load the work: translate business requirements (time-to-insight, revenue impact, or regulatory retention) into explicit policy documents and measurable standards that live alongside code and data contracts. When you treat policies as engineering artifacts, they become testable gates rather than vague mandates.
Begin with clear definitions so everyone shares the same language: a policy is a rule set that governs behavior (for example, retention or access), a standard is a required implementation pattern (for example, naming conventions or encryption algorithms), and a metric is a quantitative signal used to measure compliance or impact. Define service-level objectives (SLOs) for dataset health—freshness SLOs, completeness thresholds, and allowed schema-change windows—and map each SLO to an owner who can remediate failures. Make these definitions versioned and discoverable in the data catalog so you can trace a broken dashboard back to the precise policy and the person accountable.
Encode rules where possible using policy-as-code so enforcement happens at commit time rather than during audits. Policy-as-code (expressing governance rules as executable, version-controlled artifacts) lets your CI/CD pipelines validate retention flags, detect schema drift, and deny promotion of datasets that don’t meet encryption or lineage requirements. For example, implement a pipeline stage that rejects a dataset promotion unless the retention TTL annotation exists, PII fields are flagged, and unit tests for the latest schema pass. This pattern reduces manual ticketing and provides an auditable trail for both engineers and compliance teams.
Choose metrics that map directly to business outcomes rather than vanity signals. How do you select the right metrics? Start by asking which dataset failures would increase churn, reduce revenue, or create regulatory exposure; translate those outcomes into leading and lagging indicators such as percent of queries served from fresh data, completeness (non-null rate) for revenue keys, schema drift incidents per release, consumer error rate, and data access-request turnaround time. Weight these metrics by business impact—treat a failure on a revenue fact table as higher priority than on an exploratory sandbox—and expose composite scores in team OKRs so improvements are funded and measured.
Standardize implementation details to reduce friction and ambiguity. Specify naming conventions, canonical data types, field-level metadata requirements, lineage tagging, access-control templates, encryption-at-rest and in-transit requirements, and approved anonymization techniques. For high-value assets like denormalized revenue tables require stricter SLOs, immutable change logs, and staged deployments; for sandboxes allow lighter standards with TTLs and automatic archiving. Tie standards to ownership: require owners to declare the standard class in the catalog and stewards to enforce it via automated checks.
Operationalize measurement and remediation so metrics produce action. Publish dataset scorecards that combine policy pass/fail signals with business-weighted maturity scores, stream those signals into governance dashboards and incident channels, and automate remediation playbooks for common failures (re-run ingestion, roll back schema change, notify owner). Measure the governance program itself by tracking SLO compliance rate, mean time to remediate, and correlation between governance health and time-to-insight. Taking this concept further, use those measurements to iterate on policies and standards so governance continuously reduces risk while increasing analytics velocity.
Implement catalog, lineage, and MDM
Building on this foundation, start by treating your data catalog, data lineage, and MDM as first-class engineering components rather than optional documentation. If you ask “How do you make governance accelerate analytics?” the short answer is: make metadata actionable, observable, and integrated into CI/CD so discovery, trust, and master-data reconciliation happen as part of delivery. Front-load the catalog with ownership, contracts, SLOs, and sensitivity labels so teams can make safe decisions without manual approval loops.
A practical data catalog is more than a directory; it’s a live metadata system that powers discovery, access, and automated policy enforcement. Design a metadata model that includes dataset schema, semantic tags, owners, SLOs, consumer contracts, and sensitivity classifications. Persist those attributes in versioned, machine-readable form so pipelines and policy-as-code can query them. When you map catalog entries to the dataset scorecards and incident telemetry we discussed earlier, the catalog becomes the single source of truth for prioritizing remediation and measuring time-to-insight.
Lineage gives you the context to trust and triage datasets quickly, but there are meaningful trade-offs between job-level and field-level lineage. Capture lineage at the granularity you need: job-level lineage is cheap and answers “which pipeline changed?”, while field-level lineage answers “what transformed this revenue key?” Instrument your ETL/ELT tools to emit lineage events (for example, OpenLineage-compatible metadata) or embed lineage metadata in transformation artifacts. A simple dbt model metadata block illustrates the pattern:
version: 2
models:
- name: revenue_fact
description: "Denormalized daily revenue by product"
meta:
owner: product-analytics
lineage: [stg_orders.order_amount, stg_payments.amount]
slos: {freshness_minutes: 15}
This keeps lineage consumable by catalog UIs and automated tests, and lets you compute lineage coverage metrics for dataset scorecards.
