Why Flexible Schemas Matter
Imagine you launch a product with three fields, and a month later the team asks for eight more. That moment is where flexible schemas start to matter. A schema is the blueprint of your data, and when that blueprint is too rigid, every new idea feels expensive, slow, and risky. In contrast, flexible schemas let your database grow with the product instead of forcing the product to wait for the database.
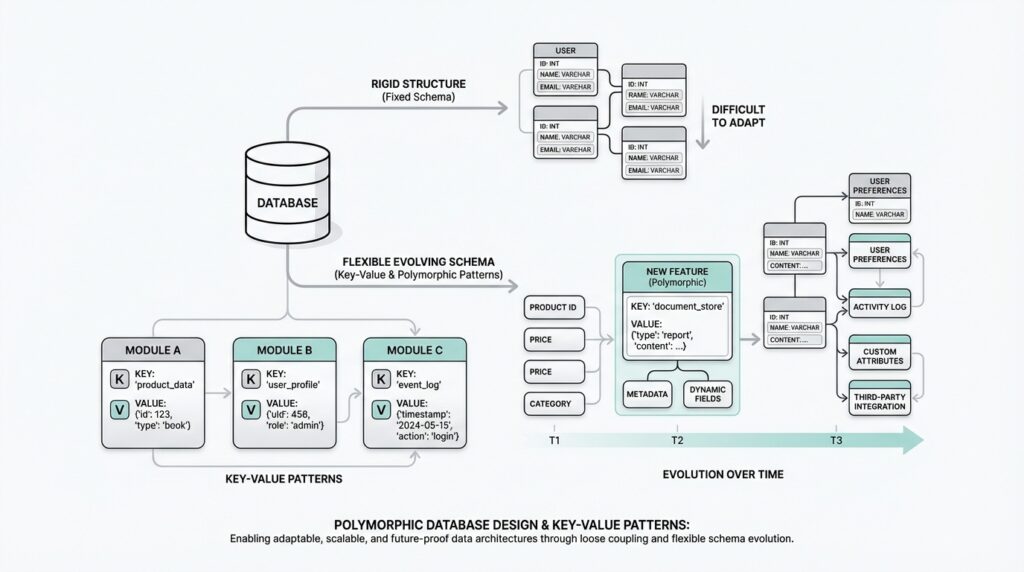
Building on this foundation, the real value shows up when your data does not all look the same. One customer might have a shipping address, another might have a pickup location, and another might have both. If you try to squeeze every possible variation into one fixed table, you end up with lots of empty columns, awkward workarounds, or constant redesigns. Flexible schemas make database design polymorphism practical because they let different record types share a common structure while still carrying their own unique details.
This is where key-value patterns become useful. Think of them like labeled drawers: the key is the label, and the value is whatever belongs there. Instead of creating a new column for every possible attribute, you store the core fields you know you need and keep the changing parts in a more open-ended format. That approach is especially helpful when you are not yet sure which fields will stick, or when different users, products, or events need different data shapes.
Why does that matter in real life? Because software changes faster than database tables like to. New business rules appear, experiments get launched, and product teams discover edge cases after the first release. A flexible schema gives you room to respond without pausing development for a painful migration every time requirements shift. You still keep structure where it matters, but you stop treating every unknown as if it must be decided on day one.
There is another quiet benefit too: flexible schemas reduce the pressure to predict the future perfectly. Early on, teams often spend too much time debating what the “right” columns should be, only to learn later that the real shape of the data looks different. With a key-value pattern, you can start with the important shared fields and allow the rest to evolve. That does not mean abandoning discipline; it means reserving strict rules for the parts of the model that are stable, while leaving room for the parts that are still changing.
Of course, flexibility comes with a trade-off. When every field can vary, you need clearer conventions for naming, validation, and querying, or the data can become messy quickly. That is why flexible schemas work best when you use them intentionally, not as an excuse to store everything carelessly. The goal is not to remove structure, but to place structure where it helps and loosen it where change is most likely.