Master Data Management (MDM) is the glue that prevents divergent meanings and reconciles golden records across domains. Decide whether a centralized golden-record service or a federated reconciliation approach fits your org: centralized MDM simplifies consistency but increases coupling, while federated MDM keeps domains autonomous but requires robust reconciliation and conflict-resolution rules. Implement identity resolution (deterministic keys + probabilistic matching), a reconciliation workflow with provenance, and publish a canonical API or dataset that downstream consumers can trust. For example, treat the product catalog as the canonical source for pricing and taxonomy and surface reconciliation exceptions into the steward workflow.
Operationalizing these systems requires embedding catalog, lineage, and MDM checks into CI/CD and data pipelines. Add pipeline stages that validate catalog metadata, verify lineage coverage thresholds, and run MDM reconciliation smoke tests before promoting datasets. Make governance failures actionable: open remediation tickets, notify owners, and optionally block promotion for high-value assets. Treat these checks like unit tests—fast, deterministic, and visible in pull requests—so engineers get immediate feedback and compliance becomes a developer workflow rather than a post-facto audit.
Finally, measure the impact and iterate: track percent of queries served from cataloged datasets, lineage coverage for top-value tables, MDM reconciliation success rate, and mean time to resolve golden-record conflicts. Use those metrics to prioritize where to invest—field-level lineage for revenue tables, stronger MDM for customer 360, lighter cataloging for ephemeral sandboxes. By making metadata actionable and tightly coupled to your release process, we reduce risk, speed up analytics, and make it practical for teams to discover, trust, and reuse data.
Automate controls and measure impact
Building on this foundation, start by treating policy-as-code, data governance, and automated controls as developer-facing features rather than compliance chores. If you ask “How do you make governance accelerate analytics instead of slowing it?” the answer is simple in principle: codify rules, run them early, and measure their business impact. Front-load SLOs and dataset metadata in the data catalog so every pipeline, PR, and deployment can reference the same authoritative policies. When governance lives in CI/CD and the catalog, policy checks become fast feedback loops that guide engineering decisions instead of bureaucratic delays.
The practical pattern is to insert automated controls at three choke points: ingestion, transformation, and dataset promotion. At ingestion we validate sensitivity labels and retention TTLs; during transformation we run unit tests and schema-drift detectors; before promotion we enforce lineage coverage and SLO compliance. Implement these checks as idempotent, fast-running jobs so they can run on pull requests and commit hooks without blocking developer velocity. By embedding controls where engineers already work, you shift left governance and reduce firefighting in production.
Make policy-as-code actionable with a small, testable example that you can replicate across repos. For instance, add a CI stage that fails a build if a manifest lacks pii=true annotations or if freshness SLOs are unmet for a revenue dataset:
jobs:
validate-dataset:
runs-on: ubuntu-latest
steps:
- run: python tools/validate_manifest.py --path manifest.yml --require pii,slos,lineage
- run: pytest tests/schema_tests.py::test_no_schema_drift
This pattern keeps checks declarative, versioned, and reviewable; teams iterate on the same artifacts that production uses, and auditors get an auditable trail without manual spreadsheets.
Measuring impact requires treating governance telemetry as first-class observability data and mapping it to business KPIs. Track SLO compliance rate, mean time to detect and remediate data incidents, percent of queries served from fresh data, and consumer error rates; correlate those with time-to-insight and revenue-impact metrics owned by product teams. Weight metrics by dataset criticality—treat failures on a revenue fact table as higher priority—and expose composite scorecards in team OKRs. This lets you answer causal questions like whether stricter schema gates reduced dashboard failures or slowed feature delivery.
Automation should not stop at detection: close the loop with remediation playbooks and controlled rollbacks. When a policy gate fails for a high-value table, automatically open a ticket with pre-populated diagnostics, notify the dataset owner, and optionally block production promotion until an owner-approved exception is recorded. For less-critical sandboxes, trigger automatic archiving or a TTL enforcement job to reduce sprawl. Use staged promotion and canary datasets to validate schema changes against a sampled production workload before full rollout, minimizing blast radius while keeping teams nimble.
Finally, build governance analytics that let you iterate on controls instead of etching them in stone. Combine catalog-sourced metadata, CI pass/fail events, access logs, and business KPIs into dashboards that show the net effect of automation on both risk and velocity. Run controlled experiments—enable a stricter policy for one product team and compare incident rates and delivery time against a control group—to learn which controls produce the best ROI. Taking this approach, we make automated controls measurable, tunable, and aligned with the same business outcomes your stakeholders care about, and then feed those learnings back into the catalog, lineage, and MDM workflows for continuous improvement.