So when should you reach for this approach? Usually when your data looks more like a family of related shapes than one neat spreadsheet. If you are building a system where records can differ in meaningful ways, flexible schemas give you a way to keep moving without rebuilding the foundation every time the design expands. And once you see that, the key-value pattern stops feeling like a workaround and starts feeling like a practical tool for keeping database design polymorphism adaptable, durable, and ready for what comes next.
Model Core Entities First
Building on this foundation, the next move is to get the stable parts of the model into place before you worry about the changing ones. In database design polymorphism, that means identifying the core entity first: the record shape that every variation can share, no matter how different the details become later. Think of it like building a house before choosing the furniture. You want the walls, doors, and rooms laid out clearly, because those are the parts that have to support everything else. When you start this way, flexible schemas feel much less chaotic, because the key-value pattern has a clear home instead of becoming a catch-all for everything.
So what counts as a core entity? It is the small set of fields that almost every record needs to exist and make sense. If you were modeling customers, that might include an ID, a name, and a creation date. If you were modeling orders, it might include an order ID, a status, and the time the order was placed. These fields are the anchors of the record, the pieces you expect to search, join, sort, and trust. Everything else can be evaluated later. This is why flexible schemas work best when you model the stable center first and treat the variable details as something layered on top.
How do you know which fields belong in that center? A good rule is to ask whether the field describes the identity of the thing or only one version of it. Identity fields belong in the core because they help you recognize the record across the whole system. Version-specific fields, by contrast, are often a better fit for the key-value pattern because they change more often or apply only to certain cases. A customer may always have a customer ID, but only some customers may have a preferred pickup location, a loyalty tier, or special delivery instructions. In database design polymorphism, that split keeps the main table clean while still giving each record room to express its differences.
This is where many beginners get tripped up, because it is tempting to put every useful detail into the first table you create. But when you do that, the model starts to blur. The core entity becomes crowded with fields that are meaningful only sometimes, and the database stops telling a clear story. If you have ever looked at a form with dozens of optional boxes and wondered which ones actually matter, you have felt this problem already. The goal is to avoid that confusion by making the shared structure obvious first, then letting the flexible schemas handle the rest in a controlled way.
A practical way to think about it is to separate “what this thing is” from “what this thing currently has.” The first part belongs in the core entity, because it stays useful even as your product grows. The second part often belongs in the key-value pattern, because it can shift with user type, region, experiment, or business rule. That is also why this approach supports database design polymorphism so well: different record types can share a common spine while carrying their own details in a more open-ended layer. You are not avoiding structure; you are placing it where it does the most work.
Once you start modeling this way, the database becomes easier to reason about. You can read the core entity and immediately understand the record’s role, while still knowing there is room for specialized attributes when you need them. That balance is the real strength of flexible schemas, and it is what makes the key-value pattern feel deliberate instead of improvised. With the core in place, the next question becomes much more interesting: which details deserve a stable column, and which ones are better left to evolve?
Design the Key-Value Table
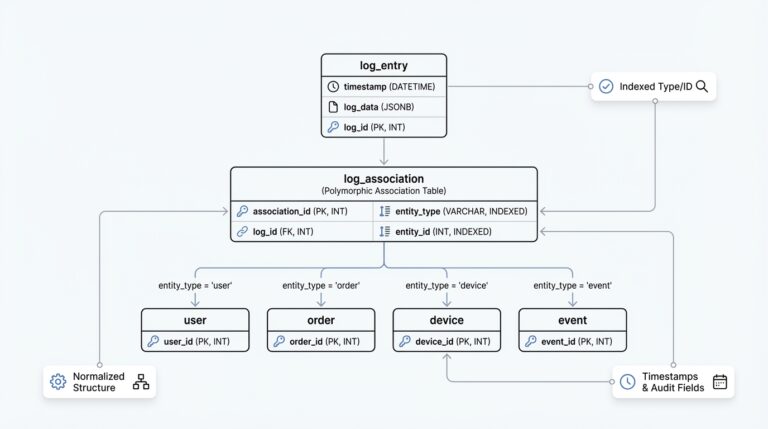
Building on this foundation, we can now shape the key-value table itself—the place where the changing parts of your data learn to live without disturbing the stable core. A key-value table is a table that stores a short label, called the key, and the piece of data attached to it, called the value. Think of it like a set of labeled envelopes: the main record stays in one drawer, while the flexible details sit in another drawer that can grow and change over time. In database design polymorphism, this is where the model starts to feel practical, because one shared entity can carry many different sets of attributes without forcing every variation into the same fixed layout.
The first design choice is to make the table answer one clear question: what record does this value belong to? That usually means storing a parent identifier, which is a number or unique code that points back to the core entity you already designed. If you are modeling customers, for example, the customer table might hold the customer ID and name, while the key-value table holds things like preferred pickup location or loyalty tier. This separation matters because it keeps the flexible schema readable. How do you know whether a field belongs here? If the field can change from one record type to another, or from one customer to the next, it is a strong candidate for the key-value table.
Once that link is in place, the next question is naming. The key should read like a clear label, not like a puzzle only the original developer can solve. Good keys are specific, consistent, and easy to search, because they become the vocabulary of your flexible schema. If one team writes preferred_pickup and another writes pickup_preference, the database starts to split into two stories instead of one. That is why conventions matter so much in a key-value table: the more freedom you give the data, the more carefully you need to guide the language around it. In database design polymorphism, this discipline is what keeps variety from turning into confusion.
The value column deserves just as much attention, because it has to hold different kinds of information without losing meaning. Sometimes the value is plain text, like “warehouse A.” Sometimes it is a number, like “3,” or a date, like “2026-04-08.” And sometimes it may need to hold structured data, such as a JSON object, which is a text-based way to store nested information. The important part is not choosing the fanciest format; it is choosing one that matches the kinds of details you expect to store. If you know a value will always be a short label, keep it simple. If you expect more complex settings, give the table a value format that can hold them cleanly.
You also want to think about whether each row needs a type column. A type column tells the database what kind of value it is holding, such as text, number, date, or boolean, where boolean means true or false. That extra clue can make validation easier, because your application can check whether the value fits the kind of data the key expects. Without that guardrail, a flexible schema can become a little too flexible, and the database may end up storing mismatched values that are difficult to query later. This is one of the quiet lessons of designing a key-value table: the more open the design, the more important it becomes to preserve meaning.
Now that we understand the basic shape, let us take a step back and ask what the table is really protecting. It is protecting the core entity from churn. Instead of changing the main table every time a new attribute appears, you let the key-value table absorb those shifts while the stable record stays calm and predictable. That makes inserts and updates easier to manage, especially when your application supports different record shapes for different users, regions, or product modes. You are not hiding complexity; you are moving it to a place built for change.
A well-designed key-value table also needs one final promise: it should be easy to read back into a human story. When you query it, you should be able to reconstruct the record without guessing which values belong together or what each label means. That is why thoughtful column names, consistent keys, and clear value types all work together. They turn flexible schemas into something dependable instead of messy. And once that structure is in place, the next challenge becomes much more interesting: deciding how to validate those values so the freedom of database design polymorphism does not come at the cost of trust.
Handle Polymorphic Records
Building on this foundation, the next step is to let one record wear more than one shape without losing its identity. In database design polymorphism, that usually means keeping a shared parent row for the things every record must know, then attaching variant-specific details for the parts that differ. Think of it like a passport and its visa pages: the passport tells you who the traveler is, while the extra pages describe where they can go. That same pattern keeps flexible schemas readable, because the main entity stays steady even when the details shift from one case to another.
How do you know which shape to expect when a record can play multiple roles? You give the row a discriminator, which is a simple marker that says what kind of variant it is. A discriminator can be a type field like pickup_customer, billing_customer, or enterprise_customer, and it gives your application a clear clue before it tries to interpret the flexible part of the record. This is one of the quiet strengths of the key-value pattern: you are not asking the database to guess, you are teaching it how to sort the possibilities. In database design polymorphism, that small label prevents a lot of confusion later.
Once the type is known, the variant data can live beside the core entity without crowding it. For example, a delivery order might always have an order ID, status, and created time, while only some orders also carry a locker code, a pickup window, or a special handling note. Those extra attributes are a natural fit for flexible schemas because they do not belong to every record in the family, but they still matter when that specific record appears. The key-value pattern works well here because it lets each record carry its own vocabulary while still sharing the same spine as the rest of the group.
When you read these records back, you want to think in layers. First, load the shared entity so you know what you are looking at; then, read the variant details and merge them into a single view for the application. That approach lines up well with database features built for semi-structured data: PostgreSQL offers json and jsonb, and jsonb supports GIN indexes for efficient searches over keys and values, while MySQL provides a native JSON type and can index JSON-derived expressions through generated columns. In practice, that means you can keep polymorphic records flexible without giving up all of your query power.
The hard part is not storing variety; it is keeping variety trustworthy. Each record type should still have rules about which keys are expected, which values are allowed, and which combinations make sense together. If you store variant data as JSON, MySQL validates JSON documents when they are written, and PostgreSQL can pair flexible storage with generated columns that compute stable values from the underlying data. That gives you a practical middle ground: the flexible schema can evolve, while the parts you need to search, sort, or trust most can still behave like ordinary columns.
So the real trick is to treat each polymorphic record like a familiar person with changing outfits, not like a brand-new stranger every time. The core entity tells you who it is, the discriminator tells you which variation you are dealing with, and the key-value pattern holds the details that only matter in that context. That is why database design polymorphism feels manageable once it clicks: you are not abandoning structure, you are arranging structure at different layers of the record. With that in place, we can move on to the next challenge of making those layers easy to validate and query without losing the flexibility that made them worthwhile in the first place.
Query Dynamic Attributes
When you start querying dynamic attributes, the first surprise is that the data you tucked away for flexibility still needs to behave like something you can search, filter, and sort. That is the whole balancing act of flexible schemas: you want the record to stay open-ended, but you also want the database to answer questions without wandering through every row like it lost the map. How do you query dynamic attributes without making every request feel improvised? The answer is to be selective about which fields stay truly dynamic and which ones deserve a path the database can index and understand.
In PostgreSQL, the jsonb type is built for this kind of work. The official documentation says jsonb can be searched efficiently with GIN indexes, and those indexes support operators for checking whether a key exists, whether a document contains another document, and whether a JSON path matches. That means you are not forced to treat every polymorphic record like an opaque blob; you can ask focused questions such as whether a key is present or whether a value matches a specific shape. In database design polymorphism, that is a powerful middle ground: the record stays flexible, but the parts you need to query most often can still be indexed.
MySQL takes a slightly different road. Its JSON columns are not indexed directly, so the usual pattern is to pull out the value you care about into a generated column, then index that column, or to use a JSON_VALUE() expression that the optimizer can use for an index. The manual also notes that JSON columns are automatically validated as JSON documents, which helps keep malformed data from slipping in and breaking later queries. In practice, that means you can keep the flexible schema in place while still giving the database a stable handle for the fields that matter in searches and reports.
This is where query design starts to feel less like guesswork and more like storytelling. You begin with the core record you already know, then you ask whether a dynamic field exists, and only then do you read its value. That layered approach matters because not every record in a polymorphic family carries the same attributes, and the database should be allowed to distinguish between “missing,” “present but empty,” and “present with a real value.” PostgreSQL’s jsonb operators and MySQL’s JSON path functions both support that style of reading, which is why flexible schemas can still support precise lookups when you treat the dynamic portion with care.
The next step is deciding which dynamic attributes deserve promotion. If a field becomes important in filters, dashboards, or joins, it is often worth extracting it into a generated or computed value so the query engine can use an ordinary index instead of scanning the whole flexible payload. PostgreSQL’s generated columns are computed from other columns, and MySQL explicitly describes generated columns as a way to simulate functional indexes, including for JSON data. That is a useful rule of thumb: if you keep asking the same question, give the database a simpler answer to store.
When you put all of this together, querying dynamic attributes becomes a design choice rather than a compromise. You let the key-value pattern hold the details that change often, but you keep a short list of fields visible to the optimizer through indexes, generated columns, or JSON-aware operators. That is what makes database design polymorphism workable in the real world: the model stays adaptable, while the queries stay clear enough to trust. And once that balance clicks, you are ready to think about the next layer—how to keep those flexible queries predictable as the data grows and the rules around it get stricter.
Add Validation and Indexes
Building on this foundation, the moment your flexible schema starts accepting real data is the moment validation and indexes become essential. Without them, database design polymorphism can drift from elegant to chaotic very quickly: keys start spelling themselves differently, values arrive in the wrong shape, and queries begin to slow down as the data grows. Think of validation as the fence around the garden and indexes as the paths that help you move through it. The key-value pattern gives you room to grow, but validation and indexes are what keep that growth organized and usable.
Validation is the set of rules that tells each record what is allowed to exist. In plain language, it answers questions like: which keys are valid for this record type, which values belong together, and what kind of data should each field hold? If a customer record is allowed to store a preferred pickup location, validation can make sure that field is a real location string instead of a random note or a half-finished sentence. That matters because flexible schemas are meant to evolve, not to become vague. The more freedom you give the model, the more important it becomes to define the edges of that freedom.
How do you keep that freedom from turning into guesswork? You validate at the moment data is written, not after the damage has spread. This can happen in the application, in the database, or in both places together. The application catches obvious mistakes early, while the database provides a final guardrail so bad data cannot slip through if one code path forgets a rule. In database design polymorphism, that double check is especially valuable because different record types often need different rules, and those rules should stay close to the data they protect.
It helps to think of validation as a recipe with variations. The base recipe stays the same, but certain ingredients only appear in one version of the dish. A delivery order might require a delivery address, while a pickup order might require a locker code instead. Both are valid, but they are not interchangeable. When you validate those differences clearly, the key-value pattern stays flexible without becoming ambiguous, and your records remain easy for both people and software to trust.
Indexes play a different role. If validation is about correctness, indexes are about speed, because they help the database find the rows you care about without scanning everything. The easiest place to start is the stable core: the parent ID, the record type, the created date, and any other fields you search constantly. After that, you can choose a small number of dynamic attributes that deserve faster lookup. This is where flexible schemas become practical in day-to-day work, because you do not index everything—you index the pieces that keep showing up in searches, filters, and reports.
The smartest indexes are the ones that match your real questions. If your team often asks, “Which enterprise customers have a special delivery note?” then the delivery note field is no longer just extra detail; it is a field with business value. That is the point where you may promote it into a searchable path, whether through a dedicated column, a computed field, or an index over structured data. In database design polymorphism, this kind of selective indexing keeps the model open-ended while still giving the database a fast route to the answers you ask most often.
There is also a quiet balance to watch here. Too little validation, and the schema becomes unreliable. Too many indexes, and every write slows down because the database has to maintain all of them. The goal is not to index every flexible field or to enforce every possible rule in advance. The goal is to protect the shared structure, validate the important variations, and index the attributes that truly drive your queries. When those pieces work together, flexible schemas stop feeling like a gamble and start feeling like a controlled way to let the model grow with the product.